Faster RCNN源码解析之-RPN网络
Faster-RCNN的内容这里就不进行解析了 不熟悉的推荐去这篇链接去看下方便后续代码解析
一文读懂Faster RCNN
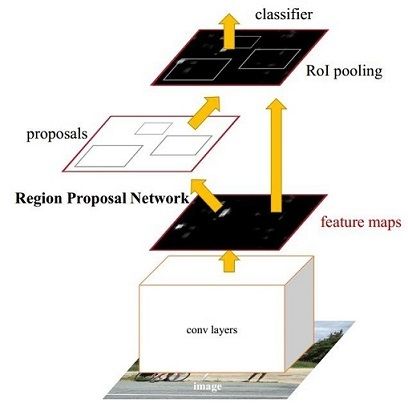
网络结构如上图
RPN region proposal network 区域建议网络 什么意思呢就是给后续fast rcnn提供region用来训练的
RCNN 和 Fast RCNN 都是采用的 Selective search 来生产region 如 RCNN 中说的 While R-CNN is ag- nostic to the particular region proposal method, we use se- lective search to enable a controlled comparison with prior detection work 都需要使用单独的算法来生产region 这对物体检测的速度有着一定的制约(其他的地方已经没办法大幅度提升网络检测速度,所以只能从region生成来进行优化) 所以出现了区域建议网络 RPN
在我们用VGG16 了13个conv层+13个relu层+4个pooling层后图片缩小为 (h/16, w/16) 然后 进行3*3的卷积后走向两个分支
a 一个分支来预测类别 区分前景还是后景 (H, W, 2k)k = 9
b 一份分支用来预测边框回归的偏差 (H, W, 4k)k = 9
假设我们现在得到featuremaps尺寸(H, W, 256) 论文中引入了anchors 概念 An anchor is centered at the sliding window (anchor 位于滑动窗口中心)
we use 3 scales and 3 aspect ratios, yielding k = 9 anchors at each sliding position For a convolutional feature map of a size W × H (typically ∼2,400), there are W H k anchors in total.
可以看出总共会有 H * W * k 个anchors

代码地址 https://github.com/rbgirshick/py-faster-rcnn
下面有一句对py-faster-rcnn的实现说的很好 This Python implementation is built on a fork of Fast R-CNN. 也就是说 RPN + Fast RCNN = Faster RCNN
源码涉及主要文件
lib/rpn/generate_anchors.py
Generates a regular grid of multi-scale, multi-aspect anchor boxes. 生成9个基准anchor
lib/rpn/proposal_layer.py
Converts RPN outputs (per-anchor scores and bbox regression estimates) into object proposals. 简单来说就是用RPN的输出生成物体检测区域
lib/rpn/anchor_target_layer.py
Generates training targets/labels for each anchor. Classification labels are 1 (object), 0 (not object) or -1 (ignore). Bbox regression targets are specified when the classification label is > 0.
意思就是生成用于RPN网络的训练数据
lib/rpn/proposal_target_layer.py
Generates training targets/labels for each object proposal: classification labels 0 - K (bg or object class 1, ... , K) and bbox regression targets in that case that the label is > 0.
意思就是生成用于Fast RCNN网络的训练数据
还有几个辅助函数实现很简单这里就不进行解析了 如边框和边框偏移的转换/nms的实现等
如果有对 ROIPoolingLayer(ROI)具体的实现感兴趣的可以移步我的这篇博客:Fast R-CNN RoI pooling layer caffe源码解析
Talk is cheap. Show me the code
generate_anchors.py
def generate_anchors(base_size=16, ratios=[0.5, 1, 2],
scales=2**np.arange(3, 6)):
"""
Generate anchor (reference) windows by enumerating aspect ratios X
scales wrt a reference (0, 0, 15, 15) window.
"""
# 得到一个基本尺寸的anchor (x1, y1, x2, y2)
base_anchor = np.array([1, 1, base_size, base_size]) - 1
# 用基本尺寸的anchor生成3个不同比列的anchor
ratio_anchors = _ratio_enum(base_anchor, ratios)
# 最终生成9个基准anchors 可以跟随sliding window移动
anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales)
for i in xrange(ratio_anchors.shape[0])])
return anchors
def _whctrs(anchor):
"""
Return width, height, x center, and y center for an anchor (window).
