剖析强化学习 - 第四部分
作者:Massimiliano Patacchiola
这是“解剖强化学习”系列的第四篇。在这篇文章中,我将介绍另一组广泛用于强化学习的技术:Actor-Critic(AC)方法。我经常将AC定义为一种元技术,它使用以前的帖子中介绍的方法来学习。基于AC的算法是强化学习中最流行的方法之一。例如,Google DeepMind的一些研究人员最近推出的Deep Determinist Policy Gradient算法是一种无模型的actor-critic方法。此外,AC框架与神经科学和动物学习有很多联系,特别是基底节(basalganglia)模型(Takahashi et al。2008)。

AC方法在我推荐的书中都没有准确地描述。例如在Russel和Norvig以及 Mitchell的书中,他们根本没有被覆盖。在经典的Sutton 和Barto的书中,也只有三个短段落(2.8,6.6,7.7),然而在第二版中第15章(神经科学)增加了对神经元AC方法的更广泛描述。“强化学习简介”一文中涵盖了强化学习技术的元分类。这里我将从神经科学开始介绍AC方法,你可以把这篇文章看作是第三篇的神经生理学文章,从心理和行为主义的角度引入时分(TD)方法。
Actor-Critic方法(老鼠)
强化学习与神经科学密切相关,而且这方面的研究往往推动了计算领域新算法的实现。在这个观察之后,我将介绍AC方法,并对神经科学领域进行简短的介绍。如果你有纯粹的计算背景,你会学到新的东西,我的目标是让你更深入地了解强化学习(扩展)世界。为了理解这些内容,你应该首先熟悉神经系统的基本结构。什么是神经元?神经元如何使用突触和神经递质进行交流?什么是大脑皮层?你不需要知道细节,在这里我想让你知道一般的概念。我们从多巴胺开始,多巴胺(Dopamine)是一种神经调节剂,它在人类和动物大脑的一些最重要的过程中起作用,你可以看到多巴胺是作为使神经元进行交流的信使。多巴胺在哺乳动物大脑的不同过程中起着重要作用(如学习,动机,成瘾),它在两个特定区域产生:黑质致密部(substantia nigra pars compacta)和腹侧被盖区(ventral tegmental area)。这两个区域直接投射到大脑的另一个区域纹状体。纹状体分为两部分:腹侧纹状体(ventral striatum)和背侧纹状体(dorsal striatum),纹状体的输出指向运动区域(motor areas)和前额叶皮层(prefrontal cortex),并且涉及运动控制和规划。

以前引用的大部分区域都是基底神经节的一部分。有不同的模型发现了基底神经节与学习之间的联系,特别是,似乎多巴胺神经元的阶段性活动可以在对未来预期奖励的新旧估计之间提供误差,这个误差与我在第三篇文章中介绍的TD学习中的误差非常相似。在详细讨论之前,我想简单区分两组的基底神经节机制:
1.腹侧纹状体,黑质,腹侧被盖区
2.背侧纹状体和运动区域
这些组织没有具体的生物学名称,但我会为这两组定义两个名称。第一组可以基于相关奖励来评估刺激的显著性,同时,它可以估计一个比较动作结果和直接后果的误差度量,并使用这个值来校准执行者。由于这些原因,我会称它为评论者(critic)。第二组可以直接获得动作,但无法估计刺激的效用,因为我称它为执行者(actor)。

actor与critic之间的互动对学习起着重要作用。特别是一致的研究表明,基底神经节参与巴甫洛夫的学习(见第三篇文章)和程序性(隐性)记忆(procedural(implicit) memory),意味着无意识的记忆,如技能和习惯。另一方面,获取事实性信息时隐含的声明性(显性)记忆(declarative(explicit) memory)似乎与另一个称为海马的区域有关。actor和critic交流的唯一方式是通过刺激腹侧纹状体后从黑质中释放的多巴胺。药物滥用可能会对多巴胺系统产生影响,改变了actor和critic之间的交流。Takahashi等人(2007)的实验表明,老鼠中的可卡因敏化可能会导致不合适的决策,特别是老鼠会受到立即获得奖励的短期利益驱动而不是长期目标的驱动。这个问题出现在任何标准的计算框架中,并且被称为信用分配(creditassignment)问题。例如,在下棋时,要隔离导致最终胜利的关键动作并不容易。

