Java IO与文件读写
目录
-
-
- 一、从控制台输入
- 二、 获取当前代码运行的工作目录路径
- 三、判断文件、文件夹是否存在以及创建
- 四、判断文件夹下有多少个文件和文件夹
- 五、遍历获取文件夹下所有文件的路径和名称
- 六、获取文件名
- 七、获取文件大小
- 八、获取文件行数
- 九、获取文件扩展名(后缀)
- 十、获取文件的创建时间和最后修改时间
- 十一、文件重命名或移动文件
- 十二、复制文件夹(目录)
- 十三、常用的文件信息的获取和处理方法
- 十四、字节流与字符流的区别
- 十五、使用字节流读写文件
- 十六、使用字符流读写文件
- 十七、输入流转化为byte数组
- 十八、java8使用Files.readAllBytes()或Files.readAllLines优雅读文本文件
- 十九、java8优雅写文件
- 二十、使用字节流复制文件
- 二十一、java8使用Files.copy()复制文件
- 二十二、使用IOUtils优雅操作流(字符串与InputStream的转化)
- 二十三、 对象的序列化与反序列化
- 二十四、使用sftp进行服务器文件上传下载
- 二十五、图片大小转换
- 二十六、将图片BufferedImage转换为MultipartFile
- 二十七、文件压缩
- 二十八、InputStream、FileInputStream 转 byte[ ]
- 二十九、文本文件的InputStream、FileInputStream 转 String
- 三十、MultipartFile或byte[]转InputStream
- 三十一、文件转byte[]
- 三十二、ByteArrayOutputStream转文件
- 三十三、InputStream转文件
- 三十四、byte[]转文件
- 三十五、byte[]转String
-
一、从控制台输入
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String inputStr = null;
while ((inputStr = br.readLine())!=null) {
System.out.println(inputStr);
}
或使用Scanner:
Scanner scanner = new Scanner(System.in);
String inputStr = null;
while ((inputStr = scanner.next()) != null) {
System.out.println(inputStr);
}
/* Scanner scanner = new Scanner(System.in);
String inputStr = null; //输入字符串
if (scanner.hasNextLine()) {
String str2 = scanner.nextLine();
System.out.println(str2);
}
scanner.close();*/
next()和nextLine()区别:
- 1、nextLine()以Enter为结束符,也就是说 nextLine()方法返回的是输入回车之前的所有字符。
- 2、nextLine()可以获得空格。
判断输入的是整数还是小数:
Scanner scan = new Scanner(System.in);
// 从键盘接收数据
int i = 0;
float f = 0.0f;
System.out.print("输入数字:");
if (scan.hasNextInt()) {// 判断输入的是否是整数
i = scan.nextInt();
System.out.println("整数数据:" + i);
}
if (scan.hasNextFloat()) {// 判断输入的是否是小数
f = scan.nextFloat();
System.out.println("小数数据:" + f);
}
scan.close();
二、 获取当前代码运行的工作目录路径
System.out.println(System.getProperty("user.dir"));
三、判断文件、文件夹是否存在以及创建
- 判断文件是否存在,不存在则创建
String filePth= "F:/cc/test2.txt";
File file = new File(filePth);
if(!file.exists()){
System.out.println("文件不存在");
//创建文件,如果cc文件夹不存在会报错,所有要先检查文件前的文件夹路径是否存在,不存在要先创建文件夹,最后再创建文件
file.createNewFile();
}else {
System.out.println("文件存在");
}
- 判断文件夹是否存在,不存在则创建
String filePth= "F:/test/aa/bb";//判断bb文件夹是否存在
File folder = new File(filePth);
if (!folder.exists() && !folder.isDirectory()) {
folder.mkdirs(); //如果test下连aa文件夹也没有,会连同aa一起创建
System.out.println("创建文件夹");
} else {
System.out.println("文件夹已存在");
}
四、判断文件夹下有多少个文件和文件夹
String path = "D:\\video\\";
int fileCount = 0;
int folderCount = 0;
File d = new File(path);
File list[] = d.listFiles();
for(int i = 0; i < list.length; i++){
if(list[i].isFile()){
fileCount++;
}else{
folderCount++;
}
}
System.out.println("文件个数:"+fileCount);
System.out.println("文件夹数:"+folderCount);
五、遍历获取文件夹下所有文件的路径和名称
获取文件夹下所有文件,包括子文件夹下的文件路径:
方法一:
public static void main(String[] args) throws Exception {
String dir="D:\\迅雷下载\\layDate-v5.3.1";
Path path = Paths.get(dir);
List<Path> paths = listFiles(path);
paths.forEach(x -> System.out.println(x));
}
public static List<Path> listFiles(Path path) throws IOException {
List<Path> result;
try (Stream<Path> walk = Files.walk(path)) {
result = walk.filter(Files::isRegularFile).collect(Collectors.toList());
}
return result;
}
方法二:
public static void main(String[] args) {
String dir="D:\\迅雷下载\\layDate-v5.3.1";
List<String> result = getAllFilesPath(dir,new ArrayList<>());
for (String file:result){
System.out.println(file);
}
}
//获取文件夹下所有的文件路径
public static List<String> getAllFilesPath(String path, List<String> list) {
File file = new File(path);
File[] tempList = file.listFiles();
for (int i = 0; i < tempList.length; i++) {
String filePath = tempList[i].toString();
if(tempList[i].isFile()){
list.add(filePath);
}else{
//如果是文件夹则递归
getAllFilesPath(filePath,list);
}
}
return list;
}
输出:
D:\迅雷下载\layDate-v5.3.1\laydate\theme\default\font\iconfont.svg
D:\迅雷下载\layDate-v5.3.1\laydate\theme\default\font\iconfont.ttf
D:\迅雷下载\layDate-v5.3.1\laydate\theme\default\font\iconfont.woff
D:\迅雷下载\layDate-v5.3.1\laydate\theme\default\laydate.css
D:\迅雷下载\layDate-v5.3.1\test.html
