大数据数仓搭建-大数据用户画像推荐系统搭建
一 确定需求
我把需求主要分为三大类
一 离线数据报表需求
二 实时观查数据走向需求
三 算法需求
二 确定系统架构
根据需求我们目前有几种大数据架构可以供参考
流式架构

流式架构非常激进,直接拔掉了批处理,数据全程以流的形式处理,所以在数据接入端没有了ETL,转而替换为数据通道。经过流处理加工后的数据,以消息的形式直接推送给了消费者。虽然有一个存储部分,但是该存储更多的以窗口的形式进行存储,所以该存储并非发生在数据湖,而是在外围系统。
优点:没有臃肿的ETL过程,数据的实效性非常高。
缺点:对于流式架构来说,不存在批处理,因此对于数据的重播和历史统计无法很好的支撑。对于离线分析仅仅支撑窗口之内的分析。
适用场景:预警,监控,对数据有有效期要求的情况。
Lambda架构
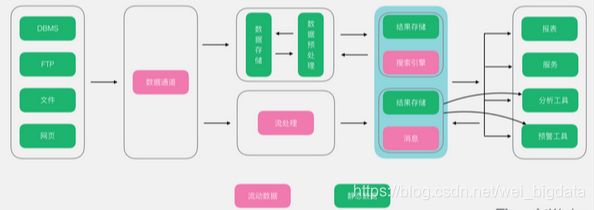 Lambda架构算是大数据系统里面举足轻重的架构,大多数架构基本都是Lambda架构或者基于其变种的架构。Lambda的数据通道分为两条分支:实时流和离线。实时流依照流式架构,保障了其实时性,而离线则以批处理方式为主,保障了最终一致性。
Lambda架构算是大数据系统里面举足轻重的架构,大多数架构基本都是Lambda架构或者基于其变种的架构。Lambda的数据通道分为两条分支:实时流和离线。实时流依照流式架构,保障了其实时性,而离线则以批处理方式为主,保障了最终一致性。
优点:既有实时又有离线,对于数据分析场景涵盖的非常到位。
缺点:离线层和实时流虽然面临的场景不相同,但是其内部处理的逻辑却是相同,因此有大量荣誉和重复的模块存在。
适用场景:同时存在实时和离线需求的情况。
Kappa架构
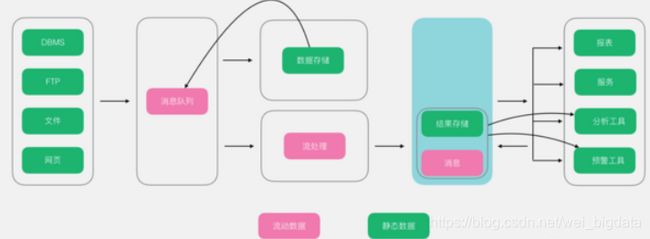 Kappa架构在Lambda 的基础上进行了优化,将实时和流部分进行了合并,将数据通道以消息队列进行替代。因此对于Kappa架构来说,依旧以流处理为主,但是数据却在数据湖层面进行了存储,当需要进行离线分析或者再次计算的时候,则将数据湖的数据再次经过消息队列重播一次则可。
Kappa架构在Lambda 的基础上进行了优化,将实时和流部分进行了合并,将数据通道以消息队列进行替代。因此对于Kappa架构来说,依旧以流处理为主,但是数据却在数据湖层面进行了存储,当需要进行离线分析或者再次计算的时候,则将数据湖的数据再次经过消息队列重播一次则可。
优点:Kappa架构解决了Lambda架构里面的冗余部分,以数据可重播的超凡脱俗的思想进行了设计,整个架构非常简洁。
缺点:虽然Kappa架构看起来简洁,但是施难度相对较高,尤其是对于数据重播部分。
适用场景:和Lambda类似,改架构是针对Lambda的优化。
Unifield架构
 以上的种种架构都围绕海量数据处理为主,Unifield架构则更激进,将机器学习和数据处理揉为一体,从核心上来说,Unifield依旧以Lambda为主,不过对其进行了改造,在流处理层新增了机器学习层。可以看到数据在经过数据通道进入数据湖后,新增了模型训练部分,并且将其在流式层进行使用。同时流式层不单使用模型,也包含着对模型的持续训练。