为了解神经元的actor-critic机制如何参与信用分配问题,Takahashi等人(2008)在Go / No-Go任务中观察了用可卡因预敏化的老鼠的表现。Go / No-Go任务的过程很简单,老鼠在一个小金属盒子里,当特定的气味(提示)被释放时,它必须学会用鼻子戳一个按钮。如果在出现积极的气味时老鼠戳按钮,它会得到奖励(糖);如果在出现消极的气味时老鼠戳按钮,它会得到苦味的物质(如奎宁)。这里的积极和消极的气味并不意味着他们愉快或不愉快,我们可以认为他们是中立的。学习意味着将特定的气味与奖励,另一种特定的气味与惩罚联系起来。最后,如果老鼠不移动(No-Go),那么奖励和惩罚都不会被给出。总共有四种可能的情况。

已经观察到,用可卡因预敏化的老鼠不能学习这一任务,可能是因为可卡因破坏了基底神经节,并且critic返回的信号变得不正常。为了检验这个假设,Takahashi等人(2008)在实验前1-3个月对一组老鼠敏化,然后将其与非敏化对照组进行比较。实验结果表明,对照组的老鼠在出现积极性气味时可以学习如何获得奖励,以及如何在出现消极性气味时采取no-go策略以避免处罚。对基底神经节的观察表明,腹侧纹状体(critic)产生了一些提示选择性神经元,当气味出现时被激发。这种神经元在训练期间被开发,并且它们的活动先于背侧纹状体(actor)中的响应。

另一方面,可卡因敏化的老鼠在训练期间没有显示任何种类的提示选择性。此外验尸分析表明,这些老鼠没有发展腹侧纹状体中的提示选择性神经元(critic)。这些结果证实了critic学习提示的作用并且训练actor关于要执行的动作的假设。
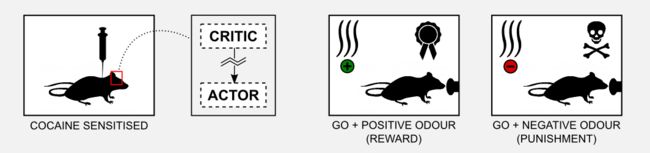
在本节中,我向您展示了AC框架如何与哺乳动物大脑的神经生物学密切相关。这种计算模型是优雅的,它可以解释像巴甫洛夫学习和吸毒成瘾的现象。然而,模型的优雅不应该阻止我们质疑它。事实上,在不同的实验中这种现象并未得到证实,例如,某种形式的刺激-奖励学习可以在没有多巴胺的情况下发生,此外,多巴胺细胞可以在刺激之前激发,这意味着它的价值不能用于更新。对于神经元AC模型及其极限的一个很好的回顾,我建议你阅读Joel等人(2002年)的文章。
现在是把注意力转向数学和代码的时候了,下面解释我们如何从生物模型中获得一个通用的计算模型?
重建Actor-Critic方法
在最后一节中,我提出了基于AC框架的基底神经节的神经元模型。在这里,使用我们迄今为止研究的强化学习技术重新建立该模型,目标是获得可用于一般情况(例如4x3网格世界)下的计算版本。AC算法的第一个实现是由Witten(1977)提出的,然而术语Actor和Critic后来被Barto等人(1988)引入来解决杆子平衡问题。首先,我们如何表示critic? 在神经元版本中,critic无法访问这些动作,对critic的输入是通过大脑皮层获得的信息,我们可以将其与通过传感器(状态估计)由Agent获得的信息进行比较。此外,critic收到了直接来自环境的奖励。critic可以用效用函数来表示,效用函数根据在每次迭代中收到的回报信息进行更新。在无模型强化学习中,我们可以使用TD(0)算法来表示critic,来自黑质和腹侧被盖区域的多巴胺输出可以由TD(0)返回的两个信号表示,即更新值和误差估计δ。在实践中,我们使用更新信号来改进效用函数和更新actor的误差。我们如何表示actor?在神经系统中,actor从大脑皮层接收输入,我们可以在传感器信号(当前状态)中转换,背侧纹状体投射到运动区域并执行动作。同样,我们可以使用包含每个状态的可能动作的状态-动作矩阵,该动作可以通过ε-greedy(或softmax)策略进行选择,然后使用critic返回的误差进行更新。一图胜千言:

我们可以总结AC算法的步骤如下:
1.产生动作atst
2.观察下一个状态st+1和奖励r
3.更新状态st的效用
4.使用δ(actor)更新动作的概率
在步骤1中,Agent根据当前策略生成一个动作。在之前的文章中,我使用ε-greedy策略来选择动作并更新策略。在这里,我将使用softmax函数选择某个动作:
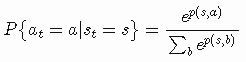
执行动作后,我们观察新的状态和奖励(步骤2)。在步骤3中,我们在TD(0)中的标准更新公式中使用奖励、st和st+1的效用(请参阅第三篇文章):
![]()
在步骤4中,我们使用误差估计δ更新策略。实际上,步骤4包括使用误差δ和一个正的步长参数β增强或减弱动作的概率:
![]()
就像在TD案例中一样,我们可以在AC方法中集成资格痕迹机制(请参阅第三篇文章)。然而在AC案件中,我们需要两套痕迹,一个是actor,另一个是critic。对于critic,我们需要为每个状态存储一个痕迹并更新它们如下:
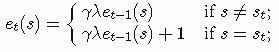
与我在第三篇文章中介绍的TD(λ)方法没有什么不同。一旦我们估计了痕迹,可以更新状态如下:
![]()
对于actor,我们必须为每个状态-动作对存储一个痕迹,类似于SARSA和Q-learning。痕迹可以更新如下:
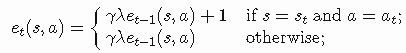
最后,选择动作的概率更新如下:
![]()
太好了,我们获得了我们的通用计算模型,用于标准强化学习场景。现在我想直接给出一个简单问题的答案:计算模型是否解释了神经生物学观察?显然是的。在上一节中,我们看到了Takahashi等人(2008)观察到用可卡因敏化的老鼠中的actor和critic之间的相互作用存在一些异常。滥用药物似乎恶化了critic对actor的多巴胺反馈。从计算的角度来看,我们可以观察到类似的结果,无论当前状态如何这时所有的U(s) 都是一样的。在这种情况下,由critic产生预测误差δ (γ = 1)直接降低了可用的奖励:
![]()
这个结果解释了为什么信贷分配问题在可卡因敏化老鼠的训练期间出现,老鼠喜欢直接奖励,并没有考虑到长期的目标,仅基于即时奖励的学习信号不足以学习复杂的Go / No-Go任务。矛盾的是,同样的结果解释了为什么在简单的任务中立即采取行动,可卡因敏化老鼠的学习速度会更快,但对于神经科学家来说,这个解释可能太过简单。最近的研究强调了在哺乳动物大脑中并行运行的多种学习系统的存在,这些系统中的一些(例如杏仁核和/或伏隔核)可以代替失灵的critic并补偿可卡因敏化造成的损害。总之,需要额外的实验来阐明神经元AC结构。
现在是编码的时候了。在下一节中,我将向您展示如何在Python中实现AC算法以及如何将其应用于清洁机器人示例。
Actor-Critic的Python的实现
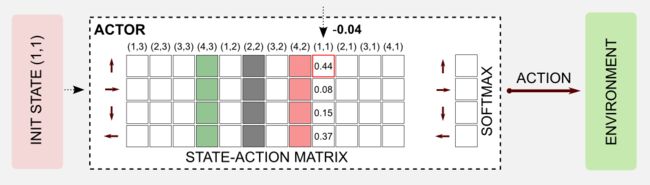
使用之前讲述的知识,我们可以轻松创建一个Python脚本来实现AC算法。像往常一样,我将使用清洁机器人示例和4x3网格世界。要理解这个例子,你必须阅读第一篇文章中介绍的网格世界的规则。首先我将描述一般的架构,然后我将在一个episode中逐步描述算法,最后我会用Python实现所有的东西。在完整的架构中,我们可以使用效用函数(状态矩阵)来表示critic。矩阵初始化为零,并通过TD学习在每次迭代中更新。例如,在第一步之后,机器人从(1,1)移动到(1,2),并获得-0.04的奖励。actor由一个状态-动作矩阵来表示,这个矩阵类似于建模Q函数时引入的矩阵。每当观察到新状态时,就会返回一个动作并且机器人会移动。这里出于易于绘图的原因,我将绘制一个空的状态动作矩阵,但想象表中的值已经初始化为随机抽样范围[0,1]中的实数。

在这里考虑的episode中,机器人从状态(1,1)的左下角开始,并且在七步后到达充电站(奖励=+ 1.0)。

首先要做的是选择动作。对状态-动作表(actor)的查询允许返回当前状态的动作向量,在我们的例子中是[0.48,0.08, 0.15, 0.37]。动作向量被传递给softmax函数返回概率分布 [0.30, 0.20, 0.22, 0.27]。使用Numpy方法np.random.choice()从分布中抽样返回UP。