D:\迅雷下载\layDate-v5.3.1\文档\官网.url
D:\迅雷下载\layDate-v5.3.1\文档\文档.url
D:\迅雷下载\layDate-v5.3.1\更新日志.url
获取绝对路径的文件名(获取的list里只有文件,没有文件夹):
public static List<String> getFilesList(String path){
List<String> list = new ArrayList<>();
File file = new File(path);
File[] tempList = file.listFiles();
for (int i = 0; i < tempList.length; i++) {
if (tempList[i].isFile()) {
list.add(tempList[i].toString());
}
}
return list;
}
测试:
String path = "D:\\video\\";
System.out.println(getFilesList(path)); //[D:\video\1.mp4, D:\video\2.mp4, D:\video\新建文本文档.txt]
获取相对路径的文件名(文件和文件夹都有):
File path = new File("D:\\ffmpegMedia\\");
//获取D:\ffmpegMedia\路径下的文件名和文件夹名
String fileNamePath[] = path.list();
for (String f : fileNamePath) {
System.out.println(f);
}
System.out.println("------------------------------------");
//获取D:\ffmpegMedia\路径下的文件名和文件夹名,返回类型为file类型
File[] files = path.listFiles();
for (File f : files) {
if (f.isFile()){
System.out.println(f.getName() + " ---> 是一个文件 " );
}
if (f.isDirectory()){
System.out.println(f.getName() + " ---> 是一个文件夹 " );
}
}
输出:
507-#网愈云故事收藏馆.mp4
aaa.mp3
pictur
temp
刻在我心底的名字-五月天.mp3
------------------------------------
507-#网愈云故事收藏馆.mp4 ---> 是一个文件
aaa.mp3 ---> 是一个文件
pictur ---> 是一个文件夹
temp ---> 是一个文件夹
刻在我心底的名字-五月天.mp3 ---> 是一个文件
list()和listFiles()区别:
- list()返回的是文件和文件夹字符串数组
- listFiles()返回的是文件和文件夹File数组,可以进行更多操作,如获取文件名、判断是否是文件等
六、获取文件名
File file = new File("F:/cc/test2.txt");
System.out.println(file.getName());//输出test2.txt
获取上传时的文件名:
String fName = file.getOriginalFilename(); //file的类型是MultipartFile
/*String fileName = fName.substring(fName.lastIndexOf("/")+1);
//或者
String fileName = fName.substring(fName.lastIndexOf("\\")+1);*/
七、获取文件大小
文件夹不适用,只能获取文件大小的整数位
public static void main(String[] args) throws IOException {
File path = new File("D:\\ffmpegMedia\\");
File[] files = path.listFiles();
for (File f : files) {
if (f.isFile()) {
System.out.println(f.getName() + " ---> 是一个文件 " + "文件大小:" + fileSize(f.length()));
}
if (f.isDirectory()) {
System.out.println(f.getName() + " ---> 是一个文件夹 "+ "文件大小:" + fileSize(f.length()));
}
}
}
/**
* 文件大小显示格式
*
* @param size
* @return
*/
private static String fileSize(long size) {
String[] units = new String[]{"B", "KB", "MB", "GB", "TB", "PB"};
double mod = 1024.0;
int i = 0;
for (i = 0; size >= mod; i++) {
size /= mod;
}
return Math.round(size) + units[i];
}
八、获取文件行数
针对可读文本文件获取行数:
Path path = Paths.get("D:/GoogleDown/attachment.java");
long lines = Files.lines(path).count();
System.out.println(lines);
九、获取文件扩展名(后缀)
public static String getFilesuffix(String fileName) {
String WINDOWS_FILE_SEPARATOR = "\\";
String UNIX_FILE_SEPARATOR = "/";
String FILE_EXTENSION = ".";
if (fileName == null) {
throw new IllegalArgumentException("fileName must not be null!");
}
String extension = "";
int indexOfLastExtension = fileName.lastIndexOf(FILE_EXTENSION);
int lastSeparatorPosWindows = fileName.lastIndexOf(WINDOWS_FILE_SEPARATOR);
int lastSeparatorPosUnix = fileName.lastIndexOf(UNIX_FILE_SEPARATOR);
int indexOflastSeparator = Math.max(lastSeparatorPosWindows, lastSeparatorPosUnix);
if (indexOfLastExtension > indexOflastSeparator) {
extension = fileName.substring(indexOfLastExtension + 1);
}
return extension;
}
测试:
//windows下
System.out.println(getFilesuffix("D:\\GoogleDown\\8r0AAAALgVL0r08D.docx"));
System.out.println(getFilesuffix("D:\\GoogleDown\\8r0AAAALgVL0r08D"));
//linux下
System.out.println(getFilesuffix("/var/local/test.pptx"));
System.out.println(getFilesuffix("/var/local/test"));
十、获取文件的创建时间和最后修改时间
String fileName = "D:\\GoogleDown\\8r0AAAALgVD0r08D.xls";
Path file = Paths.get(fileName);
//获取文件创建时间
FileTime creationTimeFileTime = (FileTime) Files.getAttribute(file, "creationTime");
Instant creationTimeInstant = creationTimeFileTime.toInstant();
//转化为当前计算机的默认时区
LocalDateTime creationTime = creationTimeInstant.atZone(ZoneId.systemDefault())
.toLocalDateTime();
//获取当前文件的最后修改时间
//转化为当前计算机的默认时区
Instant lastModifiedTimInstant = Files.getLastModifiedTime(file).toInstant();
