Spark-SQL小结
目录
一、RDD、DataFrame、DataSet的概念、区别联系、相互转换操作
1.RDD概念
2.DataFrame概念
3.DataSet概念
4.RDD、DataFrame、DataSet的区别联系
5.RDD、DataFrame、DataSet的相互转换操作
1 RDD->DataFrame、DataSet
2 DataFrame->RDD,DataSet
3 DataSet->RDD,DataFrame
二、Spark-SQL连接JDBC的方式及代码写法
1.将hive-site.xml复制到spark/spark-local/conf/下
2.将mysql驱动复制到spark-local/jars/下
3.开启spark jdbc 服务
4.连接
三、Spark-SQL连接Hive 的五种方法
1.内嵌的 HIVE
2.外部的 HIVE
3. 运行 spark-beeline
4. Spark-Sql CLI
5. IDEA中操作
5.1 注入依赖
5.2 将hive-site.xml 文件拷贝到项目的 resources 目录中。
5.3 代码实现(IDEA)
5.4运行结果展示
一、RDD、DataFrame、DataSet的概念、区别联系、相互转换操作
1.RDD概念
RDD(Resilient Distributed Datasets) 是 Spark 的核心概念,中文名是弹性数据集,通俗的讲可以理解为是一种抽象的大规模数据集合,或者是一个大的数组,这个数组是分布在集群上的,Spark会在这个数据集合上做一系列的数据处理、计算,然后产生新的RDD,直到最后得到计算结果。
2.DataFrame概念
在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中 的二维表格。DataFrame 与 RDD 的主要区别在于,前者带有 schema 元信息,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型。这使得 Spark SQL 得以洞察更多的结构信息,从而对藏于 DataFrame 背后的数据源以及作用于 DataFrame 之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观 RDD,由于无从得知所存数据元素的具体内部结构,Spark Core 只能在 stage 层面进行简单、通用的流水线优化。
同时,与 Hive 类似,DataFrame 也支持嵌套数据类型(struct、array 和 map)。从 API 易用性的角度上看,DataFrame API 提供的是一套高层的关系操作,比函数式的 RDD API 要 更加友好,门槛更低。
3.DataSet概念
DataSet 是分布式数据集合。DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame 的一个扩展。它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 Spark SQL 优化执行引擎的优点。DataSet 也可以使用功能性的转换(操作 map,flatMap,filter 等等)
➢ DataSet 是 DataFrame API 的一个扩展,是 SparkSQL 最新的数据抽象
➢ 用户友好的 API 风格,既具有类型安全检查也具有 DataFrame 的查询优化特性;
➢ 用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到 DataSet 中的字段名称;
➢ DataSet 是强类型的。比如可以有 DataSet[Car],DataSet[Person]。
➢ DataFrame 是 DataSet 的特列,DataFrame=DataSet[Row] ,所以可以通过 as 方法将 DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些的类型一样,所有的表结构信息都用 Row 来表示。获取数据时需要指定顺序。
4.RDD、DataFrame、DataSet的区别联系
(1)Spark版本
- RDD – 自Spark 1.0起
- DataFrames – 自Spark 1.3起
- DataSet – 自Spark 1.6起
(2)数据表示形式
RDD:RDD是分布在集群中许多机器上的数据元素的分布式集合。 RDD是一组表示数据的Java或Scala对象。
DataFrame:DataFrame是命名列构成的分布式数据集合。 它在概念上类似于关系数据库中的表。
Dataset:它是DataFrame API的扩展,提供RDD API的类型安全,面向对象的编程接口以及Catalyst查询优化器的性能优势和DataFrame API的堆外存储机制的功能。
(3)数据格式
RDD:它可以轻松有效地处理结构化和非结构化的数据。 和Dataframe和DataSet一样,RDD不会推断出所获取的数据的结构类型,需要用户来指定它。
DataFrame:仅适用于结构化和半结构化数据。 它的数据以命名列的形式组织起来。
Dataset:它也可以有效地处理结构化和非结构化数据。 它表示行(row)的JVM对象或行对象集合形式的数据。 它通过编码器以表格形式(tabular forms)表示。
(4)编译时类型安全
- RDD:RDD提供了一种熟悉的面向对象编程风格,具有编译时类型安全性。
- DataFrame:如果您尝试访问表中不存在的列,则持编译错误。 它仅在运行时检测属性错误。
- Dataset:DataSet可以在编译时检查类型, 它提供编译时类型安全性。
(5)序列化
RDD:每当Spark需要在集群内分发数据或将数据写入磁盘时,它就会使用Java序列化。序列化单个Java和Scala对象的开销很昂贵,并且需要在节点之间发送数据和结构。
DataFrame:Spark DataFrame可以将数据序列化为二进制格式的堆外存储(在内存中),然后直接在此堆内存上执行许多转换。无需使用java序列化来编码数据。它提供了一个Tungsten物理执行后端,来管理内存并动态生成字节码以进行表达式评估。
Dataset:在序列化数据时,Spark中的数据集API具有编码器的概念,该编码器处理JVM对象与表格表示之间的转换。它使用spark内部Tungsten二进制格式存储表格表示。数据集允许对序列化数据执行操作并改善内存使用。它允许按需访问单个属性,而不会消灭整个对象。
(6)垃圾回收
- RDD:创建和销毁单个对象会导致垃圾回收。
- DataFrame:避免在为数据集中的每一行构造单个对象时引起的垃圾回收。
- Dataset:因为序列化是通过Tungsten进行的,它使用了off heap数据序列化,不需要垃圾回收器来摧毁对象。
(7)效率/内存使用
RDD:在java和scala对象上单独执行序列化时,效率会降低,这需要花费大量时间。
DataFrame:使用off heap内存进行序列化可以减少开销。 它动态生成字节代码,以便可以对该序列化数据执行许多操作。 无需对小型操作进行反序列化。
