Redis主从复制流程
前言
Redis 支持部署多节点,然后按照 1:n 的方式构建主从集群,即一个主库、n 个从库。主从库之间会自动进行数据同步,但是只有主库同时允许读写,从库只允许读。
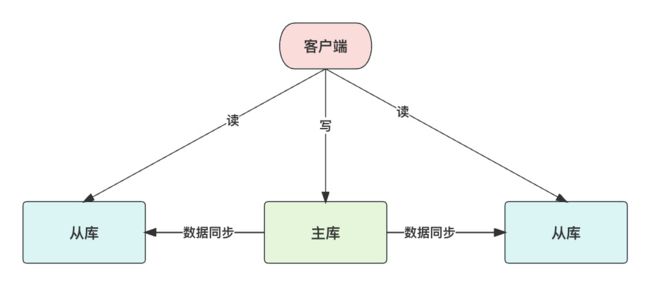
搭建主从复制集群的目的:
- 从库可用于容灾备份
- 从库可以分摊读流量
- 提高服务可用性
开启主从复制,你需要关心的配置项有:
# 主库的IP和端口
replicaof <masterip> <masterport>
# 连接主库认证的用户名和密码
masteruser <username>
masterauth <master-password>
replica-read-only yes # 从库是否只读
repl-diskless-sync no # 是否开启无盘同步 直接基于Socket传输
repl-diskless-sync-delay 5 # 无盘同步的延迟时间
repl-diskless-load disabled # 是否开启无盘加载
repl-backlog-size 1mb # 主从复制积压缓冲区大小
repl-backlog-ttl 3600 # repl_backlog过期时间 主库一段时间后没有任何从库连接将会释放backlog
主库在运行时也可以通过命令手动将其配置为从库:
replicaof <host> <port>
数据同步流程
Redis 主从库之间的数据同步可以分为三个阶段:
PSYNC <replid> <offset>
1、全量同步:从库第一次连接到主库后,因为没有任何数据,所以需要做一次全量同步。因为不知道主库的 replid 和 offset,所以会发送PSYNC ? -1。主库会触发bgsave命令生成一份完整的 RDB 文件,然后通过 Socket 发送给从库。从库接收到 RDB 文件后,首先清空自己的数据库,防止数据污染,然后加载 RDB 文件恢复数据。在数据同步期间,主库仍会接收客户端发起的写命令,所以从库此时的数据还不是最新的。因此,主库在同步期间执行的所有写命令还会写一份到 replication buffer,然后一并发送给从库。
新版本 Redis 也支持无盘复制,主库生成的 RDB 数据不落盘,直接 Socket 发给从库,适用于网络带宽高、磁盘性能差的场景。
2、基于长连接的命令传播:第一次全量同步后,主从库之间的长连接会一直保持,主库执行的所有写命令都会发给从库,从库通过回放这些写命令来和主库保持数据一致。
3、断连后的增量同步:长连接如果因为网络原因断开了,从库的数据就又不是最新的了,如果再触发一次全量同步,会给主库增加很大压力。为了解决这个问题,Redis 会在主库开辟一块缓冲区 repl_backlog,主库在命令传播的同时也会写一份到 repl_backlog,断连后的从库恢复连接后,可以通过 repl_backlog 来做增量同步。

replid 也就是主库的 run_id,它是 Redis 实例的唯一标识,可以通过info命令查看:
127.0.0.1:6379> info
# Server
run_id:50e4d514a576a152541504c334fe0a2d446bf8f6
offset 是复制偏移量,它代表主从库之间数据同步的进度,从库的 offset 越接近主库数据就越新,也可以通过它来监控从库的数据同步延迟情况。
第一次数据同步时,因为从库没有数据,所以 offset 是写死的 -1,代表主库要传输一次全量 RDB 数据,之后从库就需要记录下自己同步的偏移量。为了避免从库因为网络问题断开连接收不到写命令,主库会开辟一块单独的复制积压缓冲区 repl_backlog,默认大小是 1MB,主库在传播写命令时,也会往 repl_backlog 写一份,等待从库恢复连接后可以直接增量同步数据。
如果从库断连时间太久,期间发生的写入量又很大,repl_backlog 就会膨胀的很大,非常占用内存。因此,repl_backlog 被设计成一个固定大小的环形缓冲区,Redis 会采用循环写的方式记录写命令,默认大小个人认为太保守了,你可以根据自己的需要适当调大一点。
repl_backlog 该设置多大合适呢?可以用公式计算一下:
repl_backlog_size = (每秒写入量 * 平均数据大小 - 网络带宽) * 2
假设你的 Redis 服务每秒要写入一万次,平均每次写入数据量在 1KB,网络带宽是 5MB,那么 repl_backlog 最少要 5MB,考虑到断连等一些特殊情况,建议再扩大一倍设为 10MB 比较合适。
repl_backlog 设置的太小会导致主库频繁触发全量同步,每次全量同步都要 fork 子进程生成 RDB 文件,这在一定程度上会影响主库性能,需要特别注意。
源码
给 Redis 从库设置新主库后,从库会和主库建立连接,然后发送PING命令确保主库是正常的,接着发送AUTH命令完成认证,再发送REPLCONF命令跟主库握手,告诉主库自己的一些信息。握手完成以后,从库会发送PSYNC命令给主库,主库回复是全量同步还是增量同步,如果是第一次连接那必然是全量同步,从库开始在本地创建临时文件用于接收 RDB 数据,接收完最后清空数据库,加载 RDB 文件。

从库整个数据同步的过程,也是一个状态机切换的过程,Redis 定义了一批状态:
typedef enum {
REPL_STATE_NONE = 0, // 没有复制
REPL_STATE_CONNECT, // 准备连接主库
REPL_STATE_CONNECTING, // 连接中
/* --- 握手环节 是有序的 --- */
REPL_STATE_RECEIVE_PING_REPLY, // 等待主库回复PING
REPL_STATE_SEND_HANDSHAKE, // 准备握手
REPL_STATE_RECEIVE_AUTH_REPLY, // 等待主库回复AUTH
REPL_STATE_RECEIVE_PORT_REPLY, // 等待主库回复REPLCONF
