☀️☀️基于Spark、Hive等框架的集群式大数据分析流程详述
本文目录如下:
- 基于Spark、Hive等框架的集群式大数据分析流程详述
- 第1章 淘宝双11大数据分析—数据准备
-
- 1.1 数据文件准备
- 1.2 数据预处理
- 1.3 启动集群环境
- 1.4 导入数据到 Hive 中
-
- 1.4.1 把目标文件上传到 HDFS 中
- 1.4.2 将数据导入至 Hive 中
- 第2章 淘宝双11大数据分析—Hive 数据分析
-
- 2.1 使用 Hive 语句进行简单查询分析
- 2.2 使用用户自定义函数对数据进行处理
- 第3章 乳腺癌预测—Spark 数据分析
-
- 3.1 把目标文件上传到 HDFS 中
- 3.2 在 MySQL 中创建表, 用于存储预测结果
- 3.3 使用 Spark ML 训练数据集生成模型
基于Spark、Hive等框架的集群式大数据分析流程详述
注: 本文结构一部分参照于: 淘宝双11大数据分析 , 并深度结合了博主所学的知识,旨在描述一个 集群式大数据分析 流程,类似于一个工具类博客,方面日后进行开发。但这里不会对每个技术进行讲解,下面是一些关于文章内用到的技术的学习专栏:
- Hadoop 生态环境搭建与运行 (环境搭建)
- HDFS 学习笔记
- Scala 学习笔记
- Spark 学习笔记
- Spark SQL 学习笔记
- Hive 学习笔记
- Zookeeper 学习笔记
- Spark ML 学习笔记
- Spark 学习成果转化
- Sqoop的安装、配置与使用
可能用到的一些其他博主的文章:
…
第1章 淘宝双11大数据分析—数据准备
1.1 数据文件准备
- (1) 下载数据文件
百度云盘链接: 点击前往下载: 提取码: 0819
- (2) 将数据文件上传至
hadoop100主机 (Linux虚拟机)
首先创建文件夹 /opt/data/, 将数据文件压缩包 data_format.zip 放入其中, 然后将该压缩包解压至 /opt/data/taobao_data 文件夹中,执行命令如下:
[xqzhao@hadoop100 data]$ unzip data_format.zip -d taobao_data/
# 解压成功之后的文件
[xqzhao@hadoop100 taobao_data]$ ll
-rw-rw-r--. 1 xqzhao xqzhao 129452503 Mar 2 2017 test.csv
-rw-rw-r--. 1 xqzhao xqzhao 129759806 Mar 2 2017 train.csv
-rw-rw-r--. 1 xqzhao xqzhao 2598392805 Feb 23 2017 user_log.csv
注: 解压后文件大小约为 2.8G。由于数据文件比较大, 因此解压过程可能需要一定的时间。
1.2 数据预处理
- (1) 去除文件头部信息 (第一行)
通过查看文件前 5 行发现文件第一行是数据信息:

执行下列命令将文件第 1 行删除 (1d 代表第一行):
[xqzhao@hadoop100 taobao_data]$ sed -i '1d' user_log.csv
- (2) 截取文件
执行下述命令查看 user_log.csv 文件一共有多少行:
[xqzhao@hadoop100 taobao_data]$ wc -l user_log.csv
54925331 user_log.csv
可以看到 user_log.csv 文件中一共包含约 5500万 条数据, 这里我们只需要 10万 行即可。
执行下列命令,取文件 user_log.csv 中的前 10万 行数据并放入 user_log_l.csv 文件中:
[xqzhao@hadoop100 taobao_data]$ head -100000 user_log.csv > user_log_l.csv
1.3 启动集群环境
- 在进行下一步操作之前, 需要先启动集群环境, 具体步骤可参考: 基于 Hive 的 SparkSQL 启动流程 (启动
Spark之前需要启动Zookeeper)。 - 这里我们使用的是
Spark的 伪分布式模式。 - 集群启动完成之后,系统中的 进程 应如下图所示:

1.4 导入数据到 Hive 中
1.4.1 把目标文件上传到 HDFS 中
- (1) 执行下列命令在
HDFS上创建文件夹。
[xqzhao@hadoop100 opt]$ hdfs dfs -mkdir -p /workplace/data/taobao_data/user_log
- (2) 执行下列命令将文件
user_log_l.csv上传至创建的文件夹中。
[xqzhao@hadoop100 opt]$ hdfs dfs -put /opt/data/taobao_data/user_log_l.csv /workplace/data/taobao_data/user_log
- (3) 通过
HDFS的图形化界面, 我们可以看到上传的文件user_log_l.csv。

1.4.2 将数据导入至 Hive 中
- (1) 启动
Hive:
启动 Hive 的操作可以参考: 基于 Hive 的 SparkSQL 启动流程 中第 1.6小节 的描述 (交互式启动)。
- (2) 在 Hive 中创建数据库
dbtaobao:
hive (default)> create database dbtaobao;
OK
Time taken: 1.567 seconds
hive (default)> use dbtaobao;
OK
Time taken: 0.049 seconds
