- php、go、python后端接口签名实现
奇华智能
后台开发linux签名接口安全
1.php实现/**生成签名,$args为请求参数,$key为私钥*/functionmakeSignature($args,$key){if(isset($args['sign'])){$oldSign=$args['sign'];unset($args['sign']);}else{$oldSign='';}ksort($args);$requestString='';foreach($arg
- python第一次作业
1.技术面试题(1)TCP与UDP的区别是什么?**答:1.TCP是面向连接的协议,而UDP是元连接的协议2.TCP协议传输是可靠的,而UDP协议的传输是“尽力而为3.TCP是可以实现流控,而UDP不行4.TCP可以实现分段,而UDP不行5.TCP的传输速率较慢,占用资源较大,UDP传输速率快,占用资源小。TCP/UDP的应用场景不同TCP适合可靠性高的效率要求低的,UDP可靠性低,效率高。(2)
- python
www_hhhhhhh
pythonjava面试
1.技术面试题(1)解释Linux中的进程、线程和守护进程的概念,以及如何管理它们?答:进程:是操作系统进行资源分配的基本单位,拥有独立的地址空间、进程控制块,每个进程之间相互隔离。例如,打开一个终端窗口会启动一个bash进程。线程:是操作系统调度的基本单位,隶属于进程,共享进程的资源,但有独立的线程控制块和栈。线程切换开销远小于进程。例如,一个Web服务器的单个进程中,多个线程可同时处理不同客户
- Python lambda表达式:匿名函数的适用场景与限制
梦幻南瓜
pythonpython服务器linux
目录1.Lambda表达式概述1.1Lambda表达式的基本语法1.2简单示例2.Lambda表达式的核心特点2.1匿名性2.2简洁性2.3即时性2.4函数式编程特性3.Lambda表达式的适用场景3.1作为高阶函数的参数3.2简单的数据转换3.3条件筛选3.4GUI编程中的回调函数3.5Pandas数据处理4.Lambda表达式的限制4.1只能包含单个表达式4.2没有语句4.3缺乏文档字符串4.
- 【python】
www_hhhhhhh
python面试职场和发展
1.技术面试题(1)TCP与UDP的区别是什么?答:TCP(传输控制协议)和UDP(用户数据报协议)是两种常见的传输层协议,主要区别在于连接方式和可靠性。TCP是面向连接的协议,传输数据前需建立连接,通过三次握手确保连接可靠,传输过程中有确认、重传和顺序控制机制,保证数据完整、按序到达,适用于网页浏览、文件传输等对可靠性要求高的场景。UDP是无连接的协议,无需建立连接即可发送数据,不保证数据可靠传
- Python函数的返回值
1.返回值定义及案例:2.返回值与print的区别:print仅仅是打印在控制台,而return则是将return后面的部分作为返回值作为函数的输出,可以用变量接走,继续使用该返回值做其它事。3.保存函数的返回值如果一个函数return返回了一个数据,那么想要用这个数据,那么就需要保存.#定义函数defadd2num(a,b): returna+b#调用函数,顺便保存函数的返回值result=
- python怎么把函数返回值_python函数怎么返回值
python函数使用return语句返回“返回值”,可以将其赋给其它变量作其它的用处。所有函数都有返回值,如果没有return语句,会隐式地调用returnNone作为返回值。python函数使用return语句返回"返回值",可以将其赋给其它变量作其它的用处。所有函数都有返回值,如果没有return语句,会隐式地调用returnNone作为返回值。一个函数可以存在多条return语句,但只有一条
- Python星球日记 - 第8天:函数基础
Code_流苏
Python星球日记python函数def关键字函数参数返回值
引言:上一篇:Python星球日记-第7天:字典与集合名人说:路漫漫其修远兮,吾将上下而求索。——屈原《离骚》创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder)目录一、函数的定义与调用1.什么是函数?2.如何定义函数-`def`关键字3.函数调用方式二、参数与返回值1.函数参数类型2.如何传递参数3.返回值和`return`语句三、局部变量与全局变量1.变量作用域概念2.局部变
- 华为OD机试2025C卷 - 小明的幸运数 (C++ & Python & JAVA & JS & GO)
无限码力
华为od华为OD机试2025C卷华为OD2025C卷华为OD机考2025C卷
小明的幸运数华为OD机试真题目录点击查看:华为OD机试2025C卷真题题库目录|机考题库+算法考点详解华为OD机试2025C卷100分题型题目描述小明在玩一个游戏,游戏规则如下:在游戏开始前,小明站在坐标轴原点处(坐标值为0).给定一组指令和一个幸运数,每个指令都是一个整数,小明按照指令前进指定步数或者后退指定步数。前进代表朝坐标轴的正方向走,后退代表朝坐标轴的负方向走。幸运数为一个整数,如果某个
- Python 函数返回值
落花雨时
Python基础
