Python进阶篇
大家好,我是易安!今天我们继续Python的学习,内容稍微有些多,不过我会尽可能举一些例子让你理解。
对象比较与拷贝
在前面的学习中,我们其实已经接触到了很多 Python对象比较和复制的例子,比如下面这个,判断a和b是否相等的if语句:
if a == b:
...
再比如第二个例子,这里l2就是l1的拷贝。
l1 = [1, 2, 3]
l2 = list(l1)
但你可能并不清楚,这些语句的背后发生了什么。比如,
- l2是l1的浅拷贝(shallow copy)还是深度拷贝(deep copy)呢?
-
a == b是比较两个对象的值相等,还是两个对象完全相等呢?
关于这些问题,我希望通过本文的学习,让你有个全面的了解。
'==' 还是 'is'
等于(==)和is是Python中对象比较常用的两种方式。简单来说, '==' 操作符比较对象之间的值是否相等,比如下面的例子,表示比较变量a和b所指向的值是否相等。
a == b
而 'is' 操作符比较的是对象的身份标识是否相等,即它们是否是同一个对象,是否指向同一个内存地址。
在Python中,每个对象的身份标识,都能通过函数id(object)获得。因此, 'is' 操作符,相当于比较对象之间的ID是否相等,我们来看下面的例子:
a = 10
b = 10
a == b
True
id(a)
4427562448
id(b)
4427562448
a is b
True
这里,首先Python会为10这个值开辟一块内存,然后变量a和b同时指向这块内存区域,即a和b都是指向10这个变量,因此a和b的值相等,id也相等, a == b 和 a is b 都返回True。
不过,需要注意,对于整型数字来说,以上 a is b 为True的结论,只适用于-5到256范围内的数字。比如下面这个例子:
a = 257
b = 257
a == b
True
id(a)
4473417552
id(b)
4473417584
a is b
False
这里我们把257同时赋值给了a和b,可以看到 a == b 仍然返回True,因为a和b指向的值相等。但奇怪的是, a is b 返回了false,并且我们发现,a和b的ID不一样了,这是为什么呢?
事实上,出于对性能优化的考虑,Python内部会对-5到256的整型维持一个数组,起到一个缓存的作用。这样,每次你试图创建一个-5到256范围内的整型数字时,Python都会从这个数组中返回相对应的引用,而不是重新开辟一块新的内存空间。
但是,如果整型数字超过了这个范围,比如上述例子中的257,Python则会为两个257开辟两块内存区域,因此a和b的ID不一样, a is b 就会返回False了。
通常来说,在实际工作中,当我们比较变量时,使用 '==' 的次数会比 'is' 多得多,因为我们一般更关心两个变量的值,而不是它们内部的存储地址。但是,当我们比较一个变量与一个单例(singleton)时,通常会使用 'is'。一个典型的例子,就是检查一个变量是否为None:
if a is None:
...
if a is not None:
...
这里注意,比较操作符 'is' 的速度效率,通常要优于 '=='。因为 'is' 操作符不能被重载,这样,Python就不需要去寻找,程序中是否有其他地方重载了比较操作符,并去调用。执行比较操作符 'is',就仅仅是比较两个变量的ID而已。
但是 '==' 操作符却不同,执行 a == b 相当于是去执行 a.__eq__(b),而Python大部分的数据类型都会去重载 __eq__ 这个函数,其内部的处理通常会复杂一些。比如,对于列表, __eq__ 函数会去遍历列表中的元素,比较它们的顺序和值是否相等。
不过,对于不可变(immutable)的变量,如果我们之前用 '==' 或者 'is' 比较过,结果是不是就一直不变了呢?
答案自然是否定的。我们来看下面一个例子:
t1 = (1, 2, [3, 4])
t2 = (1, 2, [3, 4])
t1 == t2
True
t1[-1].append(5)
t1 == t2
False
我们知道元组是不可变的,但元组可以嵌套,它里面的元素可以是列表类型,列表是可变的,所以如果我们修改了元组中的某个可变元素,那么元组本身也就改变了,之前用 'is' 或者 '==' 操作符取得的结果,可能就不适用了。
这一点,你在日常写程序时一定要注意,在必要的地方请不要省略条件检查。
浅拷贝和深度拷贝
接下来,我们一起来看看Python中的浅拷贝(shallow copy)和深度拷贝(deep copy)。
对于这两个熟悉的操作,我并不想一上来先抛概念让你死记硬背来区分,我们不妨先从它们的操作方法说起,通过代码来理解两者的不同。
先来看浅拷贝。常见的浅拷贝的方法,是使用数据类型本身的构造器,比如下面两个例子:
l1 = [1, 2, 3]
l2 = list(l1)
l2
[1, 2, 3]
l1 == l2
True
l1 is l2
False
s1 = set([1, 2, 3])
s2 = set(s1)
s2
{1, 2, 3}
s1 == s2
True
s1 is s2
False
这里,l2就是l1的浅拷贝,s2是s1的浅拷贝。当然,对于可变的序列,我们还可以通过切片操作符 ':' 完成浅拷贝,比如下面这个列表的例子:
l1 = [1, 2, 3]
l2 = l1[:]
l1 == l2
True
l1 is l2
False
当然,Python中也提供了相对应的函数copy.copy(),适用于任何数据类型:
import copy
l1 = [1, 2, 3]
l2 = copy.copy(l1)
不过,需要注意的是,对于元组,使用tuple()或者切片操作符 ':' 不会创建一份浅拷贝,相反,它会返回一个指向相同元组的引用:
t1 = (1, 2, 3)
t2 = tuple(t1)
t1 == t2
True
t1 is t2
True
这里,元组(1, 2, 3)只被创建一次,t1和t2同时指向这个元组。
到这里,对于浅拷贝你应该很清楚了。浅拷贝,是指重新分配一块内存,创建一个新的对象,里面的元素是原对象中子对象的引用。因此,如果原对象中的元素不可变,那倒无所谓;但如果元素可变,浅拷贝通常会带来一些副作用,尤其需要注意。我们来看下面的例子:
l1 = [[1, 2], (30, 40)]
l2 = list(l1)
l1.append(100)
l1[0].append(3)
l1
[[1, 2, 3], (30, 40), 100]
l2
[[1, 2, 3], (30, 40)]
l1[1] += (50, 60)
l1
[[1, 2, 3], (30, 40, 50, 60), 100]
l2
[[1, 2, 3], (30, 40)]
这个例子中,我们首先初始化了一个列表l1,里面的元素是一个列表和一个元组;然后对l1执行浅拷贝,赋予l2。因为浅拷贝里的元素是对原对象元素的引用,因此l2中的元素和l1指向同一个列表和元组对象。
接着往下看。 l1.append(100),表示对l1的列表新增元素100。这个操作不会对l2产生任何影响,因为l2和l1作为整体是两个不同的对象,并不共享内存地址。操作过后l2不变,l1会发生改变:
[[1, 2, 3], (30, 40), 100]
再来看, l1[0].append(3),这里表示对l1中的第一个列表新增元素3。因为l2是l1的浅拷贝,l2中的第一个元素和l1中的第一个元素,共同指向同一个列表,因此l2中的第一个列表也会相对应的新增元素3。操作后l1和l2都会改变:
l1: [[1, 2, 3], (30, 40), 100]
l2: [[1, 2, 3], (30, 40)]
最后是 l1[1] += (50, 60),因为元组是不可变的,这里表示对l1中的第二个元组拼接,然后重新创建了一个新元组作为l1中的第二个元素,而l2中没有引用新元组,因此l2并不受影响。操作后l2不变,l1发生改变:
l1: [[1, 2, 3], (30, 40, 50, 60), 100]
通过这个例子,你可以很清楚地看到使用浅拷贝可能带来的副作用。因此,如果我们想避免这种副作用,完整地拷贝一个对象,你就得使用深度拷贝。
所谓深度拷贝,是指重新分配一块内存,创建一个新的对象,并且将原对象中的元素,以递归的方式,通过创建新的子对象拷贝到新对象中。因此,新对象和原对象没有任何关联。
Python中以copy.deepcopy()来实现对象的深度拷贝。比如上述例子写成下面的形式,就是深度拷贝:
import copy
l1 = [[1, 2], (30, 40)]
l2 = copy.deepcopy(l1)
l1.append(100)
l1[0].append(3)
l1
[[1, 2, 3], (30, 40), 100]
l2
[[1, 2], (30, 40)]
我们可以看到,无论l1如何变化,l2都不变。因为此时的l1和l2完全独立,没有任何联系。
不过,深度拷贝也不是完美的,往往也会带来一系列问题。如果被拷贝对象中存在指向自身的引用,那么程序很容易陷入无限循环:
import copy
x = [1]
x.append(x)
x
[1, [...]]
y = copy.deepcopy(x)
y
[1, [...]]
上面这个例子,列表x中有指向自身的引用,因此x是一个无限嵌套的列表。但是我们发现深度拷贝x到y后,程序并没有出现stack overflow的现象。这是为什么呢?
其实,这是因为深度拷贝函数deepcopy中会维护一个字典,记录已经拷贝的对象与其ID。拷贝过程中,如果字典里已经存储了将要拷贝的对象,则会从字典直接返回,我们来看相对应的源码就能明白:
def deepcopy(x, memo=None, _nil=[]):
"""Deep copy operation on arbitrary Python objects.
See the module's __doc__ string for more info.
"""
if memo is None:
memo = {}
d = id(x) # 查询被拷贝对象x的id
y = memo.get(d, _nil) # 查询字典里是否已经存储了该对象
if y is not _nil:
return y # 如果字典里已经存储了将要拷贝的对象,则直接返回
...
参数的传递
实际工作中,很多人会遇到这样的场景:写完了代码,一测试,发现结果和自己期望的不一样,于是开始一层层地debug。花了很多时间,可到最后才发现,是传参过程中数据结构的改变,导致了程序的“出错”。
比如,我将一个列表作为参数传入另一个函数,期望列表在函数运行结束后不变,但是往往“事与愿违”,由于某些操作,它的值改变了,那就很有可能带来后续程序一系列的错误。
因此,了解Python中参数的传递机制,具有十分重要的意义,这往往能让我们写代码时少犯错误,提高效率。
值传递和引用传递
如果你接触过其他的编程语言,比如java,很容易想到,常见的参数传递有2种: 值传递 和 引用传递。所谓值传递,通常就是拷贝参数的值,然后传递给函数里的新变量。这样,原变量和新变量之间互相独立,互不影响。
比如,我们来看下面的一段C++代码:
#include
using namespace std;
// 交换2个变量的值
void swap(int x, int y) {
int temp;
temp = x; // 交换x和y的值
x = y;
y = temp;
return;
}
int main () {
int a = 1;
int b = 2;
cout << "Before swap, value of a :" << a << endl;
cout << "Before swap, value of b :" << b << endl;
swap(a, b);
cout << "After swap, value of a :" << a << endl;
cout << "After swap, value of b :" << b << endl;
return 0;
}
Before swap, value of a :1
Before swap, value of b :2
After swap, value of a :1
After swap, value of b :2
这里的swap()函数,把a和b的值拷贝给了x和y,然后再交换x和y的值。这样一来,x和y的值发生了改变,但是a和b不受其影响,所以值不变。这种方式,就是我们所说的值传递。
所谓引用传递,通常是指把参数的引用传给新的变量,这样,原变量和新变量就会指向同一块内存地址。如果改变了其中任何一个变量的值,那么另外一个变量也会相应地随之改变。
还是拿我们刚刚讲到的C++代码为例,上述例子中的swap()函数,如果改成下面的形式,声明引用类型的参数变量:
void swap(int& x, int& y) {
int temp;
temp = x; // 交换x和y的值
x = y;
y = temp;
return;
}
那么输出的便是另一个结果:
Before swap, value of a :1
Before swap, value of b :2
After swap, value of a :2
After swap, value of b :1
原变量a和b的值被交换了,因为引用传递使得a和x,b和y一模一样,对x和y的任何改变必然导致了a和b的相应改变。
不过,这是C/C++语言中的特点。那么Python中,参数传递到底是如何进行的呢?它们到底属于值传递、引用传递,还是其他呢?
在回答这个问题之前,让我们先来了解一下,Python变量和赋值的基本原理。
Python变量及其赋值
我们首先来看,下面的Python代码示例:
a = 1
b = a
a = a + 1
这里首先将1赋值于a,即a指向了1这个对象,如下面的流程图所示:
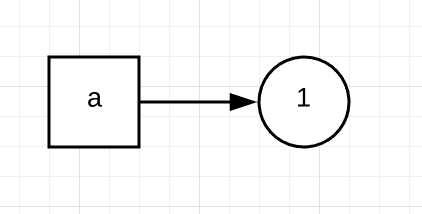
接着b = a则表示,让变量b也同时指向1这个对象。这里要注意,Python里的对象可以被多个变量所指向或引用。

最后执行a = a + 1。需要注意的是,Python的数据类型,例如整型(int)、字符串(string)等等,是不可变的。所以,a = a + 1,并不是让a的值增加1,而是表示重新创建了一个新的值为2的对象,并让a指向它。但是b仍然不变,仍然指向1这个对象。
因此,最后的结果是,a的值变成了2,而b的值不变仍然是1。

通过这个例子你可以看到,这里的a和b,开始只是两个指向同一个对象的变量而已,或者你也可以把它们想象成同一个对象的两个名字。简单的赋值b = a,并不表示重新创建了新对象,只是让同一个对象被多个变量指向或引用。
同时,指向同一个对象,也并不意味着两个变量就被绑定到了一起。如果你给其中一个变量重新赋值,并不会影响其他变量的值。
明白了这个基本的变量赋值例子,我们再来看一个列表的例子:
l1 = [1, 2, 3]
l2 = l1
l1.append(4)
l1
[1, 2, 3, 4]
l2
[1, 2, 3, 4]
同样的,我们首先让列表l1和l2同时指向了[1, 2, 3]这个对象。

由于列表是可变的,所以l1.append(4)不会创建新的列表,只是在原列表的末尾插入了元素4,变成[1, 2, 3, 4]。由于l1和l2同时指向这个列表,所以列表的变化会同时反映在l1和l2这两个变量上,那么,l1和l2的值就同时变为了[1, 2, 3, 4]。

另外,需要注意的是,Python里的变量可以被删除,但是对象无法被删除。比如下面的代码:
l = [1, 2, 3]
del l
del l 删除了l这个变量,从此以后你无法访问l,但是对象[1, 2, 3]仍然存在。Python程序运行时,其自带的垃圾回收系统会跟踪每个对象的引用。如果[1, 2, 3]除了l外,还在其他地方被引用,那就不会被回收,反之则会被回收。
由此可见,在Python中:
- 变量的赋值,只是表示让变量指向了某个对象,并不表示拷贝对象给变量;而一个对象,可以被多个变量所指向。
- 可变对象(列表,字典,集合等等)的改变,会影响所有指向该对象的变量。
- 对于不可变对象(字符串、整型、元组等等),所有指向该对象的变量的值总是一样的,也不会改变。但是通过某些操作(+=等等)更新不可变对象的值时,会返回一个新的对象。
- 变量可以被删除,但是对象无法被删除。
Python函数的参数传递
这里首先引用Python官方文档中的一段说明:
“Remember that arguments are passed by assignment in Python. Since assignment just creates references to objects, there’s no alias between an argument name in the caller and callee, and so no call-by-reference per Se.”