- (3) 在 dbtaobao 中创建一个外部表
user_log:
create external table user_log(
user_id INT,
item_id INT,
cat_id INT,
merchant_id INT,
brand_id INT,
month STRING,
day STRING,
action INT,
age_range INT,
gender INT,
province STRING
) row format delimited fields terminated by ',';
各个字段的含义请参考: 【淘宝双11大数据分析 (数据准备篇)】 中进行查看。
- (4) 加载
HDFS文件到hive(文件在HDFS)
加载 HDFS 上数据
hive (default)> load data inpath '/workplace/data/taobao_data/user_log/user_log_l.csv' into table user_log;
注: 当然也可以选择直接使用本地上传,而不用先上传至 HDFS, 这样做是为了使流程更标准一些。具体的文件加载方式等知识可以参考: Hive基础—DDL 数据定义—创建表(重要)、修改表、删除表 中第 4.5小节 的描述。
第2章 淘宝双11大数据分析—Hive 数据分析
2.1 使用 Hive 语句进行简单查询分析
- (1) 查询
user_log表中的数据总数
hive (dbtaobao)> select count(*) from user_log;
100000
- (2) 查看
user_log表中的前 10 条数据
hive (dbtaobao)> select * from user_log limit 10;
user_log.user_id user_log.item_id user_log.cat_id user_log.merchant_id user_log.brand_id user_log.month user_log.day user_log.action user_log.age_range user_log.gender user_log.province
328862 323294 833 2882 2661 08 29 0 0 1 内蒙古
328862 844400 1271 2882 2661 08 29 0 1 1 山西
328862 575153 1271 2882 2661 08 29 0 2 1 山西
328862 996875 1271 2882 2661 08 29 0 1 1 内蒙古
328862 1086186 1271 1253 1049 08 29 0 0 2 浙江
328862 623866 1271 2882 2661 08 29 0 0 2 黑龙江
328862 542871 1467 2882 2661 08 29 0 5 2 四川
328862 536347 1095 883 1647 08 29 0 7 1 吉林
328862 364513 1271 2882 2661 08 29 0 1 2 贵州
328862 575153 1271 2882 2661 08 29 0 0 0 陕西
- (3) 查询双11当天订单成交量
hive (dbtaobao)> select count(*) from user_log where action='2' AND month=11 AND day=11;
2552
- (4) 查询购物数量前三的省份
select num, province from (
select count(*) num, province from user_log where action='2' group by province
) t1 order by num desc limit 3;
# 注: t1 是必须的,不加 t1 会报错
num province
241 贵州
231 湖北
220 宁夏
2.2 使用用户自定义函数对数据进行处理
有兴趣的同学可以参考博主之前写的两个案例:
- (1) 各区域热门商品 Top3: 【点击跳转】, 效果图如下:
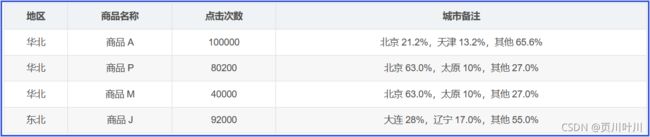
- (2) 各职业人群贷款目的Top3: 【点击跳转】, 效果图如下:

上面两个案例查询结果中的 城市备注 与 贷款目的备注 是无法通过简单地连接查询就可以得到的,必须通过 SparkSQL 中提供的 用户自定义函数 来完成。关于 用户自定义函数 (UDAF) 的知识点可以参考: SparkSQL—用户自定义函数—UDF、UDAF 中第 2.7.2小节 中的第 (3) 点的描述。
第3章 乳腺癌预测—Spark 数据分析
3.1 把目标文件上传到 HDFS 中
- (1) 执行下列命令将文件
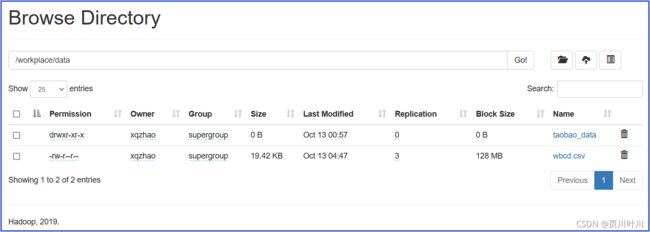
wbcd.csv上传至文件夹/workplace/data中。
[xqzhao@hadoop100 opt]$ hdfs dfs -put /opt/data/ruxian_data/wbcd.csv /workplace/data/wbcd.csv
文件中各个字段的含义请参考: 【使用Spark ML的逻辑回归来预测乳腺癌】 中第 2.1.2小节 进行查看。
在文件系统中可以看到上传的文件:
3.2 在 MySQL 中创建表, 用于存储预测结果
- (1) 首先打开
MySQL客户端
[xqzhao@hadoop100 module]$ mysql -uroot -p123456
...