REPL_STATE_RECEIVE_IP_REPLY, // 等待主库回复REPLCONF
REPL_STATE_RECEIVE_CAPA_REPLY, // 等待主库回复REPLCONF
REPL_STATE_SEND_PSYNC, // 准备发送PSYNC命令
REPL_STATE_RECEIVE_PSYNC_REPLY, // 等待主库回复PSYNC
REPL_STATE_TRANSFER, // 等待主库传输RDB数据
REPL_STATE_CONNECTED, // 全量同步完成,正常连接中
} repl_state;
replicaofCommand()是从库处理 replicaof 命令的入口方法:
- 集群模式下或故障转移时,命令是不支持调用的
- 如果参数是
no one,把自己切换为主库 - 否则把自己切换为从库,连接新主库
void replicaofCommand(client *c) {
// 集群模式和故障转移时 不支持
if (server.cluster_enabled) {
addReplyError(c,"REPLICAOF not allowed in cluster mode.");
return;
}
if (server.failover_state != NO_FAILOVER) {
addReplyError(c,"REPLICAOF not allowed while failing over.");
return;
}
if (!strcasecmp(c->argv[1]->ptr,"no") &&
!strcasecmp(c->argv[2]->ptr,"one")) {
// 把自己升级为主库
if (server.masterhost) {
replicationUnsetMaster();
sds client = catClientInfoString(sdsempty(),c);
serverLog(LL_NOTICE,"MASTER MODE enabled (user request from '%s')",
client);
sdsfree(client);
}
} else {
// 连接主库
long port;
if (c->flags & CLIENT_SLAVE)
{
// 已经是从库了
addReplyError(c, "Command is not valid when client is a replica.");
return;
}
// 第2个参数读取port
if ((getLongFromObjectOrReply(c, c->argv[2], &port, NULL) != C_OK))
return;
// 已经指向了同一个主库,不做任何处理
if (server.masterhost && !strcasecmp(server.masterhost,c->argv[1]->ptr)
&& server.masterport == port) {
serverLog(LL_NOTICE,"REPLICAOF would result into synchronization "
"with the master we are already connected "
"with. No operation performed.");
addReplySds(c,sdsnew("+OK Already connected to specified "
"master\r\n"));
return;
}
// 设置新的主库
replicationSetMaster(c->argv[1]->ptr, port);
sds client = catClientInfoString(sdsempty(),c);
serverLog(LL_NOTICE,"REPLICAOF %s:%d enabled (user request from '%s')",
server.masterhost, server.masterport, client);
sdsfree(client);
}
addReply(c,shared.ok);
}
replicationSetMaster()方法给从库设置主库:
- 断开被阻塞的客户端连接,因为自己是从库了,阻塞在例如
brpop命令的客户端已经没有意义了 - 记录主库的 IP 端口等信息
- 断开从库的从库连接,要求它们重新同步数据
- 状态机改为:待连接主库
- 连接主库
void replicationSetMaster(char *ip, int port) {
int was_master = server.masterhost == NULL;
sdsfree(server.masterhost);
server.masterhost = NULL;
if (server.master) {
freeClient(server.master);
}
// 断开被阻塞的客户端连接,自己已经是从库了,阻塞在例如brpop命令的客户端已经没有意义了
disconnectAllBlockedClients(); /* Clients blocked in master, now slave. */
// 设置新主库的 主机和端口
server.masterhost = sdsnew(ip);
server.masterport = port;
// 断开当前从库的从库连接,要求重新同步新数据
disconnectSlaves();
// 状态机改为 待连接主库
server.repl_state = REPL_STATE_CONNECT;
// 连接主库
connectWithMaster();
}
connectWithMaster()和主库连接连接:
- 和主库建立连接
- 注册可读事件:syncWithMaster
- 状态机改为:主库连接中
int connectWithMaster(void) {
// 建立连接 处理器是 syncWithMaster
