Mysql只看这一篇就够啦
目录
(注意!这只是我本人自己对sql的理解,是个小白,大佬随便看看就好了)
一)mysql基本语法
二)聚合函数
三)其他语法
on 和where 的区别
四)join连接之7种连接
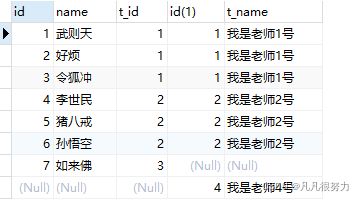
首先我们建立两张表如下
1.内连接
2.左内连接
3.右内连接
4.左外连接
5.右外连接
6.全连接
7.全外连接
五)查询语句
六)子查询
七)半连接
八)sql优化
mysql逻辑分层
我们为什么要优化?
sql:
索引
创建索引
删除索引
查询索引
sql性能问题
(1)id
(2) select_type
(3)type:
(4)possible_keys
(5)key
(6)key_len
(7)ref
(8)rows
(9) Extra
单表查询优化小结:
索引失效
注意
一些其他的优化方法
(注意!这只是我本人自己对sql的理解,是个小白,大佬随便看看就好了)
一)mysql基本语法
show databases 显示数据库
user + 数据库名 使用数据库
show tables 查看数据库里的所有表(注意要和user+数据库名一起用)
show tables from + 数据库名 (查看数据库里的所有表)
create table + 表名(数据类型,表名) 创建数据表
desc + 表名 查看表结构
二)聚合函数
count 计数
sum 求和
max 最大值
min 最小值
avg 平均值
三)其他语法
group_concat() 一般和group by 在一起使用,如果条件相等,返回数据用逗号隔开
distinct 去重
case when then 相当于java里的if else 用法一样
if else 一样,也是判断
join 连接 两个数据库连接
on 和join一起使用删除多余的数据,和where 用法差不多,但是不一样
union 连接并且去重
unionAll 连接两个表,但是不去重
as 是的意思,比如:from student as s1 给student起个别名,也可以不加
not in 代表的是不在这里面的值的信息
offset 和limit一起使用:跳过几行元素
比如 limit 1 offset 1 意思就是 跳过第一行 然后limit 表示取第一条记录
isnull ISNULL函数是MySQL控制流函数之一,它接受两个参数,如果不是NULL,则返回第一个参数。 否则,IFNULL函数返回第二个参数。
cancat 拼串
find_in_set 函数,判断包不包含此字段
find_in_set(#{projectid},projects)
on 和where 的区别
on是建立关联关系,where是对关联关系的筛选
如果条件中同时有on和where 条件:
SQL的执行实际是两步
第一步:根据on条件得到一个临时表
第二步:根据where 条件对上一步的临时表进行过滤,得到最终返回结果。
如果条件中只有on:
那么得到的临时表就是最终返回结果
四)join连接之7种连接
首先我们建立两张表如下
学生表
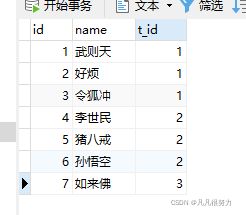
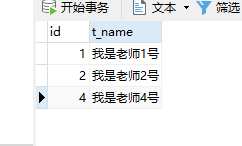
老师表
1.内连接
join
select * from student join teacher on student.t_id = teacher.id
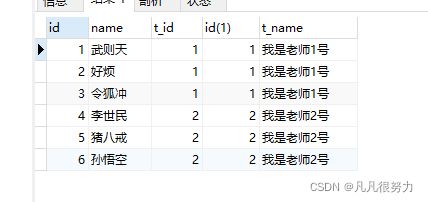
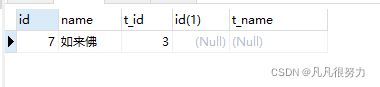
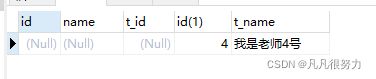
可以看到stu表里的id为7的如来佛没有输出,teacher表里的我是老师4号也没有输出
那是因为如来佛的t_id = 3 ,没有找到对应的,并且teacher表里的老师4号的id为4,而stu表里没有t_id 没有4
内连接只会查到a表和b表共有的数据
其中stu表的t_id 对应 teacher表的id
2.左内连接
left join
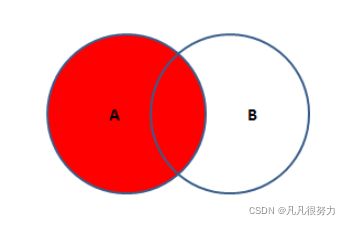