LocalDateTime lastModifiedTim = lastModifiedTimInstant.atZone(ZoneId.systemDefault())
.toLocalDateTime();
System.out.println("文件创建时间是: " + creationTime);//文件创建时间是: 2022-11-08T15:06:08.537815
System.out.println("文件最后修改时间是: " + lastModifiedTim);//文件最后修改时间是: 2022-11-11T15:55:48.853570
十一、文件重命名或移动文件
//如果 toFile 和 fromFile 的文件目录一样,只有文件名不一样就是重命名文件
String fromFile = "D:\\GoogleDown\\myfile.ppt";
String toFile = "F:\\test\\aaaapusic.log.0";
Path source = Paths.get(fromFile);
Path target = Paths.get(toFile);
// 重命名文件或将文件移动到其他路径(如果文件已经存在替换)
Files.move(source, target, StandardCopyOption.REPLACE_EXISTING);
十二、复制文件夹(目录)
将一个文件夹下的所有文件,包括嵌套的子目录里的文件和文件夹复制到另一个目录 (jdk7及以后)
TreeCopyFileVisitor类:
import java.io.IOException;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
public class TreeCopyFileVisitor extends SimpleFileVisitor<Path> {
private Path source;
private final Path target;
public TreeCopyFileVisitor(String source, String target) {
this.source = Paths.get(source);
this.target = Paths.get(target);
}
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs) throws IOException {
Path resolve = target.resolve(source.relativize(dir));
if (Files.notExists(resolve)) {
Files.createDirectories(resolve);
System.out.println("Create directories : " + resolve);
}
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
Path resolve = target.resolve(source.relativize(file));
Files.copy(file, resolve, StandardCopyOption.REPLACE_EXISTING);
System.out.println(
String.format("Copy File from \t'%s' to \t'%s'", file, resolve)
);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult visitFileFailed(Path file, IOException exc) {
System.err.format("Unable to copy: %s: %s%n", file, exc);
return FileVisitResult.CONTINUE;
}
}
测试:
public static void main(String[] args) throws Exception {
//将F:\ydz目录下的所有文件和文件夹复制到 D:\test\ 下
String fromDirectory = "F:\\ydz\\";
String toToDirectory = "D:\\test\\";
copyDirectoryFileVisitor(fromDirectory, toToDirectory);
System.out.println("Done");
}
十三、常用的文件信息的获取和处理方法
File file = new File("F:/test/test2.txt");
System.out.println("文件是否绝对路径:" + file.isAbsolute());
System.out.println("取得文件的根目录:" + file.getParent());
System.out.println("文件是否存在:" + file.exists());
System.out.println("是否是目录:" + file.isDirectory());
System.out.println("是否是文件:" + file.isFile());
System.out.println("是否是隐藏文件:" + file.isHidden());
System.out.println("是否可读:" + file.canRead());
System.out.println("是否可写:" + file.canWrite());
System.out.println("删除文件:" + file.delete());
/*使用renameTo进行文件重命名目录路径要一致*/
File oldName = new File("F:/test/test2.txt");//重命名前的文件
File newName = new File("F:/test/test3.txt");//重命名后的文件
System.out.println("文件重命名:" + oldName.renameTo(newName));
/*使用renameTo进行文件移动,目录路径要不一致,文件名要一致*/
File oldName = new File("F:/test/hello.txt");
File newName = new File("F:/tex/hello.txt");
System.out.println("文件移动:" + oldName.renameTo(newName));
输出:
文件是否绝对路径:true
取得文件的根目录:F:\test
文件是否存在:true
是否是目录:false
是否是文件:true
是否是隐藏文件:false
是否可读:true
是否可写:true
删除文件:true
文件重命名:true
文件移动:true
十四、字节流与字符流的区别
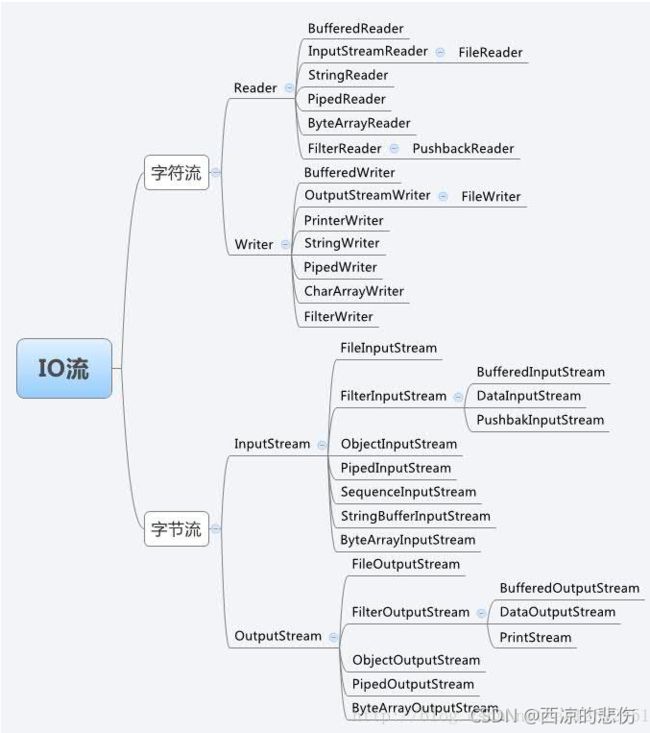
字节流:
1.字节流在操作的时候不会用到缓冲区(也就是内存)
2.字节流可用于任何类型的对象,包括二进制对象
3.字节流处理单元为1个字节,操作字节和字节数组。
InputStream是所有字节输入流的祖先,而OutputStream是所有字节输出流的祖先。
字符流:
1.而字符流在操作的时候会用到缓冲区
2.而字符流只能处理字符或者字符串
3.字符流处理的单元为2个字节的Unicode字符,操作字符、字符数组或字符串,
Reader是所有读取字符串输入流的祖先,而writer是所有输出字符串的祖先。
在硬盘上的所有文件都是以字节形式存在的(图片,声音,视频),而字符值在内存中才会形成。
所以字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的。
用字节流可以操作所有的文件,因为字节流在操作字符时,可能会有中文导致的乱码,所以由字节流引申出了字符流。图片,声音,视频等文件一般操作用字节流,文本等文件用字符流操作。
在从字节流转化为字符流时,实际上就是byte[]转化为String;
而在字符流转化为字节流时,实际上是String转化为byte[];
十五、使用字节流读写文件
-
读文本文件
FileInputStream file = new FileInputStream("F:/test/te.txt"); //读取文件为字节流 BufferedInputStream buf = new BufferedInputStream(file); //加入缓存区 int len = 0; byte[] bys = new byte[1024]; while ((len = buf.read(bys)) != -1) { //读取逐个字节数据到字节数组,读到末尾没数据了返回-1 System.out.println(new String(bys, 0, len, StandardCharsets.UTF_8)); //通过new String将字节数组转化为UTF_8编码的字符串输出 } file.close(); //关闭流 buf.close(); -
写文本文件