准确地说,Python的参数传递是 赋值传递 (pass by assignment),或者叫作对象的 引用传递(pass by object reference)。Python里所有的数据类型都是对象,所以参数传递时,只是让新变量与原变量指向相同的对象而已,并不存在值传递或是引用传递一说。
比如,我们来看下面这个例子:
def my_func1(b):
b = 2
a = 1
my_func1(a)
a
1
这里的参数传递,使变量a和b同时指向了1这个对象。但当我们执行到b = 2时,系统会重新创建一个值为2的新对象,并让b指向它;而a仍然指向1这个对象。所以,a的值不变,仍然为1。
那么对于上述例子的情况,是不是就没有办法改变a的值了呢?
答案当然是否定的,我们只需稍作改变,让函数返回新变量,赋给a。这样,a就指向了一个新的值为2的对象,a的值也因此变为2。
def my_func2(b):
b = 2
return b
a = 1
a = my_func2(a)
a
2
不过,当可变对象当作参数传入函数里的时候,改变可变对象的值,就会影响所有指向它的变量。比如下面的例子:
def my_func3(l2):
l2.append(4)
l1 = [1, 2, 3]
my_func3(l1)
l1
[1, 2, 3, 4]
这里l1和l2先是同时指向值为[1, 2, 3]的列表。不过,由于列表可变,执行append()函数,对其末尾加入新元素4时,变量l1和l2的值也都随之改变了。
但是,下面这个例子,看似都是给列表增加了一个新元素,却得到了明显不同的结果。
def my_func4(l2):
l2 = l2 + [4]
l1 = [1, 2, 3]
my_func4(l1)
l1
[1, 2, 3]
为什么l1仍然是[1, 2, 3],而不是[1, 2, 3, 4]呢?
要注意,这里l2 = l2 + [4],表示创建了一个“末尾加入元素4“的新列表,并让l2指向这个新的对象。这个过程与l1无关,因此l1的值不变。当然,同样的,如果要改变l1的值,我们就得让上述函数返回一个新列表,再赋予l1即可:
def my_func5(l2):
l2 = l2 + [4]
return l2
l1 = [1, 2, 3]
l1 = my_func5(l1)
l1
[1, 2, 3, 4]
这里你尤其要记住的是,改变变量和重新赋值的区别:
- my_func3()中单纯地改变了对象的值,因此函数返回后,所有指向该对象的变量都会被改变;
- 但my_func4()中则创建了新的对象,并赋值给一个本地变量,因此原变量仍然不变。
至于my_func3()和my_func5()的用法,两者虽然写法不同,但实现的功能一致。不过,在实际工作应用中,我们往往倾向于类似my_func5()的写法,添加返回语句。这样更简洁明了,不易出错。
装饰器
装饰器一直以来都是Python中很有用、很经典的一个feature,在工程中的应用也十分广泛,比如日志、缓存等等的任务都会用到。然而,在平常工作生活中,我发现不少人,尤其是初学者,常常因为其相对复杂的表示,对装饰器望而生畏,认为它“too fancy to learn”,实际并不如此。
函数&装饰器
函数核心回顾
引入装饰器之前,我们首先一起来复习一下,必须掌握的函数的几个核心概念。
第一点,我们要知道,在Python中,函数是一等公民(first-class citizen),函数也是对象。我们可以把函数赋予变量,比如下面这段代码:
def func(message):
print('Got a message: {}'.format(message))
send_message = func
send_message('hello world')
# 输出
Got a message: hello world
这个例子中,我们把函数func赋予了变量send_message,这样之后你调用send_message,就相当于是调用函数func()。
第二点,我们可以把函数当作参数,传入另一个函数中,比如下面这段代码:
def get_message(message):
return 'Got a message: ' + message
def root_call(func, message):
print(func(message))
root_call(get_message, 'hello world')
# 输出
Got a message: hello world
这个例子中,我们就把函数get_message以参数的形式,传入了函数root_call()中然后调用它。
第三点,我们可以在函数里定义函数,也就是函数的嵌套。这里我同样举了一个例子:
def func(message):
def get_message(message):
print('Got a message: {}'.format(message))
return get_message(message)
func('hello world')
# 输出
Got a message: hello world
这段代码中,我们在函数func()里又定义了新的函数get_message(),调用后作为func()的返回值返回。
第四点,要知道,函数的返回值也可以是函数对象(闭包),比如下面这个例子:
def func_closure():
def get_message(message):
print('Got a message: {}'.format(message))
return get_message
send_message = func_closure()
send_message('hello world')
# 输出
Got a message: hello world
这里,函数func_closure()的返回值是函数对象get_message本身,之后,我们将其赋予变量send_message,再调用send_message(‘hello world’),最后输出了 'Got a message: hello world'。
简单的装饰器
一个装饰器的简单例子:
def my_decorator(func):
def wrapper():
print('wrapper of decorator')
func()
return wrapper
def greet():
print('hello world')
greet = my_decorator(greet)
greet()
# 输出
wrapper of decorator
hello world
这段代码中,变量greet指向了内部函数wrapper(),而内部函数wrapper()中又会调用原函数greet(),因此,最后调用greet()时,就会先打印 'wrapper of decorator',然后输出 'hello world'。
这里的函数my_decorator()就是一个装饰器,它把真正需要执行的函数greet()包裹在其中,并且改变了它的行为,但是原函数greet()不变。
事实上,上述代码在Python中有更简单、更优雅的表示:
def my_decorator(func):
def wrapper():
print('wrapper of decorator')
func()
return wrapper
@my_decorator
def greet():
print('hello world')
greet()
这里的 @,我们称之为语法糖, @my_decorator 就相当于前面的 greet=my_decorator(greet) 语句,只不过更加简洁。因此,如果你的程序中有其它函数需要做类似的装饰,你只需在它们的上方加上 @decorator 就可以了,这样就大大提高了函数的重复利用和程序的可读性。
带有参数的装饰器
你或许会想到,如果原函数greet()中,有参数需要传递给装饰器怎么办?
一个简单的办法,是可以在对应的装饰器函数wrapper()上,加上相应的参数,比如:
def my_decorator(func):
def wrapper(message):
print('wrapper of decorator')
func(message)
return wrapper
@my_decorator
def greet(message):
print(message)
greet('hello world')
# 输出
wrapper of decorator
hello world
不过,新的问题来了。如果我另外还有一个函数,也需要使用my_decorator()装饰器,但是这个新的函数有两个参数,又该怎么办呢?比如:
@my_decorator
def celebrate(name, message):
...
事实上,通常情况下,我们会把 *args 和 **kwargs,作为装饰器内部函数wrapper()的参数。 *args 和 **kwargs,表示接受任意数量和类型的参数,因此装饰器就可以写成下面的形式:
def my_decorator(func):
def wrapper(*args, **kwargs):
print('wrapper of decorator')
func(*args, **kwargs)
return wrapper
带有自定义参数的装饰器
其实,装饰器还有更大程度的灵活性。刚刚说了,装饰器可以接受原函数任意类型和数量的参数,除此之外,它还可以接受自己定义的参数。
举个例子,比如我想要定义一个参数,来表示装饰器内部函数被执行的次数,那么就可以写成下面这种形式:
def repeat(num):
def my_decorator(func):
def wrapper(*args, **kwargs):
for i in range(num):
print('wrapper of decorator')
func(*args, **kwargs)
return wrapper
return my_decorator
@repeat(4)
def greet(message):
print(message)
greet('hello world')
# 输出:
wrapper of decorator
hello world
wrapper of decorator
hello world
wrapper of decorator
hello world
wrapper of decorator
hello world
原函数还是原函数吗?
现在,我们再来看个有趣的现象。还是之前的例子,我们试着打印出greet()函数的一些元信息:
greet.__name__
## 输出
'wrapper'
help(greet)
# 输出
Help on function wrapper in module __main__:
wrapper(*args, **kwargs)
你会发现,greet()函数被装饰以后,它的元信息变了。元信息告诉我们“它不再是以前的那个greet()函数,而是被wrapper()函数取代了”。
为了解决这个问题,我们通常使用内置的装饰器 @functools.wrap,它会帮助保留原函数的元信息(也就是将原函数的元信息,拷贝到对应的装饰器函数里)。
import functools
def my_decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print('wrapper of decorator')
func(*args, **kwargs)
return wrapper
@my_decorator
def greet(message):
print(message)
greet.__name__
# 输出
'greet'
类装饰器
前面我们主要讲了函数作为装饰器的用法,实际上,类也可以作为装饰器。类装饰器主要依赖于函数 __call__(),每当你调用一个类的示例时,函数 __call__() 就会被执行一次。
我们来看下面这段代码:
class Count:
def __init__(self, func):
self.func = func
self.num_calls = 0
def __call__(self, *args, **kwargs):
self.num_calls += 1
print('num of calls is: {}'.format(self.num_calls))
return self.func(*args, **kwargs)
@Count
def example():
print("hello world")
example()
# 输出
num of calls is: 1
hello world
example()
# 输出
num of calls is: 2
hello world
...
这里,我们定义了类Count,初始化时传入原函数func(),而 __call__() 函数表示让变量num_calls自增1,然后打印,并且调用原函数。因此,在我们第一次调用函数example()时,num_calls的值是1,而在第二次调用时,它的值变成了2。
装饰器的嵌套
回顾刚刚讲的例子,基本都是一个装饰器的情况,但实际上,Python也支持多个装饰器,比如写成下面这样的形式:
@decorator1
@decorator2
@decorator3
def func():
...
它的执行顺序从里到外,所以上面的语句也等效于下面这行代码:
decorator1(decorator2(decorator3(func)))
这样, 'hello world' 这个例子,就可以改写成下面这样:
import functools
def my_decorator1(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print('execute decorator1')
func(*args, **kwargs)
return wrapper
def my_decorator2(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print('execute decorator2')
func(*args, **kwargs)
return wrapper
@my_decorator1
@my_decorator2
def greet(message):
print(message)
greet('hello world')
# 输出
execute decorator1
execute decorator2
hello world
装饰器用法实例
到此,装饰器的基本概念及用法我就讲完了,接下来,我将结合实际工作中的几个例子,带你加深对它的理解。
身份认证
首先是最常见的身份认证的应用。这个很容易理解,举个最常见的例子,你登录微信,需要输入用户名密码,然后点击确认,这样,服务器端便会查询你的用户名是否存在、是否和密码匹配等等。如果认证通过,你就可以顺利登录;如果不通过,就抛出异常并提示你登录失败。
再比如一些网站,你不登录也可以浏览内容,但如果你想要发布文章或留言,在点击发布时,服务器端便会查询你是否登录。如果没有登录,就不允许这项操作等等。
我们来看一个大概的代码示例:
import functools
def authenticate(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
request = args[0]
if check_user_logged_in(request): # 如果用户处于登录状态
return func(*args, **kwargs) # 执行函数post_comment()
else:
raise Exception('Authentication failed')
return wrapper
@authenticate
def post_comment(request, ...)
...
这段代码中,我们定义了装饰器authenticate;而函数post_comment(),则表示发表用户对某篇文章的评论。每次调用这个函数前,都会先检查用户是否处于登录状态,如果是登录状态,则允许这项操作;如果没有登录,则不允许。
日志记录
日志记录同样是很常见的一个案例。在实际工作中,如果你怀疑某些函数的耗时过长,导致整个系统的latency(延迟)增加,所以想在线上测试某些函数的执行时间,那么,装饰器就是一种很常用的手段。
我们通常用下面的方法来表示:
import time
import functools
def log_execution_time(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.perf_counter()
res = func(*args, **kwargs)
end = time.perf_counter()
print('{} took {} ms'.format(func.__name__, (end - start) * 1000))
return res
return wrapper
@log_execution_time
def calculate_similarity(items):
...
这里,装饰器log_execution_time记录某个函数的运行时间,并返回其执行结果。如果你想计算任何函数的执行时间,在这个函数上方加上 @log_execution_time 即可。
输入合理性检查
在大型公司的机器学习框架中,我们调用机器集群进行模型训练前,往往会用装饰器对其输入(往往是很长的JSON文件)进行合理性检查。这样就可以大大避免,输入不正确对机器造成的巨大开销。
它的写法往往是下面的格式:
import functools
def validation_check(input):
@functools.wraps(func)
def wrapper(*args, **kwargs):
... # 检查输入是否合法
@validation_check
def neural_network_training(param1, param2, ...):
...
其实在工作中,很多情况下都会出现输入不合理的现象。因为我们调用的训练模型往往很复杂,输入的文件有成千上万行,很多时候确实也很难发现。
试想一下,如果没有输入的合理性检查,很容易出现“模型训练了好几个小时后,系统却报错说输入的一个参数不对,成果付之一炬”的现象。这样的“惨案”,大大减缓了开发效率,也对机器资源造成了巨大浪费。
缓存
我们来看缓存方面的应用。关于缓存装饰器的用法,其实十分常见,这里我以Python内置的LRU cache为例来说明(如果你不了解 LRU cache,可以点击链接自行查阅)。
LRU cache,在Python中的表示形式是 @lru_cache。 @lru_cache 会缓存进程中的函数参数和结果,当缓存满了以后,会删除least recenly used 的数据。
正确使用缓存装饰器,往往能极大地提高程序运行效率。为什么呢?我举一个常见的例子来说明。
大型公司服务器端的代码中往往存在很多关于设备的检查,比如你使用的设备是安卓还是iPhone,版本号是多少。这其中的一个原因,就是一些新的feature,往往只在某些特定的手机系统或版本上才有(比如Android v200+)。
这样一来,我们通常使用缓存装饰器,来包裹这些检查函数,避免其被反复调用,进而提高程序运行效率,比如写成下面这样:
@lru_cache
def check(param1, param2, ...) # 检查用户设备类型,版本号等等
...