select * from student left join teacher on student.t_id = teacher.id
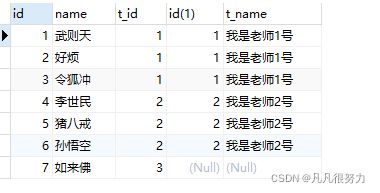
左内连接如图所示,能查到左表的所有数据,如果右表没有条件匹配的则为null
3.右内连接
right join
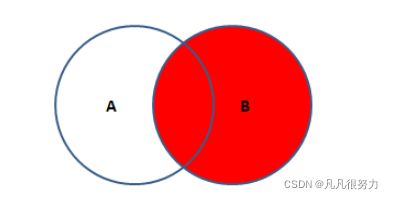
select * from student right join teacher on student.t_id = teacher.id
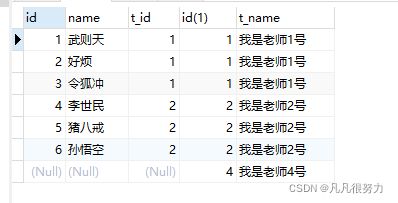
右内连接如图所示,能查到右表的所有数据,如果做表没有条件匹配的则为null,和left join正好相反
4.左外连接
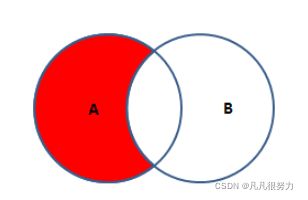
select * from student left join teacher on student.t_id = teacher.id where teacher.id is null
注意不能是 =null 必须是is null
左外连接:看图就相当于 左内连接 减去内连接,就得到了左外连接,具体看我写的sql,
一个左内连接,再加一个where 条件 teacher.id is null 相当于把内连接的数据全部给筛选掉了
这是一种思路!
还可以全连接减去右内连接 ,但是mysql我没这么写过,之前学过hive 可以这么实现
sql是很灵活的,一个功能右很多种实现方法,当然只不过是效率高低,sql复杂与简单罢了
当然我们要学会最简单的写法,我们要有这种思维能力
5.右外连接
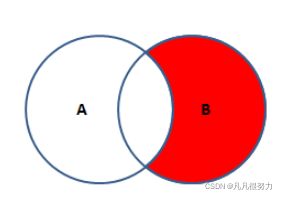
select * from student right join teacher on student.t_id = teacher.id where student.t_id is null
右外连接:右内连接 减去内连接,就得到了右外连接,和左外连接思路一样
6.全连接
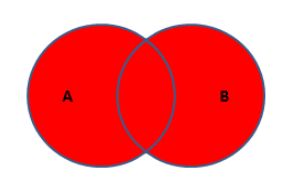
select * from student left join teacher on student.t_id = teacher.id
union
select * from student right join teacher on student.t_id = teacher.id
上面这张图表示的是两张表的所有部分。就是左外连接+右外连接在去重一次就搞定了(全连接,mysql中不支持,oracle中是支持的)。虽然MySQL不支持全连接的直接实现方式,但是提供了间接的实现方式,就是A表独有+B表独有,在去重一次。
union是连接并且去重
7.全外连接
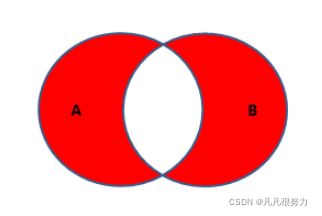
select * from student left join teacher on student.t_id = teacher.id where teacher.id is null
union
select * from student right join teacher on student.t_id = teacher.id where student.t_id is null

mysql还是不支持,但是可以用union写,就是左外连接+右外连接同样的套路
7种join知道就行了,后面的很少用,用的最多的就是join 和left join 和right join
五)查询语句
查询语句语法:select ... from ... where .... group by .... having... order by.....limit
where 里是条件
group by 是分组
having 是过滤
order by 是排序
limit是截取 一般用于分页
他们的执行顺序是:from– on-join-where–group by-select–having-order by-limit
group by 在实现的时候 会进行排序 默认是升序 升序asc 降序desc
我们这里只说查询,其他没什么好说的
六)子查询
为什么要使用子查询?
