LeetCode-178-分数排名(面试必备)
LeetCode-178-分数排名
本文中带来的是LeetCode-SQL的第178题,讲解的是关于MySQL中的排名问题,非常重要和实用的一篇文章,真心建议搜藏保存:
- 题目介绍
- 分析思路
- 3种不同窗口函数
- MySQL5 中实现开窗函数

最初接触到SQL中的排名是在一名日本作者MICK写的书中:《SQL进阶教程》,感兴趣的可以认真阅读下,对SQL提升很有帮助。

题目
首先介绍下具体的题目:编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
+----+-------+
| Id | Score |
+----+-------+
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
+----+-------+
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):相同分数采取的是相同排名,下个排名没有间隔。
+-------+------+
| Score | Rank |
+-------+------+
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
+-------+------+
思路
思路1
这种思路就是我从日本作者书中学习到的一种方法。
select
s1.Score -- 分数
,(select count(distinct s2.Score) -- 大于等于此分数的分数值的不重复个数
from Scores s2
where s2.Score > s1.Score) + 1 as `Rank` -- 排名
from Scores s1
order by 2; -- 2表示第2个字段
-- 变换方式
select
s1.score,
(select count(*) + 1 -- 排名不能从1开始
from (select distinct score from Scores) s2 -- 1、找出表中有多少种不同的分数:有多少分数就有多少排名
where s2.score > s1.score) as Rank -- 2、筛选大于某个分数
from Scores s1
order by 2;

思路2
思路2和思路1的思想是相同的,采用的where语句
select
s1.Score
,count(distinct(s2.Score)) `Rank`
from Scores s1, Scores s2
where s1.Score <= s2.Score
group by s1.Id
order by 2; -- 2表示第2个字段
代码解释为:
1、两张相同的表分别命令为s1和s2
2、在给定s1.Score的情况下,找出有多少个分数满足:s2.Score >= s1.Score。比如s1.Score=3.65,那么就有:[4.00 ,4.00, 3.85, 3.65, 3.65]满足要求,但是相同分数的排名相同,所以对分数进行了去重:count(distinct s2.Score),那么3.65的排名就是3
3、group by对s1的数据进行分组排名,要不然只会返回一条数据
4、排名的升序排列
整体思想
不管是思路1,还是思路2,基本上都是两个步骤实现的:
- 第一部分是降序排列的分数
- 第二部分是每个分数对应的排名
1、关于第一部分的实现:直接排名降序实现
select a.Score
from Scores a
order by a.Score DESC -- 直接根据分数降序实现
2、关于第二部分的实现:假设现在给你一个分数S,我们如何算出它的排名Rank?
我们可以先提取出大于等于 S 的所有分数集合 H ,将 H 去重后的元素个数就是 S 的排名。比如某次考试小明考了98分,大于小明分数有[100,99,100,99,98];去重之后就是[100,99,98],总共3个元素;所以小明同学的排名就是第3名。
先提取满足要求的集合H:
select b.Score
from Scores b
where b.Score >= S;
再对集合H去重之后的个数作为排名:
select count(distinct b.Score) -- 去重后的个数当做排名
from Scores b
where b.Score >= S as Rank;
实际上这里的S对应的就是a.Score:
select
a.Score as Score,
(select count(distinct b.Score)
from Scores b
where b.Score >= a.Score) as Rank -- 将S替代成了a.Score
from Scores a
order by a.Score DESC;
窗口函数
窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。
语法
窗口函数的基本语法:
<窗口函数> over (partition by <用于分组的字段名> -- partition子句可省略,不指定分组
order by <用于排序的列名>)
<窗口函数>的位置上可以放两种函数:
- 专用窗口函数,如rank、dense_rank、row_number等
- 聚合函数,如sum、avg、count、max、min等
功能
- 同时具有分组和排序的功能
- 不改变原有表的行数
- 窗口函数原则上只能写在
select子句中
rank/dense_rank/row_number
在MySQL8.X或者hive中专用的窗口函数有3个:
rank:并列跳跃排名dense_rank:并列连续排名row_number:连续排名
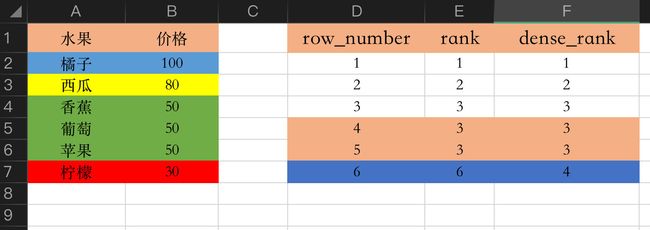
通过一个例子来说明3个函数的排序差异体现在哪里。现在给定五个成绩:93,93,85,80,75,分别使用3个不同的开窗函数得到的结果分别是:
1、使用 DENSE_RANK() 进行排名会得到:1,1,2,3,4
2、使用 RANK() 进行排名会得到:1,1,3,4,5
3、使用 ROW_NUMBER() 进行排名会得到:1,2,3,4,5
最后再通过一个表格来说明下区别:下图是待排序的数据