//true代表追加模式写入,没有参数true文件的内容会以覆盖形式写 FileOutputStream outputStream = new FileOutputStream("F:/test/te.txt", true); BufferedOutputStream buf = new BufferedOutputStream(outputStream); 加入缓存区 buf.write("hello".getBytes()); //hello转化为字节数组写入文件 buf.write("\n".getBytes()); //换行 buf.write(97); // 97代表字母a,将a写入文件 buf.write("\n".getBytes()); //换行 byte[] bys = {97, 98, 99, 100, 101}; buf.write(bys, 1, 3);//将98, 99, 100代表的bcd写入文件 buf.close(); //关闭流 outputStream.close();文件最终内容:hello
a
bcd -
文件转字节数组,字节数组转文件(文件的拷贝)
//img.jpg文件转字节数组bys
FileInputStream in = new FileInputStream("F:/img.jpg");//输入流
ByteArrayOutputStream bos=new ByteArrayOutputStream();
byte[] buffer=new byte[1024];
int len=0;
while((len=in.read(buffer))!=-1){ //输入流转读取到字节数组输出流
bos.write(buffer,0,len); //将字节数组buffer里的数据写入到bos字节数组输出流
}
in.close();
bos.flush();
byte[] bys = bos.toByteArray(); //bos字节数组输出流转化为字节数组bys
//字节数组bys转为文件img1.jpg(文件不存在会创建文件)。相当于利用img.jpg的字节数组bys复制了一张图片
String file="F:/img1.jpg";
FileOutputStream outputStream = new FileOutputStream(file);
BufferedOutputStream buf = new BufferedOutputStream(outputStream); //加入缓存区
buf.write(bys);//字节数组写入缓冲区输出流
buf.close(); //关闭流
outputStream.close();
十六、使用字符流读写文件
-
读文件
FileInputStream file = new FileInputStream("F:/test/te.txt"); //读取文件为字节流 InputStreamReader in = new InputStreamReader(file, "GBK"); //字节流转化为字符流,以GBK读取防止中文乱码 BufferedReader buf = new BufferedReader(in); //加入到缓存区 String str = ""; while ((str = buf.readLine()) != null) { //按行读取,到达最后一行返回null System.out.println(str); } buf.close(); file.close(); -
写文件
FileWriter f = new FileWriter("F:/test/te.txt", true); //文件读取为字符流,追加模式写数据 BufferedWriter buf = new BufferedWriter(f); //文件加入缓冲区 buf.write("hello"); //向缓冲区写入hello buf.write("\n"); //向缓冲区写入换行,或者采用buf.newLine(); buf.write("def"); //向缓冲区写入def buf.close(); //关闭缓冲区并将信息写入文件 f.close();为防止文件乱码你可以使用utf-8编码:
File file1 = new File("F:/test/te.txt"); Writer writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file1), StandardCharsets.UTF_8)); writer.write("要输入的字符串"); writer.flush(); writer.close();
十七、输入流转化为byte数组
FileInputStream in = new FileInputStream("F:/test/te.txt");//输入流
ByteArrayOutputStream bos=new ByteArrayOutputStream();
byte[] buffer=new byte[1024];
int len=0;
while((len=in.read(buffer))!=-1){ //输入流转读取到字节数组输出流
bos.write(buffer,0,len);
}
in.close();
bos.flush();
byte[] result=bos.toByteArray(); //输出流转化成byte数组
十八、java8使用Files.readAllBytes()或Files.readAllLines优雅读文本文件
- Files.readAllBytes读取文件为一个字符串:
byte[] data = Files.readAllBytes(Paths.get("F:/oracle_init.sql")); //获取文件转化为字节数组
String str= new String(data, StandardCharsets.UTF_8); //字节数组转化为UTF_8编码的字符串
//String str= new String(data, "GBK"); //上一行代码若有中文乱码,可改用此行代码
System.out.println(str); //输出文件内容
优化为一行代码:
String content = new String(Files.readAllBytes(Paths.get("F:/oracle_init.sql")), StandardCharsets.UTF_8);
System.out.println(content); //输出文件内容
注意:Files.readAllBytes(Path)方法把整个文件读入内存,此方法返回一个字节数组。在针对大文件的读取的时候,可能会出现内存不 足,导致堆溢出。所以大文件不推荐此方法读取。
- Files.readAllLines读取文件为一个List:
Files.readAllLines读取文件为一个List,List中每一个元素是一行的内容
//readAllLines默认使用utf-8格式读取
List<String> lines = Files.readAllLines(Paths.get("F:/zzz.txt") );
lines.forEach(v-> System.out.println(v));
有时候你的txt或者文档是GBK编码的,使用上面的readAllLines默认 utf-8 读取就会报错:
java.nio.charset.MalformedInputException: Input length = 1
这个时候你可以指定编码读取:
//你也可以指定其他编码,如:Files.readAllLines(Paths.get("F:/zzz.txt") , StandardCharsets.ISO_8859_1);
List<String> lines = Files.readAllLines(Paths.get("F:/zzz.txt") , Charset.forName("GBK"));
lines.forEach(v-> System.out.println(v));
注意:不适用读取大文件
- Files.write将List写入文件:
Path out = Paths.get("D:\\GoogleDown\\test.txt");//文件不存在会自动创建
List<String> arrayList = new ArrayList<> (Arrays.asList ( "a" , "b" , "c" ));//abc分别是三行的内容
Files.write(out,arrayList,Charset.defaultCharset());
十九、java8优雅写文件
文本文件:
//文件不存在会自动创建,true表示在文件末尾追加形式写入,false则覆盖写入
try {
PrintWriter writer = new PrintWriter(new BufferedWriter(new FileWriter("F:/ccc.txt", true)));
writer.println("777");
writer.println("888");
writer.close();
} catch (IOException e) {
System.err.println(e);
}
二进制文件(图片、音频等):
byte data[] = ...
