ORACLE的内存结构介绍
1、内存结构汇总
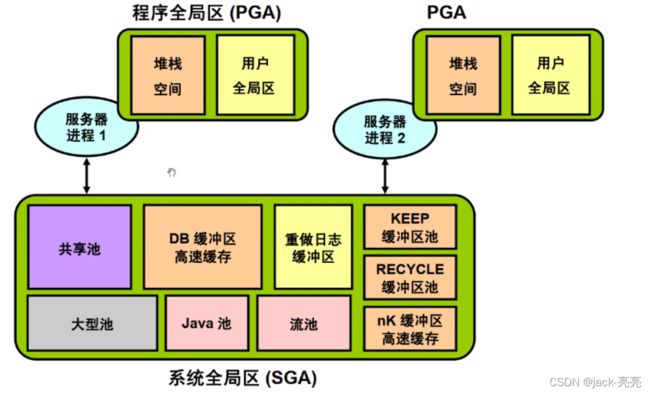
SGA :系统全局区,是oracle的进程共享的内存区域。
sga当中包含6大区域:share pool 共享池
buffer cache 缓冲区高速缓存
redo log buffer 重做日志缓冲区
large pool 大型池
java pool java池
stream pool 流池
注意:sga中主要是share pool、buffer cache和redo log buffer这三块。
pga:进程全局区,是oracle的服务进程(前台进程)独占的内存区域
pga区域包含:堆栈空间
用户全局区 --> UGA
2、SGA - 共享池(share pool)
share pool属于SGA,包含:共享SQL区域(库高速缓存)、数据字典高速缓存、控制结构
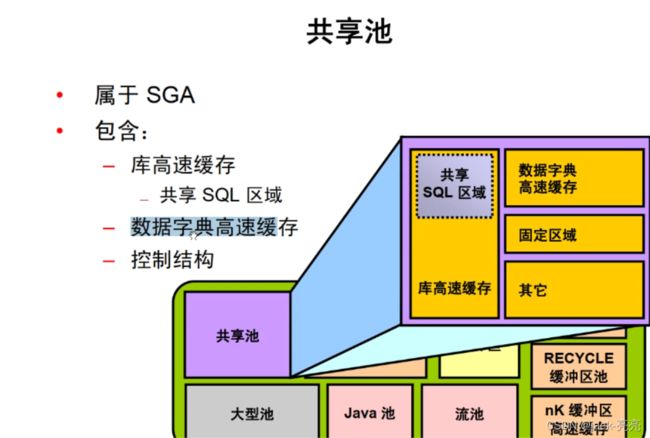
1、共享SQL区域
一条SQL的执行流程:客户端 --> 实例 --> 执行SQL语句(客户端) --> SQL发送给oracle实例
--> SQL解析 --> 产生所谓的执行计划 --> 数据库实例中的优化器会基于各方面的成本进行考虑,选择最优的执行计划 --> 执行SQL语句 --> 将结果返回给客户端
Oracle为了提升执行效率,将执行过的SQL的执行计划包含在共享SQL区域。一旦有后续的SQL需要执行,则先来共享SQL区域中进行SQL对比,如果有完全一样的,有记录,则直接拿记录的执行计划去执行SQL了。从而可以省略了解析SQL和产生执行计划的过程了,可以按照记录的执行计划去执行SQL语句。oracle不区分大写小,但是共享池是严格区分大小写的,要完全一样才能引用。
软解析:直接引用共享SQL区域中的执行计划的解析方式,叫软解析
硬解析:当未匹配到完全一样的SQL的执行计划,则需要SQL进行完整解析,并重新确定执行计划
SQL中的软解析执行效率 高于 硬解析。执行效率:软解析 > 硬解析
例如:select * from test; --> 一旦执行,共享SQL区域会包含该SQL执行的执行计划。
select * from test; -->如果有完全一样的SQL再次执行,则直接调用共享池中的执行计划
来获取最终结果,他存在不是结果,是存的是这条路怎么走。
select * from TEST; --> 重新解析SQL,重新生成执行计划,重新执行
oracle数据库 --> 运行时间越长,性能越好,并且趋于稳定。
2、数据字典高速缓存
data dictionary --> 数据字典
update test set id=100 where name = ‘zhangsan’;
哪些情况会导致SQL执行失败:(1)test表不存在。--> 如果遍历硬盘中的所有表,固然能确定该表是否存在,但是这样效率太低了。所以数据库会自动维护数据字典,包含对象名称,也就是表名,他会加载到内存中的,这样查找表的时候效率就会高很多。为了提升查询表的性能,数据字典会缓存到内存中公进程访问。 (2)name字段不存在 --> 所以需要确认id字段和name是否存在。所以数据字典中会缓存表结构中基本的字段信息。(3)zhangsan这个值不存在。--> 查询数据的操作是在表中完成的。(4)权限不足。 --> 为了提高SQL的执行效率,数据库会自动维护数据字典信息,用于SQL对象确认,权限验证等操作。
3、SGA - 数据库缓冲区高速缓存(buffer cache)
1、缓冲区高速缓存的作用
buffer cache用于缓存数据块。数据块是我们在建库时定义的数据库的基本IO单位。建库时可以定义数据块大小,但是建库完成后不能修改,当时这个单个数据块大小不会影响太大性能。
