R count函数_【SQL】SQL面试50题思路解答与分类整理(中)窗口函数与子查询
题目快速查找索引
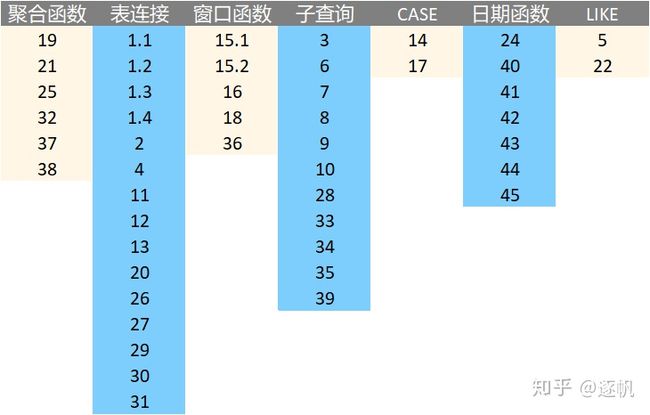
阅读指南
上篇
-
- 【第一部分】聚合函数(sum/avg/count/min/max)
- 【第二部分】表连接(inner join/left join/right join/full join/exclude join)
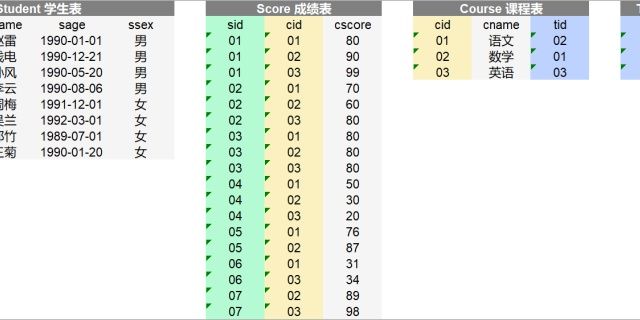
中篇
-
- 【第三部分】窗口函数+Limit+变量(rank/dense rank/row number)
- 【第四部分】子查询
下篇
-
- 【第五部分】CASE
- 【第六部分】日期函数
【第三部分】窗口函数+Limit+变量
知识要点与易错点总结
在MySQL中,Limit用于指定要返回的记录数量
- Limit有两个参数,前一个数字是开始行号,后一个数字是限制条数
- 例1:Limit 2,1 指的是从第2行开始,再多选择1行,也就是说只选了第3行
- 例2:Limit 3 指的是选择前3条记录,也就是说省略了第二个参数
因为SQL不能Group by以后取Limit,所以为了进行每组内排名,就需要用到窗口函数了,常见使用场景例如:
- 排名问题:显示各科成绩的排名
- TopN问题:按照总成绩进行排名,并奖励班级前三名
窗口函数的语法规则如下:
<窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名>)
- <窗口函数>的位置,可以写以下两种函数:
- 1. 窗口函数,包括rank, dense_rank, row_number等
- 2. 聚合函数,如sum, avg, count, max, min等
- 解释一下几个主要的窗口函数:
- rank() 是跳跃排序,两个并列第二名下来就是第四名,即1,2,2,4,5
- dense_rank() 是连续排序,两个并列第二名后仍然跟着第三名,即1,2,2,3,4
- row_number() 是没有重复值的排序,可以利用它来实现分页,永远是1,2,3,4,5(即使原本的数据有重复值)
- 注意:因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中
窗口函数题目整理(完整题目列表见文章最后)
【18. 查询各科成绩前三名的记录】
#保留名次空缺
- 查询各科成绩前三名,是典型TopN问题
- 窗口函数只能用在select后面,不能用在where后面,所以要先写子查询,并且子查询产生的表需要有命名,例如t1,否则会报错
- rank() 函数保留名次空缺,即有重复名次时会跳过,两个第二名并列时显示1,2,2,4,5
- dense_rank() 函数不保留名次空缺,两个第二名并列时显示1,2,2,3,4
- Partition by后用课程cid分组,Order by后用分数cscore排名
【15.1 按各科成绩进行排序,并显示排名, 成绩重复时保留名次空缺】
***相比上一题【18. 查询各科成绩前三名的记录】,这里不但需要显示排名,还需要显示各科成绩,所以用窗口函数显示排名是最简单的方法
解法1:窗口函数
#解法1:窗口函数
- 保留名次空缺,使用rank函数,以课程编号cid分组,按分数cscore排名
- rank函数在有重复值时使用跳跃排序,即有并列第二时,显示1,2,2,4,5
解法2:表连接查询
如果不用rank函数,写法就相对复杂一点了,下面是思路分析
第一步:初步排名
#初步排名
- 为了对每个学生的各科成绩排序,可以把成绩表自交,用课程编号cid来连接两个score表(因为是对比课程的成绩)
- join条件是当cid相同的时候,左表成绩<右表成绩,注意这里的AND连接符
- 最后注意Order by的条件,之所以先按sid排序,后按cid排序,是为了能看到同一个学生的每一节课的成绩排行
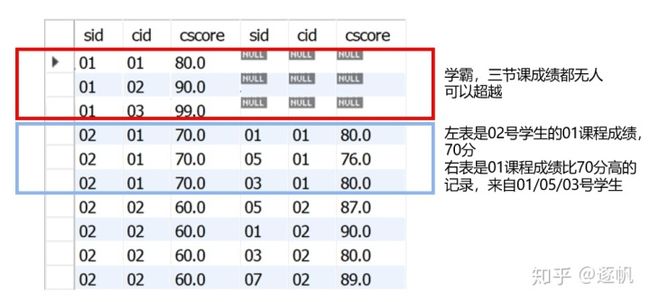
- 结果为sid=01号学生,他的1/2/3三门课的成绩在右表都是null,也就是说没有其他人的成绩比他高,学霸实锤
