Flink 系例之 SQL 案例 - 游戏上报数据统计
本期示例
本示例通过模拟上报数据展现玩家在游戏内的登录、退出、创角、升级等事件,从而了解游戏运营动态;
玩家进入游戏后,通常游戏内会进行定时事件上报,后台通过上报数据分析不同的游戏热度。通过玩家在游戏内的行为事件,分析游戏内玩家的存活度或游戏粘性;
统计说明
统计维度
当天游戏在线总人数
每分钟游戏登录人数
每分钟游戏退出人数
每分钟游戏升级人数
每分钟角色分类人数
每分钟游戏区服人数
各游戏角色占比输出效果
数据流在flink中实时计算后,输出到elasticsearch索引库中存。
在kibana中加载elasticsearch中检索维度数据,创建多维度独立图表。
在kibana中将独立图表组建成可视化大屏展示。执行流程
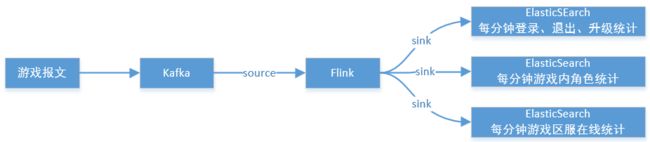
设计说明
我们随便找个游戏官网,摘录几款游戏信息,组装成假想的游戏数据上报,写入 kafka 数据结构:
-- 数据格式
{
"gameId": "凤武",
"serverId": "s28",
"uid": 374704566,
"event": "create",
"role": "战士",
"createTime": "2021-10-20 20:12:56",
"createTimeSeries": 1634710376772
}游戏:gameId
区服:serverId
用户:uid
事件:login,quit,create,upgrade
角色:无,法师,战士,道士
上报时间:20201-10-20 20:12:56
上报时间戳:1634710376772
注:此数据通过 java 客户端程序循环随机组装模拟生成后,推送到 kafka 指定 game_behavior 主题队列中,由 flink 拉取数据流处理;
依赖服务
flink 1.11.1 (webui + sql client) 主机个数:2 集群模式:Standalonekafka_2.11-2.2.2 主机个数:1 集群模式:单机
kafka-eagle-web-2.0.3 (kafka管理WEB控制平台)
zookeeper (kafka自带zk)
elasticsearch-6.6.2 主机个数:1 集群模式:单机
kibana-6.6.2 (es管理WEB控制平台)ES 索引结构
按分钟游戏事件统计表 es_min_game_count
game_id 游戏ID
time_str 时间(按分钟维度统计)
login_num 登录上报人数
quit_num 退出上报人数
up_num 升级上报人数
data_time 窗口内最大数据时间
create_time 入索引库的创建时间按分钟游戏创角统计表 es_min_game_role_count
game_id 游戏ID
time_str 时间(按分钟维度统计)
role 游戏角色
num 当前角色上报人数
data_time 窗口内最大数据时间
create_time 入索引库的创建时间按分钟游戏创角统计表 es_min_game_server_count
game_id 游戏ID
time_str 时间字符串(按分钟维度统计)
server_id 游戏区服
num 当前在线上报人数(登录上报人数 - 退出上报人数)
data_time 窗口内最大数据时间
create_time 入索引库的创建时间flink 官方 SQL 文档
https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/dev/table/sql/queries.htmlflink 常规命令
# 只需启动master主机即可,会自动发送指令启动slaves
./bin/start-cluster.sh
# 停止集群
./bin/stop-cluster.sh
# 启动sql客户端(依赖集群)
./bin/sql-client.sh embedded
# 退出窗口
quit;
-- 查看运行的job
./bin/flink list
-- 停止job
./bin/flink cancel be0a6e1218f65db63bec70f2ae15c459
-- 查看flink帮助
./bin/flink -h
-- 启动Flink - SQL客户端 查看帮助文档
./bin/sql-client.sh embedded 进入后输入:help
或
./bin/sql-client.sh -hFlink - SQL 操作流程
数据流输入源表
-- 创建表
CREATE TABLE game_source (
gameId STRING,
serverId STRING,
uid BIGINT,
event STRING,
role STRING,
createTime STRING,