"""
# 得到宽高和中心点坐标
w = anchor[2] - anchor[0] + 1
h = anchor[3] - anchor[1] + 1
x_ctr = anchor[0] + 0.5 * (w - 1)
y_ctr = anchor[1] + 0.5 * (h - 1)
return w, h, x_ctr, y_ctr
def _mkanchors(ws, hs, x_ctr, y_ctr):
"""
Given a vector of widths (ws) and heights (hs) around a center
(x_ctr, y_ctr), output a set of anchors (windows).
"""
# 将宽高和中心点重新转成anchor的坐标表示(x1, y1, x2, y2)
ws = ws[:, np.newaxis]
hs = hs[:, np.newaxis]
anchors = np.hstack((x_ctr - 0.5 * (ws - 1),
y_ctr - 0.5 * (hs - 1),
x_ctr + 0.5 * (ws - 1),
y_ctr + 0.5 * (hs - 1)))
return anchors
def _ratio_enum(anchor, ratios):
"""
Enumerate a set of anchors for each aspect ratio wrt an anchor.
"""
# 将anchor坐标转成 宽高和中心点 因为生成的3个anchor中心点一直
# 这里是求解方程得到的 x * y = w * h x / y = ratios
# x, y = np.sqrt(w * h / ratios), np.sqrt(w * h / ratios) * ratios
w, h, x_ctr, y_ctr = _whctrs(anchor)
size = w * h
size_ratios = size / ratios
ws = np.round(np.sqrt(size_ratios))
hs = np.round(ws * ratios)
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors
def _scale_enum(anchor, scales):
"""
Enumerate a set of anchors for each scale wrt an anchor.
"""
# 生成尺寸比列的3个anchor
w, h, x_ctr, y_ctr = _whctrs(anchor)
ws = w * scales
hs = h * scales
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchorsproposal_layer.py
class ProposalLayer(caffe.Layer):
"""
Outputs object detection proposals by applying estimated bounding-box
transformations to a set of regular boxes (called "anchors").
"""
def setup(self, bottom, top):
# parse the layer parameter string, which must be valid YAML
layer_params = yaml.load(self.param_str_)
self._feat_stride = layer_params['feat_stride']
anchor_scales = layer_params.get('scales', (8, 16, 32))
self._anchors = generate_anchors(scales=np.array(anchor_scales))
self._num_anchors = self._anchors.shape[0]
if DEBUG:
print 'feat_stride: {}'.format(self._feat_stride)
print 'anchors:'
print self._anchors
# rois blob: holds R regions of interest, each is a 5-tuple
# (n, x1, y1, x2, y2) specifying an image batch index n and a
# rectangle (x1, y1, x2, y2)
top[0].reshape(1, 5)
# scores blob: holds scores for R regions of interest
if len(top) > 1:
top[1].reshape(1, 1, 1, 1)
def forward(self, bottom, top):
# Algorithm:
#
# for each (H, W) location i
# generate A anchor boxes centered on cell i
# apply predicted bbox deltas at cell i to each of the A anchors
# clip predicted boxes to image
# remove predicted boxes with either height or width < threshold
# sort all (proposal, score) pairs by score from highest to lowest
# take top pre_nms_topN proposals before NMS
# apply NMS with threshold 0.7 to remaining proposals
# take after_nms_topN proposals after NMS
# return the top proposals (-> RoIs top, scores top)
assert bottom[0].data.shape[0] == 1, \
'Only single item batches are supported'
# bottom 是上层的输出 也就是这层的输入 也就是rpn的输出
cfg_key = str(self.phase) # either 'TRAIN' or 'TEST'
# 读取配置信息 最后送给fast rcnn多少个region训练
# __C.TRAIN.RPN_PRE_NMS_TOP_N = 12000
# __C.TEST.RPN_PRE_NMS_TOP_N = 6000
# 从 H * W * A 中选出得分最高的 12000个region
pre_nms_topN = cfg[cfg_key].RPN_PRE_NMS_TOP_N
# __C.TRAIN.RPN_POST_NMS_TOP_N = 2000
# __C.TEST.RPN_POST_NMS_TOP_N = 300
# 进过nms后得到 2000个region
post_nms_topN = cfg[cfg_key].RPN_POST_NMS_TOP_N
# __C.TRAIN.RPN_NMS_THRESH = 0.7 __C.TEST.RPN_NMS_THRESH = 0.7
nms_thresh = cfg[cfg_key].RPN_NMS_THRESH
# __C.TRAIN.RPN_MIN_SIZE = 16 __C.TEST.RPN_MIN_SIZE = 16
min_size = cfg[cfg_key].RPN_MIN_SIZE
# the first set of _num_anchors channels are bg probs
# the second set are the fg probs, which we want
# 取出前景的类别得分 bottom[0] 维度(batch, 2k, H, W) 后面K个为前景得分
scores = bottom[0].data[:, self._num_anchors:, :, :]
# bottom[1] 是边框回归的输出
bbox_deltas = bottom[1].data