- 结果为sid=02号学生,对于cid 01课程,右表有01/05/03三个同学的cid 01课成绩比他高;对于cid 02课程,右表有05/01/03/07四个同学的cid 02课成绩比他高;以此类推
第二步:加入学生名次
#最终代码
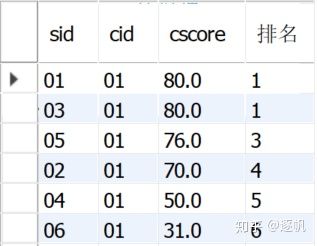
- 对于sid=01号学生,右表数据都是null,所以对于第一行到第三行,count(t2.cscore)都是null,所以排名为 count(t2.cscore)+1 = 1,即第一名
- 对于sid=02号学生,cid=01课程的右表有三行,即三个同学成绩比他高,所以sid 02号的排名为 count(t2.cscore)+1 = 3+1 = 4,即第四名
- 所以把count(t2.cscore)+1作为新字段rank进行排名即可,同时按t1.cid, t1.sid, t1.cscore对结果分组,最后按cid排序
- 补充:其实count(t2.sid)+1或count(t2.cid)+1都可以,反正右表有一行数据就count一次

【15.2 按各科成绩进行排序,并显示排名, 成绩重复时合并名次】
***和上一题的区别就是如果有重复成绩,合并名次,即有并列第二时,显示1,2,2,3,4
解法1:窗口函数
#解法1:窗口函数
- 不保留名次空缺,使用dense_rank函数,以课程编号cid分组,按分数cscore排名
- rank函数在有重复值时使用跳跃排序,即有并列第二时,显示1,2,2,4,5
解法2:表连接
#解法2:表连接
- 基本和上一题的代码一致,但是这次count函数必须要使用t2.cscore了,因为需要找到distinct的cscore然后进行排名,这样的话如果有并列的分数,cscore只会被count一次
【16. 查询学生的总成绩,并进行排名,总分重复时保留名次空缺】
解法1:窗口函数
#解法1:窗口函数
- 省略partition by子句就是不指定分组,只指定按总分排序
解法2:使用变量
#解法2:使用变量方法1(设置变量myrank初始值)
变量就是一个容器,在需要不断更改的地方放一个变量,而不是固定的值,这样每次需要更改的时候,只需要更改变量的值就可以。这一题解法2中使用变量myrank保存排名的动态变化。
说明一下变量的使用方法:
- MySQL里面的变量是不严格限制数据类型的,它的数据类型根据你赋给它的值而随时变化
- 定义变量
- 使用 @变量名 来定义一个变量,如 @abc,就是创建一个叫做abc的变量
- 给变量赋值
- 使用set时可以用“=”或“:=”,但是使用select时必须用“:=赋值”
- set @abc=1 或set @abc:=1,就是使用set语句创建并初始化变量abc的值为1
- select @abc:=1,就是把1赋值给变量abc
- select @abc:=字段名 from 表名 where ...,就是从数据表中获取一条记录字段的值给变量abc,在执行后输出到查询结果集上面
解法2:使用变量方法1(设置变量myrank初始值)
- set语句用来创建并初始化变量
- set @myrank = 0; 这行代码每次都需要运行,将变量初始值设为0
- 接着在select语句中设置变量 @myrank := @myrank+1 as 排名
解法2:使用变量方法2(每次查询都初始化变量myrank)
- 使用子查询,(select @myrank := 0) as t2,然后从t1和t2两个表查询内容
【36. 查询所有课程成绩第二名到第三名的学生信息及课程成绩】
select - 第一步,使用子查询通过dense_rank函数查询排名情况,并且将查询结果存为新表t1
- 第二步,通过学生编号sid连接学生表和新表t1
- 第三步,加入Where条件筛选,查找排名为第二名和第三名的数据,(2,3) 代表排名=2 or 排名=3,不是一个区间范围
- 最后用两个条件进行排序,先用cid排序(按各科成绩排序),再用排名排序(按各科成绩排名排序),排序规则默认是asc
【第四部分】子查询
知识要点与易错点总结
什么情况下需要用子查询?