Dataset:它允许对序列化数据执行操作并改善内存使用。 因此,它可以允许按需访问单个属性,而无需反序列化整个对象。
(8)编程语言支持
RDD:RDD提供Java,Scala,Python和R语言的API。 因此,此功能为开发人员提供了灵活性。
DataFrame:DataFrame同样也提供Java,Scala,Python和R语言的API。
Dataset:Dataset 的一些API目前仅支持Scala和Java,对Python和R语言的API在陆续开发中。
(9)聚合操作(Aggregation)
- RDD:RDD API执行简单的分组和聚合操作的速度较慢。
- DataFrame:DataFrame API非常易于使用。 探索性分析更快,在大型数据集上创建汇总统计数据。
- Dataset:在Dataset中,对大量数据集执行聚合操作的速度更快。
5.RDD、DataFrame、DataSet的相互转换操作
DataFrame相当于在RDD的基础上添加了结构,DataSet相当于在DataFrame的基础上添加了类型
1 RDD->DataFrame、DataSet
// 创建rdd
scala> val rdd = sc.makeRDD(List(("zhangsan",18)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[23] at makeRDD at :28
scala> rdd.collect().foreach(println)
(zhangsan,18)
// rdd->df rdd.toDF(列名1,列名2,...)
scala> val df = rdd.toDF("name","age")
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
// 打印输出
scala> df.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 18|
+--------+---+
// rdd->ds 样例类RDD.toDS()
// 创建样例类
case class User(name: String, age: Int)
scala> val rdd1 = rdd.map(data=>User(data._1,data._2))
rdd1: org.apache.spark.rdd.RDD[User] = MapPartitionsRDD[27] at map at :31
scala> val ds = rdd1.toDS()
ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
scala> ds.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 18|
+--------+---+
2 DataFrame->RDD,DataSet
// df -> RDD df.rdd
scala> val dfToRDD = df.rdd
dfToRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[35] at rdd at :29
scala> dfToRDD.collect().foreach(println)
[zhangsan,18]
// df -> ds ds.as[样例类]
scala> val dfTods = df.as[User]
dfTods: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
scala> dfTods.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 18|
+--------+---+
3 DataSet->RDD,DataFrame
// ds -> RDD ds.rdd
scala> val dsToRDD = ds.rdd
dsToRDD: org.apache.spark.rdd.RDD[User] = MapPartitionsRDD[44] at rdd at :29
scala> dsToRDD.collect().foreach(println)
User(zhangsan,18)
// ds -> df ds.toDF
scala> val dsTodf = ds.toDF
dsTodf: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> dsTodf.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 18|
+--------+---+
二、Spark-SQL连接JDBC的方式及代码写法
1.将hive-site.xml复制到spark/spark-local/conf/下
cp /opt/software/hive-2.3.3/conf/hive-site.xml /opt/software/spark/spark-local/conf/
2.将mysql驱动复制到spark-local/jars/下
cd /opt/software/spark/spark-local/jars
3.开启spark jdbc 服务
sbin/start-thriftserver.sh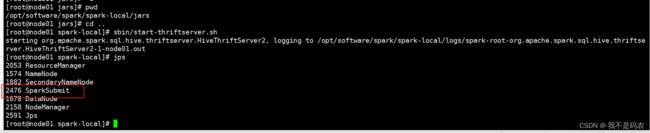 4.连接
4.连接
beeline -u jdbc:hive2://node01:10000 -n root 显示如上表示成功了!!!!
显示如上表示成功了!!!!
三、Spark-SQL连接Hive 的五种方法
Apache Hive 是 Hadoop 上的 SQL 引擎,Spark SQL 编译时可以包含 Hive 支持,也可以不包含。包含 Hive 支持的 Spark SQL 可以支持 Hive 表访问、UDF (用户自定义函数)、Hive 查询语言(HQL)等。需要强调的一点是,如果要在 Spark SQL 中包含Hive 的库,并不需要事先安装 Hive。一般来说,最好还是在编译 Spark SQL 时引入 Hive支持,这样就可以使用这些特性了。
使用方式分为内嵌Hive、外部Hive、Spark-SQL CLI、Spark beeline 以及代码操作。
1.内嵌的 HIVE
如果使用 Spark 内嵌的 Hive, 则什么都不用做, 直接使用即可。但是在实际生产活动当中,几乎没有人去使用内嵌Hive这一模式。
2.外部的 HIVE
如果想在spark-shell中连接外部已经部署好的 Hive,需要通过以下几个步骤:
➢ Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下
➢ 把 Mysql 的驱动 copy 到 jars/目录下
➢ 如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
➢ 重启 spark-shell

