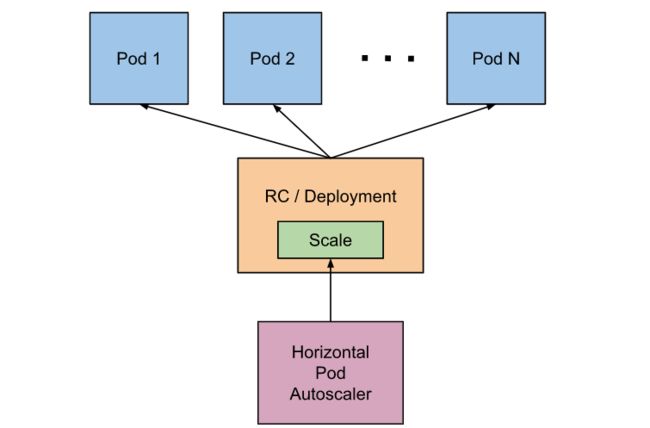
一、概述
Pod 水平自动扩缩(Horizontal Pod Autoscaler)简称 HPA,HPA 可以根据 CPU 利用率进行自动伸缩 Pod 副本数量,除了 CPU 利用率,也可以基于其他应程序提供的自定义度量指标来执行自动扩缩。
通过 HPA 可以达到某个时刻业务请求量很大的时候,不需要我们人工去干涉,它会根据我们设定的指标来进行自动伸缩 Pod 数量来应付访问量。

二、安装Metrics-Server
Heapster 官方在v1.11中已经被废弃,Heapster 监控数据可用,但 HPA 不再从 Heapster 拿数据,所以就不能满足我们本次实验。
Kubernetes 版本为 v1.2 或更高采用 Metrics-Server 来获取监控数据, HPA 根据此 Metrics API 来获取度量数据,所以本次实验需要安装 Metrics-Server 插件。
2.1 下载YAML文件,修改配置
Metrics-Server GitHub 链接:
https://github.com/kubernetes-sigs/metrics-server
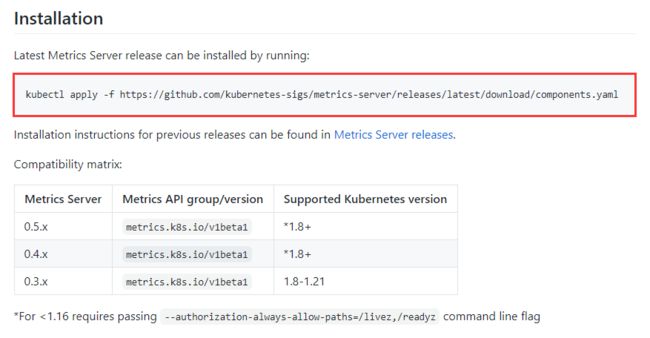
由于我的环境 K8s 版本是 1.21,直接安装最新的 Metrics-Server 即可。
我们需要下载components.yaml下载到本地,添加- --kubelet-insecure-tls到配置文件中,否则会报错
[root@k8s-master01 ]# wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml如果 Linux 操作系统一直无法下载,可以尝试在 Windows 上的迅雷下载好上传。
打开components.yaml添加如下配置:
- --kubelet-insecure-tls
# kubelet 的10250端口使用的是https协议,连接需要验证tls证书,--kubelet-insecure-tls不验证客户端证书。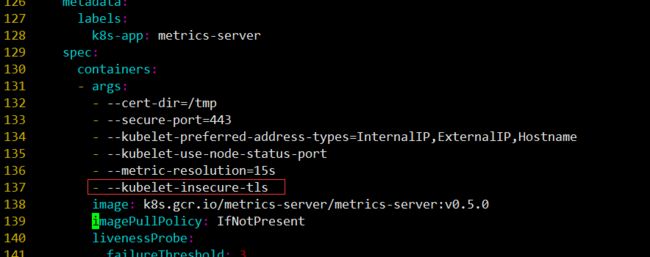
2.2 注意事项
如果不添加- --kubelet-insecure-tls ,可能会出现如下报错
查看 metrics-server-xxx-xxx 详细事件时发现报错如下:
[root@k8s-master01 ~]# kubectl describe pod metrics-server-xxx-xxx -n kube-system
我们在查看该 Pod 详细日志,报错如下:
[root@k8s-master01 ~]# kubectl logs -n kube-system metrics-server-6dfddc5fb8-f8gnd
...
