Spark SQL编程之DataFrame
Spark SQL
特性
- 易整合
- 统一的数据访问方式
- 兼容hive
- 标准的数据链接
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象:DataFrame和DataSet,并且作为分布式SQL查询引擎的作用
SparkSession创建
在老的版本中,SparkSQL提供两种SQL查询起始点:一个叫SQLContext,用于Spark自己提供的SQL查询;一个叫HiveContext,用于连接Hive的查询。
SparkSession是Spark最新的SQL查询起始点(2.0.0版本之后),实质上是SQLContext和HiveContext的组合,所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的
val builder = SparkSession.builder().master("local")
val session: SparkSession = builder.getOrCreate()
session.sparkContext.getConf.setMaster("local")DataFrame
DataFrame是一个分布式数据容器,然而DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从API易用性的角度上看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低
DataFrame创建
PS: 下面为操作的数据源(可以自己造数据测试)
[{"name":"朱元璋","age":41},{"name":"朱允文","age":22},{"name":"朱棣","age":43},{"name":"朱高炽","age":47},{"name":"朱瞻基","age":28},{"name":"朱祁镇","age":9},{"name":"朱祁钰","age":22},{"name":"朱见深","age":18},{"name":"朱佑橖","age":18},{"name":"朱厚照","age":15},{"name":"朱厚熜","age":18},{"name":"朱翊钧","age":10},{"name":"朱常洛","age":39},{"name":"朱由校","age":16},{"name":"朱由检","age":18}] //可以使用绝对路径,也可以使用相对路径
val rdd: sql.DataFrame = session.read.option("multiLine", true)//多行载入
.json("scala-demo\\src\\main\\scala\\com\\example\\scala\\rdd\\emperor.json")展示数据及schema
rdd.show()
rdd.printSchema()创建临时表
注意:临时表是Session范围内的,Session退出后,表就失效了
//临时表创建
rdd.createOrReplaceTempView("emperor")创建全局表
注意:如果想应用范围内有效,可以使用全局表。使用全局表时需要全路径访问,如:global_temp.people
//全局表创建
rdd.createGlobalTempView("emperor")sql编写(常用)
// 默认不加任何前缀
// val rdd = session.sql("select name,age from emperor")
// 增加临时前缀
// val rdd = session.sql("select name,age from tem.emperor")
// 增加全局前缀
val sql1 = session.sql("select name,age from global_temp.emperor")
// 直接进行sql运算
val sql2 = session.sql("select name,age+1 as age from global_temp.emperor")
// 分组sql
val sql3 = session.sql("select age ,count(1) from global_temp.emperor group by age")api接口(较常用)
def testSqlApi(session: SparkSession) = {
//需要在方法中导入该扩展功能才能使用$"xxx"的方式
import session.implicits._
val df = session.read.option("multiLine", true).json("scala-demo\\src\\main\\scala\\com\\example\\scala\\rdd\\emperor.json")
//df.printSchema()
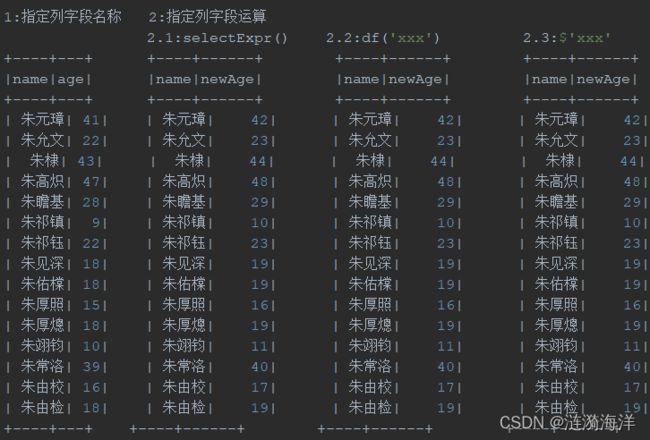
println("1.1: 指定列字段名称select()方式")
df.select("name", "age").show()
println("1.2:指定列字段名称selectExpr()方式")
df.selectExpr("name", "age+1").show()
// 1.6.0之前的写法
println("1.3:指定列字段名称df('xxx')方式")
df.select(df("name"), df("age") + 1).show()
println("1.4:指定列字段名称$'xxx'方式")
// 2.1.0版本之后的写法
df.select($"name", $"age" + 1).show()
println("2.指定列字段名称")
df.filter("age>25").show()
df.filter($"age" > 25).show()
println("3.分组求个数")
df.groupBy("age").count().show()
println("4.指定字段的运算")
}执行查询结果
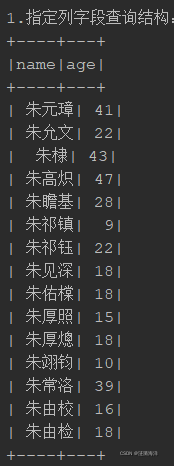
println("1.指定列字段查询结构: ")
sql1.show()
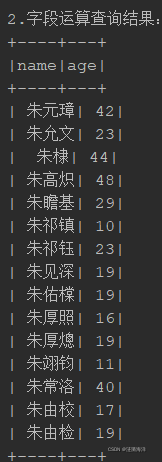
println("2.字段运算查询结果: ")
sql2.show()
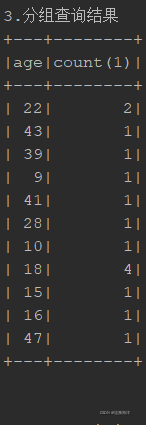
println("3.分组查询结果")
sql3.show()结果输出 (sql)
结果输出(api)

RDD转换成DataFrame
PS:如果需要RDD与DF或者DS之间操作需要引入包
import session.implicits._
源文件
ming.txt
朱元璋 41
朱允文 22
朱棣 43
朱高炽 47
朱瞻基 28
朱祁镇 9
朱祁钰 22
朱见深 18
朱佑橖 18
朱厚照 15
朱厚熜 18
朱翊钧 10
朱常洛 39
朱由校 16
朱由检 18 def testTransfer(session: SparkSession) = {
import session.implicits._
val pRdd = session.sparkContext.textFile("D:\\Java\\workspace\\study\\scala-demo\\src\\main\\scala\\com\\example\\scala\\rdd\\ming.txt")
println("rdd转换成df")
val eRdd: sql.DataFrame = pRdd.map(x => {
val emperor = x.split(" ")
(emperor(0), emperor(1))
}).toDF("name", "age")
eRdd.createGlobalTempView("emperor")
session.sql("select name,age from global_temp.emperor where age > 40").show()
}rdd转换成df
+----+---+
|name|age|
+----+---+
| 朱元璋| 41|
| 朱棣| 43|
| 朱高炽| 47|
+----+---+DataFrame转换成 RDD
DataFrame对象中内置属性rdd,可以直接通过该属性获取RDD
val rdd = eRdd.rdd
println("df转换成rdd")
rdd.collect().foreach(x => print(x) + ", ")## 输出
[朱元璋,41][朱允文,22][朱棣,43][朱高炽,47][朱瞻基,28][朱祁镇,9][朱祁钰,22][朱见深,18][朱佑橖,18][朱厚照,15][朱厚熜,18][朱翊钧,10][朱常洛,39][朱由校,16][朱由检,18]