匿名内部类访问局部变量为什么要加final?
这一切都始于对final关键字的追问......
一、匿名内部类如何访问到外部变量?
我们参考大佬的这篇文章中引用的例子,来看一下匿名内部类访问外部变量的方法:
public class Hello {
public static void main(String[] args) {
String str="haha";
new Thread() {
@Override
public void run() {
System.out.println(str);
}
}.start();
}
}这里我们用匿名内部类的方式开一个子线程,在其中访问外部变量str
我们将这段代码反编译,得到以下代码:
public class Hello$1 extends Thread {
private String val$str;
Hello$1(String paramString) {
this.val$str = paramString;
}
public void run() {
System.out.println(this.val$str);
}
}可以看到匿名内部类的构造器中传入了一个参数,我们可以推理出这个参数就是底层传入的str的值,也就是说匿名内部类之所以可以访问局部变量,是因为在底层将这个局部变量的值传入到了匿名内部类中,并且以匿名内部类的成员变量的形式存在,这个值的传递过程是通过匿名内部类的构造器完成的。
看到这里不知道大家有没有产生一个疑惑:在匿名内部类的构造器中传入的这个参数,它到底是一个拷贝后的值还是一个引用?类似于C/C++里面常见的传值还是传地址的区别,这个传入的参数如果只是一个和原有实际参数相等的值,那么一旦外部修改了这个值,在我们的匿名内部类中,这个值依然不会改变,这显然会带来问题;而如果其是一个引用,则不会出现这个问题。
二、Java中参数的传递方式
Java唯一的参数传递方式———按值传递
读者们如果想阅读详细的论证过程,可以参考大佬的这篇文章,结论就是上面那句话,但是要真正理解这句话,我们按照Java的数据类型分成两类进行分析:
1.传递基本数据类型时
基本类型(primitive types), 共有8种,即int, short, long, byte, float, double, boolean, char(注意,并没有string类型)。这种类型的定义是通过诸如int a = 3; long b = 255L;的形式来定义的,称为自动变量。值得注意的是,自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在。如int a = 3; 这里的a是一个指向int类型的引用,指向3这个字面值。这些字面值的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。
在传递位于栈中的基本数据类型时,Java会直接传入原数据的拷贝值,因为是直接拷贝的值,所以在匿名内部类的外部对参数进行操作不会对已经传入的变量产生影响
2.传递包装类数据时
包装类数据,如Integer, String, Double和各种类等等将相应的基本数据类型包装起来的类。这些类数据全部存在于堆中。
题外话,Java中内存存储的划分及规则为:
| 内存划分 | 说明 | 示例 |
| 寄存器 | 最快的存储区, 由编译器根据需求进行分配,在程序中无法控制 | 略 |
| 栈 | 存放基本类型的变量数据和对象的引用,但对象本身不存放在栈中,而是存放在堆(new 出来的对象)或者常量池中(字符串常量对象存放在常量池中) | int a = 3 |
| 堆 | 存放所有new出来的对象 | Integer a = new Integer() |
| 静态域 | 存放静态成员 | static定义的 |
| 常量池 | 存放字符串常量和基本类型常量 | public static final |
| 非RAM存储 | 硬盘等永久存储空间 | 略 |
表1 Java内存分配
在传递包装类型数据时,传递的是复制过的对象引用(地址),注意这个引用(地址)是复制过的,也就是说又新建了一块内存并在这块内存中又保存了复制后的一份引用(地址),这时候有两个引用(地址)是指向同一个对象的,所以不管外部或内部改变这个引用(地址)对应空间的数据,其本身值都会受到影响,虽然是复制的但是引用(地址)指向的是同一个地址,当你把这个引用(地址)指向其他对象的引用时并不会改变原对象,因为你拿到的引用(地址)是复制过的引用,而不是原引用本身。
附上几张张原创图片帮助大家理解:

图1 实际参数
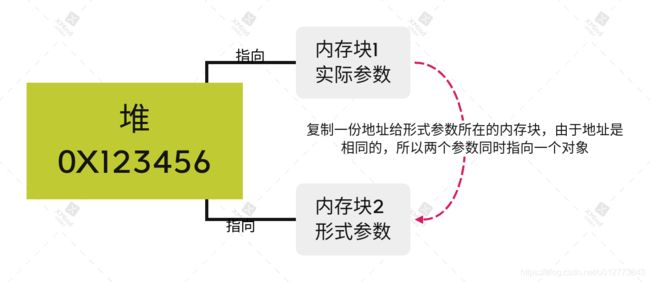
图2 实际参数传递给形式参数

图3 将形式参数指向其他对象的引用
总结:Java中的引用(地址)是复制过的,正因为其传递的是复制过的引用(地址)的值,所以说Java只有值传递
是不是觉得有些绕?确实,那不妨来听一下下面这段解释:
Java的这种参数传递方式一定不是引用传递,因为如果是引用传递,修改形式参数的指向,原实际参数的指向一定也会改变,所以它只能是值传递,但是这种值传递和我们平时理解的又有些不同,其实无论是值传递还是引用传递,其实都是一种求值策略(Evaluation strategy)。在求值策略中,还有一种叫做按共享传递(call by sharing)。其实Java中的参数传递严格意义上说应该是按共享传递。
按共享传递,是指在调用函数时,传递给函数的是实参的地址的拷贝(如果实参在栈中,则直接拷贝该值)。在函数内部对参数进行操作时,需要先拷贝的地址寻找到具体的值,再进行操作。如果该值在栈中,那么因为是直接拷贝的值,所以函数内部对参数进行操作不会对外部变量产生影响。如果原来拷贝的是原值在堆中的地址,那么需要先根据该地址找到堆中对应的位置,再进行操作。因为传递的是地址的拷贝所以函数内对值的操作对外部变量是可见的。
三、匿名内部类访问局部变量为什么要加final?