createTimeSeries BIGINT,
ts AS TO_TIMESTAMP(FROM_UNIXTIME(createTimeSeries / 1000, 'yyyy-MM-dd HH:mm:ss')),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'game_behavior',
'properties.bootstrap.servers' = '192.168.1.1:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'json'
);
-- 查看表或者视图的 Schema
DESCRIBE game_source;
-- 删除表
DROP TABLE game_source;例解读
-- 表示将orderTimeSeries时间戳转换为ts时间格式
ts AS TO_TIMESTAMP(FROM_UNIXTIME(orderTimeSeries / 1000, 'yyyy-MM-dd HH:mm:ss'))
-- 设置水印,表示按ts时间定义水印位,允许5秒延迟,防止数据并没有严格按时间顺序流入后,对窗口内数据进行再计算。例如:当前最大时间为55秒,则延迟5秒,即55-5=50,时间为50秒之前的数据认为已全部到达;
WATERMARK FOR ts as ts - INTERVAL '5' SECOND
-- 通过计算列产生一个处理时间列(PROCTIME()内置时间函数)
proctime asPROCTIME(),
-- scan.startup.mode 指offset的消费模式
earliest-offset表示从topic中最初的数据开始消费
latest-offset表示从topic中最新的数据开始消费
group-offsets表示从topic中指定的group上次消费的位置开始消费,所以必须配置group.id参数
timestamp表示从topic中指定的时间点开始消费,指定时间点之前的数据忽略,需结合'scan.startup.timestamp-millis'配置一起使用
specific-offsets表示从topic中指定的offset开始,这个比较复杂,需要手动指定offset,结合'scan.startup.specific-offsets'配置一起使用查询 SQL 示例
-- 查询结果
select gameId,serverId,uid,event,role,createTime,createTimeSeries,ts from game_source;
-- 统计每种游戏类型的总量
select gameId,count(uid) as uCount from game_source group by gameId;
-- 统计每种订单类型的总价
select gameId,event,sum(uid) as uCount from game_source group by gameId,event;
-- 基于时间字段排序
select gameId,serverId,uid,event,role,createTime from game_source order by ts;
-- 查询时间排序的前3条记录。注意:LIMIT 查询需要有一个 ORDER BY 。
select gameId,serverId,uid,event,role,createTime from game_source order by ts limit 3;
-- 按游戏分组,按事件类型进行计算;
SELECT gameId,SUM(login) as login_num,SUM(quit) as quit_num,SUM(upgrade) as up_num
FROM (SELECT gameId,
CASE event WHEN 'login' THEN 1 ELSE 0 END AS login,
CASE event WHEN 'quit' THEN 1 ELSE 0 END AS quit,
CASE event WHEN 'upgrade' THEN 1 ELSE 0 END AS upgrade FROM game_source )
GROUP BY gameId;数据统统计输出目标表
-- 创建按分钟统计游戏人数(输出到elasticsearch)
CREATE TABLE es_min_game_count_sink (
game_id STRING,
time_str STRING,
login_num INT,
quit_num INT,
up_num INT,
data_time TIMESTAMP(3),
create_time TIMESTAMP(3),
