吴恩达 tensorflow2.0 实践系列课程(3):NLP
tensorflow2.0 中的自然语言处理
基本都是入门级的,而且也正如课程设计目标,主体放在 tensorflow 的基本使用上。围绕的 NLP 相关问题有:
- 文本如何变为数字送入模型进行处理? (word-key/one-hot、embeddings)
- 文本分类怎么做?比如情感分析?贴 label 做分类
- 文本预测怎么做?比如模仿莎士比亚文笔? 这里必须将文本视作序列,所以用 LSTMs。
0 A conversation with Andrew Ng
如何将文本转变为数字来处理?
如果 cat 被表示为某个/串数字,那么 dog 呢?
1.1 Introduction
专注于文本而非图像,并且基于文本模型构建分类器,从情感分析入手。
1.2 Word based encodings
对文字进行编码,比如 ASCII 码,但是这样可以帮助我们理解文字吗?(以下针对英语)
只考虑字母是不可以的,因为字母顺序未包含在编码中。考虑为每个单词编码,算是一个开始。真正使用时,可以调用 API。
1.3 Using APIs
使用的是 keras 下文本预处理的 Tokenizer API。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizer
sentences = [
'I love my dog',
'I love my cat'
]
tokenizer = Tokenizer(num_words=100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(word_index)
输出如下,可以看到主要进行了以下处理:
- 大小写归一化;
- 标点被处理掉了;
- 生成了字典,key 为 word,val 为 index

1.4 Notebook for lesson 1
1.5 Text to sequence
直接使用 Tokenizer 来处理文本,问题就是不整齐 + 未登录词。
from tensorflow.keras.preprocessing.text import Tokenizer
sentences = [
'I love my dog',
'I love my cat',
'You love my dog!',
'Do you think my dog is amazing?'
]
tokenizer = Tokenizer(num_words=100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sentences)
print(word_index)
print(sequences)

当遇到未登录词,会直接略过:
test_data = [
'i really love my dog',
'my dog loves my manatee'
]
test_seq = tokenizer.texts_to_sequences(test_data)
print(test_seq)
# no really
# [[4, 2, 1, 3], [1, 3, 1]]
1.6 Looking more at the Tokenizer
根据前面的结果,可以得到两点结论:
- 需要尽可能多的训练数据来 cover 尽可能多的单词;
- 对于未登录单词,可以用某个标记来处理,而不是直接 ignore。
标记未登录词可以在实例化 Tokenizer 时进行:
tokenizer = Tokenizer(num_word=100, oov_token="" )
未登录词解决以后,下一步要处理的就是文本对齐的问题。
1.7 Padding
需要新增 keras 序列预处理的 pad_sequences。
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
sentences = [
'I love my dog',
'I love my cat',
'You love my dog!',
'Do you think my dog is amazing?'
]
tokenizer = Tokenizer(num_words=100, oov_token="" )
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sentences)
# default pre-padding padding='post'
# default max_len = max length of sequences max_len = 10
# default pre-truncating truncating='post'
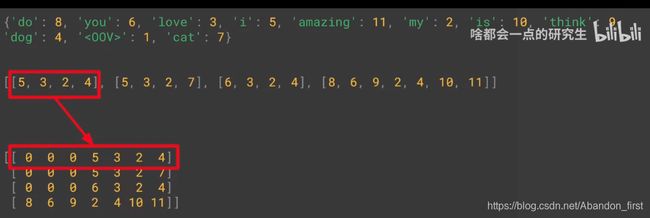
padded = pad_sequences(sequences)
print(word_index)
print(sequences)
print(padded)