1、方便理解。
2、实现更复杂的查询。
3、提高查询效率。
现在有两张表:
stu学生表
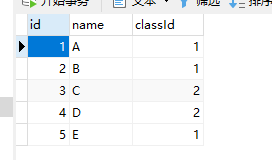
class班级表
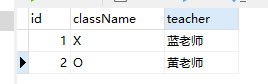
问题:我要查找老师为蓝老师的学生所有信息
join怎么写:
select stu.id,stu.`name`,stu.classId from stu join class on stu.classId = class.id where class.teacher = '蓝老师'
子查询怎么写:
select * from stu where classId = (select id from class where teacher = '蓝老师')
两个输出结果是一样的,但是看子查询思路是不是瞬间清晰很多,但其实join的效率是要比子查询要高的,在我理解看来,所有子查询能办到的事情,都可以通过join来实现,个人还是比较喜欢使用join
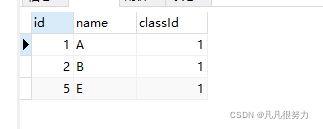
那么问题来了
select * from stu where classId = (select id from class where teacher = '蓝老师')
这条sql真的对吗?
我往表里加一条数据


运行同样的sql为什么报错了呢?那是因为:
子查询里的查询如果用等于号的话只能返回一个条件,即stu.classId = (select id from class where class.manager = '蓝老师') ,而蓝老师必须是唯一的

我们把=号改成in就好了
如果用in的话,可以返回一列数据
这种是在where条件里写子查询,那还可以怎么写呢,同样的问题
select stu.id,stu.`name`,stu.classId from stu join (select id from class where class.teacher = '蓝老师') as c on stu.classId = c.id
输出结果也是一样的,但是注意了,在from里的子查询必须要加别名,否则就报错啦
可以在select里写子查询
可以在having里写子查询(不常见,基本没写过,但是可以实现)
可以在on里写子查询(不常见,基本没写过,但是可以实现)
我这里就不一一举例啦
七)半连接
什么是半连接?
半连接就是当你的子查询用到你父查询里的数据的时候就是半连接
我们来举例说明,还是上面的stu表
问题:我们要查询每个classId里的学生id最大的那个学生姓名
怎么写?
看到每个classId最大,是不是想到聚合函数max,还有group by 分组
select max(id) from stu group by classId 输出如下
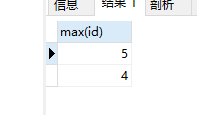
对面上面的stu表 ,我们是不是拿到每个班级最大的学生的id了呢,只需要再给他嵌套一层查询,就可以查到他的姓名了
select * from stu where id in (select max(id) from stu group by classId)
这里为什么要用in还记得吗?因为他的上面返回的max是一列数据,而不是一个数据,所以不能用=号,输出如下
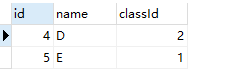
为了方便大家看,我就全部输出出来了
那用半连接怎么实现呢
select * from stu as s1 where id =(select max(id) from stu s2 where s2.classId = s1.classId)
输入同上,这点有点绕,我相信有的小伙伴看到这点已经很懵逼了
(select max(id) from stu s2 where s2.classId = s1.classId) 你看这个子查询里
先查到最大的id,那条件是什么呢?是不是你子查询里的class id 等于你父查询的 class id,
那是不是就拿到了所有的classId的最大id值,然后外面的where 条件,id就等于最大id值
但是注意!一定要起别名,因为你的子查询和父查询都是查的一个表,所以必须要起别名
不然mysql也会像你一样,蒙蒙的

然后就报错了哦
细心的小伙伴有没有发现,其实半连接就相当于替代了分组,总归一句话
半连接就是当你的子查询用到你父查询里的数据的时候就是半连接
八)sql优化
mysql逻辑分层
连接层: 提供与客户端连接的服务
服务层: 1.提供各种用户使用的接口,
2.提供sql优化器
引擎层: 提供各种存储数据的方式 InnoDB,Myisam
InnoDB(mysql默认引擎):事务优先,适合高并发操作 行锁
Myisam:性能优先 表锁
存储层: 存储数据
我们为什么要优化?