PRIMARY KEY (game_id, time_str) NOT ENFORCED
) WITH (
'connector.type' = 'elasticsearch',
'connector.version' = '6',
'connector.property-version' = '1',
'connector.hosts' = 'http://192.168.1.1:9200',
'connector.index' = 'es_min_game_count',
'connector.document-type' = 'doc',
'format.type' = 'json',
'update-mode'='append',
'connector.bulk-flush.max-actions' = '1',
'connector.bulk-flush.max-size' = '0mb'
);
-- 创建按分钟统计角色人数(输出到elasticsearch)
CREATE TABLE es_min_game_role_count_sink (
game_id STRING,
time_str STRING,
role STRING,
num INT,
data_time TIMESTAMP(3),
create_time TIMESTAMP(3),
PRIMARY KEY (game_id, time_str) NOT ENFORCED
) WITH (
'connector.type' = 'elasticsearch',
'connector.version' = '6',
'connector.property-version' = '1',
'connector.hosts' = 'http://192.168.1.1:9200',
'connector.index' = 'es_min_game_role_count',
'connector.document-type' = 'doc',
'format.type' = 'json',
'update-mode'='append',
'connector.bulk-flush.max-actions' = '1',
'connector.bulk-flush.max-size' = '0mb'
);
-- 创建按分钟统计游戏区服人数(输出到elasticsearch)
CREATE TABLE es_min_game_server_count_sink (
game_id STRING,
time_str STRING,
server_id STRING,
num INT,
data_time TIMESTAMP(3),
create_time TIMESTAMP(3),
PRIMARY KEY (game_id, time_str) NOT ENFORCED
) WITH (
'connector.type' = 'elasticsearch',
'connector.version' = '6',
'connector.property-version' = '1',
'connector.hosts' = 'http://192.168.1.1:9200',
'connector.index' = 'es_min_game_server_count',
'connector.document-type' = 'doc',
'format.type' = 'json',
'update-mode'='append',
'connector.bulk-flush.max-actions' = '1',
'connector.bulk-flush.max-size' = '0mb'
);
-- 显示所有表与视图
SHOW TABLES;示例解读
document-type表示Elasticsearch 文档类型。在 elasticsearch-7 中不再需要。
format.type表示连接器支持的指定格式。该格式必须生成一个有效的 json 文档。 默认使用内置的 'json' 格式。
update-mode表示文档写入模式,默认append追加;
connector.bulk-flush.max-actions表示每个批量请求的最大缓冲操作数。 可以设置为'0'来禁用它(0实际有抛错,改为1)。
connector.bulk-flush.max-size表示每个批量请求的缓冲操作在内存中的最大值。单位必须为 MB。 可以设置为'0'来禁用它。创建数据视图
-- 创建按每1分钟统计数的视图
CREATE VIEW es_count_min_game_view AS
SELECT gameId as game_id,
DATE_FORMAT(TUMBLE_END(ts, INTERVAL'1'MINUTE), 'yyyy-MM-dd HH:mm:00') as window_time,
