mybatis一级缓存和二级缓存
计算机有两大基本的功能:计算和存储
存储方面,缓存的设计和实现也是一门学问。这门学问里面包含什么门道呢?不妨研究一下MyBatis缓存类PerpetualCache,一定会大有收获的。在MyBatis里面,存在一个PerpetualCache,它是一级缓存、二级缓存的最基本实现,但PerpetualCache只不过包装了一下HashMap。Perpetual是"永久、不间断"之意,以PerpetualCache为根本,在cache.decorators包里面有多种缓存的代理,实现了各种清除策略。
缓存的设计有两个重点问题:如何存储数据和数据清除策略。
存储的话,用哈希表即可完美解决。对于清除策略而言,往往有多种选择。MyBatis作者Clinton Begin选择Perpetual来命名缓存,暗示这是一个最底层的缓存,数据一旦存储进来,永不清除,如果实现清除策略,请把Perpetual包装一下。在cache.decorators包里面有多种缓存,它们内部串联的主线就是按照“不同的清除策略”来贯穿的。
一、一级缓存
Mybatis对缓存支持,默认情况下,只开启一级缓存,一级缓存只是相对于同一个SqlSession而言。所以参数完全一样的情况下,我们使用同一个SqlSession对象调用相同Mapper的相同方法,只执行一次SQL,这也是一级缓存生成key的策略。因为使用SqlSession第一次查询后,MyBatis会将其放在缓存中,再次查询的时候,如果没有声明刷新,并且缓存没有超时的情况下,SqlSession都会取出当前缓存的数据,而不会再次发送SQL到数据库。
1、同一个SqlSession是什么意思?
这里说的SqlSession不是SqlSessionTemplate,而是指通过DefaultSqlSessionFactory.openSession(执行器) 得到的DefaultSqlSession,当外部请求进来,都会重新生成一个新的DefaultSqlSession,并且在生成DefaultSqlSession的过程中,也会重新创建执行器,这个时候新的DefaultSqlSession和缓存绑定,当请求结束时会关闭DefaultSqlSession和清空一级缓存。
new SimpleExecutor(this, transaction); 创建执行器,同时创建新的一级缓存
中间会调用父类的构造方法BaseExecutor,这里就有重新创建一级缓存对象
protected BaseExecutor(Configuration configuration, Transaction transaction) {
this.transaction = transaction;
//重新生成缓存对象。
this.localCache = new PerpetualCache("LocalCache");
this.localOutputParameterCache = new PerpetualCache("LocalOutputParameterCache");
this.closed = false;
this.configuration = configuration;
}
所以每次重行进来就会新生成一个DefaultSqlSession,那么他的缓存对象也会重新生成,所以说一级缓存级别是SqlSession级别,当执行完commit后,需要关闭sqlSession,在关闭sqlSession的同时也会清空一级缓存
private class SqlSessionInterceptor implements InvocationHandler {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//1、得到新的DefaultSqlSession
SqlSession sqlSession = getSqlSession(.....);
try {
//2、执行查询包括数据和缓存
Object result = method.invoke(sqlSession, args);
if (!isSqlSessionTransactional(sqlSession, SqlSessionTemplate.this.sqlSessionFactory)) {
sqlSession.commit(true);//没有开启事务,就会自动提交事务
}
return result;
} catch (Throwable t) {
...
} finally {
//3、关闭sqlSession
if (sqlSession != null) {
closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);
}
}
}
}
//关闭sqlSession,并且清空一级缓存
@Override
public void close(boolean forceRollback) {
try {
....
} catch (SQLException e) {
。。。。
} finally {
transaction = null;
localCache = null;//清空一级缓存
localOutputParameterCache = null;
closed = true;
}
}
2、一级缓存的生命周期有多长?