FileOutputStream out = new FileOutputStream("F:/ccc.mp3");
out.write(data);
out.close();
二十、使用字节流复制文件
不使用缓冲区(不推荐):
FileInputStream inputStream = new FileInputStream("F:/test/te.txt"); //待复制的文件
FileOutputStream outputStream = new FileOutputStream("F:/new/te1.txt"); //要复制到的路径和文件名
byte[] bytes = new byte[1024];
int len = 0;
while ((len=inputStream.read(bytes)) != -1) { //读取待复制的文件到字节数组bytes
outputStream.write(bytes,0,len); //字节数组bytes的数据写入要复制到的文件
}
inputStream.close();
outputStream.close();
使用缓冲区(推荐):
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("F:/test/lv.mp4"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("F:/new/lv1.mp4"));
int len = 0;
byte[] bytes =new byte[1024];
while ((len=bis.read(bytes)) != -1) {
bos.write(bytes,0,len);
}
bis.close();
bos.close();
经测试使用缓冲区的复制和下面的使用Files.copy()复制速度最快,比较推荐。
二十一、java8使用Files.copy()复制文件
Path source = Paths.get("F:/oracle_init.sql"); //源文件路径
File f = new File("F:/test/new.sql"); //拷贝后的文件名和路径
f.createNewFile(); //创建一个空的new.sql, 如果test目录下已经存在new.sql原来的会被覆盖。
//复制文件
Files.copy(source, new FileOutputStream(f));
二十二、使用IOUtils优雅操作流(字符串与InputStream的转化)
需要导入包org.apache.commons.io
1.从流中读取数据
-
文件内容转换成List
FileInputStream fileInputStream = new FileInputStream(new File("F:/test/oracle_init.sql")); //也可以用下面的FileOutputStream的构造方法获取文件,比较简洁 //FileOutputStream fileInputStream = new FileOutputStream("F:/test/oracle_init.sql"); List<String> list = IOUtils.readLines(fileInputStream, "UTF-8");//只要是InputStream流都可以,比如http响应的流 for (String str : list){ //list中每个元素是一行 System.out.println(str); } -
文件内容转换成String
FileInputStream fileInputStream = new FileInputStream(new File("F:/test/oracle_init.sql")); String content = IOUtils.toString(fileInputStream,"UTF-8"); System.out.println(content); -
把流转换为byte数组
FileInputStream fileInputStream = new FileInputStream(new File("F:/test/oracle_init.sql")); byte[] bytes = IOUtils.toByteArray(fileInputStream); //只要是InputStream流都可以 -
byte数组转化为String
FileInputStream fileInputStream = new FileInputStream(new File("F:/test/oracle_init.sql")); byte[] bytes = IOUtils.toByteArray(fileInputStream); String str= new String(bytes, StandardCharsets.UTF_8);//若有中文乱码StandardCharsets.UTF_8改为"GBK" System.out.println(str); -
把字符串转换为InputStream
InputStream inputStream = IOUtils.toInputStream("aaaaaaa", "UTF-8"); -
InputStream 转换为 String
String result = IOUtils.toString(inputStream, StandardCharsets.UTF_8);参考:https://stackoverflow.com/questions/309424/how-do-i-read-convert-an-inputstream-into-a-string-in-java?rq=1
2.把数据写入流
//true为追加模式再文件末尾写内容把数据写入输出流
FileOutputStream outputStream = new FileOutputStream("F:/test/te.txt", true);
IOUtils.write("abc", outputStream,"GBK");//将abc写入文件,编码格式为GBK
outputStream.close();
3.文件拷贝
FileInputStream in = new FileInputStream(new File("F:/new/lv.mp4"));
FileOutputStream out = new FileOutputStream("F:/test/lv1.mp4");
IOUtils.copy(in, out);
in.close();
out.close();
把oracle_init.sql文件内容追加到te.txt末尾:
FileInputStream in = new FileInputStream(new File("F:/oracle_init.sql"));
FileOutputStream out = new FileOutputStream("F:/test/te.txt",true);
IOUtils.copy(in, out);
in.close();
out.close();
参考:Apache Commons IO之IOUtils优雅操作流
二十三、 对象的序列化与反序列化
序列化对象就是把对象转成字节数组,便于传输或存储。
反序列化对象就是将序列化后的字节数组再恢复成对象。
序列化对象方法:
/*对象转字节数组*/
public static byte[] serizlize(Object object){
ObjectOutputStream oos = null;
ByteArrayOutputStream baos = null;
try {
baos = new ByteArrayOutputStream();
oos = new ObjectOutputStream(baos);
oos.writeObject(object);
byte[] bytes = baos.toByteArray();
return bytes;
} catch (Exception e) {
e.printStackTrace();
}finally {
try {
if(baos != null){
baos.close();
}
if (oos != null) {
oos.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return null;
}
序列化对象方法:
/*字节数组转对象*/
public static Object deserialize(byte[] bytes){
ByteArrayInputStream bais = null;
ObjectInputStream ois = null;
try{
bais = new ByteArrayInputStream(bytes);
ois = new ObjectInputStream(bais);
return ois.readObject();
}catch(Exception e){
e.printStackTrace();
}finally {
try {
} catch (Exception e2) {
e2.printStackTrace();
}
}
return null;
}
实例:
public static void main(String[] args) throws IOException { Student st = new Student(2,"张三"); List<Integer> score=new ArrayList<>(); score.add(99); score.add(88); st.setScore(score); byte[] by = Test.serizlize(st);//对象转化为字节数组 /*字节数组写入文件*/ FileOutputStream outputStream = new FileOutputStream("F:/test/te.txt", true); BufferedOutputStream buf = new BufferedOutputStream(outputStream); 加入缓存区 buf.write(by);//将字节流写入文件 buf.close(); //关闭流 outputStream.close(); /*读取文件为字节数组*/ FileInputStream in = new FileInputStream("F:/test/te.txt");//输入流 ByteArrayOutputStream bos=new ByteArrayOutputStream(); byte[] buffer=new byte[1024]; int len=0; while((len=in.read(buffer))!=-1){ //输入流转读取到字节数组输出流 bos.write(buffer,0,len); } in.close(); bos.flush(); byte[] result=bos.toByteArray(); //输出流转化成byte数组 /*字节数组转成对象*/ Student st2 = (Student)deserialize(result); System.out.println(st2);//输出:id:2,name:张三,score:[99, 88],address:null }
