RabbitMQ 升级到 3.8 后,消息触发重新排队和投递?
现象
原本我们线上用的 RabbitMQ 版本为 3.3.5,是比较老的版本了。升级到 3.8.27 后,出现了奇怪的 bug。
部分消息无法消费,再不断触发重新投递。
配置
来说说我们线上的配置
-
开启消息应答机制(Message Confirm),也就是手动确认。消费者必须回应 basic_ack,Broker 才会删除消息。这也是保证消息不丢失的基本操作。
-
开启预取(basic_qos)
由于 RabbitMQ 会将指定数量的消息(perfetch_count)预取到消费者。
线上通常建议加上此配置,RabbitMQ 默认行为是尽可能的将消息分送给消费者。如果消费者处理不过来,大量的消息将处于 unack 状态。而 unack 消息必须在内存中,可能因内存不足导致 OOM 或卡顿。
分析
部分任务执行时间是比较长的,具体时间没有统计过。十几分钟是有的。
但 RabbitMQ 3.3.5 却没有问题,3.8.27 却有问题。于是在想 是否新版 MQ 调整了默认行为。
从表象来看,像消费者处理消息多了超时时间,从而触发 重新入队(ReQueue) 和 重新投递 (Re Delivery)
经过查询。果然,在官方文档发下了一段话。
In modern RabbitMQ versions, a timeout is enforced on consumer delivery acknowledgement. This helps detect buggy (stuck) consumers that never acknowledge deliveries. Such consumers can affect node’s on disk data compaction and potentially drive nodes out of disk space.
If a consumer does not ack its delivery for more than the timeout value (30 minutes by default), its channel will be closed with a PRECONDITION_FAILED channel exception. The error will be logged by the node that the consumer was connected to. All outstanding deliveries on that channel, from all consumers, will be requeued.
现代 RabbitMQ 集群,开始支持 consumer_timeout(消费者超时),默认 30 分钟。超过该时间,消息将重新入队。
基本可以认为是这个问题了。
老版本的 MQ 没有该配置,默认行为不超时。而新版默认超时会重新入队,导致重新投递消费。
除此之外,按理说我们的任务量不大,也只有个别执行时间较长,理论也不会突破 30 分钟限制。
前面提到了预取 basic_qos,一个进程每次取 50 个,而这 50 个是按顺序执行的。举个例子,如果前 40 个执行时间超过 30 分钟,那么最后 10 个会触发重新排队。
实验
先做个实验,消费者收到消息后 sleep 一小时,看是否会触发重新投递。
producer
import pika
class Producer:
def __init__(self):
params = pika.ConnectionParameters()
connection = pika.BlockingConnection(params)
self._channel = connection.channel()
def publish(self, body):
self._channel.queue_declare('queue1')
self._channel.exchange_declare('queue1')
self._channel.queue_bind('queue1', 'queue1')
self._channel.basic_publish('queue1', 'queue1', body)
if __name__ == '__main__':
Producer().publish('hello world')
consumer
import pika
import time
class Consumer:
def __init__(self):
params = pika.ConnectionParameters()
connection = pika.BlockingConnection(params)
self._channel = connection.channel()
def start(self):
def on_message_callback(channel, method, properties, body):
print(body)
for i in range(3600):
print(i)
time.sleep(1)
print('回复 ack')
self._channel.basic_ack(method.delivery_tag)
self._channel.basic_qos(prefetch_count=50)
self._channel.basic_consume('queue1', on_message_callback)
self._channel.start_consuming()
if __name__ == '__main__':
Consumer().start()
结果,消息果然从 UnAcked 变为 Ready,进行 ReQueue 了。
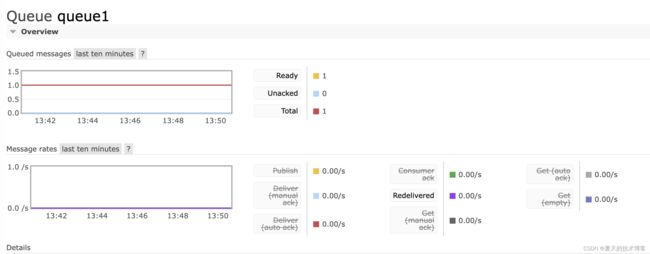
消费者再次接受后,重新排队的消息由于有 Redelivered 标记,所以可以看到下图紫色线有波动。

那么,从哪个版本开始有这个行为呢。
官网略坑,只告诉你现代版本 MQ 有此限制。具体版本号也没说明。
从 issue 来看,该时间调整过多次,具体建议大家根据实际版本进行测试。
简单的方法,可以通过获取环境变量来得到该值
root@my-rabbit:/# rabbitmqctl environment | grep consumer_timeout
{consumer_timeout,1800000},
如何解决
RabbitMQ version >= 3.8.15 后。
- 我们可以在 advanced.config 中配置 consumer_timeout 为 undefined,表示不超时,官方不建议这样配置。
[
{rabbit, [
{consumer_timeout, undefined}
]}
]
- 在 rabbitmq.conf 中根据任务执行时间,调整 consumer_timeout。
# one hour in milliseconds
consumer_timeout = 3600000
其次,需要配置 heartbeat 用来检测、保活 TCP 连接。否则可能空闲连接可能被操作系统 kill 掉。
以 Python 代码为例。
params = pika.ConnectionParameters(heartbeat=600)
补充
除了 consumer_timeout 影响之外,如果你用的是 block_connection,长时间执行的任务,还会受到 heartbeat 影响。
heartbeat 心跳包,默认连续两次收不到,会断开连接
解决方案
- 禁用心跳包,开启 keepalive (不推荐)
- 异步确认心跳包。使用 selectConnection 或者多开启一个线程来确认 heartbeat
参考
在 RabbitMQ 3.8.15 及更高版本中禁用消费者超时
送达确认超时