I0531 07:57:33.049547 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
I0531 07:57:43.049460 1 server.go:188] "Failed probe" probe="metric-storage-ready" err="not metrics to serve"
E0531 07:57:44.458989 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.115.11:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.115.11 because it doesn't contain any IP SANs" node="k8s-master01"
E0531 07:57:44.472464 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.115.13:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.115.13 because it doesn't contain any IP SANs" node="k8s-node02"
E0531 07:57:44.478313 1 scraper.go:139] "Failed to scrape node" err="Get \"https://192.168.115.12:10250/stats/summary?only_cpu_and_memory=true\": x509: cannot validate certificate for 192.168.115.12 because it doesn't contain any IP SANs" node="k8s-node01"
2.3 手动下载镜像
由于k8s.gcr.io在国外,导致无法下载metrics-server镜像问题。
当我们查看 Pod 状态是发现为ImagePullBackOff
[root@k8s-master01 ~]# kubectl get pod -n kube-system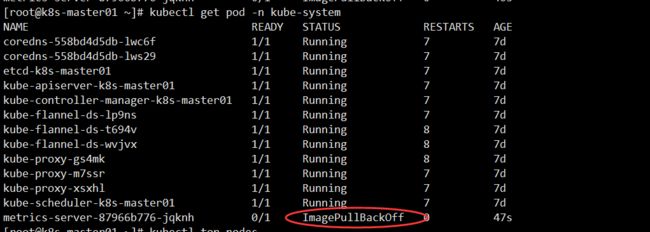
查看 metrics-server-xxx-xxx 详细事件时发现报错如下:
[root@k8s-master01 ~]# kubectl describe pod metrics-server-xxx-xxx -n kube-system
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 4m1s default-scheduler Successfully assigned kube-system/metrics-server-87966b776-jqknh to k8s-node01
Normal Pulling 106s (x4 over 4m) kubelet Pulling image "k8s.gcr.io/metrics-server/metrics-server:v0.5.0"
Warning Failed 91s (x4 over 3m45s) kubelet Failed to pull image "k8s.gcr.io/metrics-server/metrics-server:v0.5.0": rpc error: code = Unknown desc = Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
Warning Failed 91s (x4 over 3m45s) kubelet Error: ErrImagePull
Warning Failed 76s (x6 over 3m45s) kubelet Error: ImagePullBackOff
Normal BackOff 61s (x7 over 3m45s) kubelet Back-off pulling image "k8s.gcr.io/metrics-server/metrics-server:v0.5.0"
需要手动下载镜像再进行改名(每个节点都需要下载)
[root@k8s-master01 ~]# docker pull bitnami/metrics-server:0.5.0
[root@k8s-master01 ~]# docker tag bitnami/metrics-server:0.5.0 k8s.gcr.io/metrics-server/metrics-server:v0.5.0
注意:当你看到这篇笔记的时候,可能镜像已经更新了,根据报错提示来下载即可。
2.4 开始创建 Metrics-Server
只需要在 K8s-master 节点创建即可!