1、MyBatis在开启一个数据库会话时,会创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象。Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。
2、如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用。
3、如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用。
4、SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用
3、Demo
下面演示下mybatis和spring整合的项目demo,触发一级缓存sql打印的变化。
@Override
public User doSomeBusinessStuff(String userId) throws Exception {
userMapper.getUser("3");
userMapper.getUser("3");//再次执行相同的查询操作
return null;
}
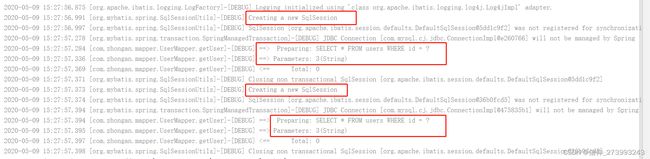
为什么会查询两次,难道没有缓存有问题?上面说了,一级缓存是SqlSession级别的,2次执行getUser方法,都创建了一个新的SqlSession,其实是userMapper的这个接口被spring代理了,里面有个很关键的代码。
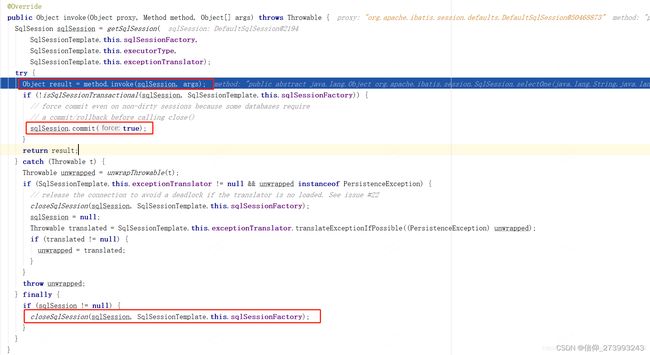
当执行完getUser方法后,会调用Commit和close方法(Commit会清空整个SqlSession的一级缓存),导致第一次和第二次执行getUser得到的SqlSession不是同一个,所以执行了2次sql查询。如果避免commit和close,就要开启事务(不晓得怎么开启事务请查看这边文章:开启事务)
@Transactional
@Override
public User doSomeBusinessStuff(String userId) throws Exception {
userMapper.getUser("3");
userMapper.getUser("3");
return null;
}
打印sql

二、二级缓存
先看下二级缓存的工作机制
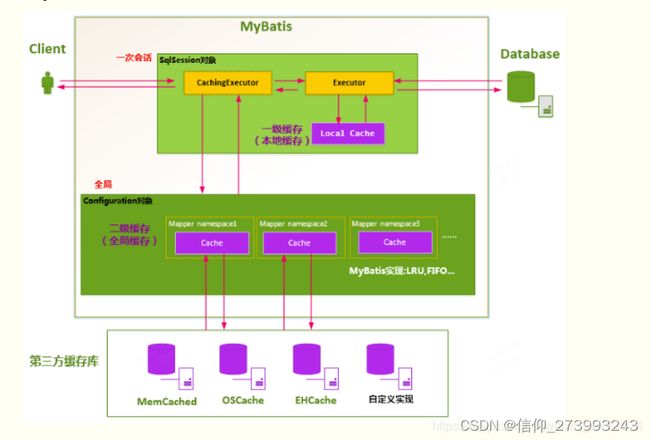
二级缓存默认是不开启的,如果需要开启二级缓存。开启二级缓存有3步,这里介绍使用注解的方式
1、@CacheNamespace(blocking = true)
2、<cache-ref namespace="com.winterchen.dao.UserDao"/>
3、DO实现Serializable接口
在你的Mapper上加上@CacheNamespace(blocking = true)注解就可以了。看下使用二级缓存后打赢出来的日志。
@Override
public User doSomeBusinessStuff(String userId) throws Exception {
userMapper.getUser("3");
userMapper.getUser("3");
return null;
}
为了避免一级缓存影响sql打印,先把事务关了。
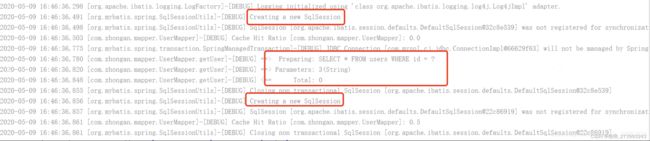
可以发现也是打印了一次sql,但是创建了两次SqlSession,说明第二次是从二级缓存里面取得。二级缓存的select语句将会被缓存,insuret、update、deleted语句会刷新缓存
2、注意
二级缓存有个坑:那就是当你在2个mapper里面都引用了同一张表,就比如,mapper1里面有个User表查询操作,mapper2有个user表更新操作,当再次在mapper1里面在执行查询操作,发现拿到的还更新前的数据。这就是缓存Key生成原则问题,缓存key是通过mapper进行划分的,相同的mapper里面所有方法,使用的是同一个缓存区域,所以不同的mapper里面操作同一张表就会出现上面那种问题。在现实中,线上的一个应用最少2个实例,这个时候,这个问题就暴露出来了,所以缓存最好还是使用第三方缓存插件。
三、一缓存源码介绍
1、缓存存储对象
一级缓存的实现类PerpetualCache,里面其实就是一个HashMap没有过多的并发设计。key是一个Object,他的类型是CacheKey,所以在Map里面put或者get操作时,CacheKey的HashCode方法和equals就很重要了。因为HahsMap源码里面针对Hash碰撞和数据覆盖就会用到这个2个方法。
public class PerpetualCache implements Cache {
private Map<Object, Object> cache = new HashMap<Object, Object>();
}
//Key的设计:CacheKey,很多属性
public class CacheKey implements Cloneable, Serializable {
private final int multiplier;
private int hashcode; //哈希码存到Map里面会用到,这个也是提前生成好的。
private long checksum; //总和校验,当出现复合key的时候,分布计算每个key的哈希码,然后求总和
private int count; //list的数量
private List<Object> updateList; //当出现复合key的时候,保存每个key。
@Override
public boolean equals(Object object) {
。。。。。。
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}
@Override
public int hashCode() {
return hashcode;
}
}
下面是实际使用时CacheKey的截图

关于key的生成规则
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset()); //页码
cacheKey.update(rowBounds.getLimit()); //查询条数
cacheKey.update(boundSql.getSql()); //sql语句
for (ParameterMapping parameterMapping : parameterMappings) {
....