这里softmax函数将N维动作向量x作为输入并返回一个N维矢量,范围为[0,1]中的实数值,加起来为1。 softmax函数可以很容易地在Python中实现,但与原始的softmax方程式不同,在这里我将在指数中用numpy.max()来避免近似误差:
def softmax(x):
'''Compute softmax values of array x.
@param x the input array
@return the softmax array
'''
return np.exp(x - np.max(x)) / np.sum(np.exp(x - np.max(x)))执行动作之后达到新的状态,并获得奖励(-0.04),接着critic更新状态值并估计误差δ。这里我使用了以下参数:α = 0.1、β = 1.0、和γ =0.9,应用更新规则(算法的第3步),我们获得状态(1,1)的新值:0.0 +0.1[-0.04 + 0.9(0.0) - 0.0] = -0.004。同时可以计算误差δ 如下:-0.04 +0.9(0.0) - 0.0 = -0.04
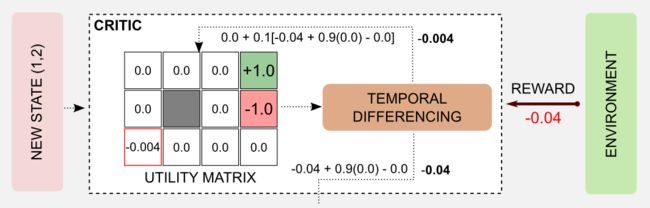
机器人处于新状态,critic评估现在必须用来更新actor的状态-动作表的误差。在这一步中,加上负项δ,状态(1,1)的动作UP被削弱。而在正δ的情况下该动作将得到加强。
现在我们可以想象重复相同的步骤直到episode结束,所有的动作都将被削弱,但最后一个动作将被加强+1.0的因子。重复更多其他episode的过程导致一个最佳效用矩阵和一个最佳策略。
下面是Python实现。首先,我们必须创建一个函数来更新效用矩阵(critic),名称是update_critic,输入参数是utility_matrix、observation和new_observation状态,然后是通常的超参数。该函数返回更新的效用矩阵和用于更新actor 的估计误差delta。
def update_critic(utility_matrix, observation, new_observation,
reward, alpha, gamma):
'''Return the updated utility matrix
@param utility_matrix the matrix before the update
@param observation the state obsrved at t
@param new_observation the state observed at t+1
@param reward the reward observed after the action
@param alpha the ste size (learning rate)
@param gamma the discount factor
@return the updated utility matrix
@return the estimation error delta
'''
u = utility_matrix[observation[0], observation[1]]
u_t1 = utility_matrix[new_observation[0], new_observation[1]]
delta = reward + gamma * u_t1 - u
utility_matrix[observation[0], observation[1]] += alpha * (delta)
return utility_matrix, delta函数update_actor用于更新状态-动作矩阵,传递给函数的参数是state_action_matrix、observation、action、update_critic返回的估计误差delta,和超参数的β,该参数可采用矩阵的形式,其中每个元素计数一个特定的状态-动作对被访问了多少次。
def update_actor(state_action_matrix, observation, action,
delta, beta_matrix=None):
'''Return the updated state-action matrix
@param state_action_matrix the matrix before the update
@param observation the state obsrved at t
@param action taken at time t
@param delta the estimation error returned by the critic
@param beta_matrix a visit counter for each state-action pair
@return the updated matrix
'''
col = observation[1] + (observation[0]*4)
if beta_matrix is None: beta = 1
else: beta = 1 / beta_matrix[action,col]
state_action_matrix[action, col] += beta * delta
return state_action_matrix 这两个函数在主循环中使用,探索开始的假设是为了保证统一的探索。这里没有使用参数beta_matrix,但可以轻松启用。
for epoch in range(tot_epoch):
#Reset and return the first observation
observation = env.reset(exploring_starts=True)
for step in range(1000):
#Estimating the action through Softmax
col = observation[1] + (observation[0]*4)
action_array = state_action_matrix[:, col]
action_distribution = softmax(action_array)
#Sampling an action using the probability
#distribution returned by softmax
action = np.random.choice(4, 1, p=action_distribution)
#beta_matrix[action,col] += 1 #increment the counter
#Move one step in the environment and get obs and reward
new_observation, reward, done = env.step(action)
#Updating the critic (utility_matrix) and getting the delta
utility_matrix, delta = update_critic(utility_matrix, observation,
new_observation, reward,
alpha, gamma)
#Updating the actor (state-action matrix)
state_action_matrix = update_actor(state_action_matrix, observation,
action, delta, beta_matrix=None)
observation = new_observation
if done: break像往常一样,完整代码我上传在官方的GitHub库名为actor_critic.py。使用gamma = 0.999和alpha = 0.001运行脚本,我获得了以下的效用矩阵:
Utility matrix after 1001 iterations:
[[-0.02564938 0.07991029 0.53160489 0. ]
[-0.054659 0. 0.0329912 0. ]
[-0.06327405 -0.06371056 -0.0498283 -0.11859039]]
...
Utility matrix after 150001 iterations:
[[ 0.85010645 0.9017371 0.95437213 0. ]
[ 0.80030524 0. 0.68354459 0. ]
[ 0.72840853 0.55952242 0.60486472 0.39014426]]
...
Utility matrix after 300000 iterations:
[[ 0.84762914 0.90564964 0.95700181 0. ]
[ 0.79807688 0. 0.69751386 0. ]
[ 0.72844679 0.55459785 0.60332219 0.38933992]]比较第一篇文章中使用AC获得的结果和动态编程获得的结果,我们可以注意到一些差异。