#返回值,返回值就是函数执行以后返回的结果#可以通过return来指定函数的返回值#可以之间使用函数的返回值,也可以通过一个变量来接收函数的返回值defsum(*nums):#定义一个变量,来保存结果result=0#遍历元组,并将元组中的数进行累加forninnums:result+=nprint(result)#sum(123,456,789)#return后边跟什么值,函数就会返回什么值#r
- 存档python爬虫、Web学习资料
1python爬虫学习学习Python爬虫是个不错的选择,它能够帮你高效地获取网络数据。下面为你提供系统化的学习路径和建议:1.打好基础首先要掌握Python基础知识,这是学习爬虫的前提。比如:变量、数据类型、条件语句、循环等基础语法。列表、字典等常用数据结构的操作。函数、模块和包的使用方法。文件读写操作。推荐通过阅读《Python编程:从入门到实践》这本书或者在Codecademy、LeetCo
- Python爬虫入门到实战(3)-对网页进行操作
荼蘼
爬虫
一.获取和操作网页元素1.获取网页中的指定元素tag_name()方法:获取元素名称。text()方法:获取元素文本内容。click()方法():点击此元素。submit()方法():提交表单。send_keys()方法:模拟输入信息。size()方法:获取元素的尺寸可进入selenium库文件夹下的webdriver\remote\webelement.py中查看更多的操作方法,2.在元素中输入
- 华为OD 机试 2025 B卷 - 周末爬山 (C++ & Python & JAVA & JS & GO)
无限码力
华为OD机试真题刷题笔记华为od华为OD2025B卷华为OD机考2025B卷华为OD机试2025B卷华为OD机试
周末爬山华为OD机试真题目录点击查看:华为OD机试2025B卷真题题库目录|机考题库+算法考点详解华为OD机试2025B卷200分题型题目描述周末小明准备去爬山锻炼,0代表平地,山的高度使用1到9来表示,小明每次爬山或下山高度只能相差k及k以内,每次只能上下左右一个方向上移动一格,小明从左上角(0,0)位置出发输入描述第一行输入mnk(空格分隔)。代表m*n的二维山地图,k为小明每次爬山或下山高度
- Python,C++,Go开发芯片电路设计APP
Geeker-2025
pythonc++golang
#芯片电路设计APP-Python/C++/Go综合开发方案##系统架构设计```mermaidgraphTDA[Web前端]-->B(Python设计界面)B-->C(GoAPI网关)C-->D[C++核心引擎]D-->E[硬件加速]F[数据库]-->CG[EDA工具链]-->DH[云服务]-->C```##技术栈分工|技术|应用领域|优势||------|----------|------||
- 红队测试-代理和中间人攻击工具
小浪崇礼
BetterCAP-Modular,portableandeasilyextensibleMITMframework.Ettercap-Comprehensive,maturesuiteformachine-in-the-middleattacks.Habu-Pythonutilityimplementingavarietyofnetworkattacks,suchasARPpoisoning,D
- pyside6使用1 窗体、信号和槽
一、概要由于作者前期很多年都在使用C++和Qt框架进行项目的开发工作,故可以熟练的使用Qt框架。Qt框架在界面设计以及跨平台运用方面,有着巨大的优势,而界面设计恰恰是python的短板,故使用pyside6实现python和Qt的互补。1.1pyside6安装更新pip工具:pipinstall--upgradepip命令行执行如下指令:pipinstallpyside6-ihttps://pyp
- python-读写mysql(操作mysql数据库)
importpymysqlimportpandasaspdimporttimeonly_time=time.localtime(time.time())time_now=time.strftime('%Y-%m-%d%H:%M:%S',only_time)dt=time.strftime('%Y%m%d',only_time)t=time.time()tt=int(t)parentId=''sta
- python读写mysql
cavin_2017
Python学习
目前用到的连接数据库,主要实现连个功能:1.根据sql查询2.将dataframe数据通过pandas包写入mysql数据库中1.根据sql查询:通常我们通过sql查询mysql中的表,分三步1.连接数据库2.数据查询3.关闭连接,如果需要查询的步骤较多,将查询封装成函数,通过参数传递sql代码会省事很多。##定义连接数据库函数defmy_db(host,user,passwd,db,sql,po
- python+playwright 学习-91 cookies的获取保存删除相关操作
上海-悠悠
playwrightpython
前言playwright可以获取浏览器缓存的cookie信息,可以将这些cookies信息保存到本地,还可以加载本地cookies。获取cookies相关操作在登录前和登录后分别打印cookies信息,对比查看是否获取成功。fromplaywright.sync_apiimportsync_playwrightwithsync_playwright()asp:browser=p.chromium.