SUM(login) as login_num,
SUM(quit) as quit_num,
SUM(upgrade) as up_num,
MAX(ts) as data_time FROM (
SELECT gameId,ts,
CASE event WHEN 'login' THEN 1 ELSE 0 END AS login,
CASE event WHEN 'quit' THEN 1 ELSE 0 END AS quit,
CASE event WHEN 'upgrade' THEN 1 ELSE 0 END AS upgrade FROM game_source)
GROUP BY TUMBLE(ts, INTERVAL'1'MINUTE),gameId;
-- 创建按每1分钟统计角色数的视图
CREATE VIEW es_count_min_game_role_view AS
SELECT gameId as game_id,
DATE_FORMAT(TUMBLE_END(ts, INTERVAL'1'MINUTE), 'yyyy-MM-dd HH:mm:00') as window_time,
role,COUNT(uid) asnum,MAX(ts) as data_time
FROM game_source where eventin ('create','upgrade')
GROUP BY TUMBLE(ts, INTERVAL'1'MINUTE),gameId,role;
-- 创建按每1分钟统计区服人数的视图
CREATE VIEW es_count_min_game_server_view AS
SELECT gameId as game_id,serverId as server_id,
DATE_FORMAT(TUMBLE_END(ts, INTERVAL'1'MINUTE), 'yyyy-MM-dd HH:mm:00') as window_time,
SUM(login) as login_num,
SUM(quit) as quit_num,
MAX(ts) as data_time FROM (
SELECT gameId,ts,serverId,
CASE event WHEN 'login' THEN 1 ELSE 0 END AS login,
CASE event WHEN 'quit' THEN 1 ELSE 0 END AS quit
FROM game_source where event in ('login','quit')
) GROUP BY TUMBLE(ts, INTERVAL'1'MINUTE),gameId,serverId;创建并执行 job 任务
-- 创建每分钟游戏登录、退出、升级上报人数统计JOB
INSERT INTO es_min_game_count_sink
SELECT
game_id,
window_time as time_str,
cast(login_num asINT),
cast(quit_num asINT),
cast(up_num asINT),
TO_TIMESTAMP(CONVERT_TZ(DATE_FORMAT(data_time, 'yyyy-MM-dd HH:mm:ss'),'UTC','GMT-08:00')) as data_time,
TO_TIMESTAMP(DATE_FORMAT(CURRENT_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss')) as create_time
FROM es_count_min_game_view;
-- 创建每分钟游戏角色上报人数统计JOB
INSERT INTO es_min_game_role_count_sink
SELECT game_id,window_time as time_str,role,
cast(numasINT),
TO_TIMESTAMP(CONVERT_TZ(DATE_FORMAT(data_time, 'yyyy-MM-dd HH:mm:ss'),'UTC','GMT-08:00')) as data_time,
TO_TIMESTAMP(DATE_FORMAT(CURRENT_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss')) as create_time
FROM es_count_min_game_role_view;
-- 创建每分钟游戏区服在线人数统计JOB
INSERT INTO es_min_game_server_count_sink
