多GPU联合训练深度学习模型
目前,深度学习已经进入大模型时代,虽然大模型有着诸多的其余深度学习模型无可比拟的优势,但是其庞大的规模却能让很多人望而却步,比如,训练一个大语言模型就是一件很困难的事。众所周知,目前的GPU内存是有限制的,就拿最有名的n卡来说,最大的内存容纳也只有80G,但是在训练大模型时,一个普通的训练过程其显存暂用量就有可能轻松超过80G,如果超过了80G后,我们就只能袖手旁观了吗?答案显然是否定的。这里我们将介绍如何使用多块GPU来联合训练模型。
一、前期准备:
1、构建模型框架:
①神经网路模型:
lass NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits②训练函数与测试函数
def train(dataloader, model, loss_fn, optimizer, device):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device) # copy data from cpu to gpu
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")def test(dataloader, model, loss_fn, device):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device) # copy data from cpu to gpu
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")③数据集准备
2、运行环境搭建
这里选用亚马逊ec2云服务器,选用适合自己任务的机器实例,详情见如何在EC2平台上创建实例并用于跑深度学习模型_小飞的大肥牛的博客-CSDN博客
二、单GPU运行
无论你处于深度学习何种段位,相信你对单GPU训练模式都不会陌生,他的训练过程就如下图所示,这里就不赘述。

三、多GPU训练---DataParallel
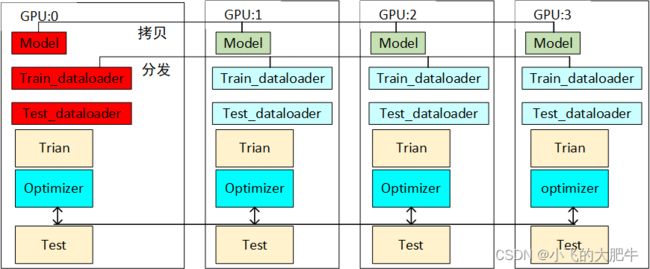
1、DataParallel的基本原理
Dataparallel是数据分离型,其具体做法是:在前向传播过程中,输入数据会被分成多个子部分送到不同的 device 中进行计算,而网络模型则是在每个 device 上都拷贝一份,即:输入的 batch 是平均分配到每个 device 中去,而网络模型需要拷贝到每个 device 中。在反向传播过程中,每个副本积累的梯度会被累加到原始模块中,未指明 output_device 的情况下会在 device_ids[0] 上进行运算,更新好以后把权重分发到其余卡。如下图所示:
2、使用方式:
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
n_gpu = torch.cuda.device_count() # 统计服务器gpu个数
device = torch.device('cuda:0' if n_gpu > 0 else 'cpu') # 指定主设备
device_ids = list(range(n_gpu)) # 给gpu编号派发
model = NeuralNetwork().to(device) # 定义模型并指派到主设备
model = torch.nn.DataParallel(model, device_ids=device_ids) # 拷贝模型副本到每个gpu中3、注意事项
运行DataParallel模块之前,并行化模块必须在device_ids [0]上具有其参数和缓冲区。在执行DataParallel之前,会首先把其模型的参数放在device_ids[0]上。举个例子,服务器是八卡的服务器,刚好前面序号是0的卡被别人占用着,于是你只能用其他的卡来,比如你用2和3号卡,如果你直接指定 device_ids=[2, 3] 的话会出现模型初始化错误,类似于module没有复制到在 device_ids[0] 上去。那么你需要在运行train之前需要添加如下两句话指定程序可见的devices,如下:
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "2, 3"当添加这两行代码后,那么 device_ids[0] 默认的就是第2号卡,你的模型也会初始化在第2号卡上了,而不会占用第0号卡了。设置上面两行代码后,那么对这个程序而言可见的只有2和3号卡,和其他的卡没有关系,这是物理上的号卡,逻辑上来说其实是对应0和1号卡,即 device_ids[0] 对应的就是第2号卡,device_ids[1] 对应的就是第3号卡。(当然你要保证上面这两行代码需要定义在下面两行代码之前:
device_ids = [0, 1]
net = torch.nn.DataParallel(net, device_ids=device_ids)四、多GPU训练---DataparallelDistributed(DDP)
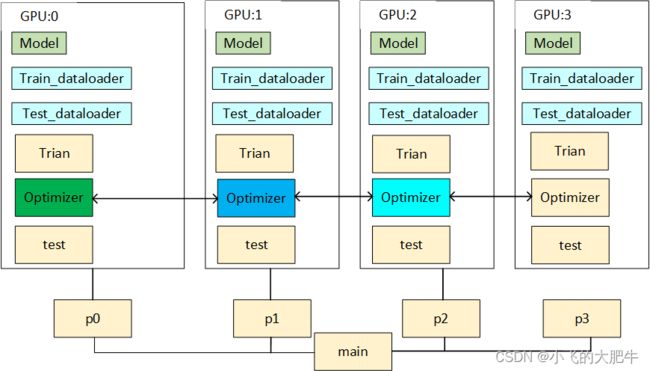
1、DDP的基本原理
DataparallelDistributed 在每次迭代中,操作系统会为每个GPU创建一个进程,每个进程具有自己的 optimizer ,并独立完成所有的优化步骤,进程内与一般的训练无异。在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由 rank=0 的进程,将其 broadcast 到所有进程。各进程用该梯度来更新参数。由于各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。
2、DDP的torch.distributed.launch启动版本
①定义启动DDP的函数setup_DDp()
def setup_DDP(backend="nccl", verbose=False):
rank = int(os.environ['RANK']) # 环境中变量,由命令行参数传入
local_rank = int(os.environ["LOCAL_RANK"])
world_size = int(os.environ["WORLD_SIZE"])
# If the OS is Windows or macOS, use gloo instead of nccl
dist.init_process_group(backend=backend)
# set distributed device
device = torch.device("cuda:{}".format(local_rank))
if verbose:
print("Using device: {}".format(device))
print(f"local rank: {local_rank}, global rank: {rank}, world size: {world_size}")
return rank, local_rank, world_size, device②在setup_DDp()启动的每个线程中编写类似单GPU的代码
# 启动ddp多个线程
rank, local_rank, world_size, device = setup_DDP(verbose=True)
# 线程之间对数据进行采样
train_sampler = DistributedSampler(training_data, shuffle=True)
test_sampler = DistributedSampler(test_data, shuffle=False)