- Python——登录后获取cookie访问页面
尖叫的太阳
importrequestsurl="https://kyfw.12306.cn/otn/view/index.html"#网址首页https://kyfw.12306.cn/otn/view/index.html的cookieheaders={'User-Agent':'Mozilla/5.0(WindowsNT6.1;Win64;x64)','Cookie':'JSESSIONID=3330D
- python request 获取cookies value值的方法
dianqianwei8752
pythonc/c++
importrequestsres=requests.get(url)cookies=requests.utils.dict_from_cookiejar(res.cookies)print(cookies[key])转载于:https://www.cnblogs.com/VseYoung/p/python_cookies.html
- python连接达梦数据库方式
water bucket
python数据库pandas
1、通过jaydebeapi调用jdbcimportpandasaspdimportjaydebeapiif__name__=='__main__':url='jdbc:dm://{IP}:{PORT}/{库名}'username='{username}'password='{password}'jclassname='dm.jdbc.driver.DmDriver'jarFile='{DmJdb
- Python一次性批量下载网页内所有链接
Zhy_Tech
python前端开发语言
需要下载一个数据集,该数据集每一张图对应网页内一条链接,如下图所示。一开始尝试使用迅雷,但是迅雷一次性只能下载30条链接。采用Python成功实现一次性批量下载。importosimportrequestsfrombs4importBeautifulSoup#目标网页的URLurl="https://"#请将此处替换为实际的网页URL#指定下载文件的文件夹路径#使用原始字符串download_fo
- 初探贪心算法 -- 使用最少纸币组成指定金额
是小V呀
C++贪心算法算法c++python
python实现:#对于任意钱数,求最少张数n=int(input("money:"))#输入钱数bills=[100,50,20,10,5,2,1]#纸币面额种类total=0forbinbills:count=n//b#整除面额求用的纸币张数ifcount>0:print(f"{b}纸币张数{count}")n-=count*b#更新剩余金额total+=count#累加纸币数量print(f
- 【Python】Gym 库:于开发和比较强化学习(Reinforcement Learning, RL)算法
彬彬侠
Python基础pythonGym强化学习RLGymnasium
Gym是Python中一个广泛使用的开源库,用于开发和比较强化学习(ReinforcementLearning,RL)算法。它最初由OpenAI开发,提供标准化的环境接口,允许开发者在各种任务(如游戏、机器人控制、模拟物理系统)中测试RL算法。Gym的设计简单且灵活,适合学术研究和工业应用。2022年,Gym被整合到Gymnasium(由FaramaFoundation维护)中,成为主流的强化学习
- Python 虚拟环境完全指南
wsj__WSJ
pythonpython开发语言
为何离不开虚拟环境?在Python开发领域,虚拟环境堪称管理项目依赖的不二利器,其重要性体现在多个关键层面:项目隔离独立运行环境构建:为每一个项目量身打造专属的Python运行环境,使各个项目之间相互隔离,互不干扰。化解依赖版本冲突:有效解决不同项目对同一依赖包的版本需求不一致的难题。例如,项目A基于Django3.2进行开发,而项目B需要Django4.0才能正常运作,通过虚拟环境,两者可并行不
- python学习路线(从菜鸟到起飞)
突突突然不会编了
python学习开发语言
以下是基于2025年最新技术趋势的Python学习路线,综合多个权威资源整理而成,涵盖从零基础到进阶应用的全流程,适合不同学习目标(如Web开发、数据分析、人工智能等)的学习者。路线分为基础、进阶、实战、高级、方向拓展五个阶段,并附学习资源推荐:一、基础阶段(1-2个月)目标:掌握Python核心语法与编程思维,熟悉开发环境。环境搭建安装Python3.10+,配置PyCharm或VSCode开发