- 用某个查询结果作为另一个查询的条件的时候
- 不能直接join,需要先统计出中间数据的时候
- 多表联合查询的时候或者是检索指定的数据的时候
比较运算符
- IN:在范围内的值,只要有就是True
- 只用于子查询:ANY(和子查询返回的任何一个值比较为True,则返回True)
- 只用于子查询:ALL(和子查询返回的所有值比较为True,则返回True)
子查询题目整理(完整题目列表见文章最后)
【3. 查询在成绩表存在成绩的学生信息】
【28. 查询所有学生的课程及分数情况(存在学生没成绩,没选课的情况)】
***两题思路一致,可以用子查询,也可以用表连接,第28题和第3题解法2的区别就是不加Where筛选成绩非null值的数据(存在学生没成绩,没选课的情况)
解法1:子查询
#解法1:子查询
- 第一步,用子查询,找到成绩表中有成绩的学生sid
- 第二步,拿这个sid去学生表查学生信息
解法2:表连接
#解法2:表连接
- Left join 学生表和成绩表,然后用Where过滤联合表里cscore不为null的学生(有cscore就有成绩)
- 然后使用select distinct语句来去重,每个学生的信息只返回一行
【6. 查询学过"张三"老师授课的同学的信息】
***可以用Where直接多表查询,也可以用子查询,子查询的思路与下一题【10. 查询没学过"张三"老师讲授的任一门课程的学生姓名】相同
select 【10. 查询没学过"张三"老师讲授的任一门课程的学生姓名】
select - 总的思路是反向思考,即先找到所有上过张三老师课的学生,取反即为没上过课的学生
- 写SQL子查询的思路,越先查的东西其实是放在越后面的
- 第一步,line4,在teacher表中查到张三老师的tid
- 第二步,line3,用第一步找到的tid,在course表中查到这个tid对应的cid,即这个老师教的课是哪一门
- 第三步,line2,用第二步找到的cid,在score表中查到学过这门课的学生sid
- 第四步,line1,用第二步找到的sid,在student表中查找对应学生,反向思考,没上过这门课就用not in
【33. 成绩不重复,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及成绩】
#解法1:MAX
select cname, tname, sname, cscore, max(distinct cscore) as 最高分
from student, course, score, teacher
where score.sid = student.sid
and score.cid = course.cid
and teacher.tid = course.tid
and tname = '张三';
#解法2:Limit
select cname, tname, sname, cscore
from student, course, score, teacher
where score.sid = student.sid
and score.cid = course.cid
and teacher.tid = course.tid
and tname = '张三'
order by cscore desc limit 1;- 多表联合查询,直接用Where多条件筛选最快
- 解法1使用Max函数,只返回成绩最高的第一条记录
- 解法2用cscore从高到低排序后,使用LIMIT关键字返回第一条记录
【34. 成绩有重复,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及成绩】
***和上一题的区别是,如果张三老师所授课程里有多个学生获得并列第一的成绩,需要全部找出来,这时用MAX只能找到其中一个,并且如果不知道到底有几个学生是并列第一的话,也没有办法使用LIMIT。比较好的方式是子查询。
第一步:修改成绩表
#修改成绩表
update score
set cscore = 90
where cid = 02 and sid = 07;- 因为原本的成绩表里02课程没有两个相同的最高分,所以可以先手动修改一下数据表,把07号学生的02课成绩从89改成90分,这样成绩表的02课程就有两个90分
- 如果MySQL报错,是因为安全模式的限制,需要点击顶部菜单栏的Edit → Preference → SQL Editor → 取消勾选Safe Updates → 重启MySQL
- 建议运行完Update语句后,把Safe Updates重新勾选回来
第二步:查询多个02课程最高分
#最终代码
select cname, tname, sname, cscore