类似于第三篇文章中的TD(0)的估计,两个终止状态的值为零。这是事实的结果,我们无法估计终止状态的更新值,因为在终止状态之后没有另一个状态。正如在第三篇文章中所讨论的那样,这不是一个大问题,并且不会以任何显著的方式影响收敛。从实际的角度来看,使用AC算法得到的结果可能会不稳定,因为有更多的超参数需要调整,但范式(paradigm)的灵活性往往可以平衡这个缺点。
Actor-only和 Critic-only方法
在Sutton和Barto的书中, AC方法被认为是TD方法的一部分。这是有道理的,因为critic是TD(0)算法的一种实现,并且按照相同的规则进行更新。问题是:为什么我们应该使用AC方法而不是TD学习?AC方法的主要优点是由critic返回的δ是由外部监督者(supervisor) 度量产生的误差,我们可以用这个措施来调整监督学习的策略。从这个意义上讲,使用外部监督者可以减少纯Actor-only 方法的方差。当我介绍函数逼近时,这些方面会更加清晰。AC方法的另一个优点是动作选择需要最少的计算。直到现在,我们总是使用一些离散数量的可能动作。当动作空间是连续的并且可能的动作数量是无限的时,在这个无限集合中搜索最优动作在计算上是无法实现的。AC方法可以将策略表示为单独的离散结构,并用它来找到最佳的动作;AC方法的另一个优点是它们与哺乳动物大脑中的奖励机制相似,这种相似性使AC方法成为心理学和生物学模型。总结来说,使用AC方法有三个优点:
1.在函数逼近时的方差减小
2.在连续动作空间中的计算效率
3.与哺乳动物大脑中生物奖励机制的相似性
从分类学的角度来看,actor和critic之间的区别也非常有用。在文章“ReinforcementLearning in a Nutshell”一文中, AC方法被认为是一个元类别,它可以用于将我介绍的所有技术分配到三组:AC方法、Critic-only、 Actor-only。在这里,我将采用类似的方法对其中的内容进行更广泛地涉猎,在这篇文章中,我介绍了一种AC算法的可能架构。在AC方法中,actor和critic被显示地表示和分开训练,但是是否可能仅使用actor还是仅使用critic? 在之前的文章中,我总是使用效用函数和策略。在动态规划中,这两个实体在值迭代和策略迭代算法中收敛(请参阅第一篇文章),然而,它们都是基于效用估计的,因为策略可以通过广义策略迭代(GPI)机制实现收敛(见第二篇文章)。事实上,在TD学习中,即使重点基于策略(SARSA和Q-learning),我们也总是依赖效用估计(请参阅第三篇文章)。所有这些方法可以大致分为一类称为Critic-only的类别,Critic-only方法总是在效用函数之上建立一个策略,正如我所说的,效用函数是AC框架中的critic。