二十四、使用sftp进行服务器文件上传下载
请参考我另一篇文章:
java 使用sftp从远程服务器上传下载删除文件
二十五、图片大小转换
-
通过url 获取图片流 BufferedImage 并转换大小
try { //通过url获取BufferedImage图像缓冲区 URL img = new URL("https://img1.360buyimg.com/image/jfs/t1/38591/20/3737/314695/5cc69c01E1838df09/dd6dce681bd23031.jpg"); BufferedImage image = ImageIO.read(img); //获取图片的宽、高 System.out.println("Width: " + image.getWidth()); System.out.println("Height: " + image.getHeight()); //调整图片大小为532x532尺寸 BufferedImage newImage = resizeImage(image,532,532); //图像缓冲区图片保存为图片文件(文件不存在会自动创建文件保存,文件存在会覆盖原文件保存) ImageIO.write(newImage, "jpg", new File("F:/test/pic1.jpg")); } catch (IOException e) { e.printStackTrace(); }resizeImage方法:
//通过BufferedImage图片流调整图片大小 public static BufferedImage resizeImage(BufferedImage originalImage, int targetWidth, int targetHeight) throws IOException { Image resultingImage = originalImage.getScaledInstance(targetWidth, targetHeight, Image.SCALE_DEFAULT); BufferedImage outputImage = new BufferedImage(targetWidth, targetHeight, BufferedImage.TYPE_INT_RGB); outputImage.getGraphics().drawImage(resultingImage, 0, 0, null); return outputImage; }其他可能会用到的方法:
//BufferedImage图片流转byte[]数组 public static byte[] imageToBytes(BufferedImage bImage) { ByteArrayOutputStream out = new ByteArrayOutputStream(); try { ImageIO.write(bImage, "jpg", out); } catch (IOException e) { log.error(e.getMessage()); } return out.toByteArray(); } //byte[]数组转BufferedImage图片流 private static BufferedImage bytesToBufferedImage(byte[] ImageByte) { ByteArrayInputStream in = new ByteArrayInputStream(ImageByte); BufferedImage image = null; try { image = ImageIO.read(in); } catch (IOException e) { e.printStackTrace(); } return image; } -
读取图片文件进行调整图片大小
try { //读取原始图片 BufferedImage image = ImageIO.read(new FileInputStream("F:/test/pic1.jpg")); System.out.println("Width: " + image.getWidth()); System.out.println("Height: " + image.getHeight()); //调整图片大小 BufferedImage newImage = resizeImage(image,200,200); //图像缓冲区图片保存为图片文件(文件不存在会自动创建文件保存,文件存在会覆盖原文件保存) ImageIO.write(newImage, "jpg", new File("F:/test/pic2.jpg")); } catch (IOException e) { e.printStackTrace(); }参考:How Can I Resize an Image Using Java?
二十六、将图片BufferedImage转换为MultipartFile
上面一条是将图片转为BufferedImage进行大小调整,有时候我们需要将BufferedImage转为MultipartFile进行上传等操作
方法一:
-
第一步:创建类实现MultipartFile接口
import org.springframework.web.multipart.MultipartFile; import java.io.*; public class ConvertToMultipartFile implements MultipartFile { private byte[] fileBytes; String name; String originalFilename; String contentType; boolean isEmpty; long size; public ConvertToMultipartFile(byte[] fileBytes, String name, String originalFilename, String contentType, long size) { this.fileBytes = fileBytes; this.name = name; this.originalFilename = originalFilename; this.contentType = contentType; this.size = size; this.isEmpty = false; } @Override public String getName() { return name; } @Override public String getOriginalFilename() { return originalFilename; } @Override public String getContentType() { return contentType; } @Override public boolean isEmpty() { return isEmpty; } @Override public long getSize() { return size; } @Override public byte[] getBytes() throws IOException { return fileBytes; } @Override public InputStream getInputStream() throws IOException { return new ByteArrayInputStream(fileBytes); } @Override public void transferTo(File dest) throws IOException, IllegalStateException { new FileOutputStream(dest).write(fileBytes); } } -
第二步:转换
//读取原始图片 BufferedImage image = ImageIO.read(new FileInputStream("F:/test/pic1.jpg")); //BufferedImage转MultipartFile MultipartFile multipartFile = new ConvertToMultipartFile(imageToBytes(image), "pic1", "myPicture", "jpg", imageToBytes(image).length);
方法二:
引入依赖:
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-testartifactId>
<version>5.3.2version>
<scope>compilescope>
dependency>
try {
//读取图片转换为 BufferedImage
BufferedImage image = ImageIO.read(new FileInputStream("F:/test/pic1.jpg"));
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ImageIO.write( newImage, "jpg", baos );
//转换为MultipartFile
MultipartFile multipartFile = new MockMultipartFile("pic1.jpg", baos.toByteArray());
} catch (IOException e) {
e.printStackTrace();
}
参考:How to convert BufferedImage to a MultiPart file without saving file to disk?