# bottom[2]里面存图片信息
im_info = bottom[2].data[0, :]
if DEBUG:
print 'im_size: ({}, {})'.format(im_info[0], im_info[1])
print 'scale: {}'.format(im_info[2])
# 1. Generate proposals from bbox deltas and shifted anchors
# 得到特征图的 h w
height, width = scores.shape[-2:]
if DEBUG:
print 'score map size: {}'.format(scores.shape)
"""
下面代码生成 H * W * A 个anchor
利用numpy的广播性质实现
简单来说就是9个基准的anchor 类似于每个anchor都会在特征图上滑动然后加上特征度每个特征位置信息实现
"""
# Enumerate all shifts
shift_x = np.arange(0, width) * self._feat_stride
shift_y = np.arange(0, height) * self._feat_stride
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
shifts = np.vstack((shift_x.ravel(), shift_y.ravel(),
shift_x.ravel(), shift_y.ravel())).transpose()
# Enumerate all shifted anchors:
#
# add A anchors (1, A, 4) to
# cell K shifts (K, 1, 4) to get
# shift anchors (K, A, 4)
# reshape to (K*A, 4) shifted anchors
A = self._num_anchors
K = shifts.shape[0]
anchors = self._anchors.reshape((1, A, 4)) + \
shifts.reshape((1, K, 4)).transpose((1, 0, 2))
anchors = anchors.reshape((K * A, 4))
# Transpose and reshape predicted bbox transformations to get them
# into the same order as the anchors:
#
# bbox deltas will be (1, 4 * A, H, W) format
# transpose to (1, H, W, 4 * A)
# reshape to (1 * H * W * A, 4) where rows are ordered by (h, w, a)
# in slowest to fastest order
bbox_deltas = bbox_deltas.transpose((0, 2, 3, 1)).reshape((-1, 4))
# Same story for the scores:
#
# scores are (1, A, H, W) format
# transpose to (1, H, W, A)
# reshape to (1 * H * W * A, 1) where rows are ordered by (h, w, a)
scores = scores.transpose((0, 2, 3, 1)).reshape((-1, 1))
# Convert anchors into proposals via bbox transformations
# 这个函数就是rpn输出额边框回归值修正anchors 得到proposal region
proposals = bbox_transform_inv(anchors, bbox_deltas)
# 2. clip predicted boxes to image
# 对超出边界的proposal regions进行裁剪
proposals = clip_boxes(proposals, im_info[:2])
# 3. remove predicted boxes with either height or width < threshold
# (NOTE: convert min_size to input image scale stored in im_info[2])
# 过滤掉尺寸过小的proposal regions
keep = _filter_boxes(proposals, min_size * im_info[2])
proposals = proposals[keep, :]
scores = scores[keep]
# 4. sort all (proposal, score) pairs by score from highest to lowest
# 5. take top pre_nms_topN (e.g. 6000)
# 对scores进行排序选择得分最高的6000个 训练和测试不同
order = scores.ravel().argsort()[::-1]
if pre_nms_topN > 0:
order = order[:pre_nms_topN]
proposals = proposals[order, :]
scores = scores[order]
# 6. apply nms (e.g. threshold = 0.7)
# 7. take after_nms_topN (e.g. 300)
# 8. return the top proposals (-> RoIs top)
# 进行非极大值抑制 然后在跳出最终用于训练的proposal
keep = nms(np.hstack((proposals, scores)), nms_thresh)
if post_nms_topN > 0:
keep = keep[:post_nms_topN]
proposals = proposals[keep, :]
scores = scores[keep]
# Output rois blob
# Our RPN implementation only supports a single input image, so all
# batch inds are 0
# 给我们最后的proposals数据添加一个batch维度 用于网络训练 因为bath_size==1 batch_inds为0
# batch_inds为0 是因为最后进行roi操作需要知道当前出的proposal来源于哪种图片 因为batch_size==1所以索引为0
batch_inds = np.zeros((proposals.shape[0], 1), dtype=np.float32)
blob = np.hstack((batch_inds, proposals.astype(np.float32, copy=False)))
# top就是该层的输出
top[0].reshape(*(blob.shape))
top[0].data[...] = blob
# [Optional] output scores blob
if len(top) > 1:
top[1].reshape(*(scores.shape))
top[1].data[...] = scores
def backward(self, top, propagate_down, bottom):
"""This layer does not propagate gradients."""
pass
def reshape(self, bottom, top):
"""Reshaping happens during the call to forward."""
passanchor_target_layer.py
class AnchorTargetLayer(caffe.Layer):
"""
Assign anchors to ground-truth targets. Produces anchor classification
labels and bounding-box regression targets.
