面试官:啥是集群策略啊?
本周是在家办公的一周,上面的图就是我在家的工位。
工欲善其事,必先利其器。在家办公,我是认真的。
在家里开发的时候有需求是这样的:一个如果接口调用失败,需要自动进行重试。
虽然关系不大,但是我还是想到了Dubbo的集群容错策略:Failover Cluster,即失败自动切换。
(这个转折是不是有点生硬.......)
所以借本文对于Dubbo的Cluster集群和Failover Cluster(失败自动切换)策略进行一个详细分析。
本文如果没有特别说明的地方,源码均是来自最新的2.7.5版本。
在阅读之前先抛出几个问题:
1.Dubbo Cluster集群的作用是什么?
2.Dubbo Cluster的10个实现类你能说出来几个,其中哪几个是集群容错的方法实现?
3.默认的集群实现类是什么呢?
4.Failover Cluster调用失败之后,会自动进行几次重试呢?
5.什么是Dubbo的粘滞连接?
6.粘滞连接在Cluster中是怎么应用的?
7.Cluster选择出一个可用的Invoker最多要进行几次选择?
8.请问几次选择分别是什么?
注意:上面的8个问题,前3个是非常常见的面试题。后面的都是你阅读完本文后就可以知道问题的答案,面试中并不常见,但是后面的问题可以综合成一个非常高频的面试题:有看过什么源码吗,能给我讲讲吗?
本文会对上面的问题进行逐一的、详细的解读。文章的最后会进行一个问题和答案的汇总。
废话不多说,看完之后觉得不错,还求个关注。抱拳了,老铁。
Dubbo Cluster集群的作用是什么?
在生产环境,我们常常是多个服务器跑相同的应用,这种做的目的其一是为了避免单点故障。
为了避免单点故障,现在的应用通常至少会部署在两台服务器上。而对于一些负载比较高的服务,比如网关服务,会部署更多的服务器。
这样,在同一环境下的服务提供者数量会大于1。对于服务消费者来说,同一环境下出现了多个服务提供者。
这时会出现几个问题:对于一次请求,我作为消费者到底调用哪个提供者呢?服务调用失败的时候我怎么做呢?是重试?是抛出异常?或者仅仅是打印出异常?
为了处理这些问题,Dubbo定义了集群接口Cluster以及Cluster Invoker。
集群Cluster的用途是将多个服务提供者合并为一个Cluster Invoker,并将这个Invoker暴露给服务消费者。
这样的好处就是对服务消费者来说,只需通过这个Cluster Invoker进行远程调用即可,至于具体调用哪个服务提供者,以及调用失败后如何处理等问题,现在都交给集群模块去处理。
集群模块是服务提供者和服务消费者的中间层,为服务消费者屏蔽了服务提供者的情况,这样服务消费者就可以专心处理远程调用相关事宜。比如发请求,接受服务提供者返回的数据等。这就是Dubbo Cluster集群的作用。
Dubbo Cluster的10个实现类是什么?
根据配置可以知道Dubbo集群接口Cluster有10种实现方法如下:
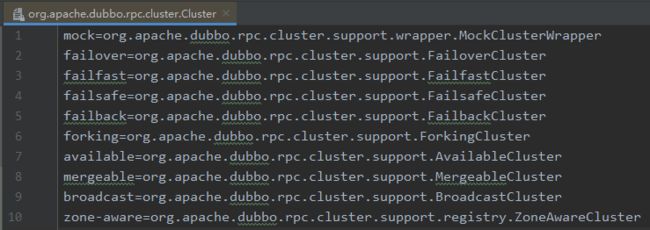
需要注意的是,十种实现方法其中只有failover、failfast、failsafe、failback、forking、broadcast这6种才属于集群容错的范畴。另外的实现均有其他的应用场景。
下面我们先说6种集群容错的实现方法:
Failover Cluster:
failover=org.apache.dubbo.rpc.cluster.support.FailoverCluster
失败自动切换,在调用失败时,失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过retries="2"来设置重试次数(不含第一次)。
Failfast Cluster:
failfast=org.apache.dubbo.rpc.cluster.support.FailfastCluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
Failsafe Cluster:
failsafe=org.apache.dubbo.rpc.cluster.support.FailsafeCluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
Failback Cluster:
failback=org.apache.dubbo.rpc.cluster.support.FailbackCluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
Forking Cluster:
forking=org.apache.dubbo.rpc.cluster.support.ForkingCluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。
Broadcast Cluster:
broadcast=org.apache.dubbo.rpc.cluster.support.BroadcastCluster
广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
所以对于这个问题你也可以回答上来了:10个实现类中有哪几个是集群容错的方法实现?
接下来再说说另外四个实现类:
Available Cluster:
available=org.apache.dubbo.rpc.cluster.support.AvailableCluster
获取可用的服务方。遍历所有Invokers通过invoker.isAvalible判断服务端是否活着,只要一个有为true,直接调用返回,不管成不成功。
Mergeable Cluster:
mergeable=org.apache.dubbo.rpc.cluster.support.MergeableCluster
分组聚合,将集群中的调用结果聚合起来,然后再返回结果。比如菜单服务,接口一样,但有多种实现,用group区分,现在消费方需从每种group中调用一次返回结果,合并结果返回,这样就可以实现聚合菜单项。
Mock Cluster:
mock=org.apache.dubbo.rpc.cluster.support.wrapper.MockClusterWrapper
本地伪装,通常用于服务降级,比如某验权服务,当服务提供方全部挂掉后,客户端不抛出异常,而是通过 Mock 数据返回授权失败。
zone-aware Cluster:
zone-aware=org.apache.dubbo.rpc.cluster.support.registry.ZoneAwareCluster
上面的几种Cluster策略在官网都能找到对应的说明,但是对于这个zone-aware目前官网上是没有介绍的,因为这是前段时间发布的2.7.5版本才支持的内容,如下图所示:

所以对于zone-aware这个策略我多说两句。具体可以参照下面的这个issue: https://github.com/apache/dubbo/issues/5399
zone-aware的应用场景是下面这样的。
业务部署假设是双注册中心:
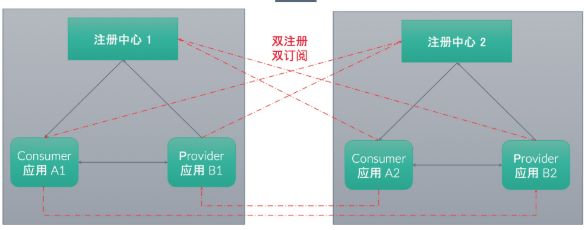
则对应消费端,先在注册中心间选择,再到选定的注册中心选址:

所以,和之前相比,在Dubbo 2.7.5以后,对于多注册中心订阅的场景,选址时的多了一层注册中心集群间的负载均衡。
这个注册中心集群间的负载均衡的实现就是:zone-aware Cluster。
对于多注册中心间的选址策略,根据类上的注释可以看出,目前设计的有下面四种:

1.指定优先级:
来自preferred="true"注册中心的地址将被优先选择,只有该中心无可用地址时才Fallback到其他注册中心
2.同 zone 优先:
选址时会和流量中的zone key做匹配,流量会优先派发到相同zone的地址
3.权重轮询:
来自北京和上海集群的地址,将以10:1的比例来分配流量
4.默认方法:
选择第一个可用的即可。
默认的集群方法是什么呢?
源码之下无秘密。我们从源码中寻找答案:

首先我们可以看到,Cluster是一个SPI接口。其默认实现是FailoverCluster.NAME,如下源码所示:

所以默认的实现方法就是:
org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker
由于Cluster是一个SPI接口,所以我们也可以根据实际需求去扩展自己的实现类。
FailoverCluster doInvoke源码解析
接下来我们就对FailoverClusterInvoker的doInvoke方法的源码进行解析。
这一小节主要回答这一个问题:Failover Cluster调用失败之后,会自动切换Invoker进行几次重试呢?