from student, course, score, teacher
where score.sid = student.sid
and score.cid = course.cid
and teacher.tid = course.tid
and tname = '张三'
and cscore in
(select max(cscore) as 最高分
from student, course, score, teacher
where score.sid = student.sid
and score.cid = course.cid
and teacher.tid = course.tid
and tname = '张三');- 与33题的区别就是加了个子查询,只用来查找最高分,然后用Where找到成绩符合最高分的所有学生,结果如下图所示
- 建议这题做完之后重新运行Update语句把07号学生的02课成绩改回89分

【7. 查询没有学全所有课程的同学的信息】
【39. 查询选修了全部课程的学生信息】
***这里主要解释第7题,第39题的代码与本题解法1里的子查询代码一致
解法1:反向思考
#解法1:反向思考
- 思路是反向思考,先找到上了所有课程的学生,然后排除这些学生,就是没有学全所有课程的学生了,用not in关键字
- 如何找学全所有课程的学生?关键在于score表里的每个学生要同时有3个cid(01/02/03),所以思路是对student表做如下过滤:
- 第一步,从course表中查找一共有几个cid (目前是3),所以select count(course.cid) from course
- 第二步,从score表中查找符合第一步中查到的cid count数量 (目前是3) 的学生sid,所以having count(score.cid) = 第一步的结果
- 第三步,从student表中查找第二步中查到的sid的学生信息,因为是取反,所以用not in
解法2:表连接
#解法2:表连接方法1
解法2:表连接方法1
- 第一步,从course表中查找一共有几个cid (目前是3) ,所以是select count(course.cid) from course
- 第二步,把student表和score表join起来,然后按照student.sid或score.sid分组
- 第三步,查找联合表中同一个sid对应的cid count数量 (目前为3) 的情况,即having子句代表某个sid学的课程数量不等于course表里一共的课程数量
解法2:表连接方法2
- 与方法1相似,但用inner join + where连接表
- inner join从查询意义上来讲,用where或on的效果相同,语法也不会报错
- 但是这题用left join更合理,因为如果一个学生要是一门课程都没学的话,inner join后就不会显示这个学生了
【8. 查询至少有一门课与学号为"01"的同学所学相同的同学的信息】
select - SQL的多表查询是越后面的越先查询,所以要最先找的表要放在最后面,所以:
- 第一步,从score表查询sid=01的学生的所有cid
- 第二步,根据第一步找到的score表cid,去score表查询有这些cid课的学生sid,同时sid不为01(排除掉sid=01学生)
- 第三步,根据第二步找到的score表sid,去student表查询第二步找到的所有sid的学生信息
【9. 查询和"01"号的同学学习的课程完全相同的其他同学的信息】
***这题是上一题【8. 查询至少有一门课与学号为"01"的同学所学相同的同学的信息】的难度提高版,而且网上能查到的答案大多是伪答案,比如说在第8题的基础上再加一个条件找出选课数也和01同学相同的学生,这种解法其实没有真正解决问题。
经过研究发现,group_concat()函数可以解决这个题目的要求,语法规则如下:
group_concat( [distinct] 需要连接的字段 [order by 需要排序的字段 asc/desc] [separator '分隔符'] )
- group_concat() 将Group by产生的同一个分组中的值连接起来,返回一个字符串结果
- [ ]方括号里的内容都是可选参数,可以不写
- 使用distinct可以排除重复值,需要连接的字段可以是多个,需要排序的字段也可以是多个
- separator后面需要一个字符串值
补充:concat_ws() 函数也有把两个字符串连接为一个字符串的效果,但是无法针对分组做处理,另外concat_ws() 函数语法为:concat_ws('分隔符', str1, str2, ...)