#构造数据迭代器
train_dataloader = DataLoader(training_data, batch_size=batch_size, sampler=train_sampler)
test_dataloader = DataLoader(test_data, batch_size=batch_size, sampler=test_sampler)
# initialize model
model = NeuralNetwork().to(device)
model = DDP(model, device_ids=[local_rank], output_device=local_rank)
for t in range(epochs):
# 保证每个epoch各gpu可以取到不同的数据组,提高训练效果
train_dataloader.sampler.set_epoch(t)
test_dataloader.sampler.set_epoch(t)
# 只选取0号gpu上的数据进行输出,即是线程0的数据输出
print_only_rank0(f"Epoch {t + 1}\n-------------------------------") # [*]
train(train_dataloader, model, loss_fn, optimizer, device)
test(test_dataloader, model, loss_fn, device)③命令行启动格式
python3 -m torch.distributed.launch --nproc_per_node=4 multi_ppd_1.py3、DDP的torch.multiprocessing启动
①定义multiprocessing模式下的DDp启动函数
import torch.distributed as dist
def setup_DDP_mp(init_method, local_rank, rank, world_size, backend="nccl", verbose=False):
# If the OS is Windows or macOS, use gloo instead of nccl
dist.init_process_group(backend=backend, init_method=init_method, world_size=world_size, rank=rank)
# set distributed device
device = torch.device("cuda:{}".format(local_rank))
if verbose:
print("Using device: {}".format(device))
print(f"local rank: {local_rank}, global rank: {rank}, world size: {world_size}")
return device②定义命令行输入参数
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("--nodes", default=1, type=int, help="number of nodes for distributed training")
parser.add_argument("--ngpus_per_node", default=4, type=int, help="number of GPUs per node for distributed training")
parser.add_argument("--dist-url", default="tcp://127.0.0.1:12355", type=str, help="url used to set up distributed training")
parser.add_argument("--node_rank", default=0, type=int, help="node rank for distributed training")
return parser.parse_args()③定义main函数即主线程
def main(local_rank, ngpus_per_node, args):
args.local_rank = local_rank
args.rank = args.node_rank * ngpus_per_node + local_rank
# [*] initialize the distributed process group and device
# 此处函数的含义与上类似,启动多个线程
device = setup_DDP_mp(init_method=args.dist_url, local_rank=args.local_rank, rank=args.rank,
world_size=args.world_size, verbose=True)
# initialize data loader
# [*] using DistributedSampler
batch_size = 64 // args.world_size # [*] // world_size
train_sampler = DistributedSampler(training_data, shuffle=True) # [*]
test_sampler = DistributedSampler(test_data, shuffle=False) # [*]
train_dataloader = DataLoader(training_data, batch_size=batch_size, sampler=train_sampler) # [*] sampler=...
test_dataloader = DataLoader(test_data, batch_size=batch_size, sampler=test_sampler) # [*] sampler=...
# initialize model
model = NeuralNetwork().to(device) # copy model from cpu to gpu
# [*] using DistributedDataParallel
model = DDP(model, device_ids=[args.local_rank], output_device=args.local_rank)
# initialize optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
for t in range(epochs):
train_dataloader.sampler.set_epoch(t)
test_dataloader.sampler.set_epoch(t)
train()
test()④启动
# 第一个参数是函数自动生成并带入的
mp.spawn(main, nprocs=args.ngpus_per_node, args=(args.ngpus_per_node, args))五、总结(各分布式框架的优劣对比)
由于各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。而在 DataParallel 中,全程维护一个 optimizer,对各 GPU 上梯度进行求和,而在主 GPU 进行参数更新,之后再将模型参数 broadcast 到其他 GPU。相较于 DataParallel,torch.distributed 传输的数据量更少,因此速度更快,效率更高。