cacheKey.update(value);//将参数转成value,塞进去
}
return cacheKey;
}
hashCode的生成
hashCode的生成是在调用CacheKey的update方法同时设置的,其实update可以把他看做是List的add操作,只不过更改的东西比较多所以叫成update。
public void update(Object object) {
//生成HashCode
int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);
count++;
checksum += baseHashCode;
baseHashCode *= count;
hashcode = multiplier * hashcode + baseHashCode;//更新HashCode
updateList.add(object);
}
小结:keyd的生成需要=MapperId+Offset+Limit+SQL+所有的入参
2、缓存对象的生成
每次请求一进来,会创建新的SqlSession,这个SqlSession是指DefaultSqlSession,不是Spring的SqlSessionTemplate,同时伴随着执行器的创建,在创建执行器的同时,也会重新创建缓存对象。
protected BaseExecutor(Configuration configuration, Transaction transaction) {
this.transaction = transaction;
//重新生成缓存对象。
this.localCache = new PerpetualCache("LocalCache");
this.localOutputParameterCache = new PerpetualCache("LocalOutputParameterCache");
this.closed = false;
this.configuration = configuration;
}
3、一级执行流程
当我们在Service里面调用Dao的方法时,最终会调用BaseExecutor的query方法,下面看下query如何调用一级缓存。
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;//查询一级缓存
if (list == null) {
//缓存为空,走数据库查询
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
return list;
}
//通过数据库查询,在更新缓存内容
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);//查询数据库
localCache.putObject(key, list); //更新一级缓存
return list;
}
四、二级缓存源码
1、开启二级缓存步骤:
步骤1、在Mapper.java类里面添加如下配置
@CacheNamespace(blocking = true)
public interface UserDao{}
eviction: 缓存清除策略,有以下几种 (默认LRU)
LRU – 最近最少使用:移除最长时间不被使用的对象。
FIFO –先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
flushInterval:刷新间隔,以毫秒为单位,时间到了就会在调用语句的时候清空缓存。默认不刷新
size: 缓存的数量(默认1024)
readOnly:只能设置成true或者false。true的情况下缓存返回的数据对象不能被修改,false的情况下会返回缓存对象的拷贝。默认值是false
步骤2 、在具体Mapper.xml里面添加如下配置
<mapper namespace="com.winterchen.dao.UserDao" >
.....
<cache-ref namespace="com.winterchen.dao.UserDao"/>
mapper>
步骤3、DO对象实现接口Serializable接口
public class UserDomain implements Serializable {}
2、下面从源码的角度分析二级缓存
1、解析步骤1和步骤2的配置
//配置的解析是在创建SqlSessionFactory的时候
protected SqlSessionFactory buildSqlSessionFactory() throws IOException {
//解析Mapper解析类
XMLMapperBuilder xmlMapperBuilder = new XMLMapperBuilder(....);
xmlMapperBuilder.parse();//开始解析
。。。。。
}
public void parse() {
if (!configuration.isResourceLoaded(resource)) {
//1、这里会解析Mapper.xml配置文件中的"cache-ref"标签
configurationElement(parser.evalNode("/mapper"));
//2、解析Mapper.java上的注解,创建缓存对象
bindMapperForNamespace();
}
}
先看下解析cache-ref标签
private void configurationElement(XNode context) {
cacheRefElement(context.evalNode("cache-ref")); //解析Mapper.xml的配置文件中的cache-ref标签。
}
解析Mapper上的注解,Mapper加了CacheNamespace注解,同时基于注解配置创建缓存对象
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) {
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
}
}
//1、最终来到parseCache方法创建缓存对象
private void parseCache() {
//type就是我们业务定义的Mapper.java类型,从里拿@CacheNamespace的注解信息
CacheNamespace cacheDomain = type.getAnnotation(CacheNamespace.class);
if (cacheDomain != null) {
//数量
Integer size = cacheDomain.size() == 0 ? null : cacheDomain.size();
//
Long flushInterval = cacheDomain.flushInterval() == 0 ? null : cacheDomain.flushInterval();
Properties props = convertToProperties(cacheDomain.properties());
//创建二级缓存
assistant.useNewCache(cacheDomain.implementation(), cacheDomain.eviction(), flushInterval, size, cacheDomain.readWrite(), cacheDomain.blocking(), props);
}
}
//2、创建缓存对象-BlockingCache
public Cache useNewCache(....) {
//创建Cache对象,注意每个Namespace都有一个独立的Cache对象,也就是以Namespace进行划分,Namespace指的就是我们具体的Mapper.java的类名。
//执行完最终build()方法,最终生成BlockingCache缓存对象。
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval) //缓存的刷新周期
.size(size) //缓存的容量大小
.readWrite(readWrite)
.blocking(blocking) //缓存的是否有阻塞功能
.properties(props)
.build();
configuration.addCache(cache);
存到configuration里面取,查询的时候要用
return cache;
}
3、关于BlockingCache我们看下是什么
BlockingCache是阻塞功能的缓存装饰器,它保证只有一个线程到数据库中查找指定key对应的数据。
假如线程A在BlockingCache中未查找到keyA对应的缓存项时,线程A会获取keyA对应的锁,这样后续线程在查找keyA是会发生阻塞
public class BlockingCache implements Cache {
private final Cache delegate;//缓存实际对象。
//可选项,获取锁定超时时间,如果设置了,在指定时间内没有拿到数据就当获取所失败
private long timeout;
//key就是我们每次查询时基于方法+sql+分页参数生成的key,value是ReentrantLock对象,当相同的方法被调用时会,会通过key拿到对应的ReentrantLock对象,
//当多个线程调用同一个查询方法,那么拿到的ReentrantLock是同一个对象,这时候多个线程就要共同来竞争这个锁了,使用tryLock或者lock来获取锁,前者是带超时时间的。
private final ConcurrentHashMap<Object, ReentrantLock> locks;
public BlockingCache(Cache delegate) {
this.delegate = delegate;
this.locks = new ConcurrentHashMap<Object, ReentrantLock>();
}
}
在构建BlockingCache缓存对象时,虽然是返回了BlockingCache对象,但是BlockingCache里面对象是属性关系有点绕,就像套娃一样,其实他的最终缓存对象就是PerpetualCache类型,这个类型我们在介绍一级缓存的时候说过他了,而PerpetualCache就是对HashMap的一个封装。

4、调用缓存源码
当缓存创建好了,查询请求进来,最终触发CachingExecutor的query方法里面,query方法会先判断二级缓存是否开启,并且二级缓存有数据,没有再走BaseExecutor的query方法,里面会有一级缓存和数据库查询的触发。
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) {
//二级缓存
Cache cache = ms.getCache();//也就是拿到我们上面说的BlockingCache缓存对象
if (cache != null) {
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
//二级缓存没有,走数据库查询和一级缓存查询,对应的也就是上面说的BaseExecutor的query方法逻辑
list = delegate.<E>query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list);
}
return list;
}
//这里走数据库查询和一级缓存查询,对应的也就是上面说的BaseExecutor的query方法逻辑
return delegate.<E>query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
tcm.getObject(cache,key); 这个代码东西比较多,大概流程就是,先通过BlockingCache拿到锁对象,然后查看缓存内是否有数据,如果有就返回并释放锁,如果没有就走下面无缓存的逻辑,也就是查数据库,注意这里不释放锁,只有在commit方法里面会有释放锁的操作,最后在关闭SqlSession的时候在把数据库的数据存到缓存里面去。
下面重点分析tcm.getObject(cache,key)的逻辑,不感兴趣的可以跳过这个小点。
List<E> list = (List<E>) tcm.getObject(cache, key);//先看下tcm是什么
//1、在CachingExecutor里面tcm是TransactionalCacheManager对象。
public class CachingExecutor implements Executor {
//tcm是TransactionalCacheManager对象,他被包装在了CachingExecutor执行器里面,CachingExecutor这个我们知道,其实就是对我们常用的执行一个封装,只不过使用CachingExecutor就可以使用二级缓存了。
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
}
//2、TransactionalCacheManager又是什么
public class TransactionalCacheManager {
//key是Cache类型,Cache的实现类是我们前面说的BlockingCache,
//value是TransactionalCache类型,TransactionalCache是什么?