show parameter block; --> db_block_size = 8192 --> 8K
buffer cache中缓存的就是来自数据库文件中的数据块。
select * from test; --> 涉及到test表的一个数据块,oracle实例会将test表对应的数据块从硬盘加载到内存,进行查询,将结果返回客户端。
update test set id=100 where name = 'zhangsan'; --> oracle实例会将zhangsan数据所在的数据块加载到内存,对buffer cahcae中的数据块进行修改,返回结果给客户端。
所以无论查询还是修改数据,都是先将数据所在的数据块加载到内存,然后执行查询/修改的操作
为什么不直接对硬盘进行修改操作?(1)进程直接修改硬盘上的数据,理论上是可以行的,但是对应数据库软件,需要定位到修改的行数据。(2)oracle实例将数据加载到内存中进行查询和修改以及oracle实际直接修改硬盘数据,这两个过程都涉及到内存中的实例和硬盘中的数据块进行交互。但是如果又有后续的操作涉及到相同的数据,则加载到内存中就不会再发生物理IO,直接写数据到硬盘需要发生再次的物理IO。所以如果再次修改的话,性能会变好。
总结:这个区域就是存放从硬盘加载到内存的数据块,使读取和修改数据都是在内存中完成。用于存放从数据文件读取的数据块副本,由所有并行用户共享。如果只是select大导致数据块被加载上来就是干净数据块,如果数据块又被修改过,则就是脏数据块。
目的:buffer cache是缓存数据块,能够提供和发生逻辑IO,提升数据库性能。
2、undo的作用
select查询会射到数据块的加载,这种情况下,数据块被加载到内存但是不进行修改,内存中的数据块就是硬盘数据库文件中数据块的副本。update涉及到数据块加载和修改,数据块刚刚被加载到内存时,和硬盘中数据库文件中的数据块一致,但是一旦修改,则产生脏数据(脏块)。
buffer cache中的脏块落盘,才能保证已修改数据的安全。但是脏块直接落盘性能很差,oracle中提出了使用redo来保证脏块数据安全。当update修改数据的操作执行完成后,数据块中的数据已经发生了变汉。
undo --> 保存已修改未提交的数据。这样做的目的是保证事务之间是隔离的。
内存 数据块 id=99 --> udpate操作 --> 数据块 id=100
--> undo id=99
在执行update语句的会话中事务未提交执行select查询,查看到的是数据块中当前值 --> id=100
在其他会话中进行select查询,查询到的都是undo中的快照值 --> id=99
undo的作用:(1)支持事务rollback
(2)RC undo解决了脏读问题
3、redo
redo重做日志 --> 一旦事务提交,则redo落盘,相较于脏块直接落盘,redo落盘性能更好
4、事务的隔离性
session1 会话1
session2 会话2
不同的隔离级别决定了事务之前的隔离性。
MySQL的隔离级别:
读未提交 RU 脏读 --> 读取到了未提交的数据
读已提交 RC 解决了脏读问题(undo),出现了幻读(读取其他事务已提交数据,inset引起
的)和不可重复读(读取其他事务已提交数据,update引起的),就是在另一
个会话中,同一个事务中前后select数据不一致
可重复读 RR 解决了欢度问题(间隙锁),解决了不可重复度问题(undo的MVCC),MVCC
是多版本并发控制,在undo中保存多个版本
序列化 串行执行事务,没有并发事务,不使用。
oeacle中也存在事务的概念,事务之前也应该存在隔离性,但是很少讨论oracle的隔离级别。
oracle的隔离级别:读已提交 RC(默认隔离级别,但是会存在幻读和不可重复度的问题)