1.8 Notebook for lesson 2
1.9 Sarcasm, really
下载 sarcasm 数据集,里面是新闻链接、标题名、和 is_sarcastic label。
1.10 Working with the Tokenizer
用前面的方法,处理这个数据集的标题。
1.11 Notebook for lesson 3
1.12 Week 1 Wrap up
以上,已经解决了将单词转换为数字表示了,下一章会引入 embeddings,然后使用 sarcasm 数据集训练一个分类器。
2.1 A conversation with Andrew Ng
embeddings 能够将单词表征成某个空间中的向量,并且同时携带语义信息,相似的词语会有距离较近的向量,且可以预训练再供他人使用。
总而言之:embeddings 很香、很香还是很香。
2.2 Introduction
只有 Tokenizer 的 word index 不太能携带表达语义信息,使用 embeddings 就可以。embeddings 是从语料库中学习到的,就像从图像中学习到的特征。
2.3 The IMBD dataset
- 50,000 movie reviews
- positive and negative
2.4 Looking into the details
- tf1 需要
tf.enable_eager_execution() - python3
import tensorflow_datasets as tfds
imdb, info = tfds.load("imdb_reviews", with_info=True, as_suoervised=True)
import numpy as np
train_data, test_data = imdb['train'], imdb['test'] # 25000 + 25000
training_sentences = []
training_labels = []
testing_sentences = []
testing_labels = []
for s, l in train_data:
training_sentences.append(str(s.numpy()))
training_labels.append(l.numpy())
for s, l in test_data:
testing_sentences.append(str(s.numpy()))
testing_labels.append(l.numpy())
training_labels_final = np.array(training_labels)
testing_labels_final = np.array(testing_labels)
vocab_size = 10000
embedding_dim = 16
max_length = 120
trunc_type = 'post'
oov_tok = ''
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(training_sentences)
padded = pad_sequences(sequences, maxlen=max_length, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences, maxlen=max_length)
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
2.5 How can we use vectors
在此文本分类任务中,根据 label 以及训练,可以使越来越相近的词向量距离越来越近。
model 中 Embedding 层的输出维度是二维,大小是 lenght of the sentence * embedding dimension。
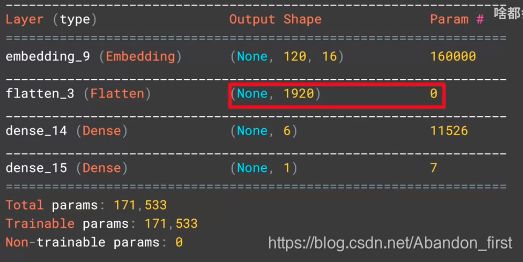
如果使用 tf.keras.layers.GlobalAveragePooling1D() 替换 flatten,输出 16 维度而不是 1920 维度。
overfitting 了:
Flatten:1.0, 0.83, 6.5s per epoch
Global…: 0.9664, 0.8187, 6.2s per epoch
2.6 More into the details
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
num_epochs = 10
model.fit(padded,
training_labels_final,
epochs=num_epoches,
validation_data=(testing_padded, testing_labels_final))
e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape) # (10000, 16)
# 为了可视化 需要 reverse word_index 的 key 和 value
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
import io
out_v = io.open('vexs.tsv', 'w', encoding='utf-8')
out_m = io.open('mata.tsv', 'w', encoding='utf-8')
for word_num in range(1, vacab_size):
word = reverse_word_index[word_num]
embeddings = weights[word_num]
out_m.write(word + "\n")
out_v.write('\t'.join([str(x) for x in embeddings]) + "\n")
out_v.close()
out_m.close()
2.7 Notebook for lesson 1
2.8 Remember the sarcasm dataset
重新回到 sarcasm,有点过拟合。
2.9 Building a classifier for the sarcasm
2.10 Let’s talk about the loss function
调整 embedding 的向量长度、每层的参数,等等各种超参数,可以解决一部分过拟合问题。
2.11 Pre-tokenized datasets
可以不自己进行 tokenized,有些数据集已经做好了 Tokenized,但是基于 sub-word 。

2.12 Diving into the code(part 1)
2.13 Notebook for lesson 3
sub word 训练的结果基本没有效果,二分类概率 50 多,相当于瞎猜。后面会引入 RNN 来解决应该关注序列的哪些位置。
这里的解释是,sub word 没有序列,无法携带对应的信息,需要序列才可以。
3.1 A conversation with Andrew Ng
此前的讨论集中在如何用数字来表述单词,然后对单词进行分类。先是 index 表示一个单词,然后是 embeddings 表示一个单词,继而 embeddings 表示 sub-word。
而单词叠在一起变成句子也就是语言的时候,具体又携带了什么信息?这就需要处理序列。即 RNNs。
3.2 Introduction
以斐波那契数列举例形容 RNN:
There is also an element that’s fed into the function from a previous function.

3.3 LSTMs
I lived in Ireland, so at school they made me learn how to speak Gaelic.
Gaelic 能够被填空,主要看靠前的 Ireland。这种就需要 LSTM 来处理长短期的信息,主要靠它的 cell state。
3.4 Implementing LSTMs in code
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, 64),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)), # 输出 64,双向,所以参数量 加倍
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])

如果要连续用两层,需要设置 return_sequences 为 True,以此来保证第一层的 LSTM 输出与下一层的输入 match。
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, 64),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64), return_sequences=True),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])