server.repl_transfer_s = server.tls_replication ? connCreateTLS() : connCreateSocket();
if (connConnect(server.repl_transfer_s, server.masterhost, server.masterport,
NET_FIRST_BIND_ADDR, syncWithMaster) == C_ERR) {
connClose(server.repl_transfer_s);
server.repl_transfer_s = NULL;
return C_ERR;
}
server.repl_transfer_lastio = server.unixtime;
// 状态机改为 主库连接中
server.repl_state = REPL_STATE_CONNECTING;
serverLog(LL_NOTICE,"MASTER <-> REPLICA sync started");
return C_OK;
}
TCP 连接建立后,syncWithMaster()方法会被触发:
- 发送
PING,确保主库正常 - 发送
AUTH完成认证 - 发送
REPLCONF命令告诉主库自己的一些信息,例如:IP、端口、是否支持无盘复制 - 发送
PSYNC命令,判断全量同步还是增量同步 - 如果是全量同步
- 创建临时文件用于接收 RDB 数据
- 注册可读事件:readSyncBulkPayload 接收 RDB 数据
void syncWithMaster(connection *conn) {
......握手前置处理......
if (server.repl_state == REPL_STATE_SEND_PSYNC) {
// 同步数据 只是发送PSYNC命令
if (slaveTryPartialResynchronization(conn,0) == PSYNC_WRITE_ERROR) {
err = sdsnew("Write error sending the PSYNC command.");
abortFailover("Write error to failover target");
goto write_error;
}
// 状态机改为 等待主库PSYNC回复
server.repl_state = REPL_STATE_RECEIVE_PSYNC_REPLY;
return;
}
// 主库回复了PSYNC,读取结果
psync_result = slaveTryPartialResynchronization(conn,1);
if (psync_result == PSYNC_CONTINUE) {// 增量同步
serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization.");
if (server.supervised_mode == SUPERVISED_SYSTEMD) {
redisCommunicateSystemd("STATUS=MASTER <-> REPLICA sync: Partial Resynchronization accepted. Ready to accept connections in read-write mode.\n");
}
return;
}
if (psync_result == PSYNC_NOT_SUPPORTED) {
// 主库不支持PSYNC命令 降级发送SYNC命令
serverLog(LL_NOTICE,"Retrying with SYNC...");
if (connSyncWrite(conn,"SYNC\r\n",6,server.repl_syncio_timeout*1000) == -1) {
serverLog(LL_WARNING,"I/O error writing to MASTER: %s",
strerror(errno));
goto error;
}
}
// 使用磁盘加载
if (!useDisklessLoad()) {
// 创建临时文件
while(maxtries--) {
snprintf(tmpfile,256,
"temp-%d.%ld.rdb",(int)server.unixtime,(long int)getpid());
dfd = open(tmpfile,O_CREAT|O_WRONLY|O_EXCL,0644);
if (dfd != -1) break;
sleep(1);
}
if (dfd == -1) {
serverLog(LL_WARNING,"Opening the temp file needed for MASTER <-> REPLICA synchronization: %s",strerror(errno));
goto error;
}
// 记录临时文件和fd
server.repl_transfer_tmpfile = zstrdup(tmpfile);
server.repl_transfer_fd = dfd;
}
// 注册可读事件,接收RDB文件
if (connSetReadHandler(conn, readSyncBulkPayload)
== C_ERR)
{
char conninfo[CONN_INFO_LEN];
serverLog(LL_WARNING,
"Can't create readable event for SYNC: %s (%s)",
strerror(errno), connGetInfo(conn, conninfo, sizeof(conninfo)));
goto error;
}
// 状态机改为 等待主库传输RDB文件
server.repl_state = REPL_STATE_TRANSFER;
server.repl_transfer_size = -1;
server.repl_transfer_read = 0;
server.repl_transfer_last_fsync_off = 0;
server.repl_transfer_lastio = server.unixtime;
return;
}
slaveTryPartialResynchronization()方法尝试增量同步,能不能增量同步是主库来判断的,可能主库压根就不支持增量同步,也可以从库落后的太多,超过了积压缓冲区的大小,这种情况下也不得不执行全量同步。
- 发送
PSYNC命令,等待主库回复 - 解析主库的回复,返回同步类型
int slaveTryPartialResynchronization(connection *conn, int read_reply) {
/**
* read_reply
* 0: 发送PSYNC命令
* 1: 读取PSYNC回复结果
*/
if (!read_reply) {
if (server.cached_master) {
// 缓存了主库的信息,直接发送 |PSYNC | 做增量同步
psync_replid = server.cached_master->replid;
snprintf(psync_offset,sizeof(psync_offset),"%lld", server.cached_master->reploff+1);
serverLog(LL_NOTICE,"Trying a partial resynchronization (request %s:%s).", psync_replid, psync_offset);
} else {
// 第一次连主库,发送 |PSYNC ? -1| 做全量同步
serverLog(LL_NOTICE,"Partial resynchronization not possible (no cached master)");
psync_replid = "?";
memcpy(psync_offset,"-1",3);
}
if (server.failover_state == FAILOVER_IN_PROGRESS) {
reply = sendCommand(conn,"PSYNC",psync_replid,psync_offset,"FAILOVER",NULL);
} else {
// 发送PSYNC命令
reply = sendCommand(conn,"PSYNC",psync_replid,psync_offset,NULL);
}
// 等待主库回复
return PSYNC_WAIT_REPLY;
}
// 全量同步 主库回复 |+FULLRESYNC |
if (!strncmp(reply,"+FULLRESYNC",11)) {
.......
return PSYNC_FULLRESYNC;
}
// 可以增量同步 主库回复|+CONTINUE|
if (!strncmp(reply,"+CONTINUE",9)) {
......
// 增量同步
replicationResurrectCachedMaster(conn);
return PSYNC_CONTINUE;
}
if (!strncmp(reply,"-NOMASTERLINK",13) ||
!strncmp(reply,"-LOADING",8))
{
// 稍后再试
return PSYNC_TRY_LATER;
}
// 其它回复认为主库不支持PSYNC
return PSYNC_NOT_SUPPORTED;
}
readSyncBulkPayload()用于接收主库发送的 RDB 数据,有两种格式:
- 有盘复制:
$,事先知道数据总长度/r/n data - 无盘复制:
$EOF:,事先不知数据总长度,\r\n data
/**
* 读取第一行信息
* - 磁盘复制: $/r/n数据
* - 无盘复制: $EOF:\r\n数据
*/
if (server.repl_transfer_size == -1) {
if (connSyncReadLine(conn,buf,1024,server.repl_syncio_timeout*1000) == -1) {
goto error;
}
// 校验第一行回复
if (buf[0] == '-') {
goto error;
} else if (buf[0] == '\0') {
server.repl_transfer_lastio = server.unixtime;
return;
} else if (buf[0] != '$') {
serverLog(LL_WARNING,"Bad protocol from MASTER, the first byte is not '$' (we received '%s'), are you sure the host and port are right?", buf);
goto error;
}
// 无盘复制数据格式
if (strncmp(buf+1,"EOF:",4) == 0 && strlen(buf+5) >= CONFIG_RUN_ID_SIZE) {
usemark = 1;
memcpy(eofmark,buf+5,CONFIG_RUN_ID_SIZE);
memset(lastbytes,0,CONFIG_RUN_ID_SIZE);
/* Set any repl_transfer_size to avoid entering this code path
* at the next call. */
// 无盘复制,不知道数据总长度,随便设置个0,避免再次读取第一行
server.repl_transfer_size = 0;
serverLog(LL_NOTICE,
"MASTER <-> REPLICA sync: receiving streamed RDB from master with EOF %s",
use_diskless_load? "to parser":"to disk");
} else {
// 有盘复制
usemark = 0;
