毕业设计-基于机器视觉的俯卧撑计数模型
目录
前言
课题背景和意义
实现技术思路
一、俯卧撑计数算法
二、实验与分析
三、总结
实现效果图样例
最后
前言
大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
毕业设计-基于机器视觉的俯卧撑计数模型
课题背景和意义
当前体能训练中普遍需要将俯卧撑计数作为考核 成绩 ,俯卧撑测试的成绩测量大都采用人工计数或红 外设备测量,这些测量方式均存在测试标准不一致、测 试效率低、裁判员工作负荷大等问题。 基于红外设备的俯卧撑计数系统主要由红外发射 器、红外接收器等设备组成。原理是测试人员撑起和 俯卧时阻断红外发射器和红外接收器之间的信号,接 收器无法接收到信号时,判定相应俯卧撑动作并进行 计数。但当红外线被非测量对象遮挡后,系统也会判 定是被运动员肢体遮挡,从而出现计数错误。所以红 外传感测量设备普遍存在的问题是容易被异物干扰而 误报成绩。 因此,采用基于机器视觉的智能算法对俯卧撑这 一类传统体能训练项目进行检测计数,具有重大意 义。人体姿态检测是视频智能监控的关键应用领域之 一,由于人体肢体自由度较高,当人在做不同的运动 时,肢体也呈现不同的状态。传统人体姿态识别框架 OpenPose 是基于卷积神经网络和监督学习的框架上开 发的开源库,可以在多种场合下实现对人体复杂姿态 的估计,在机器视觉领域有广泛的应用 。
实现技术思路
设计了一种基于机器视觉的 俯卧撑计数算法,如图所示,该算法由两个部分组 成,图像采集模块和智能计数模块,图像采集模块中 由摄像机完成图像采集。智能计数模块中由改进的 YOLOv3 算法进行对人体的目标检测,由 UltralightSimplepose 模型预测人体关键点,最后由 SVM 分类器 实现分类计数功能,输出计数结果。
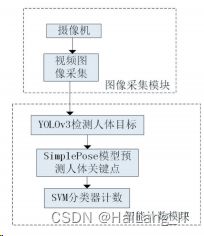
一、俯卧撑计数算法
制作俯卧撑数据集并转换成COCO数据集
格式 COCO 的英文全名是 Common Objects in Context, 该数据集是由美国微软公司建立的一种大型的图像处 理数据集,其任务信息包含目标探测、像素分割和字幕 标注等。对数据集的标注信息保存在 JSON 格式的文 件中,包括五大类注释,分别是目标检测、关键点检测、 素材分割、全景分割和字幕生成。COCO API 接口可以 实现图像标签数据加载、解析和视频可视化功能。
基于改进的YOLOv3检测人体目标
YOLOv3 是针对 YOLO 模型的又一次改进版本, 主要包括以下几个方面:
(1)YOLOV3 使用多个分类标签预测来不同的目 标,能适应更加多样性的场景。与传统的识别模型不 同,它采用了单独的逻辑分类工具,在训练过程中使用 二元交叉熵损失函数来分类目标。
(2)用于目标检测的 YOLOv3 边界框有 3 种不同 的尺寸,但提取不同尺寸的特征时运用的是同一种算 法。在基于 COCO 数据集的实验中,YOLOv3 的神经 网络分别为每种尺寸预测了三个边界框,得到的边界 张量 T 的公式是:
![]()
(3)YOLOv3 在 YOLOv2 的基础上进行了提升,同 时融合其他新型残差网络,由连续的 3 × 3 卷积层和 1 × 1 卷积层组合而成,其中还添加了几个近路连接。
YOLOv3 与 YOLO 系列以前的网络对比,权值更大,层 数更多,其卷积层数共有 53 个,所以命名 DarkNet-53,如图所示。
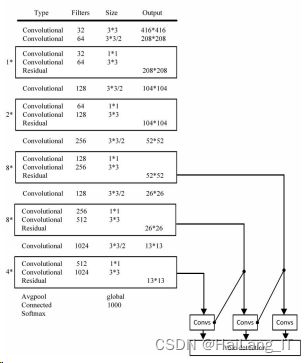
DarkNet-53 在检测精度上比传统的 YOLO 模型更 加精确,同时计算量更加精简,耗时更短。与 ResNet- 101 相比,DarkNet-53 的效率提升了近 1.5 倍,ResNet- 152 和它功能相当,但运行时间却是其 2 倍。
YOLOv3 算法可以检测多姿多态的物体,而本文只 需要检测人体。YOLOv3 有三个不同尺寸的边界框,大 小分别为 13×13、26×26、52×52。小尺寸的特征图像更 适合定位目标较大的目标,而大尺寸的特征图像更容 易检测目标较小的物体。对于只检测人的任务,YO⁃ LOv3 网络相对复杂,影响算法的检测效率,系统负担 较大。因此,在结构上对 YOLOv3 网络进行了优化,改 进后的网络结构如图所示。
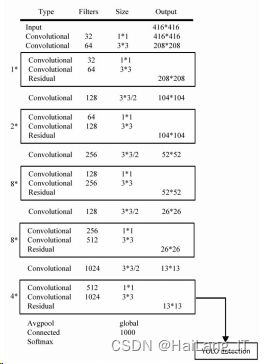
本文运用改进的 YOLOv3 进行人体目标检测,如图所示,预测出人体的感兴趣区域(ROI),圈定该区 域以便进行进一步处理。