迭代器和生成器
在第一次接触 Python 的时候,你可能写过类似 for i in [2, 3, 5, 7, 11, 13]: print(i) 这样的语句。for in 语句理解起来很直观形象,比起 C++ 和 java 早期的 for (int i = 0; i < n; i ++) printf("%d\n", a[i]) 这样的语句,不知道简洁清晰到哪里去了。
但是,你想过 Python 在处理 for in 语句的时候,具体发生了什么吗?什么样的对象可以被 for in 来枚举呢?其实靠的就是我下面讲的容器,迭代器。
容器和迭代器
容器这个概念非常好理解。我们说过,在Python 中一切皆对象,对象的抽象就是类,而对象的集合就是容器。
列表(list: [0, 1, 2]),元组(tuple: (0, 1, 2)),字典(dict: {0:0, 1:1, 2:2}),集合(set: set([0, 1, 2]))都是容器。对于容器,你可以很直观地想象成多个元素在一起的单元;而不同容器的区别,正是在于内部数据结构的实现方法。然后,你就可以针对不同场景,选择不同时间和空间复杂度的容器。
所有的容器都是可迭代的(iterable)。这里的迭代,和枚举不完全一样。迭代可以想象成是你去买苹果,卖家并不告诉你他有多少库存。这样,每次你都需要告诉卖家,你要一个苹果,然后卖家采取行为:要么给你拿一个苹果;要么告诉你,苹果已经卖完了。你并不需要知道,卖家在仓库是怎么摆放苹果的。
严谨地说,迭代器(iterator)提供了一个 next 的方法。调用这个方法后,你要么得到这个容器的下一个对象,要么得到一个 StopIteration 的错误(苹果卖完了)。你不需要像列表一样指定元素的索引,因为字典和集合这样的容器并没有索引一说。比如,字典采用哈希表实现,那么你就只需要知道,next 函数可以不重复不遗漏地一个一个拿到所有元素即可。
而可迭代对象,通过 iter() 函数返回一个迭代器,再通过 next() 函数就可以实现遍历。for in 语句将这个过程隐式化,所以,你只需要知道它大概做了什么就行了。
我们来看下面这段代码,主要向你展示怎么判断一个对象是否可迭代。当然,这还有另一种做法,是 isinstance(obj, Iterable)。
def is_iterable(param):
try:
iter(param)
return True
except TypeError:
return False
params = [
1234,
'1234',
[1, 2, 3, 4],
set([1, 2, 3, 4]),
{1:1, 2:2, 3:3, 4:4},
(1, 2, 3, 4)
]
for param in params:
print('{} is iterable? {}'.format(param, is_iterable(param)))
########## 输出 ##########
1234 is iterable? False
1234 is iterable? True
[1, 2, 3, 4] is iterable? True
{1, 2, 3, 4} is iterable? True
{1: 1, 2: 2, 3: 3, 4: 4} is iterable? True
(1, 2, 3, 4) is iterable? True
通过这段代码,你就可以知道,给出的类型中,除了数字 1234 之外,其它的数据类型都是可迭代的。
什么是生成器?
生成器是懒人版本的迭代器。
我们知道,在迭代器中,如果我们想要枚举它的元素,这些元素需要事先生成。这里,我们先来看下面这个简单的样例。
import os
import psutil
# 显示当前 python 程序占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. / 1024
print('{} memory used: {} MB'.format(hint, memory))
def test_iterator():
show_memory_info('initing iterator')
list_1 = [i for i in range(100000000)]
show_memory_info('after iterator initiated')
print(sum(list_1))
show_memory_info('after sum called')
def test_generator():
show_memory_info('initing generator')
list_2 = (i for i in range(100000000))
show_memory_info('after generator initiated')
print(sum(list_2))
show_memory_info('after sum called')
%time test_iterator()
%time test_generator()
########## 输出 ##########
initing iterator memory used: 48.9765625 MB
after iterator initiated memory used: 3920.30078125 MB
4999999950000000
after sum called memory used: 3920.3046875 MB
Wall time: 17 s
initing generator memory used: 50.359375 MB
after generator initiated memory used: 50.359375 MB
4999999950000000
after sum called memory used: 50.109375 MB
Wall time: 12.5 s
声明一个迭代器很简单, [i for i in range(100000000)] 就可以生成一个包含一亿元素的列表。每个元素在生成后都会保存到内存中,你通过代码可以看到,它们占用了巨量的内存,内存不够的话就会出现 OOM 错误。
不过,我们并不需要在内存中同时保存这么多东西,比如对元素求和,我们只需要知道每个元素在相加的那一刻是多少就行了,用完就可以扔掉了。
于是,生成器的概念应运而生,在你调用 next() 函数的时候,才会生成下一个变量。生成器在 Python 的写法是用小括号括起来, (i for i in range(100000000)),即初始化了一个生成器。
这样一来,你可以清晰地看到,生成器并不会像迭代器一样占用大量内存,只有在被使用的时候才会调用。而且生成器在初始化的时候,并不需要运行一次生成操作,相比于 test_iterator() ,test_generator() 函数节省了一次生成一亿个元素的过程,因此耗时明显比迭代器短。
生成器的其他用法
数学中有一个恒等式, (1 + 2 + 3 + ... + n)^2 = 1^3 + 2^3 + 3^3 + ... + n^3,想必你高中就应该学过它。现在,我们来验证一下这个公式的正确性。老规矩,先放代码,你先自己阅读一下,看不懂的也不要紧,接下来我再来详细讲解。
def generator(k):
i = 1
while True:
yield i ** k
i += 1
gen_1 = generator(1)
gen_3 = generator(3)
print(gen_1)
print(gen_3)
def get_sum(n):
sum_1, sum_3 = 0, 0
for i in range(n):
next_1 = next(gen_1)
next_3 = next(gen_3)
print('next_1 = {}, next_3 = {}'.format(next_1, next_3))
sum_1 += next_1
sum_3 += next_3
print(sum_1 * sum_1, sum_3)
get_sum(8)
########## 输出 ##########
next_1 = 1, next_3 = 1
next_1 = 2, next_3 = 8
next_1 = 3, next_3 = 27
next_1 = 4, next_3 = 64
next_1 = 5, next_3 = 125
next_1 = 6, next_3 = 216
next_1 = 7, next_3 = 343
next_1 = 8, next_3 = 512
1296 1296
这段代码中,你首先注意一下 generator() 这个函数,它返回了一个生成器。
接下来的yield 是魔术的关键。对于初学者来说,你可以理解为,函数运行到这一行的时候,程序会从这里暂停,然后跳出,不过跳到哪里呢?答案是 next() 函数。那么 i ** k 是干什么的呢?它其实成了 next() 函数的返回值。
这样,每次 next(gen) 函数被调用的时候,暂停的程序就又复活了,从 yield 这里向下继续执行;同时注意,局部变量 i 并没有被清除掉,而是会继续累加。我们可以看到 next_1 从 1 变到 8,next_3 从 1 变到 512。
聪明的你应该注意到了,这个生成器居然可以一直进行下去!没错,事实上,迭代器是一个有限集合,生成器则可以成为一个无限集。我只管调用 next(),生成器根据运算会自动生成新的元素,然后返回给你,非常便捷。
我们再来看一个问题:给定一个 list 和一个指定数字,求这个数字在 list 中的位置。
下面这段代码你应该不陌生,也就是常规做法,枚举每个元素和它的 index,判断后加入 result,最后返回。
def index_normal(L, target):
result = []
for i, num in enumerate(L):
if num == target:
result.append(i)
return result
print(index_normal([1, 6, 2, 4, 5, 2, 8, 6, 3, 2], 2))
########## 输出 ##########
[2, 5, 9]
那么使用迭代器可以怎么做呢?二话不说,先看代码。
def index_generator(L, target):
for i, num in enumerate(L):
if num == target:
yield i
print(list(index_generator([1, 6, 2, 4, 5, 2, 8, 6, 3, 2], 2)))
########## 输出 ##########
[2, 5, 9]
你应该看到了明显的区别,我就不做过多解释了。唯一需要强调的是, index_generator 会返回一个 Generator 对象,需要使用 list 转换为列表后,才能用 print 输出。
这里我再多说两句。在Python 语言规范中,用更少、更清晰的代码实现相同功能,一直是被推崇的做法,因为这样能够很有效提高代码的可读性,减少出错概率,也方便别人快速准确理解你的意图。当然,要注意,这里“更少”的前提是清晰,而不是使用更多的魔术操作,虽说减少了代码却反而增加了阅读的难度。
回归正题。接下来我们再来看一个问题:给定两个序列,判定第一个是不是第二个的子序列。(LeetCode 链接如下: https://leetcode.com/problems/is-subsequence/ )
先来解读一下这个问题本身。序列就是列表,子序列则指的是,一个列表的元素在第二个列表中都按顺序出现,但是并不必挨在一起。举个例子,[1, 3, 5] 是 [1, 2, 3, 4, 5] 的子序列,[1, 4, 3] 则不是。
要解决这个问题,常规算法是贪心算法。我们维护两个指针指向两个列表的最开始,然后对第二个序列一路扫过去,如果某个数字和第一个指针指的一样,那么就把第一个指针前进一步。第一个指针移出第一个序列最后一个元素的时候,返回 True,否则返回 False。
不过,这个算法正常写的话,写下来怎么也得十行左右。
那么如果我们用迭代器和生成器呢?
def is_subsequence(a, b):
b = iter(b)
return all(i in b for i in a)
print(is_subsequence([1, 3, 5], [1, 2, 3, 4, 5]))
print(is_subsequence([1, 4, 3], [1, 2, 3, 4, 5]))
########## 输出 ##########
True
False
这简短的几行代码,你是不是看得一头雾水,不知道发生了什么?
来,我们先把这段代码复杂化,然后一步步看。
def is_subsequence(a, b):
b = iter(b)
print(b)
gen = (i for i in a)
print(gen)
for i in gen:
print(i)
gen = ((i in b) for i in a)
print(gen)
for i in gen:
print(i)
return all(((i in b) for i in a))
print(is_subsequence([1, 3, 5], [1, 2, 3, 4, 5]))
print(is_subsequence([1, 4, 3], [1, 2, 3, 4, 5]))
########## 输出 ##########
. at 0x000001E70651C570>
1
3
5
. at 0x000001E70651C5E8>
True
True
True
False
. at 0x000001E70651C5E8>
1
4
3
. at 0x000001E70651C570>
True
True
False
False
首先,第二行的 b = iter(b),把列表 b 转化成了一个迭代器,这里我先不解释为什么要这么做。
接下来的 gen = (i for i in a) 语句很好理解,产生一个生成器,这个生成器可以遍历对象 a,因此能够输出 1, 3, 5。而 (i in b) 需要好好揣摩,这里你是不是能联想到 for in 语句?
没错,这里的 (i in b),大致等价于下面这段代码:
while True:
val = next(b)
if val == i:
yield True
这里非常巧妙地利用生成器的特性,next() 函数运行的时候,保存了当前的指针。比如再看下面这个示例:
b = (i for i in range(5))
print(2 in b)
print(4 in b)
print(3 in b)
########## 输出 ##########
True
True
False
至于最后的 all() 函数,就很简单了。它用来判断一个迭代器的元素是否全部为 True,如果是则返回 True,否则就返回 False。
metaclass
市面上的很多中文书,都把metaclass译为“元类”。我一直认为这个翻译很糟糕,所以也不想在这里称metaclass为元类。因为如果仅从字面理解,“元”是“本源”“基本”的意思,“元类”会让人以为是“基本类”。难道Python的metaclass,指的是Python 2的Object吗?这就让人一头雾水了。
事实上,meta-class的meta这个词根,起源于希腊语词汇meta,包含下面两种意思:
- “Beyond”,例如技术词汇metadata,意思是描述数据的超越数据;
- “Change”,例如技术词汇metamorphosis,意思是改变的形态。
metaclass,一如其名,实际上同时包含了“超越类”和“变形类”的含义,完全不是“基本类”的意思。所以,要深入理解metaclass,我们就要围绕它的 超越变形 特性。接下来,我将为你展开metaclass的超越变形能力,讲清楚metaclass究竟有什么用?怎么应用?Python语言设计层面是如何实现metaclass的 ?以及使用metaclass的风险。
metaclass的超越变形特性有什么用?
YAML 是一个家喻户晓的Python工具,可以方便地序列化/逆序列化结构数据。YAMLObject的一个 超越变形能力,就是它的任意子类支持序列化和反序列化(serialization & deserialization)。比如说下面这段代码:
class Monster(yaml.YAMLObject):
yaml_tag = u'!Monster'
def __init__(self, name, hp, ac, attacks):
self.name = name
self.hp = hp
self.ac = ac
self.attacks = attacks
def __repr__(self):
return "%s(name=%r, hp=%r, ac=%r, attacks=%r)" % (
self.__class__.__name__, self.name, self.hp, self.ac,
self.attacks)
yaml.load("""
--- !Monster
name: Cave spider
hp: [2,6] # 2d6
ac: 16
attacks: [BITE, HURT]
""")
Monster(name='Cave spider', hp=[2, 6], ac=16, attacks=['BITE', 'HURT'])
print yaml.dump(Monster(
name='Cave lizard', hp=[3,6], ac=16, attacks=['BITE','HURT']))
# 输出
!Monster
ac: 16
attacks: [BITE, HURT]
hp: [3, 6]
name: Cave lizard
这里YAMLObject的特异功能体现在哪里呢?
你看,调用统一的yaml.load(),就能把任意一个yaml序列载入成一个Python Object;而调用统一的yaml.dump(),就能把一个YAMLObject子类序列化。对于load()和dump()的使用者来说,他们完全不需要提前知道任何类型信息,这让超动态配置编程成了可能。在我的实战经验中,许多大型项目都需要应用这种超动态配置的理念。
比方说,在一个智能语音助手的大型项目中,我们有1万个语音对话场景,每一个场景都是不同团队开发的。作为智能语音助手的核心团队成员,我不可能去了解每个子场景的实现细节。
在动态配置实验不同场景时,经常是今天我要实验场景A和B的配置,明天实验B和C的配置,光配置文件就有几万行量级,工作量真是不小。而应用这样的动态配置理念,我就可以让引擎根据我的文本配置文件,动态加载所需要的Python类。
对于YAML的使用者,这一点也很方便,你只要简单地继承yaml.YAMLObject,就能让你的Python Object具有序列化和逆序列化能力。是不是相比普通Python类,有一点“变态”,有一点“超越”?
metaclass的超越变形特性怎么用?