// 读取主库要传输的数据长度
server.repl_transfer_size = strtol(buf+1,NULL,10);
}
return;
}
如果是走磁盘加载,从库会把接收到的数据写入磁盘,对应的文件描述符是repl_transfer_fd变量。接收数据时,每达到 8MB 就刷一次磁盘,避免最后一次性刷盘带来的延迟。
if ((nwritten = write(server.repl_transfer_fd,buf,nread)) != nread) {
goto error;
}
if (server.repl_transfer_read >=
server.repl_transfer_last_fsync_off + REPL_MAX_WRITTEN_BEFORE_FSYNC)
{
off_t sync_size = server.repl_transfer_read -
server.repl_transfer_last_fsync_off;
rdb_fsync_range(server.repl_transfer_fd,
server.repl_transfer_last_fsync_off, sync_size);
server.repl_transfer_last_fsync_off += sync_size;
}
最后清空本地数据库避免数据污染,然后加载接收到的 RDB 文件和主库数据保持一致。
// 清空数据库
emptyDb(-1,empty_db_flags,replicationEmptyDbCallback);
// RDB临时文件强制刷盘
if (fsync(server.repl_transfer_fd) == -1) {
cancelReplicationHandshake(1);
return;
}
int old_rdb_fd = open(server.rdb_filename,O_RDONLY|O_NONBLOCK);
// 替换rdb文件名
if (rename(server.repl_transfer_tmpfile,server.rdb_filename) == -1) {
cancelReplicationHandshake(1);
if (old_rdb_fd != -1) close(old_rdb_fd);
return;
}
// 载入新的RDB文件
if (rdbLoad(server.rdb_filename,&rsi,RDBFLAGS_REPLICATION) != C_OK) {
cancelReplicationHandshake(1);
if (server.rdb_del_sync_files && allPersistenceDisabled()) {
serverLog(LL_NOTICE,"Removing the RDB file obtained from "
"the master. This replica has persistence "
"disabled");
bg_unlink(server.rdb_filename);
}
return;
}
// 状态机改为 已连接,后续做好命令传播即可
server.repl_state = REPL_STATE_CONNECTED;
全量同步完以后,后续主从库之间就是基于长连接的命令传播了,主库会在执行写命令时执行replicationFeedSlaves()方法把命令发送给从库:
void replicationFeedSlaves(list *slaves, int dictid, robj **argv, int argc) {
// 和上次数据库编号不一样,要先发送SELECT命令
if (server.slaveseldb != dictid) {
robj *selectcmd;
// SELECT命令追加到repl_backlog
if (server.repl_backlog) feedReplicationBacklogWithObject(selectcmd);
// 遍历从库连接,发送SELECT命令
listRewind(slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
if (!canFeedReplicaReplBuffer(slave)) continue;
addReply(slave,selectcmd);
}
if (dictid < 0 || dictid >= PROTO_SHARED_SELECT_CMDS)
decrRefCount(selectcmd);
}
// 实际命令追加到repl_backlog
if (server.repl_backlog) {
......
}
//再把实际命令发送给所有从库
listRewind(slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
if (!canFeedReplicaReplBuffer(slave)) continue;
addReplyArrayLen(slave,argc);
for (j = 0; j < argc; j++)
addReplyBulk(slave,argv[j]);
}
}
总结
主从复制是 Redis 实现服务高可用的关键特性之一,主节点通过把写命令异步传播给从节点的方式来实现数据同步。同时,为了避免从库因为网络问题断开导致数据不一致,主库会开辟一块主从复制积压缓冲区 repl_backlog 缓存最近的写命令,待从库恢复连接后,可以直接走增量同步。为了避免缓冲区膨胀,repl_backlog 采用固定大小循环写的方式,一旦从库落后的太久,需要增量同步的日志被主库覆盖掉了,就不得不触发全量同步,因此建议线上可以适当调大缓冲区的大小。
从库第一次连接必须走全量同步,全量同步会影响主库的性能,所以单个 Redis 实例的内存最好控制在 4GB 左右,内存太大不单单执行 RDB 耗时,从库同步时间也会更加耗时,如果 4GB 无法满足业务需求,那么就部署分片集群。