第一章 PostgreSQL中的数据库集群、数据库和表
前言
最近想研究一下《The Internals of PostgreSQL》by Hironobu Suzuki 这本书。书内容很好,干货满满,强烈推荐。
英文电子版:https://www.interdb.jp/pg/
中文版:https://item.jd.com/12527505.html
虽然这本书有中文版,但是我还想从英文版读起,结合自己的理解,去翻译或者重新整理下这本书,一方面是因为想同时提高自己阅读英文文档的能力,另一方面我觉得中译之后的书,会给我一种距离感。将一种语言转换成另一种语言,这个过程中或多或少会伴随着信息的缺失,我担心这种缺失,会影响我的理解。
以上。
另外最近想运营一个公众号,专门发一些有关PG和linux运维的总结,刚刚搞起,很多不足之处,望海涵,欢迎各位来踩~ 公众号《PostgreSQL运维技术》。
悄悄放一张:

话不多说...
这一章主要介绍四个概念:
数据库集群的逻辑结构
数据库集群的物理结构
表文件的内部布局
读写数据元组的方法
数据库集群的逻辑结构
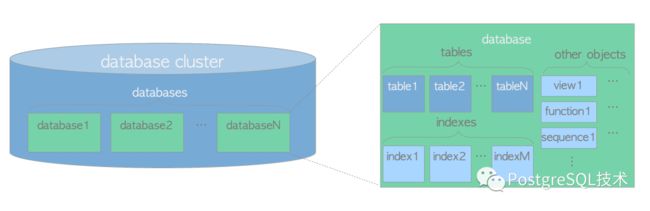
Pg中的集群,也即database cluster,是由PostgreSQL服务端来管理的一组数据库(database)的集合。注意这里是数据库(database)的集合,不是数据库服务(database servers)的集合。一个PostgreSQL服务器运行在单个主机上,管理单个数据库集群。
Pg与大多数的关系型数据库一样都是由表来存储数据,一个表(table)属于某个数据库(database),数据库(database)又同属于一个database cluster。
图1.1.数据库集群的逻辑结构
图片来源:https://www.interdb.jp/pg/pgsql01.html
在一个数据库集群中,除了有表、数据库这些数据库对象,还有比如索引、视图、函数、序列等对象,pg对这些对象统一采用对象标识符(OIDs)来管理,oid是无符号的4字节整数。数据库对象和各自的oid存储在各自的system catalogs中,比如table是存储在pg_class, 而dababase存储在pg_database中。


数据库集群的物理结构
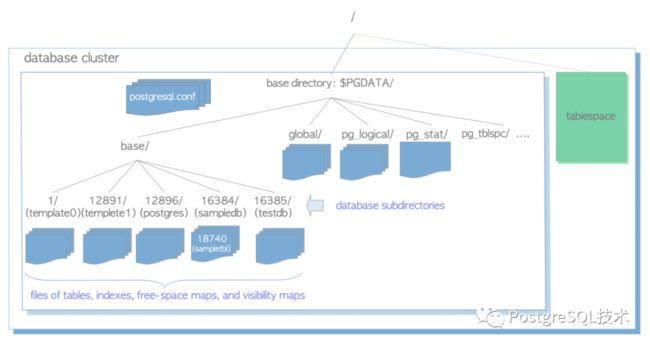
上面我们谈的是集群的逻辑结构,也即抽象概念。现在我们聊聊的物理结构也即真实存在的结构。实际上,pg的数据库集群本质上是一个目录。目录中包含一些子目录和很多的文件。
在我们安装pg时,我们一般使用initdb的命令去初始化一个新的数据库集群。initdb 有个-D参数,通过它来指定应该存储数据库集群的目录。(initdb命令可以参考我之前的一篇博客:
https://blog.csdn.net/qq_35462323/article/details/104059818)
而集群中的database对应$PGDATA/base目录下的一个文件夹,文件夹的名称即我们上面提到的oid。

比如我的pg数据上有下面四个数据库(使用\l命令查看所有数据库):
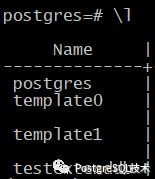
分别查看其oid:
select datname,oid from pg_database where datname in ('postgres','template0','template1','testextenddb');