- 小白带你部署LNMP分布式部署
刘俊涛liu
分布式
目录前言一、概述二、LNMP环境部署三、配置nginx1、yum安装2、编译安装四、安装1、编译安装nginx2、网络源3、稍作优化4、修改配置文件vim/usr/local/nginx/conf/nginx.conf5、书写测试页面五、部署应用前言LNMP平台指的是将Linux、Nginx、MySQL和PHP(或者其他的编程语言,如Python、Perl等)集成在一起的一种Web服务器环境。它是
- 如何构建FunASR的本地语音识别服务
FunASR简介FunASR是阿里巴巴达摩院开源的高性能语音识别工具包,支持离线识别和实时流式识别两种模式。其核心特点包括:支持多种语音任务:ASR(自动语音识别)、VAD(语音活动检测)、标点恢复、关键词检测等。提供预训练模型:覆盖中文、英文等多语言,支持不同场景(通用、会议、直播等)。支持多种部署方式:本地Python、Docker容器、ONNX推理优化等。开源地址:GitHub-FunASR
- Python 进阶学习之全栈开发学习路线
Microi风闲
【胶水语言】Pythonpython学习开发语言
文章目录前言一、Python全栈开发技术栈1.前端技术选型2.后端框架选择3.数据库访问二、开发环境配置1.工具链推荐2.VSCode终极配置3.项目依赖管理三、现代Python工程实践1.项目结构规范2.自动化测试策略3.CI/CD流水线四、部署策略大全1.传统服务器部署2.容器化部署3.无服务器部署五、性能优化技巧1.数据库优化2.异步处理3.静态资源优化结语前言Python作为当今最流行的编
- Java序列化进阶篇
g21121
java序列化
1.transient
类一旦实现了Serializable 接口即被声明为可序列化,然而某些情况下并不是所有的属性都需要序列化,想要人为的去阻止这些属性被序列化,就需要用到transient 关键字。
- escape()、encodeURI()、encodeURIComponent()区别详解
aigo
JavaScriptWeb
原文:http://blog.sina.com.cn/s/blog_4586764e0101khi0.html
JavaScript中有三个可以对字符串编码的函数,分别是: escape,encodeURI,encodeURIComponent,相应3个解码函数:,decodeURI,decodeURIComponent 。
下面简单介绍一下它们的区别
1 escape()函
- ArcgisEngine实现对地图的放大、缩小和平移
Cb123456
添加矢量数据对地图的放大、缩小和平移Engine
ArcgisEngine实现对地图的放大、缩小和平移:
个人觉得是平移,不过网上的都是漫游,通俗的说就是把一个地图对象从一边拉到另一边而已。就看人说话吧.
具体实现:
一、引入命名空间
using ESRI.ArcGIS.Geometry;
using ESRI.ArcGIS.Controls;
二、代码实现.
- Java集合框架概述
天子之骄
Java集合框架概述
集合框架
集合框架可以理解为一个容器,该容器主要指映射(map)、集合(set)、数组(array)和列表(list)等抽象数据结构。
从本质上来说,Java集合框架的主要组成是用来操作对象的接口。不同接口描述不同的数据类型。
简单介绍:
Collection接口是最基本的接口,它定义了List和Set,List又定义了LinkLi
- 旗正4.0页面跳转传值问题
何必如此
javajsp
跳转和成功提示
a) 成功字段非空forward
成功字段非空forward,不会弹出成功字段,为jsp转发,页面能超链接传值,传输变量时需要拼接。接拼接方式list.jsp?test="+strweightUnit+"或list.jsp?test="+weightUnit+&qu
- 全网唯一:移动互联网服务器端开发课程
cocos2d-x小菜
web开发移动开发移动端开发移动互联程序员
移动互联网时代来了! App市场爆发式增长为Web开发程序员带来新一轮机遇,近两年新增创业者,几乎全部选择了移动互联网项目!传统互联网企业中超过98%的门户网站已经或者正在从单一的网站入口转向PC、手机、Pad、智能电视等多端全平台兼容体系。据统计,AppStore中超过85%的App项目都选择了PHP作为后端程
- Log4J通用配置|注意问题 笔记
7454103
DAOapachetomcatlog4jWeb
关于日志的等级 那些去 百度就知道了!
这几天 要搭个新框架 配置了 日志 记下来 !做个备忘!