//我们二级缓存其实是一个大的Map,每个Namespace都有一个BlockingCache
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<Cache, TransactionalCache>();
}
//3、TransactionalCache又是什么
public class TransactionalCache implements Cache {
//保存BlockingCache对象
private final Cache delegate;
//保存未提交事务前的缓存数据,当执行完commit后会把这个数据塞到BlockingCache里面去。
private final Map<Object, Object> entriesToAddOnCommit = new HashMap<Object, Object>();
//读取二级缓存未命中数据的key,这个是做什么用的?
private final Set<Object> entriesMissedInCache = new HashSet<Object>();
public TransactionalCache(Cache delegate) {
this.delegate = delegate; //构建是传进来。
this.clearOnCommit = false;
。。。。。
}
}
当我们调用tcm获取数据时,通过Map里面拿到BlockingCache所对应的TransactionalCache,再调用TransactionalCache的getObject方法,getObject()其实就是调用BlockingCache的getObject()的方法
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
private TransactionalCache getTransactionalCache(Cache cache) {
TransactionalCache txCache = transactionalCaches.get(cache);
if (txCache == null) {
txCache = new TransactionalCache(cache);//通过BlockingCache来创建TransactionalCache对象
transactionalCaches.put(cache, txCache);//在保存起来,前面我们说了BlockingCache是Mapper.Java的维度生成的。
}
return txCache;
}
当调用BlockingCache的getObject(key)时就进到下面了的逻辑中
```java
@Override
public Object getObject(Object key) {
// 获取key对应的锁
acquireLock(key);
// 查询key,此时的delegate
Object value = delegate.getObject(key);
if (value != null) {
// 如果从缓存(PrepetualCache是用HashMap实现的)中查找到,则释放锁,否则继续持有锁
releaseLock(key);
}
//注意如果value是null是不会释放锁的
return value;
}
//获取锁
private void acquireLock(Object key) {
//通过key拿到属于这个key的ReentrantLock对象,因为多个线程调用同一个方法拿到的ReentrantLock是同一个。
Lock lock = getLockForKey(key);
if (timeout > 0) {
boolean acquired = lock.tryLock(timeout, TimeUnit.MILLISECONDS);
if (!acquired) {
throw new CacheException(....);
}
} else {
lock.lock();
}
}
四、总结
总结
一级缓存在BaseExecutor中,作用域是SqlSession
二级缓存在CachingExecutor中,作用域是namespace
两者都会在修改操作时删除缓存,事务回滚时清除缓存
执行顺序为:二级缓存→一级缓存→数据库
一级缓存默认开启,二级缓存默认关闭
1、一级缓存,二级缓存的区别
作用域不同:
一级缓存:当前对象的SqlSession
二级缓存:当前SqlSessionFactory中所有的SqlSession对象
开启方式不同:
一级缓存:默认自动开启
二级缓存:需要主动配置,手动开启
2、一级缓存缺点:
1、线程安全问题
MyBatis的SqlSession并不是线程安全的,因此在多线程环境下使用一级缓存可能会导致问题。如果两个线程共享同一个SqlSession
MyBatis的SqlSession并不是线程安全的,因此在多线程环境下使用一级缓存可能会导致问题。多个线程使用不同的SqlSession,那么在操作同一个表的数据,如果一个SqlSession有缓存,另一个更改了数据,有缓存的SqlSession再次查询时,拿到的就是换粗数据。这就会导致数据不一致的问题。
或者说如果两个线程共享同一个SqlSession,并且其中一个线程执行了一个查询,那么另一个线程,在查询的时候拿到的数据是缓存中的数据,这就会有问题。
2、没有清除机制
MyBatis的一级缓存没有自动清除机制。这意味着如果您在SqlSession中执行了更新、插入或删除操作,那么这些操作将会使缓存失效。但是,如果您在执行这些操作之前没有清除缓存,那么缓存中的数据将会是旧的,这可能会导致应用程序中的错误。
3、内存泄漏问题
MyBatis的一级缓存存储在内存中,因此如果您在应用程序中长时间使用同一个SqlSession,那么缓存中的数据可能会占用大量内存。这可能会导致内存泄漏问题,尤其是在长时间运行的应用程序中。
2、二级缓存问题:
如果是多节点部署的情况下,每个节点持有自己的缓存对象,那么在操作的时候,必然会导致读的一方,因为缓存拿到了错误的数据。
不过可以控制二级缓存刷新时间:在不设置缓存刷新时间,默认情况下查询不会刷新缓存,新增、删除、更新都是刷新缓存可以设置flushCache属性,true是刷新缓存,false是不刷新缓存