[root@k8s-master01 ~]# kubectl apply -f components.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created查看 Pod 状态发现已经 Running
[root@k8s-master01 ~]# kubectl get pod -n kube-system
检查 Metrics Server
[root@k8s-master01 ~]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master01 119m 5% 1198Mi 64%
k8s-node01 29m 1% 476Mi 25%
k8s-node02 32m 1% 433Mi 23%在 K8s Dashboard 界面查看资源使用情况
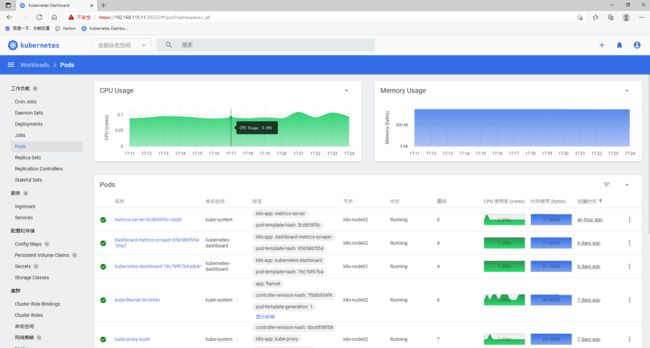
三、创建 HPA 测试案例
创建一个Deployment管理的Nginx Pod,然后利用HPA来进行自动扩缩容。
定义Deployment的YAML文件如下:(hap-deploy-demo.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-nginx-deploy
spec:
selector:
matchLabels:
run: hpa-nginx-deploy
replicas: 1
template:
metadata:
labels:
run: hpa-nginx-deploy
spec:
containers:
- name: nginx
image: hub.test.com/library/mynginx:v1 # 镜像地址
ports:
- containerPort: 80
resources:
limits: # 最大限制
cpu: 500m # CPU最大是500微核
requests: # 最低保证
cpu: 200m # CPU最小是200微核在test命名空间创建Deployment:
[root@k8s-master01 hpa-test]# kubectl create -f hpa-deploy-demo.yaml -n test
deployment.apps/hpa-nginx-deploy created-n test 指定命名空间
查看 Pod 、Deployment 状态
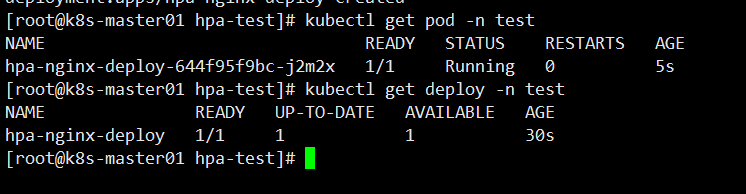
创建一个HPA,可以使用kubectl autoscale命令来创建:
[root@k8s-master01 ~]# kubectl autoscale deployment hpa-nginx-deploy --cpu-percent=20 --min=1 --max=10 -n test
horizontalpodautoscaler.autoscaling/hpa-nginx-deploy autoscaled--cpu-percent=20 HPA 会通过 Pod 伸缩保持平均 CPU 利用率在20%以内;