打开hive-site.xml并修改:

记得修改图中画线部分!!!
切换到spark的bin目录下,找到启动程序,双击打开


输入命令:
spark.sql("show databases").show
3. 运行 spark-beeline
Spark Thrift Server 是 Spark 社区基于 HiveServer2 实现的一个 Thrift 服务。旨在无缝兼容HiveServer2。因为 Spark Thrift Server 的接口和协议都和 HiveServer2 完全一致,因此我们部署好 Spark Thrift Server 后,可以直接使用 hive 的 beeline 访问 Spark Thrift Server 执行相关语句。Spark Thrift Server 的目的也只是取代 HiveServer2,因此它依旧可以和 Hive Metastore进行交互,获取到 hive 的元数据。如果想连接 Thrift Server,需要通过以下几个步骤:
➢ Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下
➢ 把 Mysql 的驱动 copy 到 jars/目录下
➢ 如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
cp /opt/software/hive-2.3.3/conf/hive-site.xml /opt/software/spark/spark-local/conf/
cp /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/hdfs-site.xml /opt/software/spark/spark-local/conf
cp /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/core-site.xml /opt/software/spark/spark-local/conf/
➢ 启动 Thrift Server
sbin/start-thriftserver.sh➢ 使用 beeline 连接 Thrift Server
beeline -u jdbc:hive2://node01:10000 -n root➢测试

4. Spark-Sql CLI
Spark SQL CLI 可以很方便的在本地运行 Hive 元数据服务以及从命令行执行查询任务。在 Spark 目录下执行如下命令启动 Spark SQL CLI,直接执行 SQL 语句,类似于 Hive 窗口。
操作步骤:
1.将mysql的驱动放入jars/当中;
2.将hive-site.xml文件放入conf/当中;
3.运行bin/目录下的spark-sql.cmd 或者打开cmd,在
F:\spark\spark-3.0.0-bin-hadoop3.2\bin当中直接运行spark-sql

5. IDEA中操作
5.1 注入依赖
org.apache.spark
spark-core_2.12
3.0.0
org.apache.spark
spark-sql_2.12
3.0.0
org.apache.maven.plugins
maven-assembly-plugin
3.1.0
org.apache.spark
spark-hive_2.12
3.0.0
org.apache.hive
hive-exec
2.3.3
mysql
mysql-connector-java
5.1.27
5.2 将hive-site.xml 文件拷贝到项目的 resources 目录中。

5.3 代码实现(IDEA)
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object HiveTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("HiveTest")
val spark: SparkSession = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
spark.sql("show databases").show()
spark.sql("create database sparkSql")
spark.sql("show databases").show()
spark.stop()
}
}5.4运行结果展示


大功告成!!!!!!