#这里定义能显示到的最低级别,若定义到INFO级别,则看不到DEBUG级别的信息了~!
log4j.rootLogger=INFO,allLog
# DAO层 log记录到dao.log 控制台 和 总日志文件
log4j.logger.DAO=INFO,dao,C
- SQLServer TCP/IP 连接失败问题 ---SQL Server Configuration Manager
darkranger
sqlcwindowsSQL ServerXP
当你安装完之后,连接数据库的时候可能会发现你的TCP/IP 没有启动..
发现需要启动客户端协议 : TCP/IP
需要打开 SQL Server Configuration Manager...
却发现无法打开 SQL Server Configuration Manager..??
解决方法: C:\WINDOWS\system32目录搜索framedyn.
- [置顶] 做有中国特色的程序员
aijuans
程序员
从出版业说起 网络作品排到靠前的,都不会太难看,一般人不爱看某部作品也是因为不喜欢这个类型,而此人也不会全不喜欢这些网络作品。究其原因,是因为网络作品都是让人先白看的,看的好了才出了头。而纸质作品就不一定了,排行榜靠前的,有好作品,也有垃圾。 许多大牛都是写了博客,后来出了书。这些书也都不次,可能有人让为不好,是因为技术书不像小说,小说在读故事,技术书是在学知识或温习知识,有些技术书读得可
- document.domain 跨域问题
avords
document
document.domain用来得到当前网页的域名。比如在地址栏里输入:javascript:alert(document.domain); //www.315ta.com我们也可以给document.domain属性赋值,不过是有限制的,你只能赋成当前的域名或者基础域名。比如:javascript:alert(document.domain = "315ta.com");
- 关于管理软件的一些思考
houxinyou
管理
工作好多看年了,一直在做管理软件,不知道是我最开始做的时候产生了一些惯性的思维,还是现在接触的管理软件水平有所下降.换过好多年公司,越来越感觉现在的管理软件做的越来越乱.
在我看来,管理软件不论是以前的结构化编程,还是现在的面向对象编程,不管是CS模式,还是BS模式.模块的划分是很重要的.当然,模块的划分有很多种方式.我只是以我自己的划分方式来说一下.
做为管理软件,就像现在讲究MVC这
- NoSQL数据库之Redis数据库管理(String类型和hash类型)
bijian1013
redis数据库NoSQL
一.Redis的数据类型
1.String类型及操作
String是最简单的类型,一个key对应一个value,string类型是二进制安全的。Redis的string可以包含任何数据,比如jpg图片或者序列化的对象。
Set方法:设置key对应的值为string类型的value
- Tomcat 一些技巧
征客丶
javatomcatdos
以下操作都是在windows 环境下
一、Tomcat 启动时配置 JAVA_HOME
在 tomcat 安装目录,bin 文件夹下的 catalina.bat 或 setclasspath.bat 中添加
set JAVA_HOME=JAVA 安装目录
set JRE_HOME=JAVA 安装目录/jre
即可;
二、查看Tomcat 版本
在 tomcat 安装目
- 【Spark七十二】Spark的日志配置
bit1129
spark
在测试Spark Streaming时,大量的日志显示到控制台,影响了Spark Streaming程序代码的输出结果的查看(代码中通过println将输出打印到控制台上),可以通过修改Spark的日志配置的方式,不让Spark Streaming把它的日志显示在console
在Spark的conf目录下,把log4j.properties.template修改为log4j.p
- Haskell版冒泡排序
bookjovi
冒泡排序haskell
面试的时候问的比较多的算法题要么是binary search,要么是冒泡排序,真的不想用写C写冒泡排序了,贴上个Haskell版的,思维简单,代码简单,下次谁要是再要我用C写冒泡排序,直接上个haskell版的,让他自己去理解吧。
sort [] = []
sort [x] = [x]
sort (x:x1:xs)
| x>x1 = x1:so
- java 路径 配置文件读取
bro_feng
java
这几天做一个项目,关于路径做如下笔记,有需要供参考。
取工程内的文件,一般都要用相对路径,这个自然不用多说。
在src统计目录建配置文件目录res,在res中放入配置文件。
读取文件使用方式:
1. MyTest.class.getResourceAsStream("/res/xx.properties")
2. properties.load(MyTest.