SELECT game_id,window_time as time_str,server_id,
cast((CASEWHEN login_num>quit_num THEN login_num - quit_num ELSE0END) asINT),
TO_TIMESTAMP(CONVERT_TZ(DATE_FORMAT(data_time, 'yyyy-MM-dd HH:mm:ss'),'UTC','GMT-08:00')) as data_time,
TO_TIMESTAMP(DATE_FORMAT(CURRENT_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss')) as create_time
FROM es_count_min_game_server_view;时间格式转换说明
-- 常用时间方法与格式转换
-- 参见:https://help.aliyun.com/document_detail/62717.html
-- 参见:https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/dev/table/functions/systemfunctions/
SELECT NOW() as create_time ;
SELECT TO_TIMESTAMP(FROM_UNIXTIME(1634783946347 / 1000, 'yyyy-MM-dd HH:mm:ss')) as create_time;
SELECT TO_TIMESTAMP(DATE_FORMAT(NOW(), 'yyyy-MM-dd HH:mm:ss')) as create_time;
SELECT TO_TIMESTAMP(DATE_FORMAT(CURRENT_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss')) as create_time;
SELECT TO_TIMESTAMP(CONVERT_TZ(DATE_FORMAT(data_time, 'yyyy-MM-dd HH:mm:ss'),'UTC','GMT-08:00')) as data_time;运行效果
Flink SQL 客户端
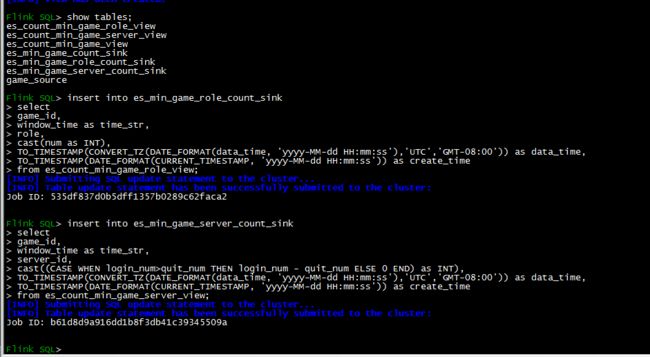
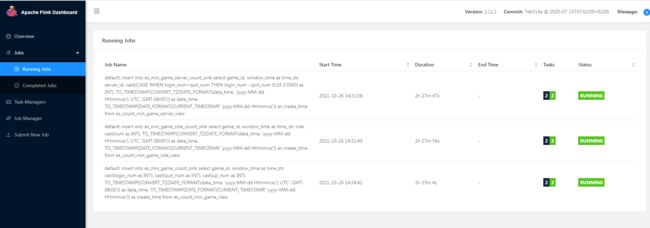
Flink 控制台 JOB 列表
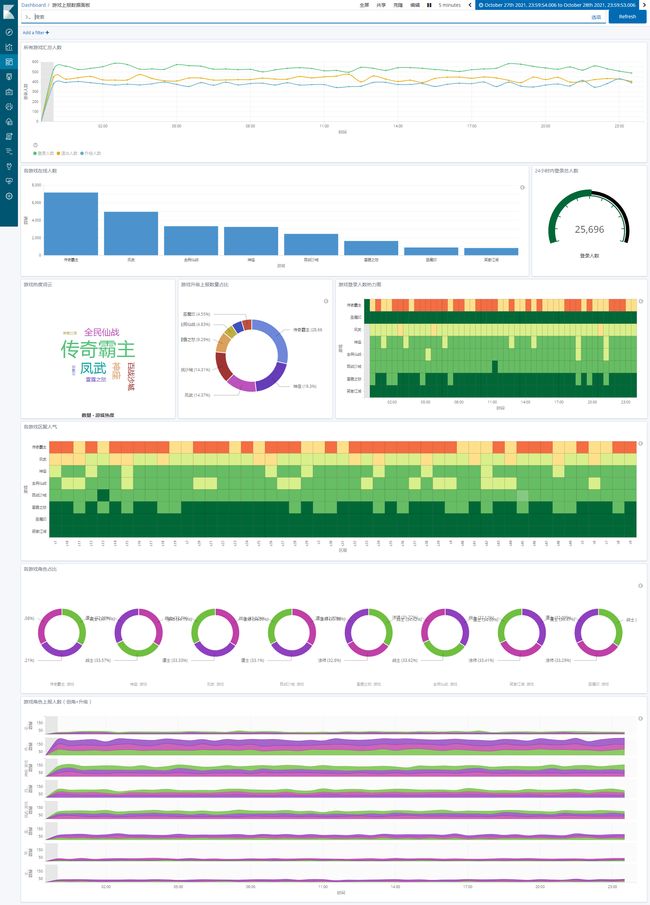
Kibana 可视化示图
问题处理
问题 1
Flink SQL> select TO_TIMESTAMP(FROM_UNIXTIME(NOW() / 1000, 'yyyy-MM-dd HH:mm:ss')) as create_time;
[ERROR] Could not execute SQL statement. Reason:
org.apache.calcite.sql.validate.SqlValidatorException: Cannot apply '/' to arguments of type' / '. Supported form(s): ' / '' / ' 处理:指出 FROM_UNIXTIME (NOW () / 1000, 'yyyy-MM-dd HH:mm:ss') 中的第一个参数运算方式,必需为 < TIMESTAMP (0)> 或 < NUMERIC> 、
问题 2
Flink SQL> select TO_TIMESTAMP(FROM_UNIXTIME(NOW(), 'yyyy-MM-dd HH:mm:ss')) as create_time;
[ERROR] Could not execute SQL statement. Reason:
org.apache.calcite.sql.validate.SqlValidatorException: Cannot apply 'FROM_UNIXTIME' to arguments of type'FROM_UNIXTIME(, )'. Supported form(s): 'FROM_UNIXTIME()''FROM_UNIXTIME(, )' 处理:nwo () 其实返回当前时区时间的时间戳,单位为秒,按理说也是 BIGINT,为啥就是不可以。换成 TO_TIMESTAMP (DATE_FORMAT (CURRENT_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss')) 来获取当前时间;
问题 3
[INFO] Submitting SQL updatestatementto the cluster...