可以发现查询到的oid是与base子目录下文件夹名是一一对应的。
图1.2.数据库集群示例
图片来源:https://www.interdb.jp/pg/pgsql01.html
那么database中的table是否也是对应base目录下的一个路径呢?答案是是的。
pg中size小于1GB的表或者索引都是存储在其所属的数据库目录下的某个文件。表和索引作为数据库对象在内部由单独的oid管理,而这些数据文件由变量relfilenode管理。
比如查看postgres数据库下的autotest_check表的oid和relfilenode。
select oid,relfilenode from pg_class where relname = 'autotest_check' limit 1;

此时,autotest_check对应文件的路径为'base/13287/21415'
注意:表和索引的relfilenode值并不总是与各自的oid匹配,因为表和索引的relfilenode值会因为TRUNCATE, REINDEX, CLUSTER等命令而改变。
在9.0或更高版本中,可以使用pg_relation_filepath函数返回某个table对应的oid路径。
比如此处的autotest_check,确实是为上面分析的'base/13287/21415'。

当表和索引的文件大小超过1GB时,PostgreSQL会创建一个名为relfilenode.1 的文件,如果新文件已被填满,则下一个名为relfilenode.2的文件将被创建,以此类推(注:在构建PostgreSQL时,可以使用选项——with-segsize来更改表和索引的最大文件大小)。
除了database对应于$PGDATA下的base文件夹,我们还要了解下,$PGDATA下的其他文件或者文件夹的含义和作用。
下表来源官方文档:https://www.postgresql.org/docs/current/storage-file-layout.html。
表1.1.$PGDATA目录下的文件和子目录的布局
| PG_VERSION | 包含PG大版本号的文件 |
| postgresql.auto.conf | 用于存储由ALTER SYSTEM设置的配置参数 |
| postmaster.opts | 记录服务器上次启动时使用的命令行参数的文件 |
| postmaster.pid | 一个锁文件,记录当前postmaster进程的pid,cluster data目录路径,postmaster进程启动时的时间戳,端口号,Unix-domain socket目录路径,有效的listen_address(ip地址或者*,如果为空表示server不基于tcp),共享内存端id。 |
| current_logfiles | 记录日志采集器当前写入的日志文件的文件 |
| base | 包含每个数据库的子目录 |
| global | 包含集群范围表的子目录,例如pg_database |
| pg_commit_ts | 包含事务提交时间戳数据的子目录 |
| pg_dynshmem | 包含动态共享内存子系统使用的文件的子目录 |
| pg_logical | 包含用于逻辑解码的状态数据的子目录 |
| pg_multixact | 包含多事务状态数据的子目录(用于共享行锁) |
| pg_notify | 包含监听/通知状态数据的子目录 |
| pg_replslot | 包含复制槽位数据的子目录 |
| pg_serial | 包含关于已提交的可序列化事务信息的子目录 |
| pg_snapshots | 导出快照的子目录 |
