第一章 计算机系统概论
第一章 计算机系统概论
1.1 计算机系统简介
一、计算机的软硬件概念
1. 计算机系统
- 硬件:计算机的实体(如主机、外设等)
- 软件:由具有各类特殊功能 的信息(程序)组成
而软件又分为:
- 系统软件:用来管理整个计算机系统(如语言处理程序、操作系统、服务性程序、数据库管理系统、网络软件)
- 应用软件:按任务需要编制成的各种程序
2. 计算机的解题过程

二、计算机系统的层次结构

软件和硬件的交界:计算机体系结构
三、计算机体系结构和计算机组成
问题:如何区分 计算机体系结构 和 计算机组成 ?
答:可以做此比喻:计算机体系结构 好比是盖房时的建筑设计师,而 计算机组成 好比是盖房时的建造工程师。
房子里面有几个卫生间、有没有阳台,这些问题应当由设计师决定;而卫生间怎么盖、阳台怎么建,这些问题就由工程师来决定。
把盖房问题换成制造计算机的过程,计算机中 是否提供乘法指令 由计算机体系结构决定,而乘法指令如何实现(是专门使用乘法器or用加法器+移位器) 由计算机组成来决定。
指令系统有哪些指令、计算机有什么数据类型数据类型、寻址技术、I/O机理 由计算机体系结构决定,而众多指令在硬件上怎么实现由计算机组成来决定。
1.2 计算机的基本组成
一、冯诺依曼计算机
历史上第一台通用计算机诞生于1946年,名为 “ENIAC” ,特点为 十进制表示 、 使用手动插拔开关的形式进行手动编程,每次改变程序都需要重新连线。
冯诺依曼机相比于 ENIAC,特点为 二进制表示 、 可以自动运行程序,不需要手动进行编程。
实际上,冯诺依曼计算机具有如下特点:
1. 计算机由五大部件组成
2. 以运算器为中心
3. 指令由操作码和地址码组成
4. 指令和数据以同等地位存于存储器,可按地址寻访
5. 存储程序
6. 指令和数据用二进制表示
这么多特点,都是什么意思呢,先把这些特点放在这里,后面会一一解释。
二、计算机硬件框图
1. 冯诺依曼计算机硬件框图
想要了解冯诺依曼机,先来看看冯诺依曼机的硬件结构是怎样的:

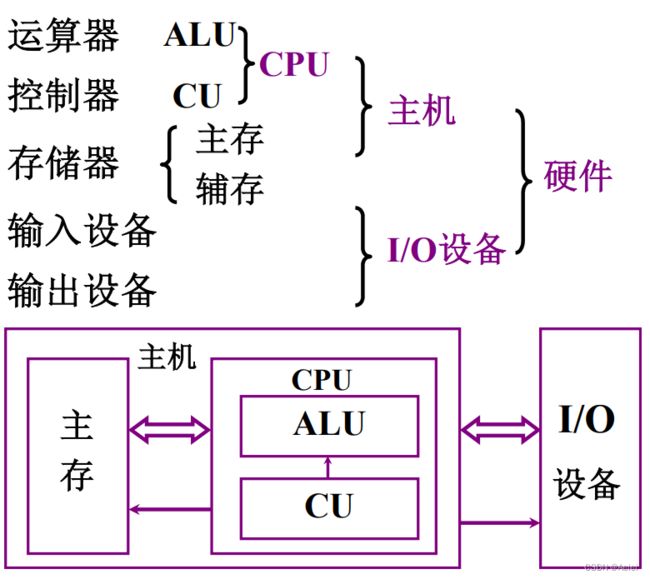
可以看到,冯诺依曼机主要由五大部件构成:运算器、存储器、控制器、输入设备、输出设备。这也对应了冯诺依曼机的第1个特点。
存储器和运算器之间传输数据;存储器和控制器之间传输指令。
在这种结构下,从外界输入数据时:首先进入运算器,然后才能进入存储器。而运算器应当是运算资源,现在却变成了搬运工,这样很浪费资源;输出数据也是同理,也要占用运算器这个重要的运算资源。这样的结构可以称为“以运算器为中心的结构”,这也对应了冯诺依曼机的第2个特点。
2. 以存储器为中心的计算机硬件框图
“以运算器为中心的结构”显然没有那么好,因此可以采用下图所示的“以存储器为中心的结构”。在这种结构中,可以把运算器的资源空闲下来,使得运算器和存储器可以并行运转,增加了系统的并行性,也就提高了效率。

3. 现代计算机硬件框图
顺便再看一看现代计算机的硬件框图:
三、计算机的工作步骤
在介绍计算机的工作步骤之前,先要介绍一下计算机的指令格式:
计算机的指令具有如下这样的格式,由两部分组成:操作码和地址码。这也对应了冯诺依曼机的第3个特点。
操作码:决定指令类别(例如在本书中:规定取数指令的操作码为000001,规定存数指令的操作码为000010,规定加法指令为000011,规定乘法指令为000100,等等等等……)
地址码:操作数存储在内存的地址(例如取数操作,要取的数在哪里呢,要根据地址码到内存中寻找被取的数)
那么,0000010000001000就是一条机器指令,代表的操作为:从0000001000地址取数。

用计算机解决一个实际问题通常包含两大步骤。一个是上机前的各种准备,另一个是上级运行。
1. 上机前的准备
1. 建立数学模型
2. 确定计算方法(例如下图)
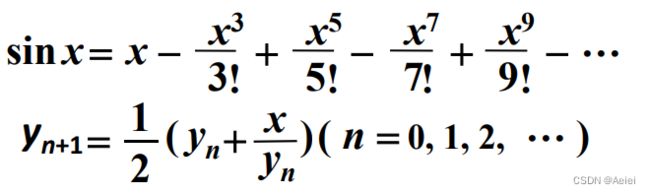
3. 编制解题程序
- 程序:所谓程序,就是运算的全部步骤
- 指令:而指令,就是运算中的每一个步骤,也就是说,整体的程序由一条条指令构成
下面举一个程序的例子:
1. 建立数学模型和确定计算方法:

2. 编制解题程序:

3. 程序运行步骤:

实际上,上图所示的指令和数据都存放在内存中,这也对应了冯诺依曼机的第4、5个特点。并且,指令和数据都是以二进制形式存储的,这也对应了冯诺依曼机的第6个特点。至此,冯诺依曼机的特点全部解释完毕。
程序已经编好了,上级前的准备已经完毕,下面进入解题环节。
2. 计算机的解题过程
这里要对冯诺依曼机五大部件中的三个部件进行介绍:存储器、运算器、控制器。
1. 存储器的基本组成
首先区分一下主存和辅存:
1. 主存储器,简称主存,是计算机硬件的一个重要部件,用来存放指令和数据。
2. 辅存,也叫做外部存储器,指硬盘、光盘等通过I/O系统与主存传递数据的存储器。
主存储器的结构如下图:
 1. 存储体:存储体内部被分为一行一行,每一行就是一个存储单元,每个存储单元可以存放一条指令或一个数据。存储单元中的内容被称为存储字,也即那些指令和数据。每一个存储单元中能存放的二进制码的位数被称作存储字长。每一个存储单元被赋予一个地址号,想要访问存储单元里的内容,需要按地址寻访。
1. 存储体:存储体内部被分为一行一行,每一行就是一个存储单元,每个存储单元可以存放一条指令或一个数据。存储单元中的内容被称为存储字,也即那些指令和数据。每一个存储单元中能存放的二进制码的位数被称作存储字长。每一个存储单元被赋予一个地址号,想要访问存储单元里的内容,需要按地址寻访。
2. MAR(Memory Adress Register):MAR用来存放那些将要访问的地址(MAR的位数取决于存储单元的个数,例如有16个存储单元,那么MAR就有4位,4位二进制数正好可以索引16个地址,比如地址0010指向的就是第2个存储单元)
3. MDR(Memory Data Register):MDR用来存放那些将要放入存储器 / 从存储体取出的数据(MDR的位数取决于存储单元的存储字长,例如存储单元可以存储8位二进制码,那么MDR就有8位)
2. 运算器的基本组成
运算器的基本组成如下图:

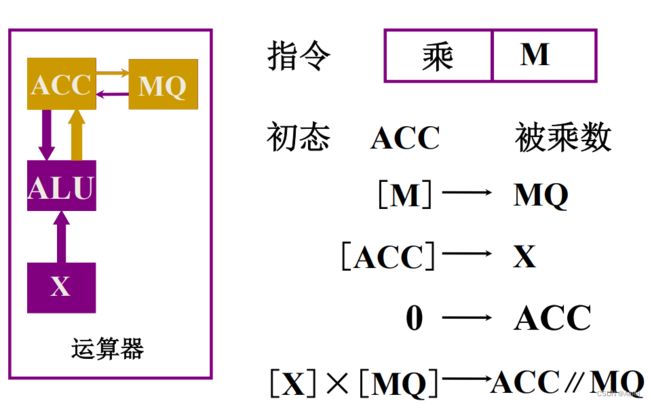
其中ACC、MQ和X是3个寄存器,在加减乘除运算的过程中,这三个寄存器用来存放数据,那么到底按照什么样的规则来存放数据呢?请看下图:

第一行表示:被加数放在ACC中,加数放在X中,二者相加,所得结果再放回ACC中。
第二行表示:被减数放在ACC中,减数放在X中,二者相减,所得结果再放回ACC中。
第三行表示:乘数放在MQ中,被乘数放在X中,二者相乘,所得结果的高位放入ACC中,低位放入MQ中。(为什么要分低位高位?比如三个寄存器都可以存放8为二进制数,两个8位二进制数的乘积为16位二进制数,一个寄存器就放不下了,需要把乘积分为高位和低位分别存放于两个寄存器)
下面介绍以下加减乘除运算的具体过程:
其中[M]表示M是一个地址,[M]就是从地址M中取来的数;→表示赋值。
① 加法操作过程:

② 减法操作过程:

③ 乘法操作过程:
④ 除法操作过程:

3. 控制器的基本组成
控制器的基本组成如下图:

1. PC(Program Counter)寄存器:程序寄存器,存放当前欲执行指令的地址,具有计数功能(PC)+1 → PC。
2. IR(Instruction Register)寄存器:指令寄存器,存放当前欲执行的指令。注意,PC存的是指令的地址,而IR存的是指令本身。
4. 主机完成一条指令的过程
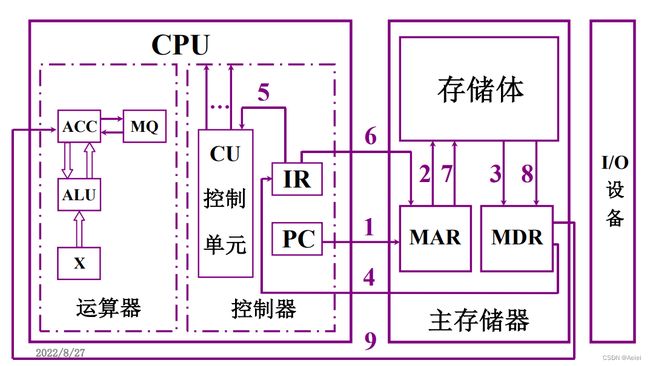
以取数指令为例:(步骤对应于下图数字)
第一步:PC→MAR(PC将第一条指令的地址送到MAR,方便下一步从存储体里读取第一条指令)
第二、三步:M(MAR) → MDR(从存储体中取出16位指令,送到MDR中存储)
第四步:MDR → IR(从MDR中取出当前的指令,送到IR指令寄存器)
第五步:OP(IR) → CU(将指令的操作码部分(OP)送到CU分析指令)
第六步:AD(IR) → MAR(将指令的地址码部分(AD)送到MAR,方便下一步从存储体中读取操作数)
第七、八步:M(MAR) → MDR(从存储体中取出操作数,送到MDR中存储)
第九步:MDR → ACC(从MDR取出操作数,送到ACC,等待被运算)
另外一条指令运行完,还需要将PC里的内容改为下一条指令地址:(PC)+1→PC
如果需要跳转的话:从地址码的地址中取到想要跳转到的指令的地址,将该地址送到PC。
5. 二次函数计算的例子

1.3 计算机硬件的主要技术指标
1. 机器字长:
CPU一次能处理数据的位数,与CPU中的寄存器位数有关
2. 存储容量
1. 主存容量:主存中存放二进制代码的总位数。即:存储容量=存储单元个数×存储字长。例如MAR为10位,MDR为8位,则存储单元个数为 2 10 2^{10} 210个,即1K,而MDR为8位,因此主存容量为1K×8位;又例如MAR为16位,MDR为32位,则主存容量为64K×32位。在现代计算机中,容量都以字节数来描述,即1Byte=8bit,例如2M位=2× 2 20 2^{20} 220位= 2 21 2^{21} 221位= 2 18 2^{18} 218字节= 2 18 2^{18} 218B=256KB.
2. 辅存容量:辅存容量通常以字节数来表示,例如,某机硬盘容量为80GB(1G=1024M= 2 10 2^{10} 210× 2 10 2^{10} 210= 2 20 2^{20} 220)
3. 运算速度
1. 主频:主频即CPU的时钟频率,表示在CPU内数字脉冲信号震荡的速度。计算机的操作在时钟信号的控制下分步执行,每个时钟信号周期完成一步操作,时钟频率的高低在很大程度上反映了CPU速度的快慢。
2. 吉普森法:等效指令速度法是通过各类指令在程序中所占的比例 wi 进行计算来得到指令的等效执行时间。

3. MIPS:每秒执行百万条指令
4. FLOPS:每秒浮点运算次数
5. CPI:执行一条指令所需时钟周期数
4. CPI
MIPS和FLOPS都是从宏观的角度描述计算机的运行速度,并不很精确;而CPI(Cycle Per Instruction:某个程序中所有指令的平均周期数)是从微观的角度描述计算机的运行速度,更加精确。我们可以使用CPI来计算一个程序执行的时间。
如何刻画一个程序执行的时间?有很多种指标可以使用,例如CPU时间(指一段程序在CPU上面运行消耗的时间)、系统时间(指一段程序从运行到终止,系统时钟走过的时间)等。我们以CPU时间为例,CPU时间 = IC×CPI× τ \tau τ:其中IC为程序的指令数, τ \tau τ为时钟周期,即主频的倒数。
CISC(复杂指令集体系):指令很复杂,程序就很短,所需指令数就很小,也即IC很小;但是由于每条指令实现起来很复杂,因此CPI很大。而RISC(精简指令集体系)则相反,IC很大,CPI很小。也就是说IC和CPI是相互制约的。
实际上CPI取决于很多因素:
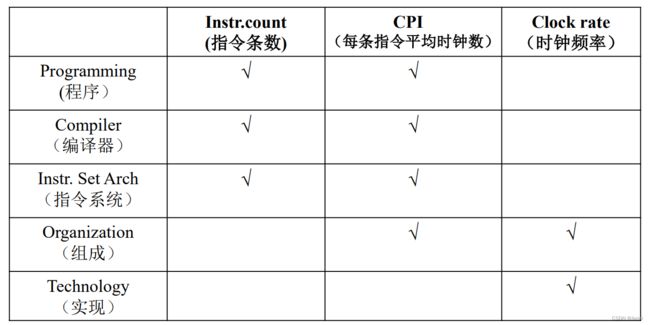
1. 程序:程序不同,则每个程序的指令条数(IC)也不尽相同,并且不同程序中,每条指令的平均时钟数(CPI)也不同。
2.编译器:不同的编译器将高级语言编译后,所得机器语言程序并不相同,其中IC不同, CPI也不同。
3. 指令系统:正如上面举到的RISC和CISC的例子,指令系统不同,IC和CPI也不同。
4. 组成:即计算机系统的逻辑实现,属于硬件层面。硬件层面已经影响不到程序,因此IC不会受影响。但是组成可以决定一条指令有几个时钟周期,因此会影响CPI。另外,由于是硬件层面,因此也会影响时钟频率(即CPU主频)。
5. 实现:即计算机系统的物理实现,由于是硬件层面,故不会影响IC;又由于计算机系统的组成已经确定,只差物理电路的搭建,因此也不会影响CPI。但是计算机系统的物理实现会影响时钟频率。
5. Amdahl定律
Amdahl定律
假设我们对机器(部件)进行某种改进,那么机器系统(部件)的加速比就是:

系统加速比告诉我们改进后的机器比改进前快多少。
系统加速比依赖于两个因素:
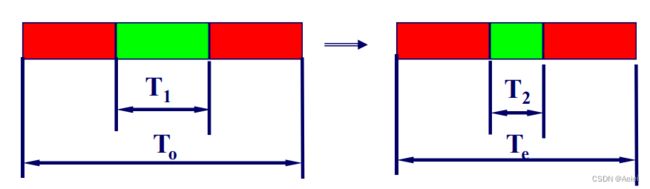
1. “可改进比例”:可改进部分在原系统计算时间中所占的比例 ,它总是小于等于1的( T 0 T 1 \frac{T_0}{T_1} T1T0)
2. “部件加速比”可改进部分改进以后的性能提高,一般情况下它是大于1的( T 1 T 2 \frac{T_1}{T_2} T2T1)
Amdahl定律的系统执行时间
部件改进后,系统的总执行时间等于不可改进部分的执行时间加上可改进部分改进后的执行时间,即:

Amdahl定律的观点
1.性能增加的递减规则
仅仅对计算机中的一部分做性能改进,则改进越多,系统获得的效果越小。
2. Amdahl定律的一个重要推论:
针对整个任务的一部分进行优化,则最大加速比不大于 1 1 − T 可 改进比例 \frac{1}{1-T_可改进比例} 1−T可改进比例1。
3. Amdahl定律衡量一个“好”的计算机系统
具有高性能价格比的计算机系统是一个带宽平衡的系统,而不是看它使用的某些部件的性能。(木桶原理)