以上的种种架构都围绕海量数据处理为主,Unifield架构则更激进,将机器学习和数据处理揉为一体,从核心上来说,Unifield依旧以Lambda为主,不过对其进行了改造,在流处理层新增了机器学习层。可以看到数据在经过数据通道进入数据湖后,新增了模型训练部分,并且将其在流式层进行使用。同时流式层不单使用模型,也包含着对模型的持续训练。
优点:Unifield架构提供了一套数据分析和机器学习结合的架构方案,非常好的解决了机器学习如何与数据平台进行结合的问题。
缺点:Unifield架构实施复杂度更高,对于机器学习架构来说,从软件包到硬件部署都和数据分析平台有着非常大的差别,因此在实施过程中的难度系数更高。
适用场景:有着大量数据需要分析,同时对机器学习方便又有着非常大的需求或者有规划。
**总结:**根据公司需求选择最合适的架构,我建议选择lambda架构,增加额外需求,可在此基础上变更,不影响原来业务。
三 搭建数仓流程
3.1数仓构建流程

3.2需要懂得指标
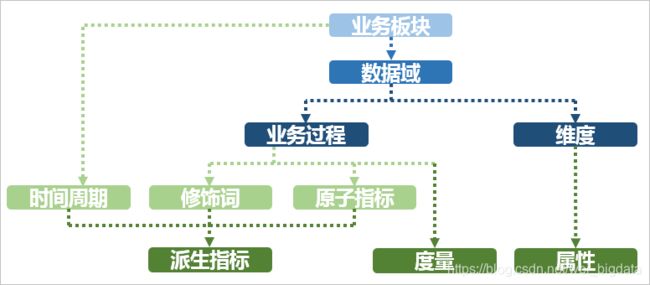
业务板块:比数据域更高维度的业务划分方法,适用于特别庞大的业务系统。
维度:维度建模由Ralph Kimball提出。维度模型主张从分析决策的需求出发构建模型,为分析需求服务。维度是度量的环境,是我们观察业务的角度,用来反映业务的一类属性 。属性的集合构成维度 ,也可以称为实体对象。例如, 在分析交易过程时,可以通过买家、卖家、商品和时间等维度描述交易发生的环境。
**属性(维度属性):**维度所包含的表示维度的列称为维度属性。维度属性是查询约束条件、分组和报表标签生成的基本来源,是数据易用性的关键。
**度量:**在维度建模中,将度量称为事实 , 将环境描述为维度,维度是用于分析事实所需要的多样环境。度量通常为数值型数据,作为事实逻辑表的事实。
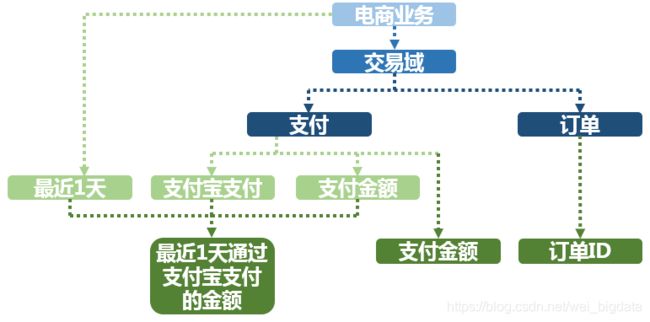
**指标:**指标分为原子指标和派生指标。原子指标是基于某一业务事件行为下的度量,是业务定义中不可再拆分的指标,是具有明确业务含义的名词 ,体现明确的业务统计口径和计算逻辑,例如如支付金额。
原子指标=业务过程+度量
派生指标=时间周期+修饰词+原子指标,派生指标可以理解为对原子指标业务统计范围的圈定。
业务限定:统计的业务范围,筛选出符合业务规则的记录(类似于SQL中where后的条件,不包括时间区间)。
**统计周期:统计的时间范围,例如最近一天,最近30天等(类似于SQL中where后的时间条件)。
统计粒度:统计分析的对象或视角,定义数据需要汇总的程度,可理解为聚合运算时的分组条件(类似于SQL中的group by的对象)。粒度是维度的一个组合,指明您的统计范围。例如某个指标是某个卖家在某个省份的成交额,则粒度就是卖家、地区这两个维度的组合。如果您需要统计全表的数据,则粒度为全表。在指定粒度时,您需要充分考虑到业务和维度的关系。统计粒度常用语作为派生指标的修饰词而存在。
3.3业务调研
确定需求,分析业务过程,划分数据域,定义维度,定义总线矩阵,明确统计指标。
具体不细说,根据公司讨论为主。
3.4架构与模型
数据模型:
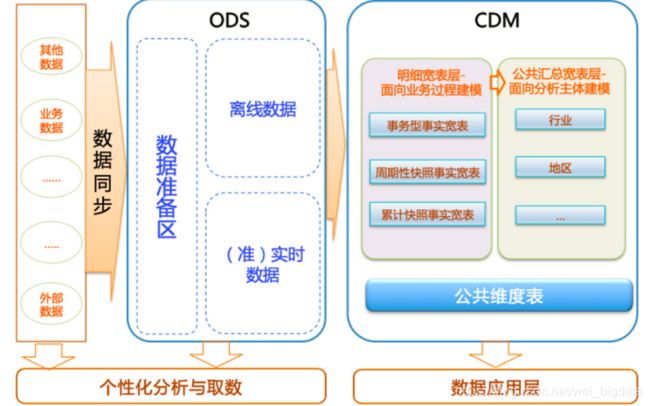
数据引入层 ods
明细粒事实层 dwd
公共汇总层dws
集市层dm
公共维度层dim
此时你要知道哪层是装载数据,哪层是建立雪花或者星型模型,哪层汇总,哪层供集市使用。
参考阿里巴巴数据建议模型

 建立过程规范化
建立过程规范化
表名规范化 如公共维度层 表名为dim_xx
保证数仓性能
稳定性,查询速度,数据安全性等
3.5总结
数仓这块主要是以业务为主,更多的需要实际沟通和探讨,技术层次组件使用,语言hql.
四 用户画像搭建
4.1了解用户画像
用户画像的核心工作是为用户打标签,打标签的重要目的之一是为了让人能够理解并且方便计算机处理,如,可以做分类统计:喜欢红酒的用户有多少?喜欢红酒的人群中,男、女比例是多少?
也可以做数据挖掘工作:利用关联规则计算,喜欢红酒的人通常喜欢什么运动品牌?利用聚类算法分析,喜欢红酒的人年龄段分布情况?
大数据处理,离不开计算机的运算,标签提供了一种便捷的方式,使得计算机能够程序化处理与人相关的信息,甚至通过算法、模型能够“理解” 人。当计算机具备这样的能力后,无论是搜索引擎、推荐引擎、广告投放等各种应用领域,都将能进一步提升精准度,提高信息获取的效率。
4.2用户画像搭建方法
数据源分析
用户数据划分为静态信息数据、动态信息数据两大类。
静态信息数据
主要包括人口属性、商业属性等方面数据
动态信息数据
用户不断变化的行为信息,当行为集中到互联网,乃至电商,用户行为就会聚焦很多。
目标数据分析
用户画像的目标是通过分析用户行为,最终为每个用户打上标签,以及该标签的权重。如,红酒 0.8、李宁 0.6。
标签,表征了内容,用户对该内容有兴趣、偏好、需求等等。
权重,表征了指数,用户的兴趣、偏好指数,也可能表征用户的需求度,可以简单的理解为可信度,概率。
数据建模方法
下面内容将详细介绍,如何根据用户行为,构建模型产出标签、权重。一个事件模型包括:时间、地点、人物三个要素。
每一次用户行为本质上是一次随机事件,可以详细描述为:什么用户,在什么时间,什么地点,做了什么事。
什么用户:关键在于对用户的标识,用户标识的目的是为了区分用户、单点定位。
综合上述分析,用户画像的数据模型,可以概括为下面的公式:用户标识 + 时间 + 行为类型 + 接触点(网址+内容),某用户因为在什么时间、地点、做了什么事。所以会打上**标签。
用户标签的权重可能随时间的增加而衰减,因此定义时间为衰减因子r,行为类型、网址决定了权重,内容决定了标签,进一步转换为公式:
标签权重=衰减因子×行为权重×网址子权重
4.3用户画像应用
用户画像是企业一个必需品,只要掌握好用户动态,就能掌握好企业产品方向。应用主要提供算法上一些产品 典型案例:推荐
总结:
用户画像主要是给用户打标签,权重,衰减系数,累加,存储库。
五 推荐系统搭建
推荐算法目前有
cf协同过滤(用户和物品)推荐
cb内容推荐(分类,决策树,近邻算法)
kb基于知识推荐(样例和约束)
混合搭配推荐
算法主要围绕推荐系统几个算法。
六 更多学习大数据朋友
我微信:LaoJiangdata 备注:大数据
公众号以及哔哩号关注:老姜的数据江湖
每周更新一篇公众号,CSDN。哔哩每周三更:职场、面试、技术。