通过源码,我们可以知道默认的重试次数是2次。
有人就问了:为什么第61行的最后还有一个"+1"呢?
你想一想。我们想要在接口调用失败后,重试n次,这个n就是DEFAULT_RETRIES,默认为2。那么我们总的调用次数就是n+1次了。所以这个"+1"是这样来的,很小的一个点。
另外图中标记了红色五角星★的地方,第62到64行。也是很关键的地方。对于retries参数,在官网上的描述是这样的:

不需要重试请设为0。我们前面分析了,当设置为0的时候,只会调用一次。
但是我也看见过retries配置为"-1"的。-1+1=0。调用0次明显是一个错误的含义。但是程序也正常运行,且只调用一次。
这就是标记了红色五角星★的地方的功劳了。防御性编程。哪怕你设置为-10086也只会调用一次。
接下来对doInvoke方法进行一个全面的解读,下面是2.7.5版本的源码,我基本上每一行主要的代码都加了注释,可以点开大图查看: org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker#doInvoke

如上所示,FailoverClusterInvoker的doInvoke方法主要的工作流程是:
首先是获取重试次数,然后根据重试次数进行循环调用,在循环体内,如果失败,则进行重试。
在循环体内,首先是调用父类AbstractClusterInvoker的select方法,通过负载均衡组件选择一个Invoker,然后再通过这个Invoker的invoke方法进行远程调用。如果失败了,记录下异常,并进行重试。
注意一个细节:在进行重试前,重新获取最新的invoker集合,这样做的好处是,如果在重试的过程中某个服务挂了,可以通过调用list方法可以保证copyInvokers是最新的可用的invoker列表。
整个流程大致如此,不是很难理解。
什么是Dubbo的粘滞连接?
接下来我们要看的是父类AbstractClusterInvoker的select方法的逻辑。但是在看select方法的逻辑之前,我必须得先铺垫一下Dubbo粘滞连接特性的知识。
官网上的解释是这样的:
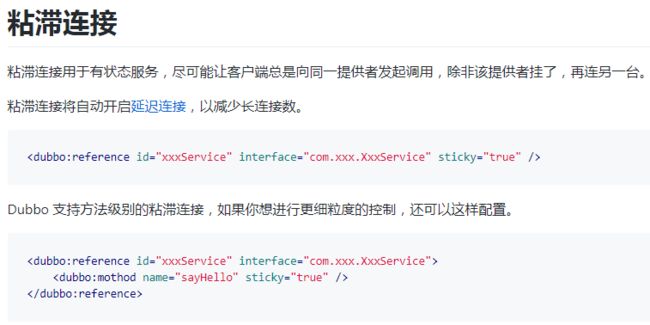
可以看出,这是一个服务治理类型的参数。当设置true时,该接口上的所有方法使用同一个provider。官方文档中说明可以用在接口和方法级别。
这些都是一些比较简单的服务治理的规则。如果需求更复杂,则需要使用路由功能。
官方文档已经说的很清楚了。我就只简单的解释一下第一句话:粘滞连接用于有状态服务。
那么什么是有状态服务,什么又是无状态服务呢?
根据我简单的理解。对服务提供者来说,究竟是有状态的服务提供者,还是无状态服务,其判断依据就一句话: 从客户端发起的两个或者多个请求,在服务端是否具备上下文关系。
举个例子,我们经常会用到的session。
众所周知,HTTP协议是无状态的。那么当在一个电商场景下,将用户挑选的商品放到购物车,保存到session里,当付款的时候,再从购物车里取出商品信息。这样通过session就实现了有状态的服务。
当一个服务被设计为无状态的时候,对于客户端来说,可以随意调用。所以无状态的服务可以很容易的进行水平扩容。
当一个服务被设计为有状态的时候,想要水平扩容的时候就不是那么简单了。因为客户端和服务端存在着上下文关系,所以客户端每次都需要请求那一台服务端。
把一个有状态的服务修改为无状态的服务的方案也很简单。还是拿session举例,这个时候,我们的分布式session就呼之欲出了。把session集中存储起来,比如放到redis中,弄一个独立于服务的session共享层。这样,一个有状态的服务就可以变为一个无状态的服务。
AbstractClusterInvoker select源码解析
看完这一小节,你也就知道了粘滞连接在Cluster中是怎么应用的了。
有了粘滞连接的知识储备后,再看select方法就比较轻松了,首先需要知道的是select方法是一个关键的公共方法,其作用就是选择出一个可用的invoke,有下面这几个Cluster的实现类都在调用:

代码片段不长,逻辑也比较清楚,具体代码解析如下:

根据代码画出select方法的流程图如下:

结合代码和流程图,再进行一个文字描述。
先介绍一下select的四个入参,分别是:
loanbalance:负载均衡策略。
invocation:它持有调用过程中的变量,比如方法名,参数等。
invokers:这里的invokers列表可以看做是存活着的服务提供者列表。
selected:已经被选择过的invoker集合。
通过源码我们可以看出,select方法的主要逻辑集中在了对粘滞连接特性的支持上。
首先是获取sticky配置,然后再检测invokers列表中是否包含 stickyInvoker,如果不包含,则认为该stickyInvoker不可用,此时将其置空。
为什么可以置空?
因为这里的invokers列表是存活着的服务提供者列表,如果这个列表不包含stickyInvoker,那自然而然的认为stickyInvoker挂了,所以置空。
接下来,如果stickyInvoker存在于invokers列表中,说明stickyInvoker还活着,此时要进行下一项检测。检测selected(选择过的服务提供者列表)中是否包含 stickyInvoker。
如果包含的话,说明stickyInvoker在此之前没有成功提供服务(但其仍然处于存活状态)。此时我们认为这个服务不可靠,不应该在重试期间内再次被调用,因此这个时候不会返回该stickyInvoker。
如果selected不包含stickyInvoker,此时还需要进行可用性检测,比如检测服务提供者网络连通性等。当可用性检测通过,才可返回 stickyInvoker,否则调用doSelect方法选择Invoker。
如果sticky为true,此时会将doSelect方法选出的Invoker赋值给stickyInvoker。
关于粘滞连接和可用性检测的默认配置如下:
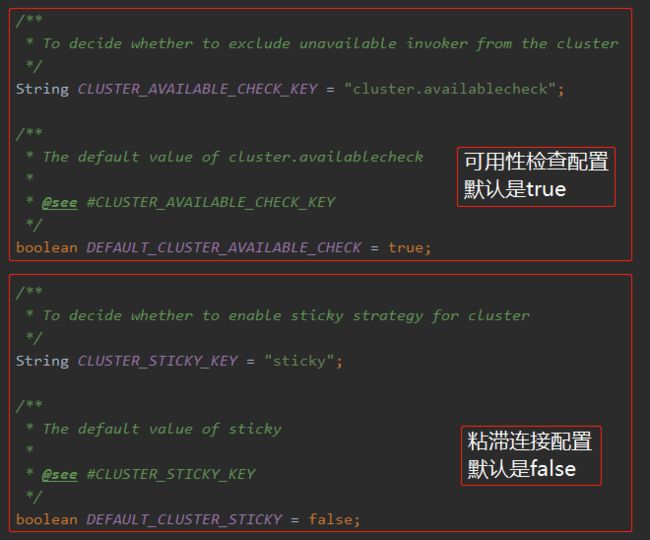
即默认情况下粘滞连接是关闭状态。当粘滞连接开启时,默认会进行可用性检查。
关于select方法先分析这么多,继续向下分析。
AbstractClusterInvoker doSelect源码解析
读完这一小节你可以回答出这两个问题:
1.Cluster选择出一个可用的Invoker最多要进行几次选择?
2.请问几次选择分别是什么?
doSelect方法的源码解析如下:

Failover Cluster选择出一个可用的Invoker最多要进行三次选择,也是doSelect的主要逻辑,三次分别是(图中标号了①②③的地方):
①:通过负载均衡组件选择 Invoker。
②:如果选出来的 Invoker 不稳定,或不可用,此时需要调用reselect 方法进行重选。
③:reselect选出来的Invoker为空,此时定位invoker在invokers列表中的位置index,然后获取index+1处的 invoker。
AbstractClusterInvoker reselect源码解析
下面我们来看一下 reselect 方法的逻辑。
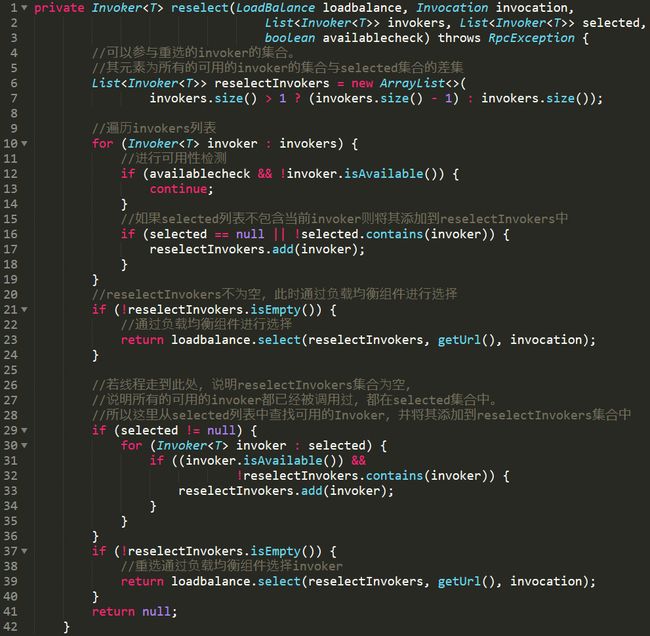
根据源码做出流程图如下:
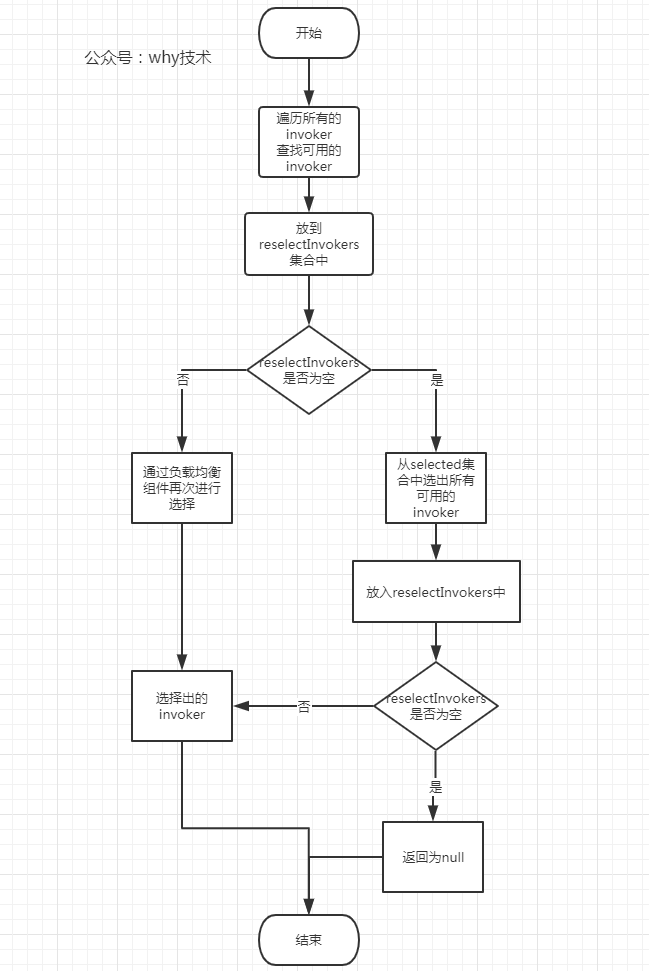
所以,reselect方法总结下来其实做了四件事情:
第一:查找可用的invoker,并将其添加到reselectInvokers集合中。这个reselectInvokers集合你可以理解为里面放的是所有的可用的invoker的集合与selected集合的差集。
第二:如果经过筛选后,reselectInvokers不为空,则通过负载均衡组件再次进行选择并返回。
第三:如果经过筛选后,reselectInvokers为空,则再从selected集合(已经被调用过的集合)中选出所有可用的invoker,放到reselectInvokers中,再次通过负载均衡组件进行选择并返回。
第四:如果进过上面的步骤后,没有选择出合适的invoker,reselectInvokers还是为空,说明所有的invoker都不可用了,返回为null。
好了,到这里就把最开始抛出的8个问题都解答完毕了,接下来对问题、答案进行一个汇总。
问题、答案汇总
1.Dubbo Cluster集群的作用是什么?
简单来说:集群模块是服务提供者和服务消费者的中间层,为服务消费者屏蔽了服务提供者的情况,这样服务消费者就可以专心处理远程调用相关事宜。比如发请求,接受服务提供者返回的数据等。这就是Dubbo Cluster集群的作用。
2.Dubbo Cluster的10个实现类你能说出来几个,其中哪几个是集群容错的方法实现?
根据配置可以知道Dubbo集群接口Cluster有10种实现方法如下:

其中failover、failfast、failsafe、failback、forking、broadcast这6种才属于集群容错的范畴。另外的实现均有其他的应用场景。还需要注意的是zone-aware是2.7.5版本后才支持的实现类,之前是registryaware。
3.默认的集群实现类是什么呢?
失败自动切换: org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker
4.Failover Cluster调用失败之后,会自动切换Invoker进行几次重试呢?
自动进行2次重试,共计调用3次。
5.什么是Dubbo的粘滞连接?
粘滞连接用于有状态服务,尽可能让客户端总是向同一提供者发起调用,除非该提供者挂了,再连另一台。粘滞连接将自动开启延迟连接,以减少长连接数。
6.粘滞连接在Cluster中是怎么应用的?
参照AbstractClusterInvoker select源码解析。select方法的主要逻辑集中在了对粘滞连接特性的支持上。
7.Cluster选择出一个可用的Invoker最多要进行几次选择?
最多进行三次选择。
8.请问几次选择分别是什么?
①:通过负载均衡组件选择 Invoker。 ②:如果选出来的 Invoker 不稳定,或不可用,此时需要调用reselect 方法进行重选。 ③:reselect选出来的Invoker为空,此时定位invoker在invokers列表中的位置index,然后获取index+1处的 invoker。
最后说一句(求个关注)
之前也写过几篇Dubbo相关的文章,有兴趣的可以看一看:
《Dubbo 2.7.5在线程模型上的优化》
《快速失败机制&失败安全机制》
《够强!一行代码就修复了我提的Dubbo的Bug。》
《Dubbo加权轮询负载均衡的源码和Bug,了解一下?》
《Dubbo一致性哈希负载均衡的源码和Bug,了解一下?》
《一文讲透Dubbo负载均衡之最小活跃数算法》
《参加Dubbo社区开发者日成都站后,带给我的一点思考。》
《Dubbo 2.7新特性之异步化改造》
才疏学浅,难免会有纰漏,如果你发现了错误的地方,还请你留言给我指出来,我对其加以修改。
感谢您的阅读,原创不易,求个关注.
以上。
欢迎关注公众号【why技术】,坚持输出原创。愿你我共同进步。