基于Ultralight-SimplePose预测人体关键点
Ultralight-SimplePose 是一种超轻量的人体关键点 预测框架,主要运用的是 Simple Baseline 算法。与传 统人体姿态检测框架相比,具有速度快,精度高的优 势。采用自上而下的策略,先进行目标检测(人),再对 每个检测到的人进行单人的关键点检测(单人姿态估 计),输入图像是改进后的 YOLOv3 检测到 的人的 ROI。 Ultralight-SimplePose 算法中提出的 Simple Base⁃ line 结构如图所示。

该算法与 Hourglass和 CPN 在生成高分辨率特 征图的方式上有所不同,后两者都使用上采样来提高 特征映射的分辨率,并将卷积参数放入其他块中。而 Simple Baseline 的方法是将上采样和卷积参数以更简 单的方式组合到反卷积层中,而不使用跳层连接。
该算法在姿态追踪方面具体有如下几点:
(1)光流联合传播:光流(Optical Flow)是指运动的 目标在连续多帧图像上的像素移动的瞬时速度,光流 矢量是图像上相应的坐标点灰度的瞬时变化率。
(2)基于光流的姿态匹配:帧间追踪某个目标时, 需要计算目标前后帧的匹配度,在运动较快或者密集 场景下,使用边界框 IoU(Intersection over Union)作为相似性度量(SBbox)效果不好,此时框不重叠,且与实 例没有对应关系;当两帧间的姿态相差较大时,使用对 象关节点相似性 OKS(Object Keypoint Similarity)效果也 不好,无法进行有效匹配。
![]()
以上是关于 Ultralight-SimplePose 框架人体姿态 预测的算法原理简述,调用 Ultralight-SimplePose 进行 训练,得到俯卧撑状态下的人体关键点预测模型。
图为实验中 人体俯卧撑时关键点预测图:

基于SVM分类器的俯卧撑计数 支持向量机
SVM(Support Vector Machines)是一种 二分类模型。SVM 的基本算法是对于线性可分的数 据集,求解一个超平面,该超平面能够将训练数据集划 分为正类和负类,并最大化其几何区间 。
非线性的映射在 SVM 里由核函数来实现,核 函数的作用是简化高维空间中的映射计算量,本文采 用高斯径向基核函数(Gaussian radial basis function ker⁃ nel)来实现输入空间到特征空间的映射,设训练数据集 T ={ } ( ) x1 ,y1 ,( ) x2,y2 ,…,( ) xN,yN ,坐标点数据 xi ∈ Rd , d 为样本空间维度,学习目标 yi ∈ {-1,1} 为二元变 量,i,j = 1,2,…,N 。
输入实例为 Xi 、Xj ,核函数表达式为:
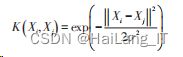
通过核函数求解凸二次规划问题,在高维度空间 里分类决策函数为:
![]()
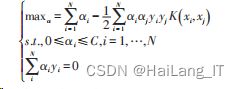
将核函数 K 代入式中,得到基于高斯径向基核 函数的 SVM 最优分类函数:
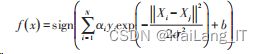
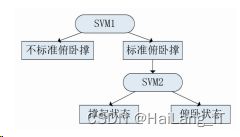
将获得的人体 17 个关键点坐标 数据集进行处理,为减少计算维度和计算量,去除与俯 卧撑动作无关的脸部点位,只提取手肘夹角、肩肘夹角、臀腰夹角等特征,输入 SVM 分类器进行训练。分 别将以下三种状态进行标注:标准俯卧撑状态下的撑 起状态,俯卧状态,以及不标准俯卧撑状态。
为了完成 俯卧撑计数的同时实现对俯卧撑动作标准化的监督, 使用二叉树法依次分类样本,如图所示:
训练出检测俯卧撑计数的 SVM 分类器后,设置计 数器,若实例动作不标准,则不予计数,当图像遍历撑 起、俯卧、撑起三个状态时,则计数器加一,实现俯卧撑 计数功能,如图所示。

二、实验与分析
本文实验环境为 PyTorch 1.4.0、Python 3.6、Ubuntu 18.04.4LTS、MXNet 1.5.0;处理器为 Intel Core i5-7400, CPU 频率为 3.0GHz;内存 8GB;GPU 显卡为 NVIDIA GTX 1080TI,显存 12GB。
选择 hmdb51、UCF50人类行为数据集中 俯卧撑视频,自制俯卧撑训练视频等抽帧作为训练数 据集,选取其中 3000 张图片作为数据样本。
实验测试由视频测试,抽帧得到的图片数据传递至智能计数模块开始计数 ,每张图片检测耗时125ms。本实验以计数准确率作为评价标准,实验测试 结果见表。
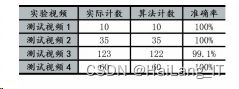
根据实验结果所示,该算法完全正确率大于 99%,可以实时地,准确地进行俯卧撑体能训练及测试计数。
三、总结
本文设计了一种基于机器视觉的俯卧撑计数算 法,能准确实现体能训练及考核中俯卧撑计数,比人工 计数更准确,节省人力成本;比红外感应计数更便捷、 安全、不易被异物干扰。
实现效果图样例
俯卧撑计数:

我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!