1.性能低,
2.执行时间太长
3.等待时间太长
4.sql语句欠佳,索引失效
5.服务器参数设置不合理
sql:
编写过程:
select..from..join..on..where..group by..having..order by..limit..
编析过程:
from– on-join-where–group by-having-select-order by-limit
索引
深度探讨索引原理
什么是索引?
索引:就是用什么样的方式,能更快,更容易的检索内容,就是如何更快速的找到你想要的数据
检索数据
就比如一个list集合 [ 1,30,50,60,80,100],每个数据都有自己的index,就是索引,并不是只有数据库再用,而是各处都在用
找到一个数据,所需要的对比次数的期望是多少?期望就是平均值的意思

如果想拿到1,list.get[0]就可以了
1+2+3+4+5+6+7=28 28/7=4 平均值就是4步
假设list长度是n,请问要找多少次,就相当于1+2+3......+n
就相当于(1+n)+(2+n-1)..... * (n/2) 大概率要找2分之n次
顺序查找不需要有序,但是效率很慢
b树和b+树哪个好,很多人都理解不了为什么b+树比b数好
内存是分页的,他是一块一快存储的,在磁盘上也是一块一块存储的
1.在磁盘里把一块内容放到内存中是非常快的
2.当我们把一块东西放到内存是比较快的时候,我们去获取索引的时候,它只包含索引数据,而不包含具体其他数据,只有到叶子节点,他才会包含其他数据,好处是什么,就是我们整个索引它所占的存储空间就会比b树小很多,所以他会更容易的放到我们的内存里面,更容易放进去,所以更快
mysql的索引用的就是b+
索引是帮助mysql高效获取数据的排好序的数据结构
数据分的越开,建立的索引就越好
其实sql优化,主要就是在优化索引
索引:就相当于书的目录
索引的关键字index 他是帮助mysql高效获取数据的数据结构,索引是数据结构(B树,Hash树)
B树:遵循一个原则:小的放左,大的放右
这里我们不探讨数据结构,有兴趣的可以自己去看看
索引的弊端:
1.索引本身很大,可以存放在内存/硬盘里
2.索引不是适合所有的情况均使用:a.少量数据 b.频繁更新字段c.很少使用的字段
3.所有提高查询效率,降低增删改的效率
索引的优势:
1.提高查询效率(降低io使用率)
2.降低CPU使用率
三层Btree可以存放上百万条数据
索引是帮助mysql高效获取数据的排好序的数据结构
索引分为:
单值索引: 单列,比如给age加索引,一个表可以有多个单值索引
唯一索引:不能重复 比如:id
复合索引:多个列构成的索引(相当于二级目录)可以有多个列
创建索引
1)create 索引类型 索引名 on 表(字段)
单值索引举例: create index 索引名 on 表名(字段);
唯一索引举例: create unique index 索引名 on 表名(字段);
复合索引举例:create index 索引名 on 表名(字段1,字段2);
2)alter table 表名 add 索引类型 索引名(字段)
单值索引举例: alter table 表名 add index 索引名(字段);
唯一索引举例: alter table 表名 add unique index 索引名(字段);
复合索引举例:alter table 表名 add index 索引名(字段1,字段2);
DDL语句会自动提交,不需要commit;
注意事项
如果一个字段是主键,他自动就是主键索引
主键一定是索引,但是索引不一定是主键
主键不能为null,唯一索引可以为null
删除索引
drop index 索引名 on 表名;
举例:drop index 索引名 on stu;
查询索引
show index from 表名
其实个人感觉这些没啥用,navicat可视化做的很不错了,都可以直接查看操作,删除
但是创建索引的时候我还是习惯用sql,比较方便
sql性能问题
分析sql的执行计划:
explain 可以模拟SQL优化器执行sql语句,从而让开发人员知道自己编写的sql状况

explain+自己写的sql语句就可以了,这是一个关键字
我们一个一个看
(1)id
1) 执行计划id相同时:数据小的表优先查询
2) id不相同时候:在嵌套子查询时,先查询最内层,
3)id又相同又不同,id值越大越优先,id值相同从上往下,顺序执行
(2) select_type
1).primary:包含子查询sql中的主查询(最外层)
2) subquery:包含子查询sql中的子查询(非最外层)