二十七、文件压缩
工具类:
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.util.List;
import java.util.Map;
import java.util.zip.ZipEntry;
import java.util.zip.ZipOutputStream;
public class ZipUtils {
/**
*
* 文件夹压缩成ZIP
*
* @param srcDir 压缩文件夹路径
* @param out 压缩文件输出流
* @param keepDirStructure 是否保留原来的目录结构,true:保留目录结构;
*
* false:所有文件跑到压缩包根目录下(注意:不保留目录结构可能会出现同名文件,会压缩失败)
*
* @throws RuntimeException 压缩失败会抛出运行时异常
*
*/
public static void toZip(String srcDir, OutputStream out, boolean keepDirStructure)
throws RuntimeException {
long start = System.currentTimeMillis();
ZipOutputStream zos = null;
try {
zos = new ZipOutputStream(out);
File sourceFile = new File(srcDir);
compress(sourceFile, zos, sourceFile.getName(), keepDirStructure);
long end = System.currentTimeMillis();
System.out.println("压缩完成,耗时:" + (end - start) + " ms");
} catch (Exception e) {
throw new RuntimeException("zip error from ZipUtils", e);
} finally {
if (zos != null) {
try {
zos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**
* 多文件压缩成ZIP
*
* @param imageMap 需要压缩的文件列表,键值对为 <文件名,文件的字节数组>,文件名必须包含后缀
* @param out 压缩文件输出流
* @throws RuntimeException 压缩失败会抛出运行时异常
*/
public static void toZip(Map<String, byte[]> imageMap, OutputStream out) throws RuntimeException {
long start = System.currentTimeMillis();
try (ZipOutputStream zos = new ZipOutputStream(out)) {
for (Map.Entry<String, byte[]> map : imageMap.entrySet()) {
zos.putNextEntry(new ZipEntry(map.getKey()));
zos.write(map.getValue());
zos.closeEntry();
}
long end = System.currentTimeMillis();
System.out.println("压缩完成,耗时:" + (end - start) + " ms");
} catch (Exception e) {
throw new RuntimeException("zip error from ZipUtils", e);
}
}
/**
* 多文件压缩成ZIP
* @param srcFiles 需要压缩的文件列表
* @param out 压缩文件输出流
* @throws RuntimeException 压缩失败会抛出运行时异常
*/
public static void toZip(List<File> srcFiles , OutputStream out)throws RuntimeException {
long start = System.currentTimeMillis();
try(ZipOutputStream zos= new ZipOutputStream(out)) {
for (File srcFile : srcFiles) {
byte[] buf = new byte[2048];
zos.putNextEntry(new ZipEntry(srcFile.getName()));
int len;
FileInputStream in = new FileInputStream(srcFile);
while ((len = in.read(buf)) != -1){
zos.write(buf, 0, len);
}
zos.closeEntry();
in.close();
}
long end = System.currentTimeMillis();
System.out.println("压缩完成,耗时:" + (end - start) +" ms");
} catch (Exception e) {
throw new RuntimeException("zip error from ZipUtils",e);
}
}
/**
*
* 递归压缩方法
* @param sourceFile 源文件
* @param zos zip输出流
* @param name 压缩后的名称
* @param keepDirStructure 是否保留原来的目录结构,true:保留目录结构;
*
* false:所有文件跑到压缩包根目录下(注意:不保留目录结构可能会出现同名文件,会压缩失败)
* @throws Exception
*/
private static void compress(File sourceFile, ZipOutputStream zos, String name, boolean keepDirStructure) throws Exception {
byte[] buf = new byte[2048];
if (sourceFile.isFile()) {
// 向zip输出流中添加一个zip实体,构造器中name为zip实体的文件的名字
zos.putNextEntry(new ZipEntry(name));
// copy文件到zip输出流中
int len;
FileInputStream in = new FileInputStream(sourceFile);
while ((len = in.read(buf)) != -1) {
zos.write(buf, 0, len);
}
// Complete the entry
zos.closeEntry();
in.close();
} else {
File[] listFiles = sourceFile.listFiles();
if (listFiles == null || listFiles.length == 0) {
// 需要保留原来的文件结构时,需要对空文件夹进行处理
if (keepDirStructure) {
// 空文件夹的处理
zos.putNextEntry(new ZipEntry(name + "/"));
// 没有文件,不需要文件的copy
zos.closeEntry();
}
} else {
for (File file : listFiles) {
// 判断是否需要保留原来的文件结构
if (keepDirStructure) {
// 注意:file.getName()前面需要带上父文件夹的名字加一斜杠,
// 不然最后压缩包中就不能保留原来的文件结构,即:所有文件都跑到压缩包根目录下了
compress(file, zos, name + "/" + file.getName(), keepDirStructure);
} else {
compress(file, zos, file.getName(), keepDirStructure);
}
}
}
}
}
}
-
测试:压缩多个文件(利用byte[]压缩)
import org.apache.commons.io.IOUtils; import utils.ZipUtils; import java.io.*; import java.util.HashMap; import java.util.Map; public class Test { public static void main(String[] args) { try { //读取图片转换为byte[] FileInputStream inputStream1 = new FileInputStream("F:/test/pic1.jpg"); byte[] bytes1 = IOUtils.toByteArray(inputStream1); //读取pdf转换为byte[] FileInputStream inputStream2 = new FileInputStream("F:/test/doc_20210203100237.pdf"); byte[] bytes2 = IOUtils.toByteArray(inputStream2); //读取txt转换为byte[] FileInputStream inputStream3 = new FileInputStream("F:/test/za.txt"); byte[] bytes3 = IOUtils.toByteArray(inputStream3); //三个文件存入picMap Map<String, byte[]> picMap = new HashMap<>(); picMap.put("pic1.jpg", bytes1); picMap.put("doc_20210203100237.pdf", bytes2); picMap.put("za.txt", bytes3); //定义输出流和最终生成的文件名,如;MyPic.zip FileOutputStream fileOutputStream = new FileOutputStream(new File("F:/test/MyPic.zip")); BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(fileOutputStream); //开始压缩 ZipUtils.toZip(picMap, bufferedOutputStream); } catch (IOException e) { e.printStackTrace(); } } }- 测试,压缩多文件文件(读取文件为byte[]压缩):