"""
def forward(self, bottom, top):
# Algorithm:
#
# for each (H, W) location i
# generate 9 anchor boxes centered on cell i
# apply predicted bbox deltas at cell i to each of the 9 anchors
# filter out-of-image anchors
# measure GT overlap
assert bottom[0].data.shape[0] == 1, \
'Only single item batches are supported'
# map of shape (..., H, W)
height, width = bottom[0].data.shape[-2:]
# GT boxes (x1, y1, x2, y2, label)
gt_boxes = bottom[1].data
# im_info
im_info = bottom[2].data[0, :]
if DEBUG:
print ''
print 'im_size: ({}, {})'.format(im_info[0], im_info[1])
print 'scale: {}'.format(im_info[2])
print 'height, width: ({}, {})'.format(height, width)
print 'rpn: gt_boxes.shape', gt_boxes.shape
print 'rpn: gt_boxes', gt_boxes
# 1. Generate proposals from bbox deltas and shifted anchors
# 得到 (H * W * A) 个anchor
shift_x = np.arange(0, width) * self._feat_stride
shift_y = np.arange(0, height) * self._feat_stride
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
shifts = np.vstack((shift_x.ravel(), shift_y.ravel(),
shift_x.ravel(), shift_y.ravel())).transpose()
# add A anchors (1, A, 4) to
# cell K shifts (K, 1, 4) to get
# shift anchors (K, A, 4)
# reshape to (K*A, 4) shifted anchors
A = self._num_anchors
K = shifts.shape[0]
all_anchors = (self._anchors.reshape((1, A, 4)) +
shifts.reshape((1, K, 4)).transpose((1, 0, 2)))
all_anchors = all_anchors.reshape((K * A, 4))
total_anchors = int(K * A)
# only keep anchors inside the image
# 多虑掉超出边界的anchor
inds_inside = np.where(
(all_anchors[:, 0] >= -self._allowed_border) &
(all_anchors[:, 1] >= -self._allowed_border) &
(all_anchors[:, 2] < im_info[1] + self._allowed_border) & # width
(all_anchors[:, 3] < im_info[0] + self._allowed_border) # height
)[0]
if DEBUG:
print 'total_anchors', total_anchors
print 'inds_inside', len(inds_inside)
# keep only inside anchors
# 得到过滤掉超出边界的anchor
anchors = all_anchors[inds_inside, :]
if DEBUG:
print 'anchors.shape', anchors.shape
# label: 1 is positive, 0 is negative, -1 is dont care
labels = np.empty((len(inds_inside), ), dtype=np.float32)
labels.fill(-1)
# overlaps between the anchors and the gt boxes
# overlaps (ex, gt)
# 计算出 anchor 和 gtbox的iou
overlaps = bbox_overlaps(
np.ascontiguousarray(anchors, dtype=np.float),
np.ascontiguousarray(gt_boxes, dtype=np.float))
# 得到每个anchor和所有gtboxes相交IOU最大的gtbox索引
argmax_overlaps = overlaps.argmax(axis=1)
# 取出最大的iou值
max_overlaps = overlaps[np.arange(len(inds_inside)), argmax_overlaps]
# 与上面刚好相反 去对应gtbox对应的最大anchor
gt_argmax_overlaps = overlaps.argmax(axis=0)
# 得到最大的anchor
gt_max_overlaps = overlaps[gt_argmax_overlaps,
np.arange(overlaps.shape[1])]
# 这句代码的意思是找出和gt_max_overlaps里面值相等的anchor
# 也就是可能对于某一个gtbox 有多个anchor计算的iou值一致 gt_argmax_overlaps = overlaps.argmax(axis=0) 这个只能找出第一个
# np.where(overlaps == gt_max_overlaps)[0] 这句代码就是找出那些和最大iou值相等的其他anchor
gt_argmax_overlaps = np.where(overlaps == gt_max_overlaps)[0]
if not cfg.TRAIN.RPN_CLOBBER_POSITIVES:
# assign bg labels first so that positive labels can clobber them
# 对于iou小于0.3的anchor标记成背景 negative
labels[max_overlaps < cfg.TRAIN.RPN_NEGATIVE_OVERLAP] = 0
# fg label: for each gt, anchor with highest overlap
# 将与gtbox相交iou最大的anchor标注成 前景positive
labels[gt_argmax_overlaps] = 1
# fg label: above threshold IOU
# 如果有最大iou大于0.7也标注成positive
labels[max_overlaps >= cfg.TRAIN.RPN_POSITIVE_OVERLAP] = 1
if cfg.TRAIN.RPN_CLOBBER_POSITIVES:
# assign bg labels last so that negative labels can clobber positives
# 如果一个anchor同时属于 positive和negative 标注成negative
labels[max_overlaps < cfg.TRAIN.RPN_NEGATIVE_OVERLAP] = 0
# subsample positive labels if we have too many
# 从上面的anchor中选出256个anchor用于训练
# 期望找出128个postive 和 128个negative
num_fg = int(cfg.TRAIN.RPN_FG_FRACTION * cfg.TRAIN.RPN_BATCHSIZE)
fg_inds = np.where(labels == 1)[0]
if len(fg_inds) > num_fg:
disable_inds = npr.choice(
fg_inds, size=(len(fg_inds) - num_fg), replace=False)
labels[disable_inds] = -1
# subsample negative labels if we have too many
num_bg = cfg.TRAIN.RPN_BATCHSIZE - np.sum(labels == 1)
bg_inds = np.where(labels == 0)[0]
if len(bg_inds) > num_bg:
disable_inds = npr.choice(
bg_inds, size=(len(bg_inds) - num_bg), replace=False)
labels[disable_inds] = -1
#print "was %s inds, disabling %s, now %s inds" % (
#len(bg_inds), len(disable_inds), np.sum(labels == 0))
bbox_targets = np.zeros((len(inds_inside), 4), dtype=np.float32)
# 这个就是将anchor的边框坐标转换成回归值
# 就是进行边框回归的公式计算 得到需要训练的回归值
bbox_targets = _compute_targets(anchors, gt_boxes[argmax_overlaps, :])
bbox_inside_weights = np.zeros((len(inds_inside), 4), dtype=np.float32)
bbox_inside_weights[labels == 1, :] = np.array(cfg.TRAIN.RPN_BBOX_INSIDE_WEIGHTS)
bbox_outside_weights = np.zeros((len(inds_inside), 4), dtype=np.float32)
if cfg.TRAIN.RPN_POSITIVE_WEIGHT < 0:
# uniform weighting of examples (given non-uniform sampling)
# 如果对样本进行均匀采样处理出现的概率都是一样的权重是一样
num_examples = np.sum(labels >= 0)
positive_weights = np.ones((1, 4)) * 1.0 / num_examples
negative_weights = np.ones((1, 4)) * 1.0 / num_examples
else:
assert ((cfg.TRAIN.RPN_POSITIVE_WEIGHT > 0) &
(cfg.TRAIN.RPN_POSITIVE_WEIGHT < 1))
# 如果是非均匀采样这里将权重设置成 该样本的概率乘以1/positive_samples
# loss = p * loss(positive) + (1-p) loss(negative)
# 目的就是调节正负样本损失在总损失中站的比例 防止样本多的损失占比过大
positive_weights = (cfg.TRAIN.RPN_POSITIVE_WEIGHT /
np.sum(labels == 1))
negative_weights = ((1.0 - cfg.TRAIN.RPN_POSITIVE_WEIGHT) /
np.sum(labels == 0))
# 得到正负样本的权重值
bbox_outside_weights[labels == 1, :] = positive_weights
bbox_outside_weights[labels == 0, :] = negative_weights
if DEBUG:
self._sums += bbox_targets[labels == 1, :].sum(axis=0)
self._squared_sums += (bbox_targets[labels == 1, :] ** 2).sum(axis=0)
self._counts += np.sum(labels == 1)
means = self._sums / self._counts
stds = np.sqrt(self._squared_sums / self._counts - means ** 2)
print 'means:'
print means
print 'stdevs:'
print stds
# map up to original set of anchors
# 将label映射回 H * W * A 的空间大小
labels = _unmap(labels, total_anchors, inds_inside, fill=-1)
# 把图像内部的anchor对应的bbox_target映射回所有的anchor(加上了那些超出边界的anchor,填充0)
bbox_targets = _unmap(bbox_targets, total_anchors, inds_inside, fill=0)
bbox_inside_weights = _unmap(bbox_inside_weights, total_anchors, inds_inside, fill=0)
bbox_outside_weights = _unmap(bbox_outside_weights, total_anchors, inds_inside, fill=0)
if DEBUG:
print 'rpn: max max_overlap', np.max(max_overlaps)
print 'rpn: num_positive', np.sum(labels == 1)
print 'rpn: num_negative', np.sum(labels == 0)
self._fg_sum += np.sum(labels == 1)
self._bg_sum += np.sum(labels == 0)
self._count += 1
print 'rpn: num_positive avg', self._fg_sum / self._count
print 'rpn: num_negative avg', self._bg_sum / self._count
# 下面就是进行简单的reshape操作和返回
# labels
# [H * W * A] --> [1, H, W, A] --> [1, A, H, W]
labels = labels.reshape((1, height, width, A)).transpose(0, 3, 1, 2)
labels = labels.reshape((1, 1, A * height, width))