[ERROR] Could notexecuteSQL statement. Reason:
org.apache.flink.table.api.ValidationException: TypeTIMESTAMP(6) oftablefield'create_time' does notmatchwith the physicaltypeTIMESTAMP(3) of the 'create_time'fieldof the TableSink consumed type.处理:原定义 create_time 字段为 TIMESTAMP 类型;通过 describe tableName; 查看发现该字段实际为 TIMESTAMP (6) 即时间为毫秒级,如:2020-10-21T03:58:37.100; 重新建表,create_time 字段指定 TIMESTAMP (3) 即可,即秒级,如:2020-10-21T03:58:37;
问题 4
data_time入elasticsearch后,发现时间比window_time大了8小时,MAX(ts) 获取最大时间戳后,转换显示为:2021-10-22T00:22:06,其中带T则是因为flink时区问题TIMESTAMP类型数据,根据“格林威治标准时间”会向东区增加8小时,最终进入elasticsearch后为2021-10-2208:22:06;处理:通过以下几种方案;
方案 1:CONVERT_TZ (DATE_FORMAT (ts, 'yyyy-MM-dd HH:mm:ss'),'UTC','GMT-08:00'),CONVERT_TZ (string1, string2, string3) 将日期时间字符串 1(具有默认 ISO 时间戳格式 'yyyy-MM-dd HH:mm:ss')从时区字符串 2 转换为时区字符串 3。时区的格式应该是缩写(例如 “PST”)、全名(例如 “America/Los_Angeles”)或自定义 ID(例如 “GMT-08:00”)。例如,CONVERT_TZ ('1970-01-01 00:00:00', 'UTC', 'America/Los_Angeles') 返回 '1969-12-31 16:00:00'。
方案 2:FROM_UNIXTIME (createTimeSeries / 1000 - (60 * 60 * 8), 'yyyy-MM-dd HH:mm:ss'),直接取源数据的时间戳除以 1000 (取秒值)- 减去东区增加的 8 小时;
方案 3:cast (MAX (ts) as INT) - (60 * 60 * 8),直接从 t (TIMESTAMP 类型) 转换成 INT 类型减去 8 小时的秒数即为原始时间值(注:ts 已转换为秒的时间戳,非毫秒),在通过 FROM_UNIXTIME (date,string) 方法转成 TIMESTAMP 类型数据。
问题 5
--flink中jobTask执行意外失败,需要重新恢复job从kafka中消费数据,经过分析,主要是消费数据后,推送到es中失败,需要从上一个时间点恢复job;
2021-10-23 17:51:34,134 INFOorg.apache.flink.runtime.executiongraph.ExecutionGraph[]-Jobdefault: insertintoes_min_game_role_count_sink
...
fromes_count_min_game_role_view (9d4aefc94586b02dfd809261d35e7d26) switchedfromstateFAILINGtoFAILED.
org.apache.flink.runtime.JobException: RecoveryissuppressedbyNoRestartBackoffTimeStrategy
atorg.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:116) ~[flink-dist_2.12-1.11.1.jar:1.11.1]
...
Causedby: java.lang.RuntimeException: AnerroroccurredinElasticsearchSink.
...处理:重新建 source 源表,配置 kafka 属性中的'scan.startup.mode' = 'timestamp',再通过'scan.startup.timestamp-millis' = '1634982694000' 指定时间点(毫秒)来消费 kafka 中的数据,重启 job;防止 flink 中重启后获取的数据偏移位为当前最新,导致数据缺失计算;
-- 创建表
CREATE TABLE game_source2 (
gameId STRING,
serverId STRING,
uid BIGINT,
event STRING,
role STRING,
createTime STRING,
createTimeSeries BIGINT,
ts AS TO_TIMESTAMP(FROM_UNIXTIME(createTimeSeries / 1000, 'yyyy-MM-dd HH:mm:ss')),
WATERMARK FOR ts AS ts - INTERVAL'5'SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'game_behavior',
'properties.bootstrap.servers' = '192.168.1.1:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'timestamp',
'scan.startup.timestamp-millis' = '1634982694000',
'format' = 'json'
);