import java.io.*; import java.util.ArrayList; import utils.ZipUtils; import java.util.List; public class Test { public static void main(String[] args) { try { //要压缩的文件列表 List<File> fileList = new ArrayList<>(); fileList.add(new File("F:/test/pic1.jpg")); fileList.add(new File("F:/test/doc_20210203100237.pdf")); //压缩后的文件名和保存路径 FileOutputStream fos2 = new FileOutputStream(new File("f:/test/Myzip.zip")); //开始压缩 ZipUtils.toZip(fileList, fos2); } catch (FileNotFoundException e) { e.printStackTrace(); } } } -
压缩文件夹
import utils.ZipUtils; import java.io.*; public class Test { public static void main(String[] args) { try { //定义输出流和最终生成的文件名,如;保存到 F盘的 MyPic.zip FileOutputStream fileOutputStream = new FileOutputStream(new File("F:/Myfolder.zip")); BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(fileOutputStream); //开始压缩 F盘下的test文件夹 ZipUtils.toZip("F:/test", bufferedOutputStream,true); } catch (FileNotFoundException e) { e.printStackTrace(); } } }
参考:Java实现将文件或者文件夹压缩成zip
二十八、InputStream、FileInputStream 转 byte[ ]
利用Apache Commons IO库
InputStream is;
//FileInputStream is;
byte[] bytes = IOUtils.toByteArray(is);
参考:Convert InputStream to byte array in Java
二十九、文本文件的InputStream、FileInputStream 转 String
利用Apache Commons IO库
StringWriter writer = new StringWriter();
IOUtils.copy(inputStream, writer, encoding);
String theString = writer.toString();
参考:How do I read / convert an InputStream into a String in Java?
三十、MultipartFile或byte[]转InputStream
//multipartFile获取文件byte[]
byte[] bytes = multipartFile.getBytes();
//byte[]转 InputStream
InputStream in = new ByteArrayInputStream(bytes);
三十一、文件转byte[]
方法一:
(jdk7以前)
File file = new File("F:/oracle_init.sql");
FileInputStream fl = new FileInputStream(file);
byte[] arr = new byte[(int)file.length()];
fl.read(arr);
fl.close();
方法二:
(jdk7及以后)
File file = new File("F:/oracle_init.sql");
byte[] bytes = Files.readAllBytes(file.toPath());
//byte[] bytes = Files.readAllBytes(Paths.get("F:/oracle_init.sql"));
方法三:
(使用apache.commons.io库):
File file = new File("F:/oracle_init.sql");
byte[] bytes = FileUtils.readFileToByteArray(file);
三十二、ByteArrayOutputStream转文件
如果你有一个字节数组输出流想把它写入文件或转为文件可如下:
ByteArrayOutputStream byteArrayOutputStream = getByteStreamMethod();
try(OutputStream outputStream = new FileOutputStream("thefilename")) {
byteArrayOutputStream.writeTo(outputStream);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
测试:
public static void main(String[] args) throws IOException {
//img.jpg文件转字节数组bys
FileInputStream in = new FileInputStream("F:/te.txt");//输入流
ByteArrayOutputStream bos=new ByteArrayOutputStream();
byte[] buffer=new byte[1024];
int len=0;
while((len=in.read(buffer))!=-1){ //输入流转读取到字节数组输出流
bos.write(buffer,0,len); //将字节数组buffer里的数据写入到bos字节数组输出流
}
in.close();
bos.flush();
//ByteArrayOutputStream里的数据写入文件F:/test1.txt
try(OutputStream outputStream = new FileOutputStream("F:/test1.txt")) {
bos.writeTo(outputStream);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
三十三、InputStream转文件
InputStream in = ...;
FileOutputStream out = new FileOutputStream("F:/test1.txt");
byte[] buffer = new byte[1024];
int read;
while ((read = in.read(buffer)) != -1) {
out.write(buffer, 0, read);
}
out.close();
或者利用Apache Commons IO库:
InputStream = sftpUtil.downloadFile();
File file = new File("D:\\abcdf.mp4");
FileUtils.copyInputStreamToFile(in, file);
三十四、byte[]转文件
byte[] bytes = ... ;
try (FileOutputStream fos = new FileOutputStream("F:/test1.txt")) {
fos.write(bytes);
}
或者利用Apache Commons IO库:
byte[] bytes = ...;
FileUtils.writeByteArrayToFile(new File("pathname"), bytes);
三十五、byte[]转String
如果字节数组是存储的文本类型的数据,可如下转为一个字符串:
byte[] encoded = ... ;
String str = new String(encoded, StandardCharsets.UTF_8);
参考:
Java I/O Tutorial
java基础io流——OutputStream和InputStream的故事(温故知新)
Java:字节流和字符流(输入流和输出流)
Java IO流操作汇总: inputStream 和 outputStream
JAVA中字符流详解
字符流与字节流的区别
使用sftp上传下载删除文件,创建文件夹