- 读《研磨设计模式》-代码笔记-简单工厂模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
package design.pattern;
/*
* 个人理解:简单工厂模式就是IOC;
* 客户端要用到某一对象,本来是由客户创建的,现在改成由工厂创建,客户直接取就好了
*/
interface IProduct {
- SVN与JIRA的关联
chenyu19891124
SVN
SVN与JIRA的关联一直都没能装成功,今天凝聚心思花了一天时间整合好了。下面是自己整理的步骤:
一、搭建好SVN环境,尤其是要把SVN的服务注册成系统服务
二、装好JIRA,自己用是jira-4.3.4破解版
三、下载SVN与JIRA的插件并解压,然后拷贝插件包下lib包里的三个jar,放到Atlassian\JIRA 4.3.4\atlassian-jira\WEB-INF\lib下,再
- JWFDv0.96 最新设计思路
comsci
数据结构算法工作企业应用公告
随着工作流技术的发展,工作流产品的应用范围也不断的在扩展,开始进入了像金融行业(我已经看到国有四大商业银行的工作流产品招标公告了),实时生产控制和其它比较重要的工程领域,而
- vi 保存复制内容格式粘贴
daizj
vi粘贴复制保存原格式不变形
vi是linux中非常好用的文本编辑工具,功能强大无比,但对于复制带有缩进格式的内容时,粘贴的时候内容错位很严重,不会按照复制时的格式排版,vi能不能在粘贴时,按复制进的格式进行粘贴呢? 答案是肯定的,vi有一个很强大的命令可以实现此功能 。
在命令模式输入:set paste,则进入paste模式,这样再进行粘贴时
- shell脚本运行时报错误:/bin/bash^M: bad interpreter 的解决办法
dongwei_6688
shell脚本
出现原因:windows上写的脚本,直接拷贝到linux系统上运行由于格式不兼容导致
解决办法:
1. 比如文件名为myshell.sh,vim myshell.sh
2. 执行vim中的命令 : set ff?查看文件格式,如果显示fileformat=dos,证明文件格式有问题
3. 执行vim中的命令 :set fileformat=unix 将文件格式改过来就可以了,然后:w
- 高一上学期难记忆单词
dcj3sjt126com
wordenglish
honest 诚实的;正直的
argue 争论
classical 古典的
hammer 锤子
share 分享;共有
sorrow 悲哀;悲痛
adventure 冒险