top[0].reshape(*labels.shape)
top[0].data[...] = labels
# bbox_targets
bbox_targets = bbox_targets \
.reshape((1, height, width, A * 4)).transpose(0, 3, 1, 2)
top[1].reshape(*bbox_targets.shape)
top[1].data[...] = bbox_targets
# bbox_inside_weights
bbox_inside_weights = bbox_inside_weights \
.reshape((1, height, width, A * 4)).transpose(0, 3, 1, 2)
assert bbox_inside_weights.shape[2] == height
assert bbox_inside_weights.shape[3] == width
top[2].reshape(*bbox_inside_weights.shape)
top[2].data[...] = bbox_inside_weights
# bbox_outside_weights
bbox_outside_weights = bbox_outside_weights \
.reshape((1, height, width, A * 4)).transpose(0, 3, 1, 2)
assert bbox_outside_weights.shape[2] == height
assert bbox_outside_weights.shape[3] == width
top[3].reshape(*bbox_outside_weights.shape)
top[3].data[...] = bbox_outside_weights
def backward(self, top, propagate_down, bottom):
"""This layer does not propagate gradients."""
pass
def reshape(self, bottom, top):
"""Reshaping happens during the call to forward."""
passproposal_target_layer.py
输入是rois 就是经过proposal_layer.py层输出的proposal region 训练有2000个测试有300个 生成训练数据的label标签和边框回归值
class ProposalTargetLayer(caffe.Layer):
"""
Assign object detection proposals to ground-truth targets. Produces proposal
classification labels and bounding-box regression targets.
"""
def forward(self, bottom, top):
# 该层的输入是 rois 和 gtboxes --> bottom
# Proposal ROIs (0, x1, y1, x2, y2) coming from RPN
# (i.e., rpn.proposal_layer.ProposalLayer), or any other source
all_rois = bottom[0].data
# GT boxes (x1, y1, x2, y2, label)
# TODO(rbg): it's annoying that sometimes I have extra info before
# and other times after box coordinates -- normalize to one format
gt_boxes = bottom[1].data
# Include ground-truth boxes in the set of candidate rois
zeros = np.zeros((gt_boxes.shape[0], 1), dtype=gt_boxes.dtype)
# 将ground_th加入候选区域用于训练
all_rois = np.vstack(
(all_rois, np.hstack((zeros, gt_boxes[:, :-1])))
)
# Sanity check: single batch only
assert np.all(all_rois[:, 0] == 0), \
'Only single item batches are supported'
# 为每张图片设置正负样本数目
num_images = 1
# 128个样本
rois_per_image = cfg.TRAIN.BATCH_SIZE / num_images
# 32个正样本
fg_rois_per_image = np.round(cfg.TRAIN.FG_FRACTION * rois_per_image)
# Sample rois with classification labels and bounding box regression
# targets
# 生成训练用的labels 和 边框回归数据
labels, rois, bbox_targets, bbox_inside_weights = _sample_rois(
all_rois, gt_boxes, fg_rois_per_image,
rois_per_image, self._num_classes)
if DEBUG:
print 'num fg: {}'.format((labels > 0).sum())
print 'num bg: {}'.format((labels == 0).sum())
self._count += 1
self._fg_num += (labels > 0).sum()
self._bg_num += (labels == 0).sum()
print 'num fg avg: {}'.format(self._fg_num / self._count)
print 'num bg avg: {}'.format(self._bg_num / self._count)
print 'ratio: {:.3f}'.format(float(self._fg_num) / float(self._bg_num))
# sampled rois
top[0].reshape(*rois.shape)
top[0].data[...] = rois
# classification labels
top[1].reshape(*labels.shape)
top[1].data[...] = labels
# bbox_targets
top[2].reshape(*bbox_targets.shape)
top[2].data[...] = bbox_targets
# bbox_inside_weights
top[3].reshape(*bbox_inside_weights.shape)
top[3].data[...] = bbox_inside_weights
# bbox_outside_weights
top[4].reshape(*bbox_inside_weights.shape)
top[4].data[...] = np.array(bbox_inside_weights > 0).astype(np.float32)
def backward(self, top, propagate_down, bottom):
"""This layer does not propagate gradients."""