第一步:找到所有学生的选课情况
#第一步:找到所有学生的选课情况
- Group by以学生编号sid分组,也就是说要对分组后每个学生sid对应的所有cid进行连接
- group_concat的参数里,需要连接的字段为cid,按cid排序,分隔符为 '-'

第二步:找到01号学生的选课情况
#第二步:找到01号学生的选课情况
- 与第一步的区别就是加了Where筛选sid=01的情况,这时01学生的选课情况字段返回结果应该是:01-02-03
第三步:join上面的两个表,连接条件为 选课情况 字段,并去除01号同学的记录
#最终代码
- t1表是所有学生的选课情况,t2表是01号学生的选课情况,两个表join后,再与学生表join,查询学生信息,并删掉sid=01的学生信息
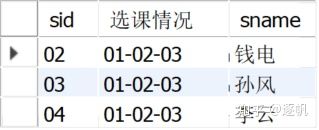
【35. 查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩】
***题目本身有歧义,这里理解为找出选了不止一门课,且自己的不同课程分数相同的学生,比如说一个学生选了01课和03课,且分数都是80
解法1:子查询+自交
#解法1:子查询+自交
- 原样克隆一遍成绩表,然后查询t1和t2中课程编号cid不同但分数cscore相同的学生编号sid
解法2:子查询+聚合函数
#解法2:子查询+聚合函数
- 查出选课数大于1的学生,并且不同课程分数的最大值=最小值(即分数相等)
【2020.07.14 补充题:计算每门课的男女生比例】
看到一个新的题目比较有意思,也用到了子查询,这里也分享一下解法。
select - 第一步,因为需要用到ssex学生性别,cname课程名称这两个字段,所以需要先把student、score、course三张表连接起来
- 第二步,计算男生数量,可以用count函数内嵌IF判断,符合条件则count一次,否则null。然后用男生数量除以总人数即为男生比例。女生数量和女生比例操作相同
- 最后用Group by cname显示三门课程的男女生比例
- 注意本题是直接select from子查询括号里做的三表连接结果,所以子查询做好的这张表需要有一个名称,否则会报错
附录
题目列表:
1.1 查询"01"课程比"02"课程成绩高的学生的信息及课程分数
1.2 查询同时上过"01"课程和"02"课程的学生
1.3 查询上过"01"课程但可能没上过"02"课程的学生 (这种情况显示为 null)
1.4 查询没上过"01"课程,只上过"02"课程的学生
2. 查询平均成绩大于等于 60 分的同学的学生编号、学生姓名和平均成绩
3. 查询在 SC 表存在成绩的学生信息
4. 查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null)
5. 查询「李」姓老师的数量
6. 查询学过张三老师授课的同学的信息
7. 查询没有学全所有课程的同学的信息
8. 查询至少有一门课与学号为"01"的同学所学相同的同学的信息
9. 查询和"01"号的同学学习的课程完全相同的其他同学的信息
10. 查询没学过"张三"老师讲授的任一门课程的学生姓名
11. 查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
12. 检索" 01 "课程分数小于 60,按分数降序排列的学生信息
13. 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
14. 查询各科成绩最高分、最低分和平均分,以如下形式显示:
课程 ID,课程 name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率
(及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90)
要求输出课程号和选修人数,查询结果按人数降序排列列,若人数相同,按课程号升序排列
15.1 按各科成绩进行排序,并显示排名, 成绩重复时保留名次空缺
15.2 按各科成绩进行排序,并显示排名, 成绩重复时合并名次
16. 查询学生的总成绩,并进行排名,总分重复时保留名次空缺
17. 统计各科成绩各分数段人数:课程编号,课程名称,[100-85],[85-70],[70-60],[60-0] 及所占百分比
18. 查询各科成绩前三名的记录
19. 查询每门课程被选修的学生数
20. 查询出只选修两门课程的学生学号和姓名
21. 查询男生、女生人数
22. 查询名字中含有「风」字的学生信息
23. 查询同名同性学生名单,并统计同名人数
24. 查询 1990 年年出生的学生名单
25. 查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
26. 查询平均成绩大于等于 85 的所有学生的学号、姓名和平均成绩
27. 查询课程名称为「数学」,且分数低于 60 的学生姓名和分数
28. 查询所有学生的课程及分数情况(存在学生没成绩,没选课的情况)
29. 查询任何一门课程成绩在 70 分以上的姓名、课程名称和分数
30. 查询不及格的课程
31. 查询课程编号为 01 且课程成绩在 80 分及以上的学生的学号和姓名
32. 求每门课程的学生人数
33. 成绩不重复,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
34. 成绩有重复的情况下,查询选修「张三」老师所授课程的学生中,成绩最高的学生信息及其成绩
35. 查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
36. 查询所有课程成绩第二名到第三名的学生信息及课程成绩
37. 统计每门课程的学生选修人数(超过 5 人的课程才统计)
38. 检索至少选修两门课程的学生学号
39. 查询选修了全部课程的学生信息
40. 查询各学生的年龄,只按年份来算
41. 按照出生日期来算,如果当前月日 < 出生年月的月日,年龄减一
42. 查询本周过生日的学生
43. 查询下周过生日的学生
44. 查询本月过生日的学生
45. 查询下月过生日的学生