Spark-SQL详解
目录
- 前言
- 什么是Spark SQL
- DataFrame
- DataFrame 基本操作
-
- SparkSession
- 创建DataFrame
-
- 1) 通过 Spark 的数据源创建
-
- DSL语法风格(了解)
- 2) RDD转化为DataFrame
-
- 通过手动确定转换
- 通过反射转化(用到样例类)
- 3)通过hive创建RDD
- 其它操作
-
- DataFrame转化为RDD
- DataSet
- DataSet基本操作
-
- 创建
- RDD转换为DataSet
- DataSet 转换为RDD
- DataFrame 转换为DataSet
- DataSet 转换为 DataFrame
- RDD.DataFrame.DataSet 小结
-
- 三者的共性
- 三者的区别
-
- 1. RDD:
- 2. DataFrame:
- 3. Dataset:
- 使用IDEA开发SparkSQL程序
-
- 创建一个DataFrame
- 转换
前言
在没有sparkSql之前,进行数据分析一般通过MR,SQL
但是MR运行慢,操作较为复杂,即效率比较低。
SQL运行速度较快,操作也方便。但是面向的是关系型数据库,并不适合大数据开发
模仿SQL–>HIVE
HIVE是将HIVE SQL 转换成MapReduce然后提交到集群上执行,虽然简化了Mapredece程序复杂性,但是由于MapReduce计算模型自身限制,速度并不是很快
spark模仿hive,自己形成了SparkSQL,将Spark SQL 转化为RDD,然后提交到集群执行,执行效率非常快
什么是Spark SQL
Spark SQL 是Spark用来处理结构化数据的一个模块,
但是Spark 中数据(RDD)并没有结构,怎么办呢?
在SparkSQL中Spark为我们提供了两个新的抽象
DataFrame
DataSet
Spark SQL 特点
1)Integrated(易整合)
2)Uniform Data Access(统一的数据访问方式)
3)Hive Integration(集成 Hive)
4)Standard Connectivity(标准的连接方式)
DataFrame
与RDD类似,DataFrame 是一个分布式数据容器,DataFrame 更像传统数据库的二位表格,除了数据以外,还记录数据的结构信息(即schema),强调的是结构,和属性没有太大关系

上图直观地体现了DataFrame和RDD的区别。
1)左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。
2)而右侧的DataFrame却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。
3)DataFrame是为数据提供了Schema的视图。可以把它当做数据库中的一张表来对待,
4)DataFrame也是懒执行的
性能上比 RDD要高,主要原因: 优化的执行计划:查询计划通过Spark catalyst optimiser进行优化
比如下面一个例子:
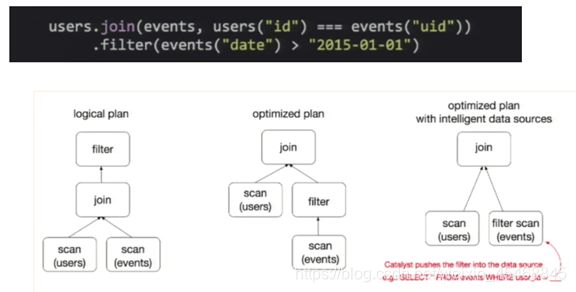
为了说明查询优化,我们来看上图展示的人口数据分析的示例。图中构造了两个DataFrame,将它们join之后又做了一次filter操作。
如果原封不动地执行这个执行计划,最终的执行效率是不高的。因为join是一个代价较大的操作,也可能会产生一个较大的数据集。
如果我们能将filter下推到 join下方,先对DataFrame进行过滤,再join过滤后的较小的结果集,便可以有效缩短执行时间。
而Spark SQL的查询优化器正是这样做的。简而言之,逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程。
DataFrame 基本操作
SparkSession
在老的版本中,SparkSQL 提供两种 SQL 查询起始点:一个叫SQLContext,用于Spark 自己提供的 SQL 查询;一个叫 HiveContext,用于连接 Hive 的查询。
从2.0开始, SparkSession是 Spark 最新的 SQL 查询起始点,实质上是SQLContext和HiveContext的组合,所以在SQLContext和HiveContext上可用的 API 在SparkSession上同样是可以使用的。
SparkSession内部封装了SparkContext,所以计算实际上是由SparkContext完成的。
当我们使用 spark-shell 的时候, spark 会自动的创建一个叫做spark的SparkSession, 就像我们以前可以自动获取到一个sc来表示SparkContext
创建DataFrame
有了 SparkSession 之后, 通过 SparkSession有 3 种方式来创建DataFrame:
1) 通过 Spark 的数据源创建
spark支持的数据源:

通过spark.read 读取的文件会自动转化为DataFrame
案例:
创建一个json文件
{
"name" = "Michae","salary"=3000}
{
"name" = "Andy","salary"=4500}
{
"name" = "Justin","salary"=3500}
{
"name" = "Berta","salary"=4000}
命令行模式:
scala> val df = spark.read.json("file:///.../test.json")
scala> df.show
结果:
+-------+------+
| name|salary|
+-------+------+
|Michael| 3000|
| Andy| 4500|
| Justin| 3500|
| Berta| 4000|
+-------+------+
将查询结果转化为视图createTempView(),没有转化为临时表createTempTable()是因为视图不可变,
scala> df.createTempView("test")
scala> spark.sql("select * from test").show
+-------+------+
| name|salary|
+-------+------+
|Michael| 3000|
| Andy| 4500|
| Justin| 3500|
| Berta| 4000|
+-------+------+
scala> spark.sql("select name from test").show
+-------+
| name|
+-------+
|Michael|
| Andy|
| Justin|
| Berta|
+-------+
注意:⭐⭐⭐⭐
- 临时视图只能在当前 Session 有效, 在新的 Session 中无效.
- 可以创建全局视图. 访问全局视图需要全路径:如
global_temp.xxx
scala> val df = spark.read.json("file///..../people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
#创建全局的临时表
scala> df.createGlobalTempView("people")
#访问需要全路径global_temp.people
scala> spark.sql("select * from global_temp.people")
res31: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> res31.show
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
scala> spark.newSession.sql("select * from global_temp.people")
res33: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> res33.show
+----+-------+
| age| name|
+----+-------+
|null|Michael