pass
def reshape(self, bottom, top):
"""Reshaping happens during the call to forward."""
pass
_sample_rois方法代码如下def _sample_rois(all_rois, gt_boxes, fg_rois_per_image, rois_per_image, num_classes):
"""
Generate a random sample of RoIs comprising foreground and background
examples.
"""
# 这里是将数组装进连续内存并计算iou
overlaps = bbox_overlaps(
np.ascontiguousarray(all_rois[:, 1:5], dtype=np.float),
np.ascontiguousarray(gt_boxes[:, :4], dtype=np.float))
gt_assignment = overlaps.argmax(axis=1)
max_overlaps = overlaps.max(axis=1)
# 为每个anchor设置所属类别 与哪个gt_boxes相交iou最大就是对应的class
labels = gt_boxes[gt_assignment, 4]
# 这里是设置正负样本数目
# Select foreground RoIs as those with >= FG_THRESH overlap
fg_inds = np.where(max_overlaps >= config.train_fg_thresh)[0]
# Guard against the case when an image has fewer than fg_rois_per_image
# foreground RoIs
fg_rois_per_this_image = min(fg_rois_per_image, fg_inds.size)
# Sample foreground regions without replacement
if fg_inds.size > 0:
# 随机抽样
fg_inds = np.random.choice(fg_inds, size=fg_rois_per_this_image, replace=False)
# Select background RoIs as those within [BG_THRESH_LO, BG_THRESH_HI)
bg_inds = np.where((max_overlaps < config.train_bg_thresh_hi) &
(max_overlaps >= config.train_bg_thresh_lo))[0]
# Compute number of background RoIs to take from this image (guarding
# against there being fewer than desired)
bg_rois_per_this_image = rois_per_image - fg_rois_per_this_image
bg_rois_per_this_image = min(bg_rois_per_this_image, bg_inds.size)
# Sample background regions without replacement
if bg_inds.size > 0:
bg_inds = np.random.choice(bg_inds, size=bg_rois_per_this_image, replace=False)
# The indices that we're selecting (both fg and bg)
# 得到
keep_inds = np.append(fg_inds, bg_inds)
# Select sampled values from various arrays:
# labels的size 为 128
labels = labels[keep_inds]
# Clamp labels for the background RoIs to 0
# 前32个是正样本 后面的都是负样本 0表示背景
labels[fg_rois_per_this_image:] = 0
# 128个
rois = all_rois[keep_inds]
# 将候选区域根据坐标回归公式进行转换
bbox_target_data = _compute_targets(
rois[:, 1:5], gt_boxes[gt_assignment[keep_inds], :4], labels)
# 生成坐标回归用的训练数据
# 将 n * 5 -> n * 4k (k是class_num)
bbox_targets, bbox_inside_weights = \
_get_bbox_regression_labels(bbox_target_data, num_classes)
return labels, rois, bbox_targets, bbox_inside_weights_get_bbox_regression_labels方法如下def _get_bbox_regression_labels(bbox_target_data, num_classes):
"""Bounding-box regression targets (bbox_target_data) are stored in a
compact form N x (class, tx, ty, tw, th)
This function expands those targets into the 4-of-4*K representation used
by the network (i.e. only one class has non-zero targets).
Returns:
bbox_target (ndarray): N x 4K blob of regression targets
bbox_inside_weights (ndarray): N x 4K blob of loss weights
"""
# 这一块属于fast-rcnn的坐标回归 每个roi回归出一个 4k的向量用来表示回归的坐标
clss = bbox_target_data[:, 0]
# 80
bbox_targets = np.zeros((clss.size, 4 * num_classes), dtype=np.float32)
bbox_inside_weights = np.zeros(bbox_targets.shape, dtype=np.float32)
inds = np.where(clss > 0)[0]
for ind in inds:
# 每个类回归4个坐标 按照顺序排序
# 设置对应的坐标回归值
# 去掉背景类 从0开始当索引所以减去1
cls = (clss[ind] - 1)
start = int(4 * cls)
end = start + 4
bbox_targets[ind, start:end] = bbox_target_data[ind, 1:]
bbox_inside_weights[ind, start:end] = (1, 1, 1, 1)
return bbox_targets, bbox_inside_weights我们分析下为什么会出现前面后面K个为前景得分
# 取出前景的类别得分 bottom[0] 维度(batch, 2k, H, W) 后面K个为前景得分
scores = bottom[0].data[:, self._num_anchors:, :, :]# 最终label变成下面的维度 (1, 1, A * height, width)
labels = labels.reshape((1, height, width, A)).transpose(0, 3, 1, 2)
labels = labels.reshape((1, 1, A * height, width))然后在损失函数的实现 rpn_cls_output 为rpn的分类输出 (1, H, W, 2*A)
# (1, H, W, 2A) --> (1, 2A, H, W) --> (1, 2, A * H, W ) --> (1, A * H, W, 2 ) 转换成和label维度一样
shape = rpn_cls_output.shape
rpn_cls_output = tf.transpose(rpn_cls_output, [0, 3, 1, 2])
rpn_cls_output = tf.reshape(rpn_cls_output, [-1, 2, shape[3] // 2 * shape[1], shape[2]])
rpn_cls_output = tf.transpose(rpn_cls_output, [0, 2, 3, 1])
rpn_cls_output = tf.reshape(rpn_cls_output, [-1, 2])最后进行损失计算 最后得到label就会变成前9个为negative得分 后9个为positive得分
如果看不出来可以通过下面的代码测试出来
import numpy as np
a = np.arange(6)
a = a.reshape((1, 1, 1, 6))
a = a.reshape((1, 3, 1, 2))
# (1, H, W, 2K) --> (1, 2K, H, W) --> (1, 2, K * H, W ) --> (1, K * H, W, 2 )
def softmax(cls_output):
rpn_cls_output = np.exp(cls_output)
rpn_cls_output = rpn_cls_output / np.sum(rpn_cls_output, axis=-1, keepdims=True)
return rpn_cls_output
# 这里进行逆transpose
out = softmax(a)
out = np.transpose(out, (0, 3, 1, 2))
out = np.reshape(out, (1, 6, 1, 1))
out = np.transpose(out, (0, 2, 3, 1))
print(out)[[[[0.26894142 0.26894142 0.26894142 0.73105858 0.73105858 0.73105858]]]]
最后我们分析下 RPN网络的损失函数

Here, i is the index of an anchor in a mini-batch and pi is the predicted probability of anchor i being an object. The ground-truth label p∗i is 1 if the anchor is positive, and is 0 if the anchor is negative. ti is a vector representing the 4 parameterized coordinates of the predicted bounding box, and t∗i is that of the ground-truth box associated with a positive anchor. The classification loss Lcls is log loss over two classes (object vs. not object). For the regression loss, we use Lreg (ti, t∗i ) = R(ti − t∗i ) where R is the robust loss function (smooth L1) defined in [2]. The term p∗i Lreg means the regression loss is activated only for positive anchors (p∗i = 1) and is disabled otherwise (p∗i = 0). The outputs of the cls and reg layers consist of {pi} and {ti} respectively.
论文中说的很清楚 第一个部分是类别损失 第二个部分是回归损失
The two terms are normalized by Ncls and Nreg and weighted by a balancing parameter λ. In our current implementation (as in the released code), the cls term in Eqn.(1) is normalized by the mini-batch size (i.e., Ncls = 256) and the reg term is normalized by the number of anchor locations (i.e., Nreg ∼ 2, 400). By default we set λ = 10,
这里我们分析下 为什么Ncls 是256 Nreg约等于2400
其实从上面我们可以看出来 最终送入rpn网络的是256个anchor 128个positive 128个negative 所以进行归一化就是256
Nreg定义是 normalized by the number of anchor locations 就是就是anchor的position 在论文中提到
During training, we ignore all cross-boundary anchors so they do not contribute to the loss. For a typical 1000 × 600 image, there will be roughly 20000 (≈ 60 × 40 × 9) anchors in total.
可以看出Nreg约等于2400
从代码实现看 也可以理解为在 feature_map 的 H, W 维度做reduce_mean