error 错误;差错
closet 壁橱;储藏室
pronounce 发音;宣告
repeat 重做;重复
majority 大多数;大半
native 本国的,本地的,本国
- hibernate查询返回DTO对象,DTO封装了多个pojo对象的属性
frankco
POJOhibernate查询DTO
DTO-数据传输对象;pojo-最纯粹的java对象与数据库中的表一一对应。
简单讲:DTO起到业务数据的传递作用,pojo则与持久层数据库打交道。
有时候我们需要查询返回DTO对象,因为DTO
- Partition List
hcx2013
partition
Given a linked list and a value x, partition it such that all nodes less than x come before nodes greater than or equal to x.
You should preserve the original relative order of th
- Spring MVC测试框架详解——客户端测试
jinnianshilongnian
上一篇《Spring MVC测试框架详解——服务端测试》已经介绍了服务端测试,接下来再看看如果测试Rest客户端,对于客户端测试以前经常使用的方法是启动一个内嵌的jetty/tomcat容器,然后发送真实的请求到相应的控制器;这种方式的缺点就是速度慢;自Spring 3.2开始提供了对RestTemplate的模拟服务器测试方式,也就是说使用RestTemplate测试时无须启动服务器,而是模拟一
- 关于推荐个人观点
liyonghui160com
推荐系统关于推荐个人观点
回想起来,我也做推荐了3年多了,最近公司做了调整招聘了很多算法工程师,以为需要多么高大上的算法才能搭建起来的,从实践中走过来,我只想说【不是这样的】
第一次接触推荐系统是在四年前入职的时候,那时候,机器学习和大数据都是没有的概念,什么大数据处理开源软件根本不存在,我们用多台计算机web程序记录用户行为,用.net的w
- 不间断旋转的动画
pangyulei
动画
CABasicAnimation* rotationAnimation;
rotationAnimation = [CABasicAnimation animationWithKeyPath:@"transform.rotation.z"];
rotationAnimation.toValue = [NSNumber numberWithFloat: M
- 自定义annotation
sha1064616837
javaenumannotationreflect
对象有的属性在页面上可编辑,有的属性在页面只可读,以前都是我们在页面上写死的,时间一久有时候会混乱,此处通过自定义annotation在类属性中定义。越来越发现Java的Annotation真心很强大,可以帮我们省去很多代码,让代码看上去简洁。
下面这个例子 主要用到了
1.自定义annotation:@interface,以及几个配合着自定义注解使用的几个注解
2.简单的反射
3.枚举
- Spring 源码
up2pu
spring
1.Spring源代码
https://github.com/SpringSource/spring-framework/branches/3.2.x
注:兼容svn检出
2.运行脚本
import-into-eclipse.bat
注:需要设置JAVA_HOME为jdk 1.7
build.gradle
compileJava {
sourceCompatibilit
- 利用word分词来计算文本相似度
yangshangchuan
wordword分词文本相似度余弦相似度简单共有词
word分词提供了多种文本相似度计算方式:
方式一:余弦相似度,通过计算两个向量的夹角余弦值来评估他们的相似度
实现类:org.apdplat.word.analysis.CosineTextSimilarity
用法如下:
String text1 = "我爱购物";
String text2 = "我爱读书";
String text3 =

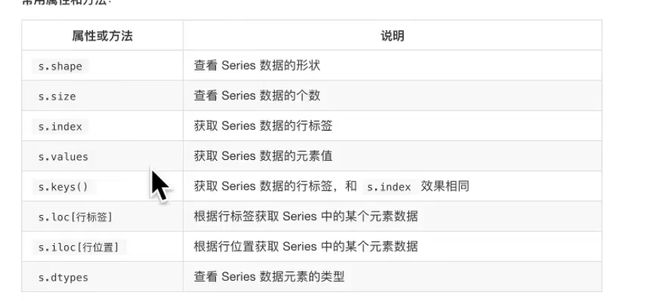
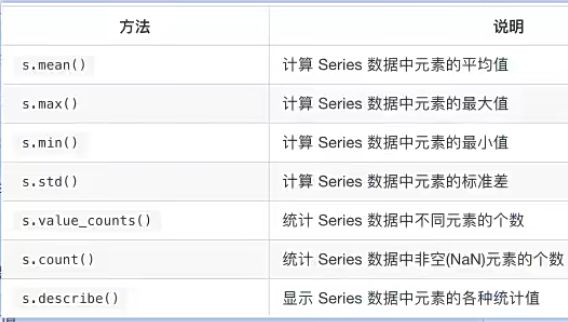
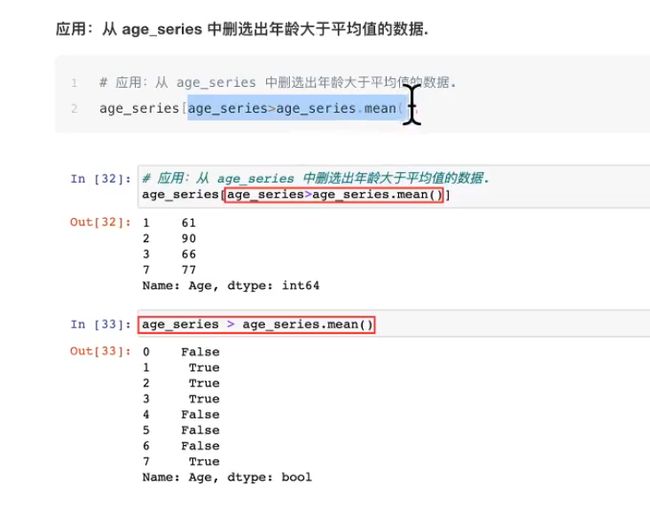
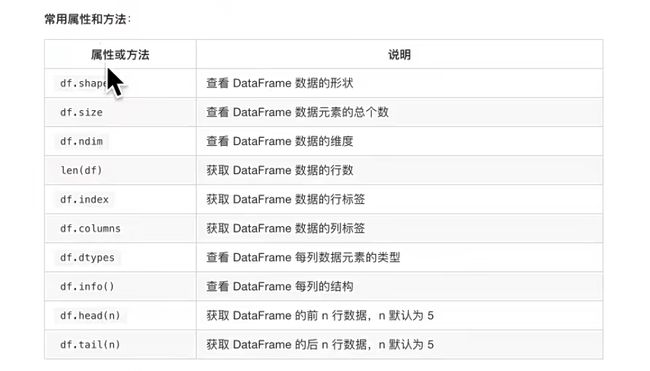



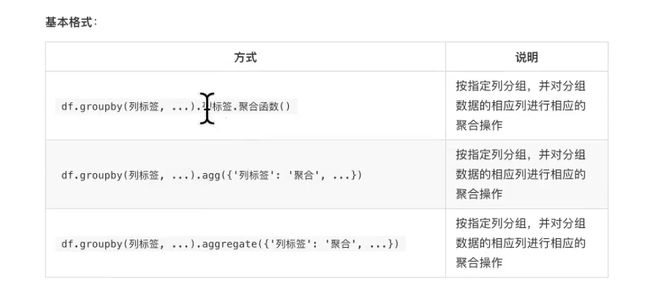
 ### 13.dataframe分组聚合
### 13.dataframe分组聚合
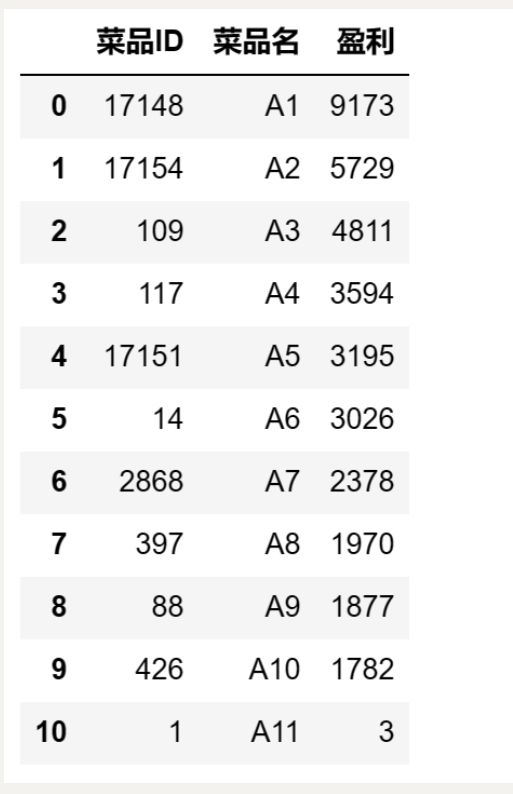
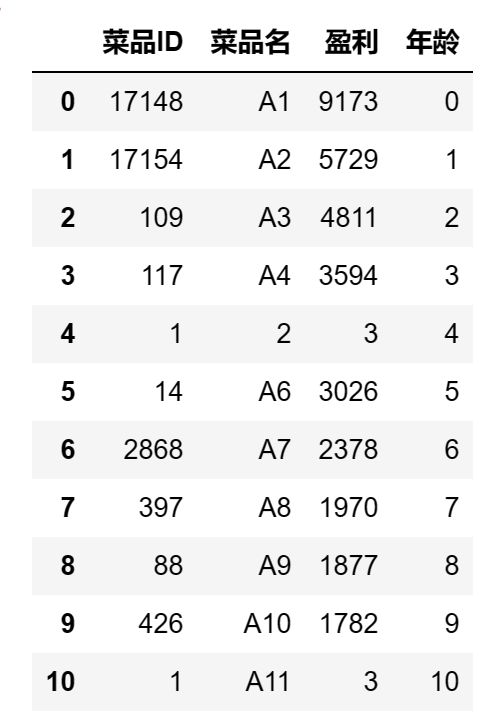
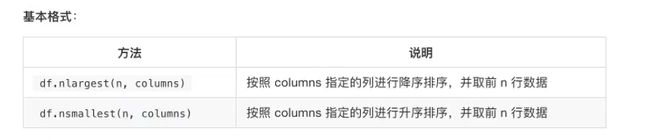
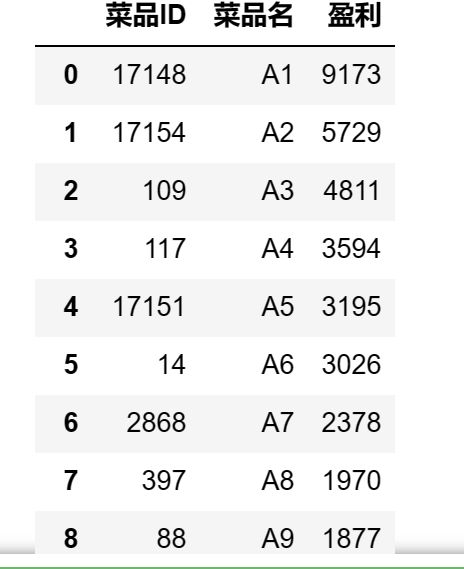
 ### 14.dataframe排序操作
### 14.dataframe排序操作