3).simple:简单查询,不包含子查询
4).derived:衍生查询(使用到了临时表)
5).union
6).union result:告知开发人员,哪张表存在union关系
(3)type:
优化级别
system>const>eq_ref>ref>range>index>all
2)system:只有一条数据的系统表,或衍生表只有一条数据的主查询,基本达不到
3)const:仅仅能查到一条数据的sql,用于Primary key 或unique 索引 (主键或者伪意见)
4) eq_ref:唯一性索引:对于每个索引键的查询,返回匹配唯一行数据,(有且只有一个)
5) ref:非唯一性索引,对于每个索引键的查询。返回匹配的所有行。
6) range:检索指定范围的行,where后是一个范围查询(between 》 《 = in{in有时候会失效})
7)index:查询全部索引中的数据
8)all:查询全部表中的数据
(4)possible_keys
可能用到的索引,不准
(5)key
实际用到的索引
(6)key_len
索引的长度
作用:判断复合索引是否被完全使用
一个字节表示null
两个字节表示可变长(varchar)
utf8:一个字符三个字节
dbk:一个字符两个字节
latin:一个字符一个字节
(7)ref
注意与type中的ref值区分。
作用:指明当前表所 参照的 字段。
举例:select ..where a.c = b.x(其中b.x可以是常量,const)
(8)rows
表示在SQL执行过程中会被扫描的行数,该数值越大,意味着需要扫描的行数,相应的耗时更长。但是需要注意的是EXPLAIN中输出的rows只是一个估算值,不能完全对其百分之百相信,如EXPLAIN中对LIMITS的支持就比较有限。
(9) Extra
1)using filesort :性能消耗大,需要二娃的一次排序(查询)(九死一生的提示,需要尽快优化)
对于单索引,如果排序和查找是同一个字段,则不会出现using filesort
复合索引:不能跨列(最佳左前缀)
2)using temporary:性能损耗大,用到了临时表一般出现在group by 中 (十死无生的提示,极大影响mysql性能,需要尽快优化)
3)using index :性能提升;索引覆盖
原因:此sql不读取源文件,只从索引文件中获取数据,只要使用到的列,全部都在索引中,就是索引覆盖 using index
4)using where 表示需要回原表
5.using join buffer 表示你写的sql太差了,给你加了个缓存,作用:mysql引擎使用了连接缓存
单表查询优化小结:
1.索引不能跨列使用,保持顺序的一致性
2.索引需要逐步优化
3.将包含in的范围查询 放到where最后,防止前面的也失效
两表查询优化小结:
1.小表驱动大表,小表放左边,大表放右边(where 小表.x = 大表.y)
2.索引建立在经常使用的字段上
三表查询优化小结:
1.小表驱动大表
2.索引建立在经常使用的字段上
索引失效
1.复合索引,不要跨列或无序使用(最佳左前缀)
2.复合索引,尽量使用全索引匹配
3.不要在索引上进行任何操作(计算,函数,类型转换)
4.复合索引,不能使用!= < > 或者is not null,否则自身及右侧所有全部失效
注意
我们学习索引优化,是一个大部分情况使用的结论,但由于sql优化器等原因,改结论不是百分之百正确,一般而言,范围查询(< > in )之后的索引失效
一些其他的优化方法
1.exist 和 in
如果主查询的数据集大,就用in
如果子查询的数据集大,就用exist
exist语法:将主查询的结果,放到子查询中进行校验(看子查询是否有数据,则校验成功)
例子:select name from stu where exist(select * from stu)
2.order by 优化
using filesort 有两种算法:双路排序,单路排序(根据io次数)
mysql4.1之前 默认使用 双路排序(扫码两次磁盘就是双面排序)先扫描排序字段,再对排序字段进行排序,再扫描其他字段,io比较消耗性能
mysql4.1之后 默认使用单路排序(只读取一次,在buffer中进行排序)
调整buffer:set max_lenth_for_sort_data
3.提高order by 查询策略:
1.选择使用单路,双路,调整buffer大小
2.避免使用select * ;
慢查询和锁这里就不说了,因为我自己也用的很少,基本没有用过
触发器也不说了,基本不用,缺点感觉很明显,最后祝大家都成为大佬!