通过3种函数排名之后的表格和区别:
select
name,price,
row_number() (order by price desc) as `row_number`,
rank() over (order by price desc) as `rank`,
dense_rank() (order by price desc) as `dense_rank`
from products;
MySQL5 实现窗口函数
MySQL8中已经内置的窗口函数,但是MySQL中是没有的,下面介绍的是如何在MySQL5 中实现上面3个窗口函数的功能。
1、实现row_number功能:连续排名
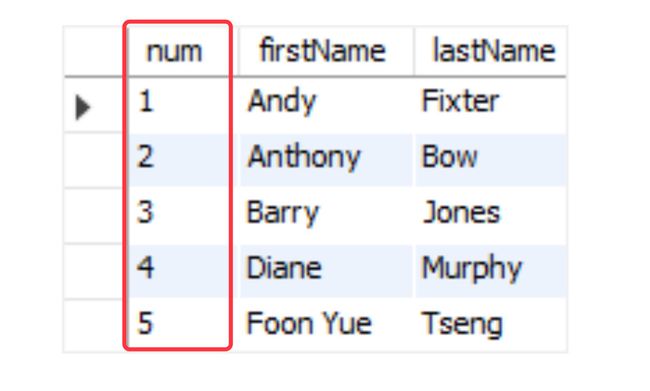
实现的过程并不复杂:直接降序排列,只是需要加上一个排名,自动加1的功能;row_number的实现参考一篇英文文章;https://www.mysqltutorial.org/mysql-row_number/,通过一个变量来实现
SET @row_number = 0; -- 设置变量
SELECT
(@row_number:=@row_number + 1) AS num, -- 变量的自加1
firstName,
lastName
FROM
employees
ORDER BY firstName, lastName
LIMIT 5;
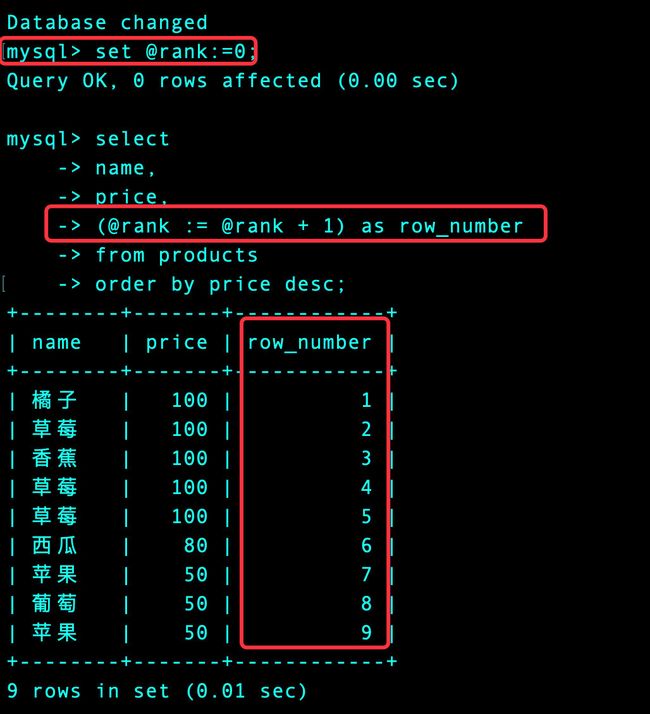
set @rank := 0; -- 设置初始值为0
select
name,
price,
(@rank := @rank + 1) as row_number
from products
order by price desc;
2、实现rank功能:并列跳跃
select p1.name,p1.price,
(select count(p2.price) -- 价格不同去重
from products p2
where p2.price > p1.price) + 1
as rank_1
from products
order by rank_1;

3、实现dense_rank功能:并列连续排名
select p1.name, p1.price,
(select count(distinct p2.price) -- 价格去重处理
from products p2
where p2.price > p1.price) + 1 as dense_rank
from products p1
order by dense_rank;

总结
SQL中的排名问题是一个非常重要的考点,面试的时候经常会被问到,尤其是3种开窗函数的使用,更是高频考点。总结下:
- hive或者 MySQL8 已经存在函数能够实现
- MySQL5 中需要自己根据不同的场景需求来写脚本统计
- 3种开窗函数的使用务必掌握