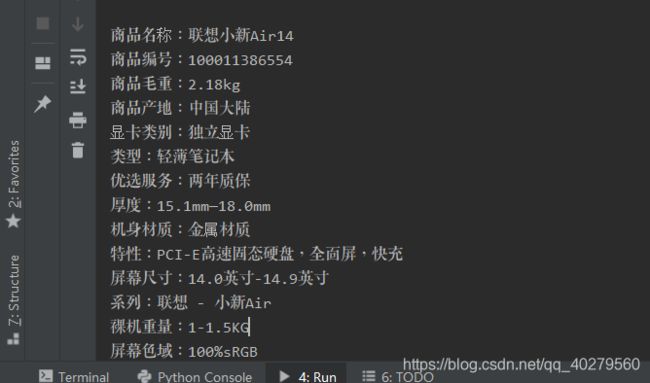
爬虫 获取WebElement内容
爬取
response_comment = browser.get(title_urls)
parameter_list = browser.find_elements_by_xpath('//*[@id="detail"]/div[2]/div[1]/div[1]/ul[2]')
print(parameter_list)
输出
[<selenium.webdriver.remote.webelement.WebElement (session="d80db2395b3847633473c1ac9d1ae2cb", element="70d33cdc-b61e-4bc2-b068-f7bc14a27cfd")>]
<Element html at 0x17aa315ebc8>
修改为
response_comment = browser.get(title_urls)
parameter_list = browser.page_source
details = BeautifulSoup(parameter_list, 'lxml')
ret = details.find('ul', "parameter2 p-parameter-list").text
print(ret)