让我们回到最初的问题,如果你已经理解了我上面所讲的内容,那么就不难得出结论:
1.解释之一
用final修饰实际上就是为了保护数据的一致性
这里所说的数据一致性,对包装类数据(引用变量)来说是引用地址的一致性,对基本类型来说就是值的一致性。
将数据拷贝完成后,如果不用final修饰,则原先的局部变量可以发生变化。这里到了问题的核心了,如果局部变量发生变化后,匿名内部类是不知道的(因为他只是拷贝了局部变量的值,并不是直接使用的局部变量)。这里举个栗子:原先局部变量指向的是对象A,在创建匿名内部类后,匿名内部类中的成员变量也指向A对象。但过了一段时间局部变量的值指向另外一个B对象,但此时匿名内部类中还是指向原先的A对象。那么程序再接着运行下去,可能就会导致程序运行的结果与预期不同。
这个解释已经非常有说服力了,但是我查阅众多博客,又找到了另一种说法......
2.解释之二
先来看一张图:
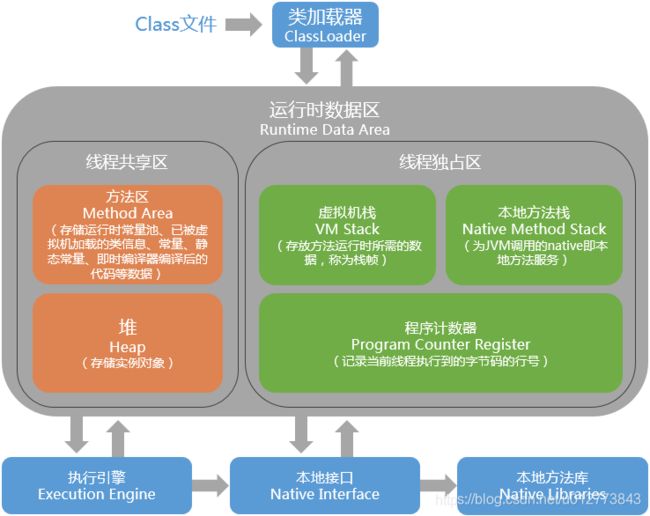
如图所示,结合之前的表1,我们知道局部变量创建之后(假如在主线程),其保存在虚拟机栈区域,当我们新建另一个线程后,新线程是不能访问其他线程中的虚拟机栈的(因为虚拟机栈位于线程独占区),所以需要使用final关键字修饰,使这个变量变成一个常量,从而进入常量池,被保存在线程共享区的方法区中,这样就可以被其他线程访问到了,总结一下,使用final关键字的原因是:
使变量转化为常量进入常量池,从而使其可以被其他线程访问
这两种说法我觉得都有道理,或许都是对的,或许只有其中一个正确,希望有大神看到之后能给我一个最合理的答案
在网上还有另一个比较流行的解释,这个解释认为:
final的作用就是延长局部变量的生命周期,局部变量如果没有用final修饰,他的生命周期和方法的生命周期是一样的,当方法弹栈,这个局部变量也会消失,那么如果局部内部类对象还没有马上消失想用这个局部变量,就没有了,如果用final修饰,那么常量会在类加载的时候进入常量池,即使方法弹栈,常量池的常量还在,也可以继续使用。
我个人觉得这个解释不太合理,局部变量确实会被回收没错,但是根据反编译的结果可以看出,局部变量已经被传入到内部类中了,在传入的时候进行了拷贝,既然我已经有了一份拷贝,那我就不需要原来的局部变量了,那么局部变量的回收和我又有什么关系呢?
以上,希望读者可以踊跃讨论并指出我的错误,谢谢!