--min=1 --max=10 允许 Pod 伸缩范围,最小的 Pod 副本数为1,最大为10;
也可以使用 YAML 进行 HPA 编写更为详细的设置。
查看 HPA 当前状态
[root@k8s-master01 hpa-test]# kubectl get hpa -n test
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-nginx-deploy Deployment/hpa-nginx-deploy 0%/20% 1 10 1 37m
当前的 CPU 利用率是 0%,由于未发送任何请求到该 Pod。
查看 hpa-nginx-deployPod 的 IP地址
[root@k8s-master01 hpa-test]# kubectl get pod -n test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hpa-nginx-deploy-9f8676f85-57kg8 1/1 Running 0 42m 10.244.1.23 k8s-node01 
3.1 增加负载测试
增大负载进行测试,我们来创建一个busybox,并且循环访问上面创建的服务。
[root@k8s-master01 ~]# kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while true; do wget -q -O- http://10.244.1.23; done" -n test
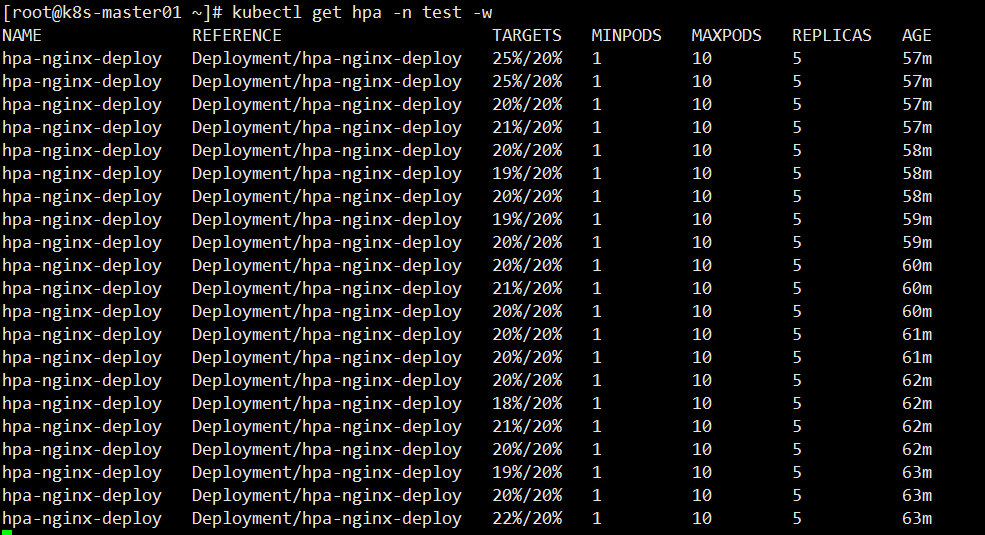
等待一小会,查看 HPA 负载情况,当前 CPU 使用率 49% 已经超出设置值
[root@k8s-master01 ~]# kubectl get hpa -n test -w
此时来查看deployment Pod 副本数量,由原来的1个自动扩容到5个
[root@k8s-master01 ~]# kubectl get deployment hpa-nginx-deploy -n test -w
再次查看 HPA 负载情况,可以看到一直保持在 20% 以内
3.2 停止负载测试
在刚刚创建 busybox 容器的终端中,输入
等待一会,查看 HPA 负载情况和 Deployment Pod副本数是否到达收缩功能
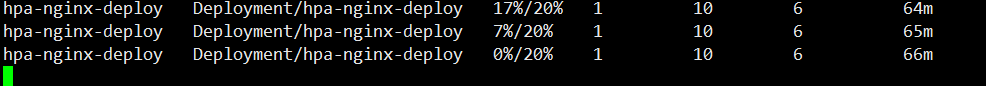
这是 Dashboard 界面情况,已经过去一两分钟了,还没见收缩,再等等
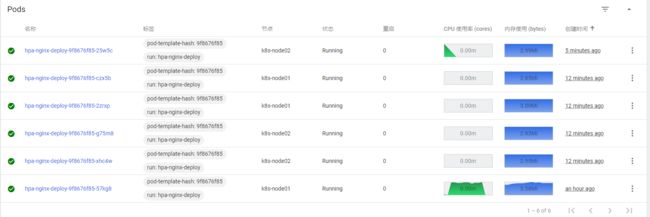
此时我们可以看到 Pod 副本数已经被收缩了,因为 CPU 使用率为 0,所以只保留最小副本数1个 Pod 对外提供服务

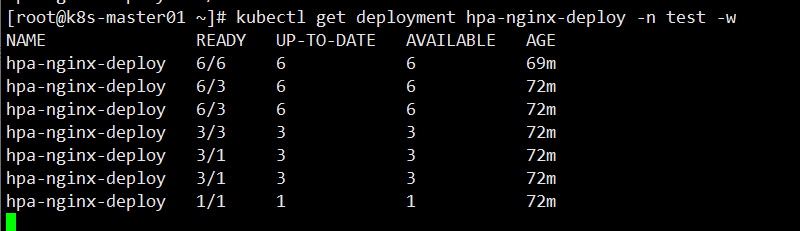
收缩的过程可能要等待几分钟;
通过上图可以看到,Pod 副本数不是一下子回收,而是逐步的回收机制。
这是 Dashboard 界面情况

到此 Pod 水平自动扩缩测试就到此结束了,HPA 不仅仅这些,还有多项度量指标和自定义度量指标自动扩缩等策略等着你去实践。