因为篇幅原因,我们这里只看YAMLObject的load()功能。简单来说,我们需要一个全局的注册器,让YAML知道,序列化文本中的 !Monster 需要载入成 Monster这个Python类型。
一个很自然的想法就是,那我们建立一个全局变量叫 registry,把所有需要逆序列化的YAMLObject,都注册进去。比如下面这样:
registry = {}
def add_constructor(target_class):
registry[target_class.yaml_tag] = target_class
然后,在Monster 类定义后面加上下面这行代码:
add_constructor(Monster)
但这样的缺点也很明显,对于YAML的使用者来说,每一个YAML的可逆序列化的类Foo定义后,都需要加上一句话, add_constructor(Foo)。这无疑给开发者增加了麻烦,也更容易出错,毕竟开发者很容易忘了这一点。
那么,更优的实现方式是什么样呢?如果你看过YAML的源码,就会发现,正是metaclass解决了这个问题。
# Python 2/3 相同部分
class YAMLObjectMetaclass(type):
def __init__(cls, name, bases, kwds):
super(YAMLObjectMetaclass, cls).__init__(name, bases, kwds)
if 'yaml_tag' in kwds and kwds['yaml_tag'] is not None:
cls.yaml_loader.add_constructor(cls.yaml_tag, cls.from_yaml)
# 省略其余定义
# Python 3
class YAMLObject(metaclass=YAMLObjectMetaclass):
yaml_loader = Loader
# 省略其余定义
# Python 2
class YAMLObject(object):
__metaclass__ = YAMLObjectMetaclass
yaml_loader = Loader
# 省略其余定义
你可以发现,YAMLObject把metaclass都声明成了YAMLObjectMetaclass,尽管声明方式在Python 2 和3中略有不同。在YAMLObjectMetaclass中, 下面这行代码就是魔法发生的地方:
cls.yaml_loader.add_constructor(cls.yaml_tag, cls.from_yaml)
YAML应用metaclass,拦截了所有YAMLObject子类的定义。也就说说,在你定义任何YAMLObject子类时,Python会强行插入运行下面这段代码,把我们之前想要的 add_constructor(Foo) 给自动加上。
cls.yaml_loader.add_constructor(cls.yaml_tag, cls.from_yaml)
所以YAML的使用者,无需自己去手写 add_constructor(Foo) 。怎么样,是不是其实并不复杂?
看到这里,我们已经掌握了metaclass的使用方法,超越了世界上99.9%的Python开发者。更进一步,如果你能够深入理解,Python的语言设计层面是怎样实现metaclass的,你就是世间罕见的“Python大师”了。
Python底层语言设计层面是如何实现metaclass的?
刚才我们提到,metaclass能够拦截Python类的定义。它是怎么做到的?
要理解metaclass的底层原理,你需要深入理解Python类型模型。下面,我将分三点来说明。
第一,所有的Python的用户定义类,都是type这个类的实例。
可能会让你惊讶,事实上,类本身不过是一个名为 type 类的实例。在Python的类型世界里,type这个类就是造物的上帝。这可以在代码中验证:
# Python 3和Python 2类似
class MyClass:
pass
instance = MyClass()
type(instance)
# 输出
'__main__.C'>
type(MyClass)
# 输出
'type'>
你可以看到,instance是MyClass的实例,而MyClass不过是“上帝”type的实例。
第二,用户自定义类,只不过是type类的 __call__ 运算符重载。
当我们定义一个类的语句结束时,真正发生的情况,是Python调用type的 __call__ 运算符。简单来说,当你定义一个类时,写成下面这样时:
class MyClass:
data = 1
Python真正执行的是下面这段代码:
class = type(classname, superclasses, attributedict)
这里等号右边的 type(classname, superclasses, attributedict),就是type的 __call__ 运算符重载,它会进一步调用:
type.__new__(typeclass, classname, superclasses, attributedict)
type.__init__(class, classname, superclasses, attributedict)
当然,这一切都可以通过代码验证,比如下面这段代码示例:
class MyClass:
data = 1
instance = MyClass()
MyClass, instance
# 输出
(__main__.MyClass, <__main__.MyClass instance at 0x7fe4f0b00ab8>)
instance.data
# 输出
1
MyClass = type('MyClass', (), {'data': 1})
instance = MyClass()
MyClass, instance
# 输出
(__main__.MyClass, <__main__.MyClass at 0x7fe4f0aea5d0>)
instance.data
# 输出
1
由此可见,正常的MyClass定义,和你手工去调用type运算符的结果是完全一样的。
第三,metaclass是type的子类,通过替换type的 __call__ 运算符重载机制,“超越变形”正常的类。
其实,理解了以上几点,我们就会明白,正是Python的类创建机制,给了metaclass大展身手的机会。
一旦你把一个类型MyClass的metaclass设置成MyMeta,MyClass就不再由原生的type创建,而是会调用MyMeta的 __call__ 运算符重载。
class = type(classname, superclasses, attributedict)
# 变为了
class = MyMeta(classname, superclasses, attributedict)
所以,我们才能在上面YAML的例子中,利用YAMLObjectMetaclass的 __init__ 方法,为所有YAMLObject子类偷偷执行 add_constructor()。
使用metaclass的风险
前面的篇幅,我都是在讲metaclass的原理和优点。的确,只有深入理解metaclass的本质,你才能用好metaclass。
不过,凡事有利必有弊,尤其是metaclass这样“逆天”的存在。正如你所看到的那样,metaclass会"扭曲变形"正常的Python类型模型。所以,如果使用不慎,对于整个代码库造成的风险是不可估量的。
换句话说,metaclass仅仅是给小部分Python开发者,在开发框架层面的Python库时使用的。而在应用层,metaclass往往不是很好的选择。
上下文管理器与with语句
什么是上下文管理器?
在任何一门编程语言中,文件的输入输出、数据库的连接断开等,都是很常见的资源管理操作。但资源都是有限的,在写程序时,我们必须保证这些资源在使用过后得到释放,不然就容易造成资源泄露,轻者使得系统处理缓慢,重则会使系统崩溃。
光说这些概念,你可能体会不到这一点,我们可以看看下面的例子:
for x in range(10000000):
f = open('test.txt', 'w')
f.write('hello')
这里我们一共打开了10000000个文件,但是用完以后都没有关闭它们,如果你运行该段代码,便会报错:
OSError: [Errno 23] Too many open files in system: 'test.txt'
这就是一个典型的资源泄露的例子。因为程序中同时打开了太多的文件,占据了太多的资源,造成系统崩溃。
为了解决这个问题,不同的编程语言都引入了不同的机制。而在Python中,对应的解决方式便是上下文管理器(context manager)。上下文管理器,能够帮助你自动分配并且释放资源,其中最典型的应用便是with语句。所以,上面代码的正确写法应该如下所示:
for x in range(10000000):
with open('test.txt', 'w') as f:
f.write('hello')
这样,我们每次打开文件 “test.txt”,并写入 ‘hello’ 之后,这个文件便会自动关闭,相应的资源也可以得到释放,防止资源泄露。当然,with语句的代码,也可以用下面的形式表示:
f = open('test.txt', 'w')
try:
f.write('hello')
finally:
f.close()
要注意的是,最后的finally block尤其重要,哪怕在写入文件时发生错误异常,它也可以保证该文件最终被关闭。不过与with语句相比,这样的代码就显得冗余了,并且还容易漏写,因此我们一般更倾向于使用with语句。
另外一个典型的例子,是Python中的threading.lock类。举个例子,比如我想要获取一个锁,执行相应的操作,完成后再释放,那么代码就可以写成下面这样:
some_lock = threading.Lock()
some_lock.acquire()
try:
...
finally:
some_lock.release()
而对应的with语句,同样非常简洁:
some_lock = threading.Lock()
with somelock:
...
我们可以从这两个例子中看到,with语句的使用,可以简化了代码,有效避免资源泄露的发生。
上下文管理器的实现
基于类的上下文管理器
了解了上下文管理的概念和优点后,下面我们就通过具体的例子,一起来看看上下文管理器的原理,搞清楚它的内部实现。这里,我自定义了一个上下文管理类FileManager,模拟Python的打开、关闭文件操作:
class FileManager:
def __init__(self, name, mode):
print('calling __init__ method')
self.name = name
self.mode = mode
self.file = None
def __enter__(self):
print('calling __enter__ method')
self.file = open(self.name, self.mode)
return self.file
def __exit__(self, exc_type, exc_val, exc_tb):
print('calling __exit__ method')
if self.file:
self.file.close()
with FileManager('test.txt', 'w') as f:
print('ready to write to file')
f.write('hello world')
## 输出
calling __init__ method
calling __enter__ method
ready to write to file
calling __exit__ method
需要注意的是,当我们用类来创建上下文管理器时,必须保证这个类包括方法 ”__enter__()” 和方法 “__exit__()”。其中,方法 “__enter__()” 返回需要被管理的资源,方法 “__exit__()” 里通常会存在一些释放、清理资源的操作,比如这个例子中的关闭文件等等。
而当我们用with语句,执行这个上下文管理器时:
with FileManager('test.txt', 'w') as f:
f.write('hello world')
下面这四步操作会依次发生:
- 方法
“__init__()”被调用,程序初始化对象FileManager,使得文件名(name)是"test.txt",文件模式(mode)是'w'; - 方法
“__enter__()”被调用,文件“test.txt”以写入的模式被打开,并且返回FileManager对象赋予变量f; - 字符串
“hello world”被写入文件“test.txt”; - 方法
“__exit__()”被调用,负责关闭之前打开的文件流。
因此,这个程序的输出是:
calling __init__ method
calling __enter__ method
ready to write to file
calling __exit__ meth
另外,值得一提的是,方法 “__exit__()” 中的参数 “exc_type, exc_val, exc_tb”,分别表示exception_type、exception_value和traceback。当我们执行含有上下文管理器的with语句时,如果有异常抛出,异常的信息就会包含在这三个变量中,传入方法 “__exit__()”。
因此,如果你需要处理可能发生的异常,可以在 “__exit__()” 添加相应的代码,比如下面这样来写:
class Foo:
def __init__(self):
print('__init__ called')
def __enter__(self):
print('__enter__ called')
return self
def __exit__(self, exc_type, exc_value, exc_tb):
print('__exit__ called')
if exc_type:
print(f'exc_type: {exc_type}')
print(f'exc_value: {exc_value}')
print(f'exc_traceback: {exc_tb}')
print('exception handled')
return True
with Foo() as obj:
raise Exception('exception raised').with_traceback(None)
# 输出
__init__ called
__enter__ called
__exit__ called
exc_type: 'Exception'>
exc_value: exception raised
exc_traceback:
exception handled
这里,我们在with语句中手动抛出了异常“exception raised”,你可以看到, “__exit__()” 方法中异常,被顺利捕捉并进行了处理。不过需要注意的是,如果方法 “__exit__()” 没有返回True,异常仍然会被抛出。因此,如果你确定异常已经被处理了,请在 “__exit__()” 的最后,加上 “return True” 这条语句。
同样的,数据库的连接操作,也常常用上下文管理器来表示,这里我给出了比较简化的代码:
class DBConnectionManager:
def __init__(self, hostname, port):
self.hostname = hostname
self.port = port
self.connection = None
def __enter__(self):
self.connection = DBClient(self.hostname, self.port)
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.connection.close()
with DBConnectionManager('localhost', '8080') as db_client:
与前面FileManager的例子类似:
- 方法
“__init__()”负责对数据库进行初始化,也就是将主机名、接口(这里是localhost和8080)分别赋予变量hostname和port; - 方法
“__enter__()”连接数据库,并且返回对象DBConnectionManager; - 方法
“__exit__()”则负责关闭数据库的连接。
这样一来,只要你写完了DBconnectionManager这个类,那么在程序每次连接数据库时,我们都只需要简单地调用with语句即可,并不需要关心数据库的关闭、异常等等,显然大大提高了开发的效率。
基于生成器的上下文管理器
基于类的上下文管理器,在Python中应用广泛,也是我们经常看到的形式,不过Python中的上下文管理器并不局限于此。除了基于类,它还可以基于生成器实现。接下来我们来看一个例子。
比如,你可以使用装饰器contextlib.contextmanager,来定义自己所需的基于生成器的上下文管理器,用以支持with语句。还是拿前面的类上下文管理器FileManager来说,我们也可以用下面形式来表示:
from contextlib import contextmanager
@contextmanager
def file_manager(name, mode):
try:
f = open(name, mode)
yield f
finally:
f.close()
with file_manager('test.txt', 'w') as f:
f.write('hello world')
这段代码中,函数file_manager()是一个生成器,当我们执行with语句时,便会打开文件,并返回文件对象f;当with语句执行完后,finally block中的关闭文件操作便会执行。
你可以看到,使用基于生成器的上下文管理器时,我们不再用定义 “__enter__()” 和 “__exit__()” 方法,但请务必加上装饰器@contextmanager,这一点新手很容易疏忽。
讲完这两种不同原理的上下文管理器后,还需要强调的是,基于类的上下文管理器和基于生成器的上下文管理器,这两者在功能上是一致的。只不过,
- 基于类的上下文管理器更加flexible,适用于大型的系统开发;
- 而基于生成器的上下文管理器更加方便、简洁,适用于中小型程序。
无论你使用哪一种,请不用忘记在方法 “__exit__()” 或者是finally block中释放资源,这一点尤其重要。
协程
什么是协程?
