【Python】Python3网络爬虫实战-40、使用Selenium爬取淘宝商品
在前一章中,我们已经成功尝试分析Ajax来抓取相关数据,但是并不是所有页面都可以通过分析Ajax来完成抓取。比如,淘宝,它的整个页面数据确实也是通过Ajax获取的,但是这些Ajax接口参数比较复杂,可能会包含加密密钥等,所以如果想自己构造Ajax参数,还是比较困难的。对于这种页面,最方便快捷的抓取方法就是通过Selenium。本节中,我们就用Selenium来模拟浏览器操作,抓取淘宝的商品信息,并将结果保存到MongoDB。
1. 本节目标
本节中,我们要利用Selenium抓取淘宝商品并用pyquery解析得到商品的图片、名称、价格、购买人数、店铺名称和店铺所在地信息,并将其保存到MongoDB。学习过程中有不懂的可以加入我们的学习交流秋秋圈784中间758后面214,与你分享Python企业当下人才需求及怎么从零基础学习Python,和学习什么内容。相关学习视频资料、开发工具都有分享
2. 准备工作
本节中,我们首先以Chrome为例来讲解Selenium的用法。在开始之前,请确保已经正确安装好Chrome浏览器并配置好了ChromeDriver;另外,还需要正确安装Python的Selenium库;最后,还对接了PhantomJS和Firefox,请确保安装好PhantomJS和Firefox并配置好了GeckoDriver。如果环境没有配置好,可参考第1章。
3. 接口分析
首先,我们来看下淘宝的接口,看看它比一般Ajax多了怎样的内容。
打开淘宝页面,搜索商品,比如iPad,此时打开开发者工具,截获Ajax请求,我们可以发现获取商品列表的接口,如图7-19所示。
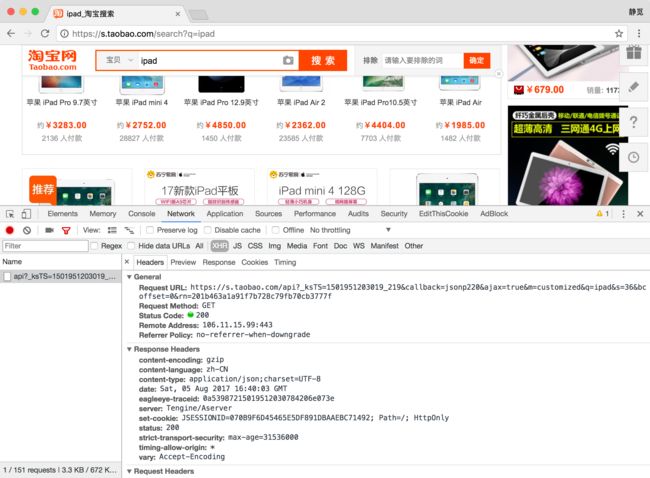
图7-19 列表接口
它的链接包含了几个GET参数,如果要想构造Ajax链接,直接请求再好不过了,它的返回内容是JSON格式,如图7-20所示。
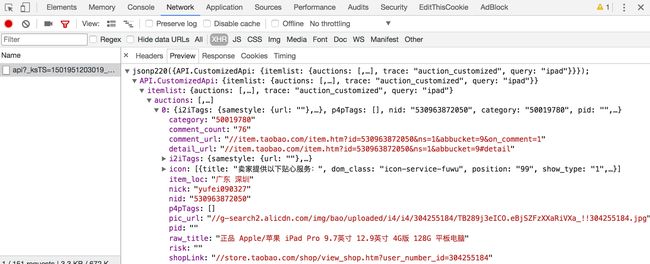
图7-20 JSON数据
但是这个Ajax接口包含几个参数,其中_ksTS、rn参数不能直接发现其规律,如果要去探寻它的生成规律,也不是做不到,但这样相对会比较烦琐,所以如果直接用Selenium来模拟浏览器的话,就不需要再关注这些接口参数了,只要在浏览器里面可以看到的,都可以爬取。这也是我们选用Selenium爬取淘宝的原因。
4. 页面分析
本节的目标是爬取商品信息。图7-21是一个商品条目,其中包含商品的基本信息,包括商品图片、名称、价格、购买人数、店铺名称和店铺所在地,我们要做的就是将这些信息都抓取下来。
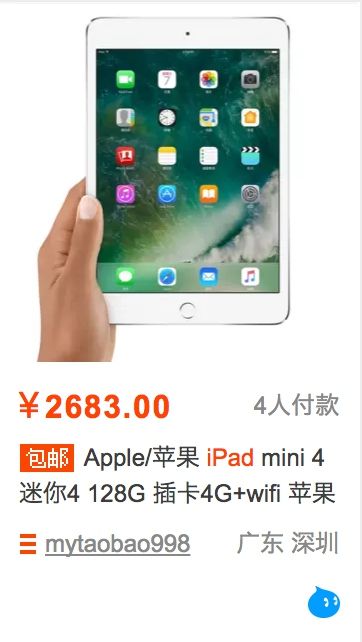
图7-21 商品条目
抓取入口就是淘宝的搜索页面,这个链接可以通过直接构造参数访问。例如,如果搜索iPad,就可以直接访问https://s.taobao.com/search?q=iPad,呈现的就是第一页的搜索结果,如图7-22所示。
图7-22 搜索结果
在页面下方,有一个分页导航,其中既包括前5页的链接,也包括下一页的链接,同时还有一个输入任意页码跳转的链接,如图7-23所示。