序列化 串行执行事务,没有并发事务,不使用。
只读模式 只读模式的事务只能进行select操作,不能进行insert、update、
delete操作。
5、keep缓冲区池和pecycle缓冲区池
这个也是属于buffer cache中的一块区域,因为db缓冲区高速缓存buffer cache,当数据块加载到buffer cache满了之后,就要刷下去数据块,oracle中会将不用的数据块加载到keep缓冲区池中,如果keep缓冲区池中在不用的时候,就会被刷到pecycle缓冲区池中。如果要被替换数据块的话,就从pecycle缓冲池。这就叫二级缓存。
6、nK缓存区高速缓存
dbca建库后,一般数据块默认使用8K的数据块,8K的数据块加载到内存中,但是如果要加载16k的数据块,则会放到nk缓存区高速缓存中。
4、SGA - 重做日志缓冲区(redo log buffer)
redo log buffer 重做日志缓冲区 --> 用于缓存redo log(重做日志)
redo log实际上就是我们进行DML操作时,对数据块进行修改产生的日志信息。
例:原id = 99,update id=100 --> 修改操作是发生在内存的数据块中的。 现在id=100
但是id=100的是脏数据,所在的数据块叫脏块,脏块保存在内存中数据是不安全的,要求数据尽快落盘,落盘才能保证数据是持久化的。脏块直接落盘性能太差,引入redo log的机制来代替脏块直接落盘。所以在现在的传统关系型数据库中,保证数据持久性机制,都是通过redo机制来保证的。
对数据块修改 --> 脏块 --> 保存在buffer cache中
--> 日志信息 --> redo log --> redo log buffer --> 日志优先落盘
日志有限落盘的好处:(1)日志数据量小于数据块数据量
(2)顺序IO(日志有限落盘)性能高于随机IO(脏块落盘)
redo log buffer中的redo log是同步落盘的,buffer cache中的脏块是异步落盘的。
redo log的好处:(1)日志优先落盘,日志数据量小,提高数据库效率保证安全。
(2)一旦数据库崩溃或者发生异常,启动数据库实例时,可以使用硬盘中的
数据页 + redo重构脏页。
5、SGA - 大型池(large pool)
为以下对象提供大型内存分配:(1)共享服务器和oracle XA接口的会话内存。(2)IO服务器进程。(3)oracle DB备份和还原操作。
服务器进程 --> 客户端连接,在oracle数据库服务器中产生服务器进程。服务器进程的工作是一对一的。就是一个服务器进程使用一块PGA空间,为一个用户连接/会话提供服务器。
共享服务器 --> 一对多的工作场景,监听进程的工作机制相关,就是一个进程服务器多个对象。
大型池和oracle的备份恢复操作相关。
6、PGA - 用户全局区(UGA)
当中包含UGA --> 用于全局区
UGA的作用:(1)保存会话信息。(2)用户查询排序。
当用户执行查询操作并且对查询结果进行排序。
select * from test order by id; --> 查询test表汇总所有行记录,并按照id排序。
MySQL --> 索引组织表。mysql会自动基于主键创建聚簇索引,并且向表中插入数据时,数据会按照聚簇索引段/主键值进行排序存放。mysql中存放的数据是有序的(主键值数据有序的)。
oracle --> 支持堆表和索引组织表,现在用的都是堆表。所以oracle数据表中存放的数据是不进行排序的,数据是无序的。堆表中的数据顺序取决于插入顺序。
我们对数据的排序操作,并不是在物理的数据块中直接进行的,而是先获取数据块中的数据,然后进行排序操作,排序的地方区域:(1)UGA --> 数据量小。(2)临时表空间 --> 数据量大。