协程是实现并发编程的一种方式。一说并发,你肯定想到了多线程/多进程模型,没错,多线程/多进程,正是解决并发问题的经典模型之一。最初的互联网世界,多线程/多进程在服务器并发中,起到举足轻重的作用。
随着互联网的快速发展,你逐渐遇到了 C10K 瓶颈,也就是同时连接到服务器的客户达到了一万个。于是很多代码跑崩了,进程上下文切换占用了大量的资源,线程也顶不住如此巨大的压力,这时, NGINX 带着事件循环出来拯救世界了。
如果将多进程/多线程类比为起源于唐朝的藩镇割据,那么事件循环,就是宋朝加强的中央集权制。事件循环启动一个统一的调度器,让调度器来决定一个时刻去运行哪个任务,于是省却了多线程中启动线程、管理线程、同步锁等各种开销。同一时期的 NGINX,在高并发下能保持低资源低消耗高性能,相比 Apache 也支持更多的并发连接。
再到后来,出现了一个很有名的名词,叫做回调地狱(callback hell),手撸过 JavaScript 的朋友肯定知道我在说什么。我们大家惊喜地发现,这种工具完美地继承了事件循环的优越性,同时还能提供 async / await 语法糖,解决了执行性和可读性共存的难题。于是,协程逐渐被更多人发现并看好,也有越来越多的人尝试用 Node.js 做起了后端开发。
回到我们的 Python。使用生成器,是 Python 2 开头的时代实现协程的老方法了,Python 3.7 提供了新的基于 asyncio 和 async / await 的方法。今天我们跟随时代,抛弃掉不容易理解、也不容易写的旧的基于生成器的方法,直接来讲新方法。
爬虫案例看协程
爬虫,就是互联网的蜘蛛,在搜索引擎诞生之时,与其一同来到世上。爬虫每秒钟都会爬取大量的网页,提取关键信息后存储在数据库中,以便日后分析。爬虫有非常简单的 Python 十行代码实现,也有 Google 那样的全球分布式爬虫的上百万行代码,分布在内部上万台服务器上,对全世界的信息进行嗅探。
话不多说,我们先看一个简单的爬虫例子:
import time
def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
time.sleep(sleep_time)
print('OK {}'.format(url))
def main(urls):
for url in urls:
crawl_page(url)
%time main(['url_1', 'url_2', 'url_3', 'url_4'])
########## 输出 ##########
crawling url_1
OK url_1
crawling url_2
OK url_2
crawling url_3
OK url_3
crawling url_4
OK url_4
Wall time: 10 s
(注意:本文的主要目的是协程的基础概念,因此我们简化爬虫的 scrawl_page 函数为休眠数秒,休眠时间取决于 url 最后的那个数字。)
这是一个很简单的爬虫,main() 函数执行时,调取 crawl_page() 函数进行网络通信,经过若干秒等待后收到结果,然后执行下一个。
看起来很简单,但你仔细一算,它也占用了不少时间,五个页面分别用了 1 秒到 4 秒的时间,加起来一共用了 10 秒。这显然效率低下,该怎么优化呢?
于是,一个很简单的思路出现了——我们这种爬取操作,完全可以并发化。我们就来看看使用协程怎么写。
import asyncio
async def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
await asyncio.sleep(sleep_time)
print('OK {}'.format(url))
async def main(urls):
for url in urls:
await crawl_page(url)
%time asyncio.run(main(['url_1', 'url_2', 'url_3', 'url_4']))
########## 输出 ##########
crawling url_1
OK url_1
crawling url_2
OK url_2
crawling url_3
OK url_3
crawling url_4
OK url_4
Wall time: 10 s
看到这段代码,你应该发现了,在 Python 3.7 以上版本中,使用协程写异步程序非常简单。
首先来看 import asyncio,这个库包含了大部分我们实现协程所需的魔法工具。
async 修饰词声明异步函数,于是,这里的 crawl_page 和 main 都变成了异步函数。而调用异步函数,我们便可得到一个协程对象(coroutine object)。
举个例子,如果你 print(crawl_page('')),便会输出
再来说说协程的执行。执行协程有多种方法,这里我介绍一下常用的三种。
首先,我们可以通过 await 来调用。await 执行的效果,和 Python 正常执行是一样的,也就是说程序会阻塞在这里,进入被调用的协程函数,执行完毕返回后再继续,而这也是 await 的字面意思。代码中 await asyncio.sleep(sleep_time) 会在这里休息若干秒, await crawl_page(url) 则会执行 crawl_page() 函数。
其次,我们可以通过 asyncio.create_task() 来创建任务。
最后,我们需要 asyncio.run 来触发运行。asyncio.run 这个函数是 Python 3.7 之后才有的特性,可以让 Python 的协程接口变得非常简单,你不用去理会事件循环怎么定义和怎么使用的问题(我们会在下面讲)。一个非常好的编程规范是,asyncio.run(main()) 作为主程序的入口函数,在程序运行周期内,只调用一次 asyncio.run。
这样,你就大概看懂了协程是怎么用的吧。不妨试着跑一下代码,欸,怎么还是 10 秒?
10 秒就对了,还记得上面所说的,await 是同步调用,因此, crawl_page(url) 在当前的调用结束之前,是不会触发下一次调用的。于是,这个代码效果就和上面完全一样了,相当于我们用异步接口写了个同步代码。
现在又该怎么办呢?
其实很简单,也正是我接下来要讲的协程中的一个重要概念,任务(Task)。老规矩,先看代码。
import asyncio
async def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
await asyncio.sleep(sleep_time)
print('OK {}'.format(url))
async def main(urls):
tasks = [asyncio.create_task(crawl_page(url)) for url in urls]
for task in tasks:
await task
%time asyncio.run(main(['url_1', 'url_2', 'url_3', 'url_4']))
########## 输出 ##########
crawling url_1
crawling url_2
crawling url_3
crawling url_4
OK url_1
OK url_2
OK url_3
OK url_4
Wall time: 3.99 s
你可以看到,我们有了协程对象后,便可以通过 asyncio.create_task 来创建任务。任务创建后很快就会被调度执行,这样,我们的代码也不会阻塞在任务这里。所以,我们要等所有任务都结束才行,用 for task in tasks: await task 即可。
这次,你就看到效果了吧,结果显示,运行总时长等于运行时间最长的爬虫。
当然,你也可以想一想,这里用多线程应该怎么写?而如果需要爬取的页面有上万个又该怎么办呢?再对比下协程的写法,谁更清晰自是一目了然。
其实,对于执行 tasks,还有另一种做法:
import asyncio
async def crawl_page(url):
print('crawling {}'.format(url))
sleep_time = int(url.split('_')[-1])
await asyncio.sleep(sleep_time)
print('OK {}'.format(url))
async def main(urls):
tasks = [asyncio.create_task(crawl_page(url)) for url in urls]
await asyncio.gather(*tasks)
%time asyncio.run(main(['url_1', 'url_2', 'url_3', 'url_4']))
########## 输出 ##########
crawling url_1
crawling url_2
crawling url_3
crawling url_4
OK url_1
OK url_2
OK url_3
OK url_4
Wall time: 4.01 s
这里的代码也很好理解。唯一要注意的是, *tasks 解包列表,将列表变成了函数的参数;与之对应的是, ** dict 将字典变成了函数的参数。
另外, asyncio.create_task, asyncio.run 这些函数都是 Python 3.7 以上的版本才提供的,自然,相比于旧接口它们也更容易理解和阅读。
解密协程运行时
现在,我们深入代码底层看看。有了前面的知识做基础,你应该很容易理解这两段代码。
import asyncio
async def worker_1():
print('worker_1 start')
await asyncio.sleep(1)
print('worker_1 done')
async def worker_2():
print('worker_2 start')
await asyncio.sleep(2)
print('worker_2 done')
async def main():
print('before await')
await worker_1()
print('awaited worker_1')
await worker_2()
print('awaited worker_2')
%time asyncio.run(main())
########## 输出 ##########
before await
worker_1 start
worker_1 done
awaited worker_1
worker_2 start
worker_2 done
awaited worker_2
Wall time: 3 s
import asyncio
async def worker_1():
print('worker_1 start')
await asyncio.sleep(1)
print('worker_1 done')
async def worker_2():
print('worker_2 start')
await asyncio.sleep(2)
print('worker_2 done')
async def main():
task1 = asyncio.create_task(worker_1())
task2 = asyncio.create_task(worker_2())
print('before await')
await task1
print('awaited worker_1')
await task2
print('awaited worker_2')
%time asyncio.run(main())
########## 输出 ##########
before await
worker_1 start
worker_2 start
worker_1 done
awaited worker_1
worker_2 done
awaited worker_2
Wall time: 2.01 s
为了让你更详细了解到协程和线程的具体区别,这里我详细地分析了整个过程。步骤有点多,别着急,我们慢慢来看。
-
asyncio.run(main()),程序进入 main() 函数,事件循环开启; - task1 和 task2 任务被创建,并进入事件循环等待运行;运行到 print,输出
'before await'; - await task1 执行,用户选择从当前的主任务中切出,事件调度器开始调度 worker_1;
- worker_1 开始运行,运行 print 输出
'worker_1 start',然后运行到await asyncio.sleep(1), 从当前任务切出,事件调度器开始调度 worker_2; - worker_2 开始运行,运行 print 输出
'worker_2 start',然后运行await asyncio.sleep(2)从当前任务切出; - 以上所有事件的运行时间,都应该在 1ms 到 10ms 之间,甚至可能更短,事件调度器从这个时候开始暂停调度;
- 一秒钟后,worker_1 的 sleep 完成,事件调度器将控制权重新传给 task_1,输出
'worker_1 done',task_1 完成任务,从事件循环中退出; - await task1 完成,事件调度器将控制器传给主任务,输出
'awaited worker_1',·然后在 await task2 处继续等待; - 两秒钟后,worker_2 的 sleep 完成,事件调度器将控制权重新传给 task_2,输出
'worker_2 done',task_2 完成任务,从事件循环中退出; - 主任务输出
'awaited worker_2',协程全任务结束,事件循环结束。
接下来,我们进阶一下。如果我们想给某些协程任务限定运行时间,一旦超时就取消,又该怎么做呢?再进一步,如果某些协程运行时出现错误,又该怎么处理呢?同样的,来看代码。
import asyncio
async def worker_1():
await asyncio.sleep(1)
return 1
async def worker_2():
await asyncio.sleep(2)
return 2 / 0
async def worker_3():
await asyncio.sleep(3)
return 3
async def main():
task_1 = asyncio.create_task(worker_1())
task_2 = asyncio.create_task(worker_2())
task_3 = asyncio.create_task(worker_3())
await asyncio.sleep(2)
task_3.cancel()
res = await asyncio.gather(task_1, task_2, task_3, return_exceptions=True)
print(res)
%time asyncio.run(main())
########## 输出 ##########
[1, ZeroDivisionError('division by zero'), CancelledError()]
Wall time: 2 s
你可以看到,worker_1 正常运行,worker_2 运行中出现错误,worker_3 执行时间过长被我们 cancel 掉了,这些信息会全部体现在最终的返回结果 res 中。
不过要注意 return_exceptions=True 这行代码。如果不设置这个参数,错误就会完整地 throw 到我们这个执行层,从而需要 try except 来捕捉,这也就意味着其他还没被执行的任务会被全部取消掉。为了避免这个局面,我们将 return_exceptions 设置为 True 即可。
到这里,发现了没,线程能实现的,协程都能做到。那就让我们温习一下这些知识点,用协程来实现一个经典的生产者消费者模型吧。
import asyncio
import random
async def consumer(queue, id):
while True:
val = await queue.get()
print('{} get a val: {}'.format(id, val))
await asyncio.sleep(1)
async def producer(queue, id):
for i in range(5):
val = random.randint(1, 10)
await queue.put(val)
print('{} put a val: {}'.format(id, val))
await asyncio.sleep(1)
async def main():
queue = asyncio.Queue()
consumer_1 = asyncio.create_task(consumer(queue, 'consumer_1'))
consumer_2 = asyncio.create_task(consumer(queue, 'consumer_2'))
producer_1 = asyncio.create_task(producer(queue, 'producer_1'))
producer_2 = asyncio.create_task(producer(queue, 'producer_2'))
await asyncio.sleep(10)
consumer_1.cancel()
consumer_2.cancel()
await asyncio.gather(consumer_1, consumer_2, producer_1, producer_2, return_exceptions=True)
%time asyncio.run(main())
########## 输出 ##########
producer_1 put a val: 5
producer_2 put a val: 3
consumer_1 get a val: 5
consumer_2 get a val: 3
producer_1 put a val: 1
producer_2 put a val: 3
consumer_2 get a val: 1
consumer_1 get a val: 3
producer_1 put a val: 6
producer_2 put a val: 10
consumer_1 get a val: 6
consumer_2 get a val: 10
producer_1 put a val: 4
producer_2 put a val: 5
consumer_2 get a val: 4
consumer_1 get a val: 5
producer_1 put a val: 2
producer_2 put a val: 8
consumer_1 get a val: 2
consumer_2 get a val: 8
Wall time: 10 s
并发编程
区分并发与并行
在我们学习并发编程时,常常同时听到并发(Concurrency)和并行(Parallelism)这两个术语,这两者经常一起使用,导致很多人以为它们是一个意思,其实不然。
首先你要辨别一个误区,在Python中,并发并不是指同一时刻有多个操作(thread、task)同时进行。相反,某个特定的时刻,它只允许有一个操作发生,只不过线程/任务之间会互相切换,直到完成。我们来看下面这张图:

图中出现了thread和task两种切换顺序的不同方式,分别对应Python中并发的两种形式——threading和asyncio。
对于threading,操作系统知道每个线程的所有信息,因此它会做主在适当的时候做线程切换。很显然,这样的好处是代码容易书写,因为程序员不需要做任何切换操作的处理;但是切换线程的操作,也有可能出现在一个语句执行的过程中(比如 x += 1),这样就容易出现race condition的情况。
而对于asyncio,主程序想要切换任务时,必须得到此任务可以被切换的通知,这样一来也就可以避免刚刚提到的 race condition的情况。
至于所谓的并行,指的才是同一时刻、同时发生。Python中的multi-processing便是这个意思,对于multi-processing,你可以简单地这么理解:比如你的电脑是6核处理器,那么在运行程序时,就可以强制Python开6个进程,同时执行,以加快运行速度,它的原理示意图如下:

对比来看,
- 并发通常应用于I/O操作频繁的场景,比如你要从网站上下载多个文件,I/O操作的时间可能会比CPU运行处理的时间长得多。
- 而并行则更多应用于CPU heavy的场景,比如MapReduce中的并行计算,为了加快运行速度,一般会用多台机器、多个处理器来完成。
并发编程之Futures
单线程与多线程性能比较
接下来,我们一起通过具体的实例,从代码的角度来理解并发编程中的Futures,并进一步来比较其与单线程的性能区别。
假设我们有一个任务,是下载一些网站的内容并打印。如果用单线程的方式,它的代码实现如下所示(为了简化代码,突出主题,此处我忽略了异常处理):
import requests
import time
def download_one(url):
resp = requests.get(url)
print('Read {} from {}'.format(len(resp.content), url))
def download_all(sites):
for site in sites:
download_one(site)
def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
download_all(sites)
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites), end_time - start_time))
if __name__ == '__main__':
main()
# 输出
Read 129886 from https://en.wikipedia.org/wiki/Portal:Arts
Read 184343 from https://en.wikipedia.org/wiki/Portal:History
Read 224118 from https://en.wikipedia.org/wiki/Portal:Society
