SQL语句4(MySQL)——DQL查询语句
DQL查询语句
 基础查询
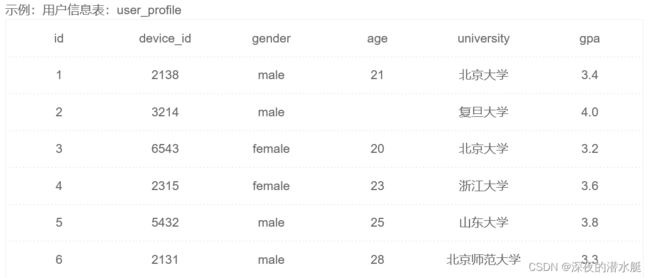
基础查询
条件查询 WHERE
in not in 大于小于between is not null and or
# 查找学校是北大的学生信息
select device_id, university
from user_profile
where university in ("北京大学")
#查找除复旦大学的用户信息
select device_id,gender,age,university
from user_profile
where university not in ("复旦大学")
#查找年龄大于24岁的用户信息
#is not null 可以过滤空值
select device_id, gender, age, university
from user_profile
where age is not null and age>24
#针对20岁及以上且23岁及以下的用户开展分析,请你取出满足条件的设备ID、性别、年龄。
select device_id,gender,age
from user_profile
where age between 20 and 23
#where age>=20 and age<=23
#找到gpa在3.5以上(不包括3.5)的山东大学用户 或 gpa在3.8以上(不包括3.8)的复旦大学同学进行用户调研,请你取出相应数据
select device_id,gender,age,university,gpa
from user_profile
where gpa>3.5 and university='山东大学' or gpa>3.8 and university='复旦大学'
模糊查询
字符匹配一般形式为:
列名 [NOT ] LIKE
匹配串中可包含如下四种通配符:
_:匹配任意一个字符;
%:匹配0个或多个字符;
[ ]:匹配[ ]中的任意一个字符(若要比较的字符是连续的,则可以用连字符“-”表 达 );
[^ ]:不匹配[ ]中的任意一个字符。
#查询学生表中姓‘张’的学生的详细信息。
SELECT * FROM 学生表 WHERE 姓名 LIKE '张%'
#查询姓“张”且名字是2个字的学生姓名。
SELECT * FROM 学生表 WHERE 姓名 LIKE '张__'
#查询学生表中姓‘张’、姓‘李’和姓‘刘’的学生的情况。
SELECT * FROM 学生表 WHERE 姓名 LIKE '[张李刘]%'
#查询学生表表中名字的第2个字为“小”或“大”的学生的姓名和学号。
SELECT 姓名,学号 FROM 学生表 WHERE 姓名 LIKE '_[小大]%'
#查询学生表中所有不姓“刘”的学生。
SELECT 姓名 FROM 学生 WHERE 姓名 NOT LIKE '刘%'
#从学生表表中查询学号的最后一位不是2、3、5的学生信息。
SELECT * FROM 学生表 WHERE 学号 LIKE '%[^235]'
 分组查询 GROUP BY
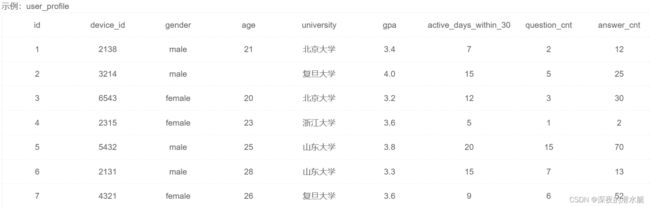
分组查询 GROUP BY
HAVING 分组后条件
排序查询 ORDER BY
ORDER BY avg_quesition_cnt 默认升序(asc)
降序 ORDER BY avg_quesition_cnt desc
#分组计算
#as 省略了
SELECT
gender,
university,
COUNT(id) user_num,
avg(active_days_within_30) avg_active_day,
avg(question_cnt) avg_question_cnt
FROM user_profile
GROUP BY university,gender
#分组过滤
#查看每个学校用户的平均发贴和回帖情况,寻找低活跃度学校进行重点运营,请取出平均发贴数低于5的学校或平均回帖数小于20的学校
select university,
avg(question_cnt) avg_question_cnt,
avg(answer_cnt) avg_answer_cnt
from user_profile
group by university
having avg(question_cnt)<5 or avg(answer_cnt)<20
#分组排序
select university,avg(question_cnt) as avg_question_cnt
from user_profile
group by university
order by avg(question_cnt)
连表查询–多表查询
select device_id, question_id,result
from question_practice_detail as a
inner join user_profile as b
on a.device_id = b.device_id and b.university='浙江大学'
常用函数**
count max avg round
COUNT(1):统计不为NULL 的记录。
COUNT(*):统计所有的记录(包括NULL)。
COUNT(字段):统计该"字段"不为NULL 的记录。
1.如果这个字段是定义为not null的话,一行行地从记录里面读出这个字段,判断不能为null,按行累加。
2.如果这个字段定义允许为null的话,判断到有可能是null,还要把值取出来在判断一下,不是null才累加。
COUNT(DISTINCT 字段):统计该"字段"去重且不为NULL 的记录
#复旦大学学生gpa最高值是多少
select max(gpa)
from user_profile
where university='复旦大学'
#男性用户有多少人以及他们的平均gpa是多少,用以辅助设计相关活动,请你取出相应数据。
#round函数,保存n位小数 round(列名,n)
#count()计数函数
select count(gender) as male_num,round(avg(gpa),1) as avg_gpa
from user_profile
where gender='male';
查询去重
用DISTINCT关键字可以去掉结果中的重复行。
DISTINCT关键字放在SELECT词的后边、目标列名序列的前边。
#查看用户来自于哪些学校,请从用户信息表中取出学校的去重数据。
#方法一
select distinct university from user_profile
#方法二
select university from user_profile group by university
查询结果限制返回行数
使用LIMIT限制结果集
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。
LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。
如果只给定一个参数,它表示返回最大的记录行数目。
如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。
为了检索从某一个偏移量到记录集的结束所有的记录行,可以指定第二个参数为 -1。
初始记录行的偏移量是 0(而不是 1)。
LIMIT OFFSET-----选取中间任意几行
#检索记录行 6-10
SELECT * FROM table LIMIT 5,5
#检索记录行11-last
SELECT * FROM table LIMIT 10,-1
#检索前 5 个记录行
SELECT * FROM table LIMIT 5
#查看前2个用户明细设备ID数据
select device_id from user_profile limit 2 offset 0
select device_id from user_profile limit 2
select device_id from user_profile limit 0,2
分页查询 LIMIT
SELECT 字段列表 FROM 表名 LIMIT 起始索引,查询条目数(每页显示的条数);
起始索引:从0开始
起始索引 = (当前页码 - 1)*每页显示的条数
LIMIT为MySQL方言