如果我们在不使用效用函数的情况下搜索最优策略会怎样?是否可能?答案是肯定的。我们可以使用Actor-only方法直接在策略空间中进行搜索,称为REINFORCE(REward Increment =非负因子x偏移增强x特征资格)的一类算法可以被认为是Actor-only 组的一部分。REINFORCE度量局部动作与Agent的全局性能之间的相关性并更新神经网络的权重。由于理解REINFORCE需要了解通过神经网络的梯度下降和泛化(我将在本系列的后面介绍)的知识,我想关注另一种称为演进算法的Actor-only技术。演进算法可使用范围广泛的技术,但在强化学习中通常使用遗传算法。使用遗传算法意味着将每个策略表示为Agent问题的可能解决方案。假设有10台清洁机器人并行工作,每台机器人使用不同的(随机初始化)策略,在100个episode之后,我们可以估计每个单个机器人的策略有多好。我们可以保留最好的机器人并随机改变他们的策略,以创造新的机器人。经过几代的进化,选择了最好的策略,其中我们可以(可能)找到最优策略。在经典强化学习教科书中,遗传算法没有涉及。我在自主机器人和人工生命实验室(LARAL)作为研究员的职业生涯中,在进化机器人学中我使用遗传算法来研究模拟机器人在不同生态环境中移动的决策策略。为了分享这方面的研究成果,我将在下一篇文章中花费更多篇幅讲解遗传算法的知识。
结论
从哺乳动物大脑的神经生物学开始,我介绍了AC方法,这是一类被研究界广泛使用的强化学习算法。神经元AC模型可以描述像巴甫洛夫学习和毒瘾这样的现象,而其计算对象可以很容易地应用于机器人学和机器学习。第三篇文章中介绍的基于TD(0)算法的Python实现非常简单。考虑到TD(0)算法作为AC方案的一部分,可以使我们得出AC方法是TD的一种变化的结论。但是,我们可以将其转化并将AC方法视为最大的类别,并将TD方法作为它的一部分,从这个角度来看,我将TD算法分类为Critic-only方法,某些技术如REINFORCE和遗传算法作为Actor-only的方法。在接下来的文章我将重点放在遗传算法,一种允许在不需要效用函数的策略空间中直接进行搜索的方法。
索引
1. [第一篇]马尔科夫决策过程,贝尔曼方程,值迭代和策略迭代算法。
2. [第二篇]蒙特卡罗概念,蒙特卡洛方法,预测与控制,广义策略迭代,Q函数。
3. [第三篇]时间差分概念,动物学习,TD(0), TD(λ)和资格痕迹,SARSA,Q-learning。
4. [第四篇]Actor-Critic方法背后的神经生物学,计算Actor-Critic方法,Actor-only和Critic-only方法。
5. [第五篇]进化算法介绍,强化学习中的遗传算法,遗传算法的策略选择。
6. [第六篇]强化学习应用,多臂老虎机,山地车,倒立摆,无人机着陆,难题。
7. [第七篇]函数逼近概念,线性逼近器,应用,高阶逼近器。
8. [第八篇] 非线性函数逼近,感知器,多层感知器,应用,政策梯度。
资源
· The complete code for theActor-Critic examples is available on the dissecting-reinforcement-learning officialrepository on GitHub.
· Reinforcement learning:An introduction. Sutton, R. S., & Barto, A. G. (1998). Cambridge: MITpress. [html]
· Reinforcement learning:An introduction (second edition). Sutton, R. S., &Barto, A. G. (in progress). [pdf]
· Reinforcement Learningin a Nutshell. Heidrich-Meisner, V., Lauer, M., Igel, C., &Riedmiller, M. A. (2007) [pdf]
参考
Barto, A. G., Sutton, R. S., & Anderson, C. W. (1983).Neuronlike adaptive elements that can solve difficult learning controlproblems. IEEE transactions on systems, man, and cybernetics, (5), 834-846.
Heidrich-Meisner, V., Lauer, M., Igel, C., & Riedmiller, M.A. (2007, April). Reinforcement learning in a nutshell. In ESANN (pp. 277-288).
Joel, D., Niv, Y., & Ruppin, E. (2002). Actor–critic modelsof the basal ganglia: New anatomical and computational perspectives. Neuralnetworks, 15(4), 535-547.
Takahashi, Y., Roesch, M. R., Stalnaker, T. A., &Schoenbaum, G. (2007). Cocaine exposure shifts the balance of associativeencoding from ventral to dorsolateral striatum. Frontiers in integrativeneuroscience, 1(11).
Takahashi, Y., Schoenbaum, G., & Niv, Y. (2008). Silencingthe critics: understanding the effects of cocaine sensitization on dorsolateraland ventral striatum in the context of an actor/critic model. Frontiers inneuroscience, 2, 14.
Williams, R. J. (1992). Simple statistical gradient-followingalgorithms for connectionist reinforcement learning. Machine learning, 8(3-4),229-256.
Witten, I. H. (1977). An adaptive optimal controller fordiscrete-time Markov environments. Information and control, 34(4), 286-295.