| pg_stat | 包含统计子系统永久文件的子目录 |
| pg_stat_tmp | 包含统计子系统临时文件的子目录 |
| pg_subtrans | 包含子事务状态数据的子目录 |
| pg_tblspc | 包含到表空间的符号链接的子目录 |
| pg_twophase | 包含已准备事务状态文件的子目录 |
| pg_wal | 包含WAL (Write Ahead Log)文件的子目录 |
| pg_xact | 包含事务提交状态数据的子目录 |
表文件的内部布局
在table数据文件内部,文件是被划分为固定长度的页(或块),默认是8kb大小。每个文件中的页面从0开始按顺序编号,这些数字称为块号。如果文件被填满,PG会在文件的末尾添加一个新的空页来增加文件的大小。
图1.3.表文件的页面布局
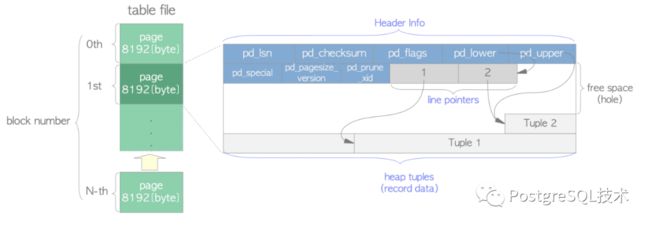
图片来源:https://www.interdb.jp/pg/pgsql01.html
表中的页面包含三种数据:
heap tuples: 堆元组,用于记录数据,从页面底部开始按顺序排列,tuple的内部结构将在第5章和第9章详细介绍。
line pointers: 行指针,占4个字节,保存着指向每个堆元组的指针。行指针构成一个简单的数组,它扮演元组索引的角色。每个索引从1开始按顺序编号,称为偏移量号。当一个新的元组被添加到页面时,一个新的行指针也被推到数组上以指向新的元组。
header data:Header数据,占24个字节,用于存储页面的基本信息。
源码中由PageHeaderData结构定义。该结构中主要变量:
pd_lsn: 这个变量存储该页面最后一次更改时写入的xlog记录的lsn。是一个8字节的无符号整数。
pd_checksum: 这个变量存储这个页面的检验和值。
pd_lower:指向行指针的末尾。
pd_upper: 执行最新的堆元祖的开始。
pd_special: 在表中的页面中,它指向页面的末尾。
另:行指针的末尾和最新元组的开始之间的空白称为空闲空间或空洞。
读写数据元组的方法
文章最后,介绍下写和读数据元组的方法。
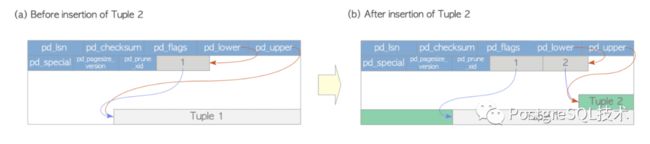
首先是写元组:
假设一个表由一个页面组成,其中只包含一个堆元组。这个页面的pd_lower指向第一个行指针,而line指针和pd_upper都指向第一个堆元组。见图1.4 (a)。
插入第二个元组时,它被放置在第一个元组之后。第二行指针被压入第一行,它指向第二个元组。pd_lower指向第二行指针,而pd_upper指向第二个堆元组。见图1.5 (b)。这个页面中的其他头数据(例如,pd_lsn, pg_checksum, pg_flag)也被重写为合适的值; 更多详情见第5章和第9章。
图1.4.写数据元组
再来是读数据元组:
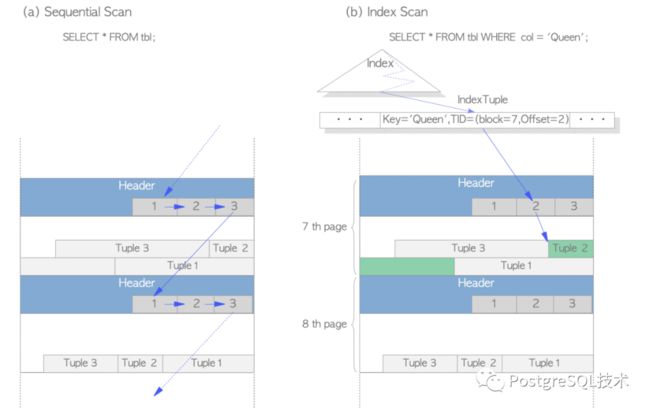
读数据两种典型的访问方法,顺序扫描和b树索引扫描,概述如下:
顺序扫描——通过扫描每个页面中的所有行指针,顺序地读取所有页面中的所有元组。见图1.5(a)。
B-tree索引扫描——索引文件包含索引元组,每个索引元组由一个索引键和一个指向目标堆元组的TID组成。如果您正在寻找的键的索引元组已经找到,PostgreSQL将使用获得的TID值读取所需的堆元组。例如在图1.5(b)中,得到的索引元组的TID值为' (block = 7, Offset = 2) '。这意味着目标堆元组是表中第7页的第2个元组,因此PostgreSQL可以读取所需的堆元组,而无需在页面中进行不必要的扫描。
图1.5.读数据元组