3.5 Accuracy and loss
训练过程中的 acc、loss 曲线如果锯齿比较多,意味着需要提升模型性能,比如加一层处理。RNNs 能够帮助处理文本分类,尤其是 unseen word。
3.6 A word from Laurence
LSTMs work with cell state to help keep context in a way that helps with understanding language.
Words that are not immediate neighbors can affect each other’s context.
3.7 Looking into the code
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, embedding_dim, input_length=max_length),
# 此两行被替换为 LSTM
# tf.keras.layers.Flatten(),
# tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
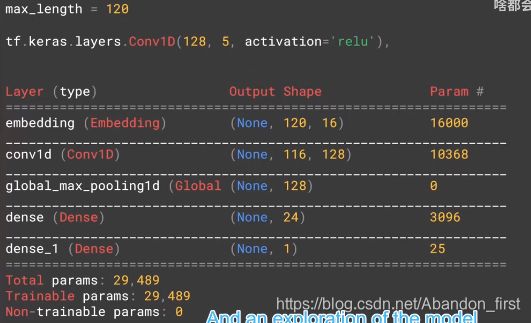
3.8 Using a convolutional network
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, embedding_dim, input_length=max_length),
# 此行被替换为 CNN
# tf.keras.layers.Flatten(),
tf.keras.layers.Conv1D(128, 5, activation='relu'), # 1D 卷积 两边都去掉 2,size -4
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
3.9 Going back to the IMDB dataset
四种方案,都 overfitting。
主框架如下:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, embedding_dim, input_length=max_length),
# 核心处理
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
Flatten
tf.keras.layers.Flatten(),

LSTM
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),

GRU
tf.keras.layers.Bidirectional(tf.keras.layers.GRU(32)),

CNN
tf.keras.layers.Conv1D(128, 5, activation='relu'),
tf.keras.layers.GlobalAveragePooling1D(),

3.10 Tips from Laurence
文本这里可能比图像更容易过拟合,因为测试集中的未登录词汇无法处理,没有获取其意义。
4.1 A conversation with Andrew Ng
讨论 generate texts,比如莎士比亚。
4.2 Introduction
前面章节在讨论分类,现在考虑如何生成/预测文本呢?
比如 twinkle tewinkle little star。
4.3 Looking into the code
tokenizer = Tokenizer()
data = "In the town of Athy one Jeremy Lanigan \n Battered away ......"
corpus = data.lower().split("\n")
tokenizer.fit_on_texts(corpus)
total_words = len(tokenizer.word_index) + 1
4.4 Training the data
input_sequences = []
# line by line
for line in corpus:
# convert to sequence
token_list = tokenizer.texts_to_sequences([line])[0]
# phrase pieces
for i in range(1, len(token_list)):
n_gram_sequences = token_list[:i+1]
input_sequences.append(n_gram_sequence)
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
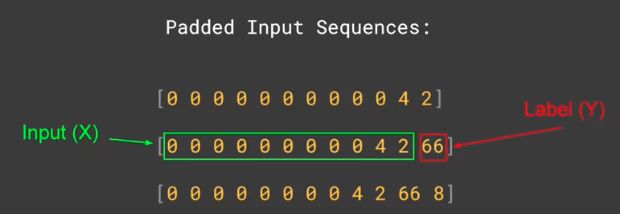
4.5 More on training the data
# the last one is the label
xs = input_sequences[:, : -1]
labels = input_sequences[:, -1]
# create a ont-hot encoding of the labels
# length of ys is the total words
ys = tf.keras.utils.to_categorical(labels, num_classes=total_words)

4.6 Notebook for lesson 1
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
import numpy as np
model = Sequential()
model.add(Embedding(total_words, 64, input_length=max_sequence_len - 1))
model.add(Bidirectional(LSTM(20)))
model.add(Dense(total_words, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(xs, ys, epochs=500, verbose=1)
seed_text = "Laurence went to dublin"
next_words = 100
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len - 1, padding='pre')
predicted = model.predict_classes(token_list, verbose=0)
output_word = ""
for word, index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
seed_text += " " + output_word
print(seed_text)
过拟合。
4.7 Finding what the next word should be
如果将之前模型中的单向 LSTM 改为双向,会好一些吗?
model = Sequential()
model.add(Embedding(total_words, 64, input_length=max_sequence_len - 1))
# model.add(LSTM(20)) # 单向 LSTM
model.add(Bidirectional(LSTM(20))) # 双向 LSTM
model.add(Dense(total_words, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(xs, ys, epochs=500, verbose=1)
4.8 Example
4.9 Predicting a word
4.10 Poetry!
更大的数据集。
model = Sequential()
model.add(Embedding(total_words, 100, input_length=max_sequence_len - 1))
# model.add(LSTM(20)) # 单向 LSTM
model.add(Bidirectional(LSTM(150))) # 双向 LSTM
model.add(Dense(total_words, activation='softmax'))
adam = Adam(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
history = model.fit(xs, ys, epochs=500, verbose=1)