Read 107637 from https://en.wikipedia.org/wiki/Portal:Biography
Read 151021 from https://en.wikipedia.org/wiki/Portal:Mathematics
Read 157811 from https://en.wikipedia.org/wiki/Portal:Technology
Read 167923 from https://en.wikipedia.org/wiki/Portal:Geography
Read 93347 from https://en.wikipedia.org/wiki/Portal:Science
Read 321352 from https://en.wikipedia.org/wiki/Computer_science
Read 391905 from https://en.wikipedia.org/wiki/Python_(programming_language)
Read 321417 from https://en.wikipedia.org/wiki/Java_(programming_language)
Read 468461 from https://en.wikipedia.org/wiki/PHP
Read 180298 from https://en.wikipedia.org/wiki/Node.js
Read 56765 from https://en.wikipedia.org/wiki/The_C_Programming_Language
Read 324039 from https://en.wikipedia.org/wiki/Go_(programming_language)
Download 15 sites in 2.464231112999869 seconds
这种方式应该是最直接也最简单的:
- 先是遍历存储网站的列表;
- 然后对当前网站执行下载操作;
- 等到当前操作完成后,再对下一个网站进行同样的操作,一直到结束。
我们可以看到总共耗时约2.4s。单线程的优点是简单明了,但是明显效率低下,因为上述程序的绝大多数时间,都浪费在了I/O等待上。程序每次对一个网站执行下载操作,都必须等到前一个网站下载完成后才能开始。如果放在实际生产环境中,我们需要下载的网站数量至少是以万为单位的,不难想象,这种方案根本行不通。
接着我们再来看,多线程版本的代码实现:
import concurrent.futures
import requests
import threading
import time
def download_one(url):
resp = requests.get(url)
print('Read {} from {}'.format(len(resp.content), url))
def download_all(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_one, sites)
def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
download_all(sites)
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites), end_time - start_time))
if __name__ == '__main__':
main()
## 输出
Read 151021 from https://en.wikipedia.org/wiki/Portal:Mathematics
Read 129886 from https://en.wikipedia.org/wiki/Portal:Arts
Read 107637 from https://en.wikipedia.org/wiki/Portal:Biography
Read 224118 from https://en.wikipedia.org/wiki/Portal:Society
Read 184343 from https://en.wikipedia.org/wiki/Portal:History
Read 167923 from https://en.wikipedia.org/wiki/Portal:Geography
Read 157811 from https://en.wikipedia.org/wiki/Portal:Technology
Read 91533 from https://en.wikipedia.org/wiki/Portal:Science
Read 321352 from https://en.wikipedia.org/wiki/Computer_science
Read 391905 from https://en.wikipedia.org/wiki/Python_(programming_language)
Read 180298 from https://en.wikipedia.org/wiki/Node.js
Read 56765 from https://en.wikipedia.org/wiki/The_C_Programming_Language
Read 468461 from https://en.wikipedia.org/wiki/PHP
Read 321417 from https://en.wikipedia.org/wiki/Java_(programming_language)
Read 324039 from https://en.wikipedia.org/wiki/Go_(programming_language)
Download 15 sites in 0.19936635800002023 seconds
非常明显,总耗时是0.2s左右,效率一下子提升了10倍多。
我们具体来看这段代码,它是多线程版本和单线程版的主要区别所在:
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_one, sites)
这里我们创建了一个线程池,总共有5个线程可以分配使用。executer.map()与前面所讲的Python内置的map()函数类似,表示对sites中的每一个元素,并发地调用函数download_one()。
顺便提一下,在download_one()函数中,我们使用的requests.get()方法是线程安全的(thread-safe),因此在多线程的环境下,它也可以安全使用,并不会出现race condition的情况。
另外,虽然线程的数量可以自己定义,但是线程数并不是越多越好,因为线程的创建、维护和删除也会有一定的开销。所以如果你设置的很大,反而可能会导致速度变慢。我们往往需要根据实际的需求做一些测试,来寻找最优的线程数量。
当然,我们也可以用并行的方式去提高程序运行效率。你只需要在download_all()函数中,做出下面的变化即可:
with futures.ThreadPoolExecutor(workers) as executor
=>
with futures.ProcessPoolExecutor() as executor:
在需要修改的这部分代码中,函数ProcessPoolExecutor()表示创建进程池,使用多个进程并行的执行程序。不过,这里我们通常省略参数workers,因为系统会自动返回CPU的数量作为可以调用的进程数。
我刚刚提到过,并行的方式一般用在CPU heavy的场景中,因为对于I/O heavy的操作,多数时间都会用于等待,相比于多线程,使用多进程并不会提升效率。反而很多时候,因为CPU数量的限制,会导致其执行效率不如多线程版本。
什么是 Futures ?
Python中的Futures模块,位于concurrent.futures和asyncio中,它们都表示带有延迟的操作。Futures会将处于等待状态的操作包裹起来放到队列中,这些操作的状态随时可以查询,当然,它们的结果或是异常,也能够在操作完成后被获取。
通常来说,作为用户,我们不用考虑如何去创建Futures,这些Futures底层都会帮我们处理好。我们要做的,实际上是去schedule这些Futures的执行。
比如,Futures中的Executor类,当我们执行executor.submit(func)时,它便会安排里面的func()函数执行,并返回创建好的future实例,以便你之后查询调用。
这里再介绍一些常用的函数。Futures中的方法done(),表示相对应的操作是否完成——True表示完成,False表示没有完成。不过,要注意,done()是non-blocking的,会立即返回结果。相对应的add_done_callback(fn),则表示Futures完成后,相对应的参数函数fn,会被通知并执行调用。
Futures中还有一个重要的函数result(),它表示当future完成后,返回其对应的结果或异常。而as_completed(fs),则是针对给定的future迭代器fs,在其完成后,返回完成后的迭代器。
所以,上述例子也可以写成下面的形式:
import concurrent.futures
import requests
import time
def download_one(url):
resp = requests.get(url)
print('Read {} from {}'.format(len(resp.content), url))
def download_all(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
to_do = []
for site in sites:
future = executor.submit(download_one, site)
to_do.append(future)
for future in concurrent.futures.as_completed(to_do):
future.result()
def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
download_all(sites)
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites), end_time - start_time))
if __name__ == '__main__':
main()
# 输出
Read 129886 from https://en.wikipedia.org/wiki/Portal:Arts
Read 107634 from https://en.wikipedia.org/wiki/Portal:Biography
Read 224118 from https://en.wikipedia.org/wiki/Portal:Society
Read 158984 from https://en.wikipedia.org/wiki/Portal:Mathematics
Read 184343 from https://en.wikipedia.org/wiki/Portal:History
Read 157949 from https://en.wikipedia.org/wiki/Portal:Technology
Read 167923 from https://en.wikipedia.org/wiki/Portal:Geography
Read 94228 from https://en.wikipedia.org/wiki/Portal:Science
Read 391905 from https://en.wikipedia.org/wiki/Python_(programming_language)
Read 321352 from https://en.wikipedia.org/wiki/Computer_science
Read 180298 from https://en.wikipedia.org/wiki/Node.js
Read 321417 from https://en.wikipedia.org/wiki/Java_(programming_language)
Read 468421 from https://en.wikipedia.org/wiki/PHP
Read 56765 from https://en.wikipedia.org/wiki/The_C_Programming_Language
Read 324039 from https://en.wikipedia.org/wiki/Go_(programming_language)
Download 15 sites in 0.21698231499976828 seconds
这里,我们首先调用executor.submit(),将下载每一个网站的内容都放进future队列to_do,等待执行。然后是as_completed()函数,在future完成后,便输出结果。
不过,这里要注意,future列表中每个future完成的顺序,和它在列表中的顺序并不一定完全一致。到底哪个先完成、哪个后完成,取决于系统的调度和每个future的执行时间。
为什么多线程每次只能有一个线程执行?
前面我说过,同一时刻,Python主程序只允许有一个线程执行,所以Python的并发,是通过多线程的切换完成的。你可能会疑惑这到底是为什么呢?
这里我简单提一下全局解释器锁的概念,具体内容后面会讲到。
事实上,Python的解释器并不是线程安全的,为了解决由此带来的race condition等问题,Python便引入了全局解释器锁,也就是同一时刻,只允许一个线程执行。当然,在执行I/O操作时,如果一个线程被block了,全局解释器锁便会被释放,从而让另一个线程能够继续执行。
通过上面的学习,我们知道,在处理I/O操作时,使用多线程与普通的单线程相比,效率得到了极大的提高。你可能会想,既然这样,为什么还需要Asyncio?
诚然,多线程有诸多优点且应用广泛,但也存在一定的局限性:
- 比如,多线程运行过程容易被打断,因此有可能出现race condition的情况;
- 再如,线程切换本身存在一定的损耗,线程数不能无限增加,因此,如果你的 I/O操作非常heavy,多线程很有可能满足不了高效率、高质量的需求。
正是为了解决这些问题,Asyncio应运而生。
什么是Asyncio
Sync VS Async
我们首先来区分一下Sync(同步)和Async(异步)的概念。
- 所谓Sync,是指操作一个接一个地执行,下一个操作必须等上一个操作完成后才能执行。
- 而Async是指不同操作间可以相互交替执行,如果其中的某个操作被block了,程序并不会等待,而是会找出可执行的操作继续执行。
举个简单的例子,你的老板让你做一份这个季度的报表,并且邮件发给他。
- 如果按照Sync的方式,你会先向软件输入这个季度的各项数据,接下来等待5min,等报表明细生成后,再写邮件发给他。
- 但如果按照Async的方式,再你输完这个季度的各项数据后,便会开始写邮件。等报表明细生成后,你会暂停邮件,先去查看报表,确认后继续写邮件直到发送完毕。
Asyncio工作原理
事实上,Asyncio和其他Python程序一样,是单线程的,它只有一个主线程,但是可以进行多个不同的任务(task),这里的任务,就是特殊的future对象。这些不同的任务,被一个叫做event loop的对象所控制。你可以把这里的任务,类比成多线程版本里的多个线程。
为了简化讲解这个问题,我们可以假设任务只有两个状态:一是预备状态;二是等待状态。所谓的预备状态,是指任务目前空闲,但随时待命准备运行。而等待状态,是指任务已经运行,但正在等待外部的操作完成,比如I/O操作。
在这种情况下,event loop会维护两个任务列表,分别对应这两种状态;并且选取预备状态的一个任务(具体选取哪个任务,和其等待的时间长短、占用的资源等等相关),使其运行,一直到这个任务把控制权交还给event loop为止。
当任务把控制权交还给event loop时,event loop会根据其是否完成,把任务放到预备或等待状态的列表,然后遍历等待状态列表的任务,查看他们是否完成。
- 如果完成,则将其放到预备状态的列表;
- 如果未完成,则继续放在等待状态的列表。
而原先在预备状态列表的任务位置仍旧不变,因为它们还未运行。
这样,当所有任务被重新放置在合适的列表后,新一轮的循环又开始了:event loop继续从预备状态的列表中选取一个任务使其执行…如此周而复始,直到所有任务完成。
值得一提的是,对于Asyncio来说,它的任务在运行时不会被外部的一些因素打断,因此Asyncio内的操作不会出现race condition的情况,这样你就不需要担心线程安全的问题了。
Asyncio用法
讲完了Asyncio的原理,我们结合具体的代码来看一下它的用法。还是以之前下载网站内容为例,用Asyncio的写法我放在了下面代码中(省略了异常处理的一些操作),接下来我们一起来看:
import asyncio
import aiohttp
import time
async def download_one(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
print('Read {} from {}'.format(resp.content_length, url))
async def download_all(sites):
tasks = [asyncio.create_task(download_one(site)) for site in sites]
await asyncio.gather(*tasks)
def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
asyncio.run(download_all(sites))
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites), end_time - start_time))
if __name__ == '__main__':
main()
## 输出
Read 63153 from https://en.wikipedia.org/wiki/Java_(programming_language)
Read 31461 from https://en.wikipedia.org/wiki/Portal:Society
Read 23965 from https://en.wikipedia.org/wiki/Portal:Biography
Read 36312 from https://en.wikipedia.org/wiki/Portal:History
Read 25203 from https://en.wikipedia.org/wiki/Portal:Arts
Read 15160 from https://en.wikipedia.org/wiki/The_C_Programming_Language
Read 28749 from https://en.wikipedia.org/wiki/Portal:Mathematics
Read 29587 from https://en.wikipedia.org/wiki/Portal:Technology
Read 79318 from https://en.wikipedia.org/wiki/PHP
Read 30298 from https://en.wikipedia.org/wiki/Portal:Geography
Read 73914 from https://en.wikipedia.org/wiki/Python_(programming_language)
Read 62218 from https://en.wikipedia.org/wiki/Go_(programming_language)
Read 22318 from https://en.wikipedia.org/wiki/Portal:Science
Read 36800 from https://en.wikipedia.org/wiki/Node.js
Read 67028 from https://en.wikipedia.org/wiki/Computer_science
Download 15 sites in 0.062144195078872144 seconds
这里的Async和await关键字是Asyncio的最新写法,表示这个语句/函数是non-block的,正好对应前面所讲的event loop的概念。如果任务执行的过程需要等待,则将其放入等待状态的列表中,然后继续执行预备状态列表里的任务。
主函数里的asyncio.run(coro)是Asyncio的root call,表示拿到event loop,运行输入的coro,直到它结束,最后关闭这个event loop。事实上,asyncio.run()是Python3.7+才引入的,相当于老版本的以下语句:
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(coro)
finally:
loop.close()
至于Asyncio版本的函数download_all(),和之前多线程版本有很大的区别:
tasks = [asyncio.create_task(download_one(site)) for site in sites]
await asyncio.gather(*task)
这里的 asyncio.create_task(coro),表示对输入的协程coro创建一个任务,安排它的执行,并返回此任务对象。这个函数也是Python 3.7+新增的,如果是之前的版本,你可以用 asyncio.ensure_future(coro) 等效替代。可以看到,这里我们对每一个网站的下载,都创建了一个对应的任务。
再往下看, asyncio.gather(*aws, loop=None, return_exception=False),则表示在event loop中运行 aws序列 的所有任务。当然,除了例子中用到的这几个函数,Asyncio还提供了很多其他的用法,你可以查看 相应文档 进行了解。
最后,我们再来看一下最后的输出结果——用时只有0.06s,效率比起之前的多线程版本,可以说是更上一层楼,充分体现其优势。
Asyncio有缺陷吗?
学了这么多内容,我们认识到了Asyncio的强大,但你要清楚,任何一种方案都不是完美的,都存在一定的局限性,Asyncio同样如此。
实际工作中,想用好Asyncio,特别是发挥其强大的功能,很多情况下必须得有相应的Python库支持。你可能注意到了,之前多线程编程中,我们使用的是requests库,但今天我们并没有使用,而是用了aiohttp库,原因就是requests库并不兼容Asyncio,但是aiohttp库兼容。
Asyncio软件库的兼容性问题,在Python3的早期一直是个大问题,但是随着技术的发展,这个问题正逐步得到解决。
另外,使用Asyncio时,因为你在任务的调度方面有了更大的自主权,写代码时就得更加注意,不然很容易出错。
举个例子,如果你需要await一系列的操作,就得使用asyncio.gather();如果只是单个的future,或许只用asyncio.wait()就可以了。那么,对于你的future,你是想要让它run_until_complete()还是run_forever()呢?诸如此类,都是你在面对具体问题时需要考虑的。
多线程还是Asyncio
不知不觉,我们已经把并发编程的两种方式都给学习完了。不过,遇到实际问题时,多线程和Asyncio到底如何选择呢?
总的来说,你可以遵循以下伪代码的规范:
if io_bound:
if io_slow:
print('Use Asyncio')
else:
print('Use multi-threading')
else if cpu_bound:
print('Use multi-processing')
- 如果是I/O bound,并且I/O操作很慢,需要很多任务/线程协同实现,那么使用Asyncio更合适。
- 如果是I/O bound,但是I/O操作很快,只需要有限数量的任务/线程,那么使用多线程就可以了。
- 如果是CPU bound,则需要使用多进程来提高程序运行效率。
全局解释器锁GIL
讲解GIL之前,我们先来看一个例子,让你感受下GIL的谜团。
比如下面这段很简单的cpu-bound代码:
def CountDown(n):
while n > 0:
n -= 1
现在,假设一个很大的数字n = 100000000,我们先来试试单线程的情况下执行CountDown(n),耗时为5.4s。
这时,我们想要用多线程来加速,比如下面这几行操作:
from threading import Thread
n = 100000000
t1 = Thread(target=CountDown, args=[n // 2])
t2 = Thread(target=CountDown, args=[n // 2])
t1.start()
t2.start()
t1.join()
t2.join()
我又在同一台机器上跑了一下,结果发现,这不仅没有得到速度的提升,反而让运行变慢,总共花了9.6s。
我还是不死心,决定使用四个线程再试一次,结果发现运行时间还是9.8s,和2个线程的结果几乎一样。
这是怎么回事呢?难道是我的机器性能有问题?你可以先自己思考一下这个问题,也可以在自己电脑上测试一下。我当然也要自我反思一下,并且提出了下面两个疑问。
第一个怀疑:我的机器出问题了吗?
这不得不说也是一个合理的猜想。因此我又找了一个单核CPU的台式机,跑了一下上面的实验。这次我发现,在单核CPU电脑上,单线程运行需要11s时间,2个线程运行也是11s时间。虽然不像第一台机器那样,多线程反而比单线程更慢,但是这两次整体效果几乎一样!
看起来,这不像是电脑的问题,而是Python的线程失效了,没有起到并行计算的作用。
顺理成章,我又有了第二个怀疑:Python的线程是不是假的线程?
Python的线程,的的确确封装了底层的操作系统线程,在Linux系统里是Pthread(全称为POSIX Thread),而在Windows系统里是Windows Thread。另外,Python的线程,也完全受操作系统管理,比如协调何时执行、管理内存资源、管理中断等等。
所以,虽然Python的线程和C++的线程本质上是不同的抽象,但它们的底层并没有什么不同。
引进GIL的原因
事实上,正是GIL,导致了Python线程的性能并不像我们期望的那样。
GIL,是最流行的Python解释器CPython中的一个技术术语。它的意思是全局解释器锁,本质上是类似操作系统的Mutex。每一个Python线程,在CPython解释器中执行时,都会先锁住自己的线程,阻止别的线程执行。
当然,CPython会做一些小把戏,轮流执行Python线程。这样一来,用户看到的就是“伪并行”——Python线程在交错执行,来模拟真正并行的线程。
那么,为什么CPython需要GIL呢?这其实和CPython的实现有关。CPython使用引用计数来管理内存,所有Python脚本中创建的实例,都会有一个引用计数,来记录有多少个指针指向它。当引用计数只有0时,则会自动释放内存。
什么意思呢?我们来看下面这个例子:
>>> import sys
>>> a = []
>>> b = a
>>> sys.getrefcount(a)
3
这个例子中,a的引用计数是3,因为有a、b和作为参数传递的getrefcount这三个地方,都引用了一个空列表。
这样一来,如果有两个Python线程同时引用了a,就会造成引用计数的race condition,引用计数可能最终只增加1,这样就会造成内存被污染。因为第一个线程结束时,会把引用计数减少1,这时可能达到条件释放内存,当第二个线程再试图访问a时,就找不到有效的内存了。
所以说,CPython 引进 GIL 其实主要就是这么两个原因:
- 一是设计者为了规避类似于内存管理这样的复杂的竞争风险问题(race condition);
- 二是因为CPython大量使用C语言库,但大部分C语言库都不是原生线程安全的(线程安全会降低性能和增加复杂度)。
GIL是如何工作的?
下面这张图,就是一个GIL在Python程序的工作示例。其中,Thread 1、2、3轮流执行,每一个线程在开始执行时,都会锁住GIL,以阻止别的线程执行;同样的,每一个线程执行完一段后,会释放GIL,以允许别的线程开始利用资源。

细心的你可能会发现一个问题:为什么Python线程会去主动释放GIL呢?毕竟,如果仅仅是要求Python线程在开始执行时锁住GIL,而永远不去释放GIL,那别的线程就都没有了运行的机会。
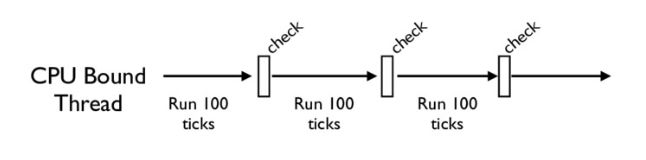
没错,CPython中还有另一个机制,叫做check_interval,意思是CPython解释器会去轮询检查线程GIL的锁住情况。每隔一段时间,Python解释器就会强制当前线程去释放GIL,这样别的线程才能有执行的机会。
不同版本的Python中,check interval的实现方式并不一样。早期的Python是100个ticks,大致对应了1000个bytecodes;而 Python 3以后,interval是15毫秒。当然,我们不必细究具体多久会强制释放GIL,这不应该成为我们程序设计的依赖条件,我们只需明白,CPython解释器会在一个“合理”的时间范围内释放GIL就可以了。
整体来说,每一个Python线程都是类似这样循环的封装,我们来看下面这段代码:
for (;;) {
if (--ticker < 0) {
ticker = check_interval;
/* Give another thread a chance */
PyThread_release_lock(interpreter_lock);
/* Other threads may run now */
PyThread_acquire_lock(interpreter_lock, 1);
}
bytecode = *next_instr++;
switch (bytecode) {
/* execute the next instruction ... */
}
}
从这段代码中,我们可以看到,每个Python线程都会先检查ticker计数。只有在ticker大于0的情况下,线程才会去执行自己的bytecode。
Python的线程安全
不过,有了GIL,并不意味着我们Python编程者就不用去考虑线程安全了。即使我们知道,GIL仅允许一个Python线程执行,但前面我也讲到了,Python还有check interval这样的抢占机制。我们来考虑这样一段代码:
import threading
n = 0
def foo():
global n
n += 1
threads = []
for i in range(100):
t = threading.Thread(target=foo)
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
print(n)
如果你执行的话,就会发现,尽管大部分时候它能够打印100,但有时侯也会打印99或者98。
这其实就是因为, n+=1 这一句代码让线程并不安全。如果你去翻译foo这个函数的bytecode,就会发现,它实际上由下面四行bytecode组成:
>>> import dis
>>> dis.dis(foo)
LOAD_GLOBAL 0 (n)
LOAD_CONST 1 (1)
INPLACE_ADD
STORE_GLOBAL 0 (n)
而这四行bytecode中间都是有可能被打断的!
所以,千万别想着,有了GIL你的程序就可以高枕无忧了,我们仍然需要去注意线程安全。正如我开头所说, GIL的设计,主要是为了方便CPython解释器层面的编写者,而不是Python应用层面的程序员。作为Python的使用者,我们还是需要lock等工具,来确保线程安全。比如我下面的这个例子:
n = 0
lock = threading.Lock()
def foo():
global n
with lock:
n += 1
如何绕过GIL?
学到这里,估计有的Python使用者感觉自己像被废了武功一样,觉得降龙十八掌只剩下了一掌。其实大可不必,你并不需要太沮丧。Python的GIL,是通过CPython的解释器加的限制。如果你的代码并不需要CPython解释器来执行,就不再受GIL的限制。
事实上,很多高性能应用场景都已经有大量的C实现的Python库,例如NumPy的矩阵运算,就都是通过C来实现的,并不受GIL影响。
所以,大部分应用情况下,你并不需要过多考虑GIL。因为如果多线程计算成为性能瓶颈,往往已经有Python库来解决这个问题了。
换句话说,如果你的应用真的对性能有超级严格的要求,比如100us就对你的应用有很大影响,那我必须要说,Python可能不是你的最优选择。
当然,可以理解的是,我们难以避免的有时候就是想临时给自己松松绑,摆脱GIL,比如在深度学习应用里,大部分代码就都是Python的。在实际工作中,如果我们想实现一个自定义的微分算子,或者是一个特定硬件的加速器,那我们就不得不把这些关键性能(performance-critical)代码在C++中实现(不再受GIL所限),然后再提供Python的调用接口。
总的来说,你只需要重点记住,绕过GIL的大致思路有这么两种就够了:
- 绕过CPython,使用JPython(Java实现的Python解释器)等别的实现;
- 把关键性能代码,放到别的语言(一般是C++)中实现。
Python 垃圾回收机制
众所周知,我们当代的计算机都是图灵机架构。图灵机架构的本质,就是一条无限长的纸带,对应着我们今天的存储器。在工程学的演化中,逐渐出现了寄存器、易失性存储器(内存)和永久性存储器(硬盘)等产品。其实,这本身来自一个矛盾:速度越快的存储器,单位价格也越昂贵。因此,妥善利用好每一寸高速存储器的空间,永远是系统设计的一个核心。
我们知道,Python 程序在运行的时候,需要在内存中开辟出一块空间,用于存放运行时产生的临时变量;计算完成后,再将结果输出到永久性存储器中。如果数据量过大,内存空间管理不善就很容易出现 OOM(out of memory),俗称爆内存,程序可能被操作系统中止。
而对于服务器,这种设计为永不中断的系统来说,内存管理则显得更为重要,不然很容易引发内存泄漏。什么是内存泄漏呢?
- 这里的泄漏,并不是说你的内存出现了信息安全问题,被恶意程序利用了,而是指程序本身没有设计好,导致程序未能释放已不再使用的内存。
- 内存泄漏也不是指你的内存在物理上消失了,而是意味着代码在分配了某段内存后,因为设计错误,失去了对这段内存的控制,从而造成了内存的浪费。
那么,Python 又是怎么解决这些问题的?换句话说,对于不会再用到的内存空间,Python 是通过什么机制来回收这些空间的呢?
计数引用
Python 中一切皆对象。因此,你所看到的一切变量,本质上都是对象的一个指针。
那么,怎么知道一个对象,是否永远都不能被调用了呢?如果你学过java那么这个问题不难理解,当这个对象的引用计数(指针数)为 0 的时候,说明这个对象永不可达,自然它也就成为了垃圾,需要被回收。
我们来看一个例子:
import os
import psutil
# 显示当前 python 程序占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. / 1024
print('{} memory used: {} MB'.format(hint, memory))
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
func()
show_memory_info('finished')
########## 输出 ##########
initial memory used: 47.19140625 MB
after a created memory used: 433.91015625 MB
finished memory used: 48.109375 MB
通过这个示例,你可以看到,调用函数 func(),在列表 a 被创建之后,内存占用迅速增加到了 433 MB:而在函数调用结束后,内存则返回正常。
这是因为,函数内部声明的列表 a 是局部变量,在函数返回后,局部变量的引用会注销掉;此时,列表 a 所指代对象的引用数为 0,Python 便会执行垃圾回收,因此之前占用的大量内存就又回来了。
明白了这个原理后,我们稍微修改一下代码:
def func():
show_memory_info('initial')
global a
a = [i for i in range(10000000)]
show_memory_info('after a created')
func()
show_memory_info('finished')
########## 输出 ##########
initial memory used: 48.88671875 MB
after a created memory used: 433.94921875 MB
finished memory used: 433.94921875 MB
新的这段代码中,global a 表示将 a 声明为全局变量。那么,即使函数返回后,列表的引用依然存在,于是对象就不会被垃圾回收掉,依然占用大量内存。
同样,如果我们把生成的列表返回,然后在主程序中接收,那么引用依然存在,垃圾回收就不会被触发,大量内存仍然被占用着:
def func():
show_memory_info('initial')
a = [i for i in derange(10000000)]
show_memory_info('after a created')
return a
a = func()
show_memory_info('finished')
########## 输出 ##########
initial memory used: 47.96484375 MB
after a created memory used: 434.515625 MB
finished memory used: 434.515625 MB
这是最常见的几种情况。由表及里,下面,我们深入看一下 Python 内部的引用计数机制。老规矩,先来看代码:
import sys
a = []
# 两次引用,一次来自 a,一次来自 getrefcount
print(sys.getrefcount(a))
def func(a):
# 四次引用,a,python 的函数调用栈,函数参数,和 getrefcount
print(sys.getrefcount(a))
func(a)
# 两次引用,一次来自 a,一次来自 getrefcount,函数 func 调用已经不存在
print(sys.getrefcount(a))
########## 输出 ##########
2
4
2
简单介绍一下,sys.getrefcount() 这个函数,可以查看一个变量的引用次数。这段代码本身应该很好理解,不过别忘了, getrefcount 本身也会引入一次计数。
另一个要注意的是,在函数调用发生的时候,会产生额外的两次引用,一次来自函数栈,另一个是函数参数。
import sys
a = []
print(sys.getrefcount(a)) # 两次
b = a
print(sys.getrefcount(a)) # 三次
c = b
d = b
e = c
f = e
g = d
print(sys.getrefcount(a)) # 八次
########## 输出 ##########
2
3
8
看到这段代码,需要你稍微注意一下,a、b、c、d、e、f、g 这些变量全部指代的是同一个对象,而sys.getrefcount() 函数并不是统计一个指针,而是要统计一个对象被引用的次数,所以最后一共会有八次引用。
理解引用这个概念后,引用释放是一种非常自然和清晰的思想。相比 C 语言里,你需要使用 free 去手动释放内存,Python 的垃圾回收在这里可以说是省心省力了。
当然如果你偏偏想手动释放内存,方法同样很简单。你只需要先调用 del a 来删除对象的引用;然后强制调用 gc.collect(),清除没有引用的对象,即可手动启动垃圾回收。
import gc
show_memory_info('initial')
a = [i for i in range(10000000)]
show_memory_info('after a created')
del a
gc.collect()
show_memory_info('finish')
print(a)
########## 输出 ##########
initial memory used: 48.1015625 MB
after a created memory used: 434.3828125 MB
finish memory used: 48.33203125 MB
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in
11
12 show_memory_info('finish')
---> 13 print(a)
NameError: name 'a' is not defined
循环引用
我们先来思考这么一个问题:如果有两个对象,它们互相引用,并且不再被别的对象所引用,那么它们应该被垃圾回收吗?
请仔细观察下面这段代码:
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
b = [i for i in range(10000000)]
show_memory_info('after a, b created')
a.append(b)
b.append(a)
func()
show_memory_info('finished')
########## 输出 ##########
initial memory used: 47.984375 MB
after a, b created memory used: 822.73828125 MB
finished memory used: 821.73046875 MB
这里,a 和 b 互相引用,并且,作为局部变量,在函数 func 调用结束后,a 和 b 这两个指针从程序意义上已经不存在了。但是,很明显,依然有内存占用!为什么呢?因为互相引用,导致它们的引用数都不为 0。
试想一下,如果这段代码出现在生产环境中,哪怕 a 和 b 一开始占用的空间不是很大,但经过长时间运行后,Python 所占用的内存一定会变得越来越大,最终撑爆服务器,后果不堪设想。
当然,有人可能会说,互相引用还是很容易被发现的呀,问题不大。可是,更隐蔽的情况是出现一个引用环,在工程代码比较复杂的情况下,引用环还真不一定能被轻易发现。
那么,我们应该怎么做呢?
事实上,Python 本身能够处理这种情况,我们刚刚讲过的,可以显式调用 gc.collect() ,来启动垃圾回收。
import gc
def func():
show_memory_info('initial')
a = [i for i in range(10000000)]
b = [i for i in range(10000000)]
show_memory_info('after a, b created')
a.append(b)
b.append(a)
func()
gc.collect()
show_memory_info('finished')
########## 输出 ##########
initial memory used: 49.51171875 MB
after a, b created memory used: 824.1328125 MB
finished memory used: 49.98046875 MB
所以你看,Python 的垃圾回收机制并没有那么弱。
Python 使用标记清除(mark-sweep)算法和分代收集(generational),来启用针对循环引用的自动垃圾回收。你可能不太熟悉这两个词,这里我简单介绍一下。
先来看标记清除算法。我们先用图论来理解不可达的概念。对于一个有向图,如果从一个节点出发进行遍历,并标记其经过的所有节点;那么,在遍历结束后,所有没有被标记的节点,我们就称之为不可达节点。显而易见,这些节点的存在是没有任何意义的,自然的,我们就需要对它们进行垃圾回收。
当然,每次都遍历全图,对于 Python 而言是一种巨大的性能浪费。所以,在 Python 的垃圾回收实现中,mark-sweep 使用双向链表维护了一个数据结构,并且只考虑容器类的对象(只有容器类对象才有可能产生循环引用)。具体算法这里我就不再多讲了,毕竟我们的重点是关注应用。
而分代收集算法,则是另一个优化手段。
Python 将所有对象分为三代。刚刚创立的对象是第 0 代;经过一次垃圾回收后,依然存在的对象,便会依次从上一代挪到下一代。而每一代启动自动垃圾回收的阈值,则是可以单独指定的。当垃圾回收器中新增对象减去删除对象达到相应的阈值时,就会对这一代对象启动垃圾回收。
事实上,分代收集基于的思想是,新生的对象更有可能被垃圾回收,而存活更久的对象也有更高的概率继续存活。因此,通过这种做法,可以节约不少计算量,从而提高 Python 的性能。
学了这么多,刚刚面试官的问题,你应该能回答得上来了吧!没错,引用计数是其中最简单的实现,不过切记,引用计数并非充要条件,它只能算作充分非必要条件;至于其他的可能性,我们所讲的循环引用正是其中一种。
调试内存泄漏
不过,虽然有了自动回收机制,但这也不是万能的,难免还是会有漏网之鱼。内存泄漏是我们不想见到的,而且还会严重影响性能。有没有什么好的调试手段呢?
答案当然是肯定的,接下来我就为你介绍一个“得力助手”。
它就是objgraph,一个非常好用的可视化引用关系的包。在这个包中,我主要推荐两个函数,第一个是show_refs(),它可以生成清晰的引用关系图。
通过下面这段代码和生成的引用调用图,你能非常直观地发现,有两个 list 互相引用,说明这里极有可能引起内存泄露。这样一来,再去代码层排查就容易多了。
import objgraph
a = [1, 2, 3]
b = [4, 5, 6]
a.append(b)
b.append(a)
objgraph.show_refs([a])

而另一个非常有用的函数,是 show_backrefs()。下面同样为示例代码和生成图,你可以自己先阅读一下:
import objgraph
a = [1, 2, 3]
b = [4, 5, 6]
a.append(b)
b.append(a)
objgraph.show_backrefs([a])
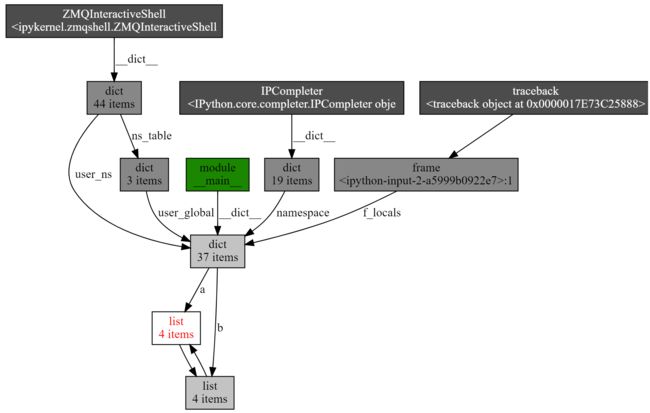
相比刚才的引用调用图,这张图显得稍微复杂一些。不过,我仍旧推荐你掌握它,因为这个 API 有很多有用的参数,比如层数限制(max_depth)、宽度限制(too_many)、输出格式控制(filename output)、节点过滤(filter, extra_ignore)等。所以,建议你使用之前,先认真看一下 文档。
总结
今天我们一起学习了Python的进阶内容
第一部分是对象的比较和拷贝,主要有下面几个重点内容。
- 比较操作符
'=='表示比较对象间的值是否相等,而'is'表示比较对象的标识是否相等,即它们是否指向同一个内存地址。 - 比较操作符
'is'效率优于'==',因为'is'操作符无法被重载,执行'is'操作只是简单的获取对象的ID,并进行比较;而'=='操作符则会递归地遍历对象的所有值,并逐一比较。 - 浅拷贝中的元素,是原对象中子对象的引用,因此,如果原对象中的元素是可变的,改变其也会影响拷贝后的对象,存在一定的副作用。
- 深度拷贝则会递归地拷贝原对象中的每一个子对象,因此拷贝后的对象和原对象互不相关。另外,深度拷贝中会维护一个字典,记录已经拷贝的对象及其ID,来提高效率并防止无限递归的发生。
第二部分是Python的变量及其赋值的基本原理,并且解释了Python中参数是如何传递的。和其他语言不同的是,Python中参数的传递既不是值传递,也不是引用传递,而是赋值传递,或者是叫对象的引用传递。
需要注意的是,这里的赋值或对象的引用传递,不是指向一个具体的内存地址,而是指向一个具体的对象。
- 如果对象是可变的,当其改变时,所有指向这个对象的变量都会改变。
- 如果对象不可变,简单的赋值只能改变其中一个变量的值,其余变量则不受影响。
清楚了这一点,如果你想通过一个函数来改变某个变量的值,通常有两种方法。一种是直接将可变数据类型(比如列表,字典,集合)当作参数传入,直接在其上修改;第二种则是创建一个新变量,来保存修改后的值,然后将其返回给原变量。在实际工作中,我们更倾向于使用后者,因为其表达清晰明了,不易出错。
第三部分是装饰器,所谓的装饰器,其实就是通过装饰器函数,来修改原函数的一些功能,使得原函数不需要修改。
Decorators is to modify the behavior of the function through a wrapper so we don’t have to actually modify the function.
而实际工作中,装饰器通常运用在身份认证、日志记录、输入合理性检查以及缓存等多个领域中。合理使用装饰器,往往能极大地提高程序的可读性以及运行效率。
第四部分介绍了四种不同的对象,分别是容器、可迭代对象、迭代器和生成器。
- 容器是可迭代对象,可迭代对象调用 iter() 函数,可以得到一个迭代器。迭代器可以通过 next() 函数来得到下一个元素,从而支持遍历。
- 生成器是一种特殊的迭代器(注意这个逻辑关系反之不成立)。使用生成器,你可以写出来更加清晰的代码;合理使用生成器,可以降低内存占用、优化程序结构、提高程序速度。
- 生成器在 Python 2 的版本上,是协程的一种重要实现方式;而 Python 3.5 引入 async await 语法糖后,生成器实现协程的方式就已经落后了。
第五部分我们通过解读YAML的源码,围绕metaclass的设计本意“超越变形”,解析了metaclass的使用场景和使用方法。接着,我们又进一步深入到Python语言设计层面,搞明白了metaclass的实现机制。
第六部分我们介绍了上下文管理器与with语句,我们先通过一个简单的例子,了解了资源泄露的易发生性,和其带来的严重后果,从而引入了应对方案——即上下文管理器的概念。上下文管理器,通常应用在文件的打开关闭和数据库的连接关闭等场景中,可以确保用过的资源得到迅速释放,有效提高了程序的安全性,
接着,我们通过自定义上下文管理的实例,了解了上下文管理工作的原理,并一起学习了基于类的上下文管理器和基于生成器的上下文管理器,这两者的功能相同,具体用哪个,取决于你的具体使用场景。
另外,上下文管理器通常和with语句一起使用,大大提高了程序的简洁度。需要注意的是,当我们用with语句执行上下文管理器的操作时,一旦有异常抛出,异常的类型、值等具体信息,都会通过参数传入 “__exit__()” 函数中。你可以自行定义相关的操作对异常进行处理,而处理完异常后,也别忘了加上 “return True” 这条语句,否则仍然会抛出异常。
第七部分则是一个比较重要的概念:协程。我从一个简单的爬虫开始,到一个真正的爬虫结束,在中间穿插讲解了 Python 协程最新的基本概念和用法。这里带你简单复习一下。
- 协程和多线程的区别,主要在于两点,一是协程为单线程;二是协程由用户决定,在哪些地方交出控制权,切换到下一个任务。
- 协程的写法更加简洁清晰,把async / await 语法和 create_task 结合来用,对于中小级别的并发需求已经毫无压力。
- 写协程程序的时候,你的脑海中要有清晰的事件循环概念,知道程序在什么时候需要暂停、等待 I/O,什么时候需要一并执行到底。
第八部分,我们首先学习了Python中并发和并行的概念与区别。
- 并发,通过线程和任务之间互相切换的方式实现,但同一时刻,只允许有一个线程或任务执行。
- 而并行,则是指多个进程同时执行。
并发通常用于I/O操作频繁的场景,而并行则适用于CPU heavy的场景。
随后,我们通过下载网站内容的例子,比较了单线程和运用Futures的多线程版本的性能差异。显而易见,合理地运用多线程,能够极大地提高程序运行效率。
我们还一起学习了Futures的具体原理,介绍了一些常用函数比如done()、result()、as_completed()等的用法,并辅以实例加以理解。
要注意,Python中之所以同一时刻只允许一个线程运行,其实是由于全局解释器锁的存在。但是对I/O操作而言,当其被block的时候,全局解释器锁便会被释放,使其他线程继续执行。
第九部分,我们一起学习了Asyncio的原理和用法,并比较了Asyncio和多线程各自的优缺点。
不同于多线程,Asyncio是单线程的,但其内部event loop的机制,可以让它并发地运行多个不同的任务,并且比多线程享有更大的自主控制权。
Asyncio中的任务,在运行过程中不会被打断,因此不会出现race condition的情况。尤其是在I/O操作heavy的场景下,Asyncio比多线程的运行效率更高。因为Asyncio内部任务切换的损耗,远比线程切换的损耗要小;并且Asyncio可以开启的任务数量,也比多线程中的线程数量多得多。
但需要注意的是,很多情况下,使用Asyncio需要特定第三方库的支持,比如前面示例中的aiohttp。而如果I/O操作很快,并不heavy,那么运用多线程,也能很有效地解决问题。
第十部分则是讲解了GIL对于应用的影响,之后我们适度剖析了GIL的实现原理,你不必深究一些原理的细节,明白其主要机制和存在的隐患即可。我也为你提供了绕过GIL的两种思路,但是,很多时候,我们并不需要过多纠结GIL的影响
文章最后,我们深入了解了Python 的垃圾回收机制,有以下几点需要注意:
- 垃圾回收是 Python 自带的机制,用于自动释放不会再用到的内存空间;
- 引用计数是其中最简单的实现,不过切记,这只是充分非必要条件,因为循环引用需要通过不可达判定,来确定是否可以回收;
- Python 的自动回收算法包括标记清除和分代收集,主要针对的是循环引用的垃圾收集;
- 调试内存泄漏方面, objgraph 是很好的可视化分析工具。
本文由 mdnice 多平台发布