mysql>
- (2) 创建
dbtaobao数据库
mysql> create database workplace;
# 选择`dbtaobao` 数据库
mysql> use workplace;
- (3) 创建
rebuy表
mysql> create table ruxian (score varchar(40),label varchar(40));
3.3 使用 Spark ML 训练数据集生成模型
package com.xqzhao.scala.spark.disease
import org.apache.spark.SparkConf
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{StringIndexer, VectorAssembler}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object Spark01_ML_Disease {
def main(args: Array[String]): Unit = {
// TODO 创建 Spark SQL 的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkML")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
// 对数据进行初步筛选, 将字符串划分成单词、筛选掉一些不符合要求的数据、去掉一些用不到的列
def parseRDD(rdd: RDD[String]): RDD[Array[Double]] = {
rdd.map(_.split(",")).filter(_(6) != "?").map(_.drop(1)).map(_.map(_.toDouble))
} // (0,1,2,3,4,5,6,7,8,9,10) => (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val rdd: RDD[String] = spark.sparkContext.textFile("hdfs://hadoop100:8020/workplace/data/wbcd.csv")
// step 1: 加载并解析数据 (转换后: 0是恶性肿瘤, 1是良性肿瘤)
val cancerRDD: RDD[Cancer] = parseRDD(rdd).map {
line => Cancer(if (line(9) == 4.0) 1 else 0, line(0), line(1), line(2), line(3), line(4), line(5), line(6), line(7), line(8))
} // (1, 2, 3, 4, 5, 6, 7, 8, 9, 10) => (10, 1, 2, 3, 4, 5, 6, 7, 8, 9)
// step 2: 为 ML pipeline 将 RDD 转换为 数据帧
import spark.implicits._
val cancerDF1_1 = cancerRDD.toDF().cache()
cancerDF1_1.show()
// step 3: 特征抽取与转换
val featureCols = Array("thickness", "size", "shape", "madh", "epsize", "bnuc", "bchrom", "nNuc", "mit")
// 将它们合并成为一个特征向量 (VectorAssembler 是一个转换器)
val assembler = new VectorAssembler()
.setInputCols(featureCols)
.setOutputCol("features")
// 接着将其转换为数据帧 (特征向量 features 在数据帧后面单独添加一列)
val cancerDF1_2 = assembler.transform(cancerDF1_1)
cancerDF1_2.show()
// 使用 StringIndexer 为训练集创建 标签 (标签 label 在数据帧后面单独添加一列) (StringIndexer 不是转换器吗? 怎么是评估器)
val labelIndexer = new StringIndexer()
.setInputCol("cancer_class")
.setOutputCol("label")
val cancerDF1_3 = labelIndexer.fit(cancerDF1_2).transform(cancerDF1_2)
cancerDF1_3.show()
// step 4: 创建测试及训练集 (splitSeed 的用处: ???)
val splitSeed = 12345L
val Array(trainingData, testData) = cancerDF1_3.randomSplit(Array(0.7, 0.3), splitSeed)
// step 5: 使用训练集创建评估器 (使用逻辑回归算法为该 pipeline 创建一个评估器)
val lr = new LogisticRegression()
.setMaxIter(50)
.setRegParam(0.01)
.setElasticNetParam(0.01)
val model = lr.fit(trainingData)
// step 6: 为测试集获取原始的 预测结果 及 可能性 (这里输出的都是测试集中的数据吗)
val predictions = model.transform(testData)
predictions.show(100)
spark.close()
}
case class Cancer(cancer_class: Double, thickness: Double, size: Double, shape: Double, madh: Double,
epsize: Double, bnuc: Double, bchrom: Double, nNuc: Double, mit: Double)
}
运行结果如下图所示:
