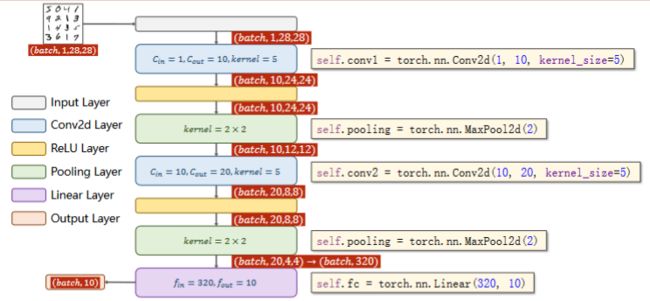
深度学习 | Pytorch深度学习实践
一、overview
基于pytorch的深度学习的四个步骤基本如下:
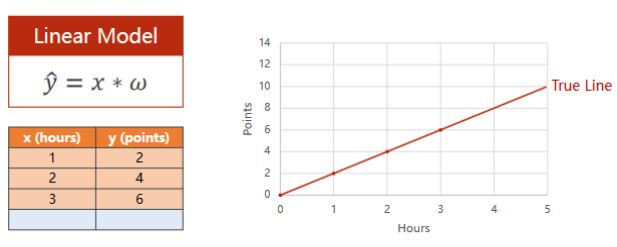
二、线性模型 Linear Model
基本概念
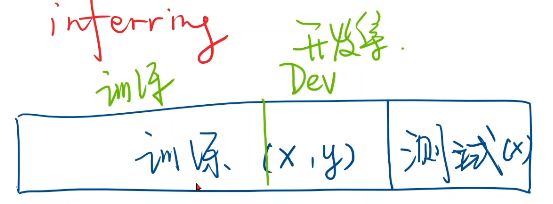
- 数据集分为测试集和训练集(训练集、开发集)
- 训练集(x,y)测试集只给(x)
- 过拟合:模型学得太多导致性能不好
- 开发集:测验模型泛化能力
- zip:从数据集中,按数据对儿取出自变量
x_val和真实值y_val
- 本例中进行人工training,穷举法
- 定义前向传播函数forward
- 定义损失函数loss
- MSE:平均平方误差

- zip:从数据集中,按数据对儿取出自变量
x_val和真实值y_val
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
def forward(x):#定义模型
return x * w
def loss(x,y):#定义损失函数
y_pred = forward(x)
return (y_pred - y) * (y_pred - y)
w_list=[]#权重
mse_list=[]
for w in np.arange(0.0,4.1,0.1):
print('w=',w)
l_sum = 0
for x_val,y_val in zip(x_data,y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val,y_val)
l_sum += loss_val
print('\t',x_val,y_val,y_pred_val,loss_val)
print('MSE=',l_sum / 3)
w_list.append(w)
mse_list.append(l_sum / 3)
plt.plot(w_list,mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
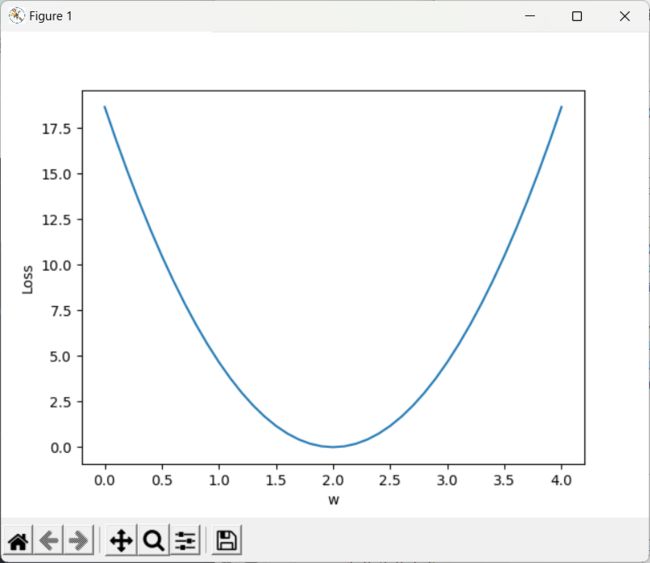
注:模型训练可视化
wisdom:可视化工具包
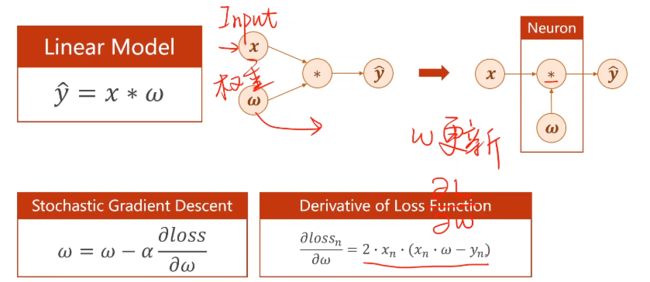
三、Gradient Descent 梯度下降
3.1、梯度下降
(基于cost function 即所有样本):
如我们想要找到w的最优值
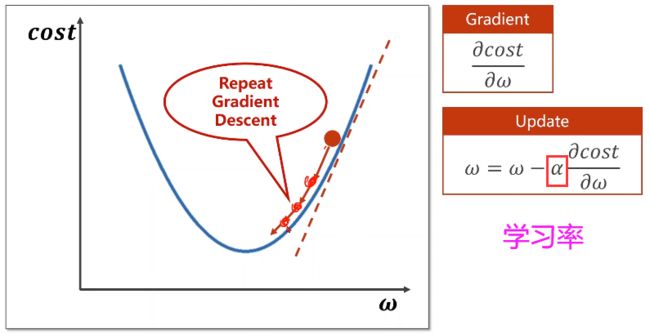
- 贪心思想:每一次迭代得到局部最优,往梯度的负方向走
- 梯度下降算法很难找到全局最优,但是在深度学习中损失函数中,全局最优最有很少出现,但会出现鞍点(梯度 = 0)

import numpy as np
import matplotlib.pyplot as plt
w = 1.0
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
def forward(x):
return x * w
def cost(xs,ys):
cost = 0
for x,y in zip(xs,ys):
y_pred = forward(x)
cost += (y_pred-y)**2
return cost / len(xs)
def gradient(xs,ys):
grad = 0
for x,y in zip(xs,ys):
grad += 2 * x * ( x * w - y)
return grad / len(xs)
epoch_list=[]
cost_list=[]
print('Predict (before training)',4,forward(4))
for epoch in range(100):
cost_val = cost(x_data,y_data)
grad_val = gradient(x_data,y_data)
w -= 0.01 * grad_val
print('Epoch',epoch,'w=',w,'loss=',cost_val)
epoch_list.append(epoch)
cost_list.append(cost_val)
print('Predict (after training)',4,forward(4))
print('Predict (after training)',4,forward(4))
plt.plot(epoch_list,cost_list)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()
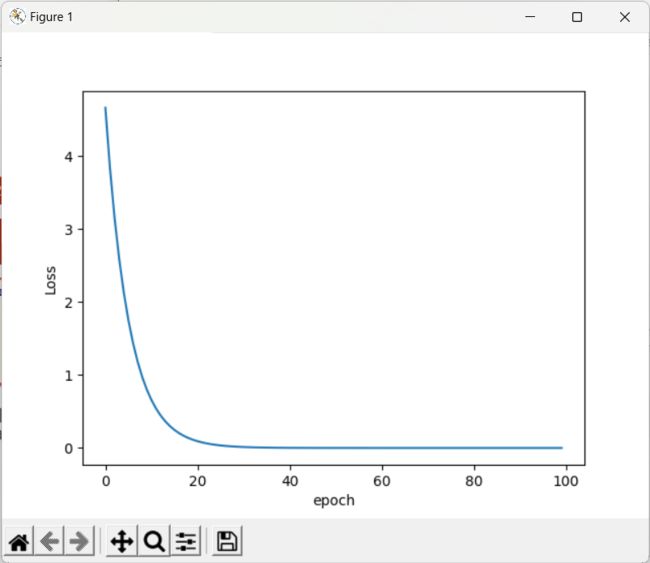
- 注:训练过程会趋近收敛
- 若生成图像局部震荡很大,可以进行指数平滑

- 若图像发散,则训练失败,通常原因是因为学习率过大
3.2、 随机梯度下降 Stochastic Gradient Descent
(基于单个样本的损失函数):
—— 因为函数可能存在鞍点,使用一个样本就引入了随机性
此时梯度更新公式为:
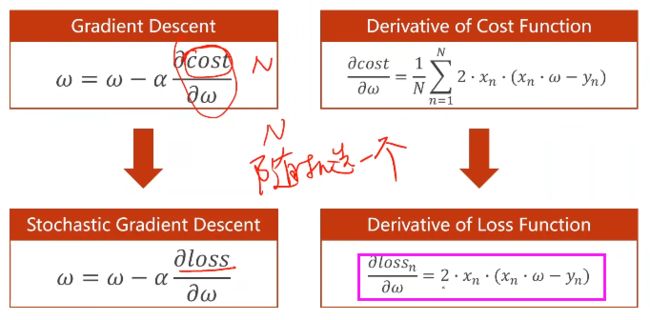
与之前的区别:
- cost改为loss
- 梯度求和变为单个样本
- 训练过程中要对每一个样本求梯度进行更新
- 由于两个样本的梯度下降不能并行化,时间复杂度太高
- 所以折中的方式:使用 Mini-Batch 批量随机梯度下降
- 若干个一组,后续将会涉及
import numpy as np
import matplotlib.pyplot as plt
w = 1.0
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
def forward(x):
return x * w
def loss(x,y):
y_pred = forward(x)
return (y_pred-y)**2
def gradient(x,y):
return 2 * x * (x * w - y)
loss_list=[]
epoch_list=[]
print('Predict (before training)',4,forward(4))
for epoch in range(100):
for x,y in zip(x_data,y_data):
grad = gradient(x,y)
w = w - 0.01 * grad
print('\tgrad',x,y,grad)
l = loss(x,y)
loss_list.append(l)
epoch_list.append(epoch)
print("progress",epoch,'w=',w,'loss=',l)
print('Predict (after training)',4,forward(4))
plt.plot(epoch_list,loss_list)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()
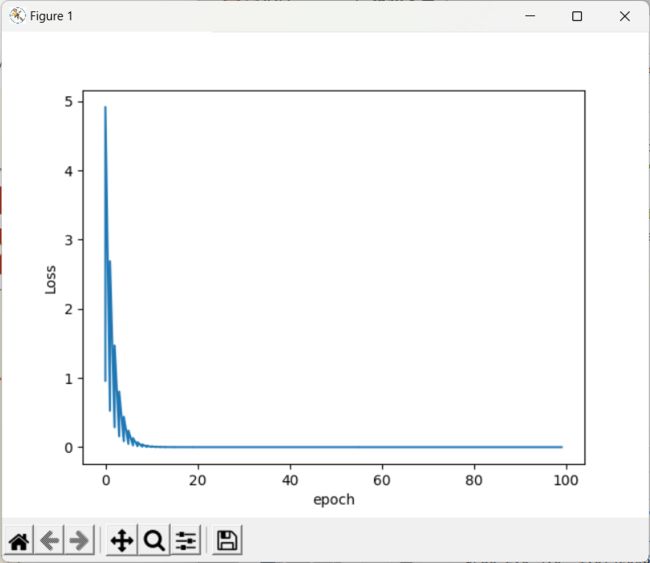
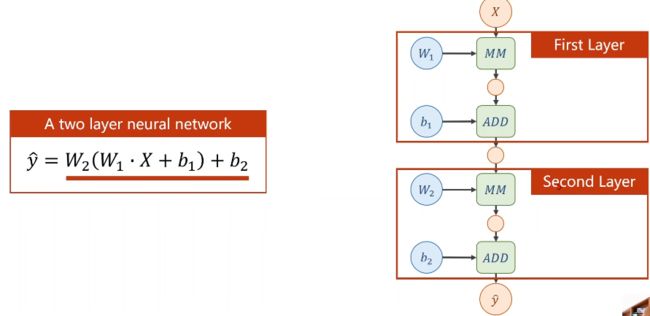
四 、反向传播 BackPropagation
对于复杂的网络:
举例来讲两层神经网络
若进行线性变换,不管多少层,最终都可以统一成一种形式,但为了让你不能在化简(即提高模型复杂程度),所以我们要对每一层最终的输出
加一个非线性的变化函数(比如sigmiod)
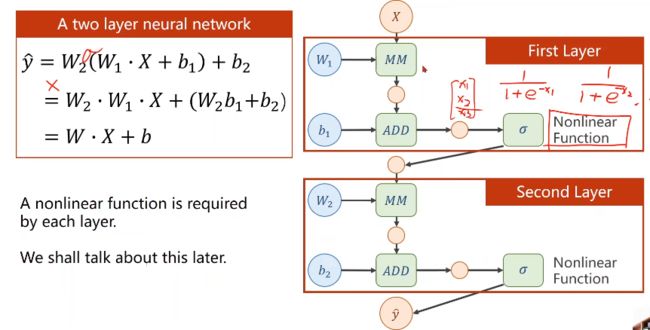
则层层叠加若需要求梯度的话就要用到 —— 链式求导:
- 1、构建计算图 —— 前馈计算(Forward)先计算最终的loss
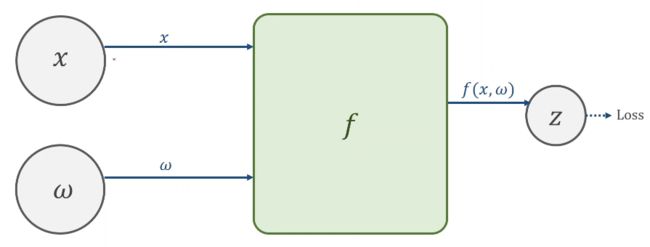
- 2、反馈(Backward)
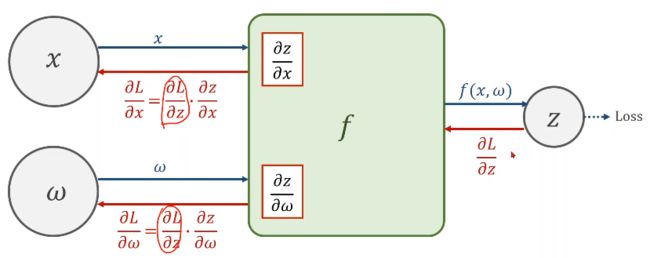
来看一下最简单的线性模型中的计算图的计算过程:


在pytorch中,使用tensor类型的数据

import torch
import matplotlib.pyplot as plt
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
w = torch.Tensor([1.0]) #注意这里一定要加[] 权重初始值
w.requires_grad = True
def forward(x):
return x * w #因为w是Tensor,这里的运算符已经被重载了,x会进行自动转换,即构造了计算图
def loss(x,y):
y_pred = forward(x)
return (y_pred - y) ** 2
epoch_list = []
loss_list = []
print('Predict (before training)',4,forward(4))
for epoch in range(100):
#sum=0
for x,y in zip(x_data,y_data):
l = loss(x,y) #只要一做backward计算图会释放,会准备下一次的图
l.backward()
print('\tgrad:',x,y,w.grad.item()) #item将梯度数值直接拿出来为标量
w.data = w.data - 0.01 * w.grad.data #grad必须要取到data
#sum += l 但l为张量,计算图,进行加法计算会构造计算图,将会发生溢出
w.grad.data.zero_() #!!!权重里面梯度的数据必须显式清零
print("progress",epoch,l.item())
epoch_list.append(epoch)
loss_list.append(l.item())
print('Predict (after training)',4,forward(4))
plt.plot(epoch_list,loss_list)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()
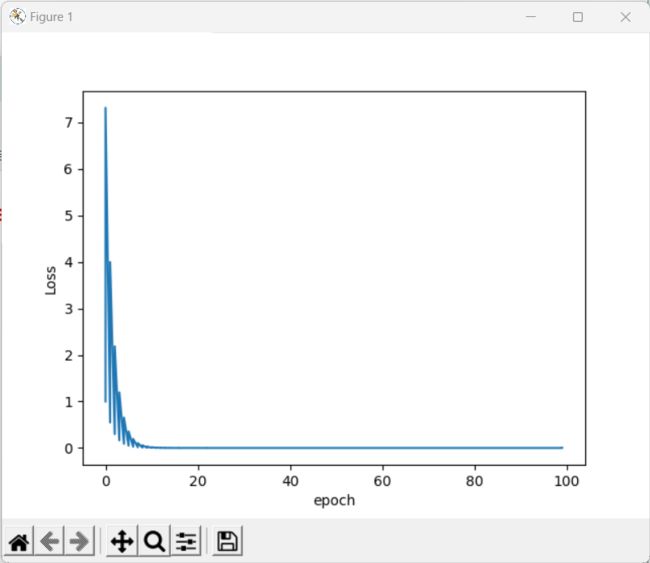
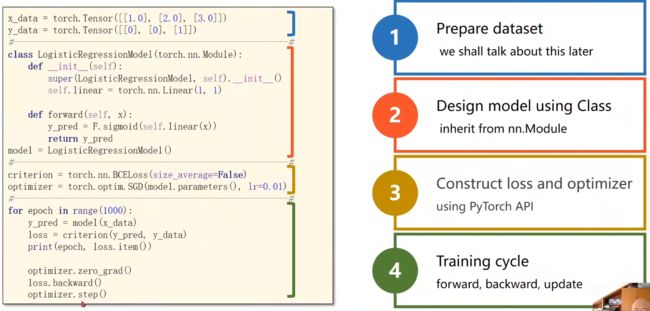
五、利用PyTorch实现线性回归模型 Linear Regression With PyTorch
pytorch神经网络四步走
- 1、构建数据集
- 2、设计模型(用来计算y_hat)
- 3、构建损失函数和优化器(我们使用pytorch封装的API)
- 4、训练周期(前馈 反馈 更新)
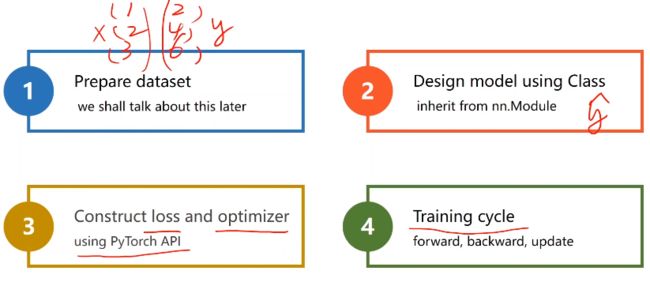
本例将使用 Mini-Batch,numpy有广播机制矩阵相加会自动扩充。

使用pytorch的关键就不在于求梯度了,而是构建计算图,这里使用仿射模型,也叫线性单元。
代码实现:
import torch
import matplotlib.pyplot as plt
# 1、准备数据
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[2.0],[4.0],[6.0]])
# 2、构建模型
class LinearModel(torch.nn.Module):
def __init__(self): #构造函数
super(LinearModel,self).__init__()
self.linear = torch.nn.Linear(1,1) #构造一个对象
def forward(self,x):
y_pred = self.linear(x) #实现可调用对象
return y_pred
model = LinearModel()
# 3、构造损失函数和优化器
criterion = torch.nn.MSELoss(size_average=False) #继承nn.Module,是否求平均
optimizer = torch.optim.SGD(model.parameters(),lr=0.01) #是一个类,不继承nn.Module,不会构建计算图,lr学习率
epoch_list = []
loss_list = []
for epoch in range(100):
# 前馈 计算 y_hat
y_pred = model(x_data)
# 前馈 计算损失
loss = criterion(y_pred,y_data)
print(epoch,loss) # loss是一个对象,打印将会自动调用__str__()
optimizer.zero_grad() # 所有权重梯度归零
# 反馈 反向传播
loss.backward()
# 自动更新,权重进行更新
optimizer.step()
epoch_list.append(epoch)
loss_list.append(loss.item())
# Output weight and bias
print('w = ',model.linear.weight.item())
print('b = ',model.linear.bias.item())
# Test Model
x_test = torch.Tensor([4.0])
y_test = model(x_test)
print('y_pred = ',y_test.data)
plt.plot(epoch_list,loss_list)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()


七、Multiple Dimension lnput
引例:糖尿病数据集分类任务
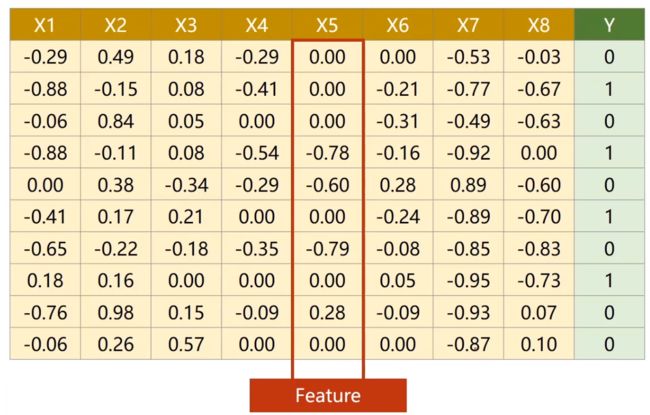
行称为:样本(Sample) 数据库中称为:记录(record)
列称为:特征 数据库中称为:字段
注:sklearn中提供一个关于糖尿病的数据集可作为回归任务的数据集
Mlultiple Dimension Loqistic Regression Model
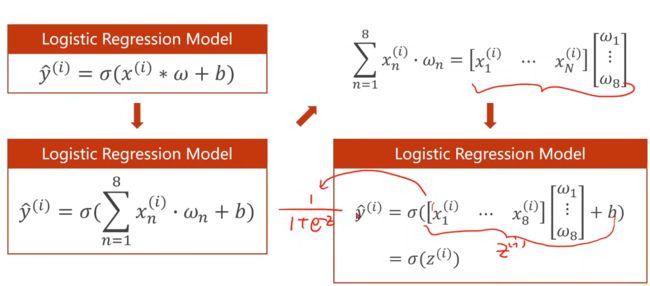
再来看下Mini-Batch(N samples)的情况
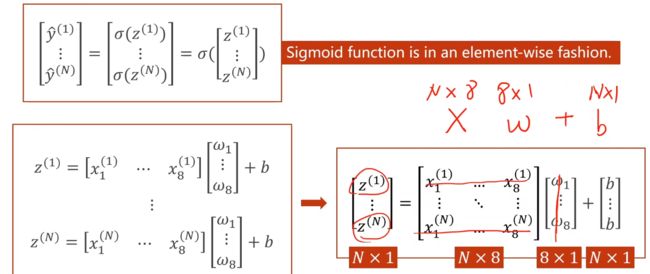
为什么这里要将方程运算转换成矩阵运算 即 向量形式呢?
———— 我们可以利用并行运算的能力,提高运行速度。

Logistics回归只有一层神经网络,若我们构造一个多层神经网络:
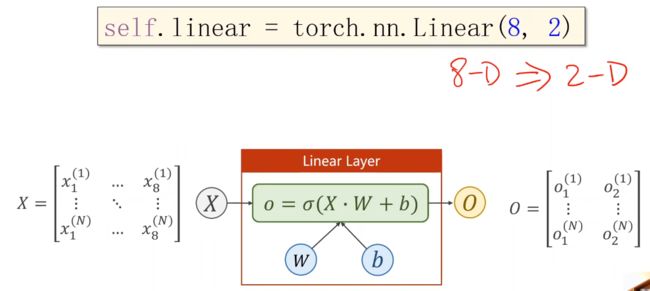
将矩阵看成一种空间变换的函数,这里的(8,2)是指将一个人一八维空间的向量映射到一个二维空间上,注意是线性的,而我们所做的空间变换不一定是线性的,
所以我们想要多个线性变换层通过找到最优的权重,把他们组合起来,来模拟一个非线性变换
注意绿色框中我们引入的  即激活函数 ,在神经网络中我们通过引入激活函数给线性变换加入非线性操作,这样就使得我们可以去拟合相应的非线性变换。
即激活函数 ,在神经网络中我们通过引入激活函数给线性变换加入非线性操作,这样就使得我们可以去拟合相应的非线性变换。
对于本例 Example: Artificial Neural Network

1、建立数据集
import numpy as np
import torch
xy = np.loadtxt('./dataset/diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1]])- 分隔符为,
- 为什么用float32,因为常用游戏显卡只支持32位浮点数,只有特别贵的显卡才支持64位
- 注意y,拿出来需要加中括号,拿出来矩阵
2、模型建立
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
- 注意上次调用的是nn.Function下的sigmoid,但是这里调用的是nn下的一个模块
3、构造损失函数和优化器
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)4、模型训练(这里还是全部数据)
for epoch in range(100):
# forward
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
# backword
optimizer.zero_grad()
loss.backward()
# update
optimizer.step()
可以尝试不同的激活函数对结果的影响
torch.nn — PyTorch 2.1 documentation
Visualising Activation Functions in Neural Networks - dashee87.github.io
注意:Relu函数取值是0到1,如果最后的输入是小于0的,那么最后输出会是0,但我们可能会算In0,所以一般来说会将最后一层的激活函数改成sigmoid。

九、多分类问题
交叉熵损失和NLL损失到底有什么区别?
lmplementation of classifier to MNIST dataset
- ToTenser:神经网络想要的输入比较小,所以需要转变成一个图像张量
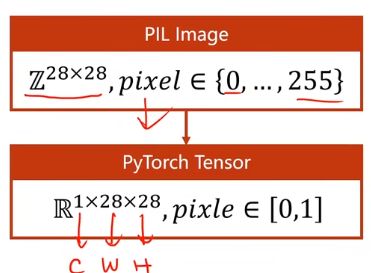
- 黑白图像:单通道
- 彩色图像:通道channel
- Normalize:标准化 切换到 0,1 分布 ,参数为 均值 标准差
- 四阶张量变成二阶张量
- 注意 最后一层不做激活
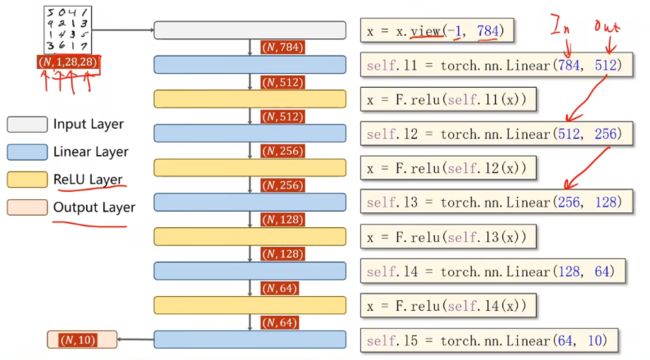
十、CNN 卷积神经网络 基础篇
首先引入 ——
- 二维卷积:卷积层保留原空间信息
- 关键:判断输入输出的维度大小
- 特征提取:卷积层、下采样
- 分类器:全连接
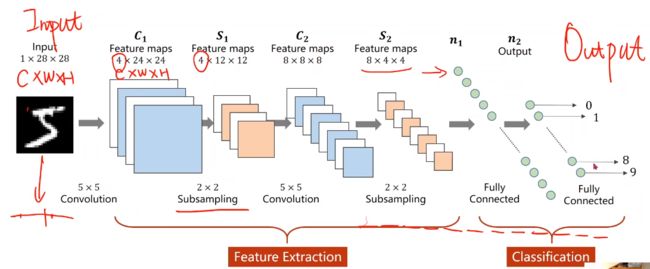
引例:RGB图像(栅格图像)
- 首先,老师介绍了CCD相机模型,这是一种通过光敏电阻,利用光强对电阻的阻值影响,对应地影响色彩亮度实现不同亮度等级像素采集的原件。三色图像是采用不同敏感度的光敏电阻实现的。
- 还介绍了矢量图像(也就是PPT里通过圆心、边、填充信息描述而来的图像,而非采集的图像)
- 红绿蓝 Channel
- 拿出一个图像块做卷积,通道高度宽度都可能会改变,将整个图像遍历,每个块分别做卷积

引例:
深度学习 | CNN卷积核与通道-CSDN博客
实现:A Simple Convolutional Neural Network
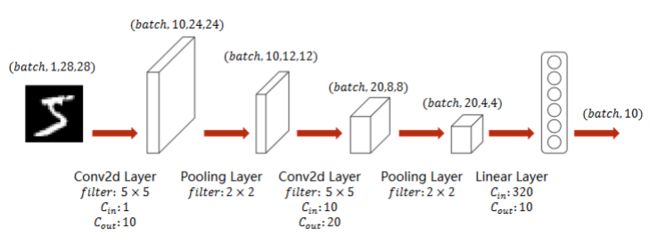
- 池化层一个就行,因为他没有权重,但是有权重的,必须每一层做一个实例
- 交叉熵损失 最后一层不做激活!