【python学习笔记】python常用模块
python常用模块
1、标准库和第三方包
1.1、引入和使用标准库
- import module
- from module import XXX
- import module as other_name
>>> import math
>>> math.pow(2,3)
8.0
>>> from math import pow
>>> pow(2,3)
8.0
>>> from math import *
>>> import math as shuxue
>>> shuxue.pow(2,3)
8.0
>>> import numpy as np
1.2、安装、引入和使用第三方包
- 安装:pip install package_name
- 来源:https://pypi.org/
C:\Users\Winner>pip install requests
Collecting requests
Downloading requests-2.27.1-py2.py3-none-any.whl (63 kB)
|████████████████████████████████| 63 kB 573 kB/s
Collecting charset-normalizer~=2.0.0
Downloading charset_normalizer-2.0.10-py3-none-any.whl (39 kB)
Collecting idna<4,>=2.5
Downloading idna-3.3-py3-none-any.whl (61 kB)
|████████████████████████████████| 61 kB 437 kB/s
Collecting urllib3<1.27,>=1.21.1
Downloading urllib3-1.26.8-py2.py3-none-any.whl (138 kB)
|████████████████████████████████| 138 kB 344 kB/s
Collecting certifi>=2017.4.17
Downloading certifi-2021.10.8-py2.py3-none-any.whl (149 kB)
|████████████████████████████████| 149 kB 218 kB/s
Installing collected packages: urllib3, idna, charset-normalizer, certifi, requests
Successfully installed certifi-2021.10.8 charset-normalizer-2.0.10 idna-3.3 requests-2.27.1 urllib3-1.26.8
安装指定版本:
pip install requests==2.0
升级已经安装的包:
pip install --upgrade requests
查看已安装的第三方包
pip list
删除已安装的第三方包或库
pip uninstall requests
更换源,使用国内的镜像,清华大学开源软件镜像站
https://mirror.tuna.tsinghua.edu.cn/help/pypi/
pypi 镜像使用帮助
pypi 镜像每 5 分钟同步一次。
临时使用
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
注意,simple 不能少, 是 https 而不是 http
设为默认
升级 pip 到最新的版本 (>=10.0.0) 后进行配置:
pip install pip -U
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
如果您到 pip 默认源的网络连接较差,临时使用本镜像站来升级 pip:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pip -U
2、编写和发布模块
2.1、模块和包的结构
模块:.py文件
Python搜索路径
>>> import module
laoqi
数据准备和特征工程
>>> b = module.Book('winner')
>>> b.get_name()
'winner'
>>>
class Book:
lang = 'learn python with winner'
def __init__(self, author):
self.author = author
def get_name(self):
return self.author
def new_book():
return "数据准备和特征工程"
if __name__ == "__main__":
python = Book('winner')
author_name = python.get_name()
print(author_name)
published = new_book()
print(published)
__name__是任何对象的一个属性,在执行此程序时,name == “main”,而当此程序作为模块被引用时,__name__是module,if条件语句就不满足,下面的代码就不会执行
>>> module.__name__
'module'
python的搜索路径
>>> import sys
>>> sys.path
['', 'C:\\Users\\Winner\\AppData\\Local\\Programs\\Python\\Python39\\python39.zip', 'C:\\Users\\Winner\\AppData\\Local\\Programs\\Python\\Python39\\DLLs', 'C:\\Users\\Winner\\AppData\\Local\\Programs\\Python\\Python39\\lib', 'C:\\Users\\Winner\\AppData\\Local\\Programs\\Python\\Python39', 'C:\\Users\\Winner\\AppData\\Local\\Programs\\Python\\Python39\\lib\\site-packages']
>>> sys.path.append('D:\Desktop\深度学习从零入门深度学习\零基础掌握 Python 入门到实战ppt\coding')
>>> sys.path
['', 'C:\\Users\\Winner\\AppData\\Local\\Programs\\Python\\Python39\\python39.zip', 'C:\\Users\\Winner\\AppData\\Local\\Programs\\Python\\Python39\\DLLs', 'C:\\Users\\Winner\\AppData\\Loc
al\\Programs\\Python\\Python39\\lib', 'C:\\Users\\Winner\\AppData\\Local\\Programs\\Python\\Python39', 'C:\\Users\\Winner\\AppData\\Local\\Programs\\Python\\Python39\\lib\\site-packages', 'D:\\Desktop\\深度学习从零入门深度学习\\零基础掌握 Python 入门到实战ppt\\coding']
包:有一定层次的目录结构
“.py”文件或子目录
init.py 这个文件即使为空,也要写到包里面

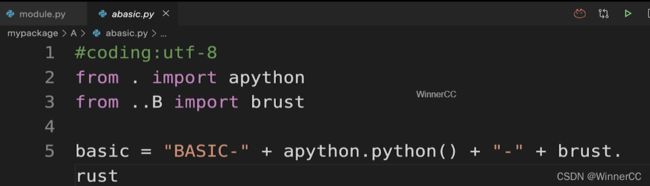
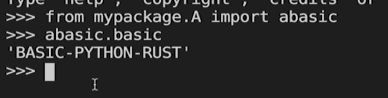
向pypi网站发布自己的第三方包
3、IO操作之文件读写
3.1、文件读写的一般方法
>>> import os
>>> os.getcwd()
'C:\\Users\\Winner\\AppData\\Local\\Programs\\Python\\Python39'
>>> f = open("test.txt","w")
>>> f.write('Life is short,you need python')
29
>>> f.close() #用这种方法,如果不close,写入的内容不会保存
>>> f = open('test.txt')
>>> f.read()
'Life is short,you need python'
>>> dir(f)
['_CHUNK_SIZE', '__class__', '__del__', '__delattr__', '__dict__', '__dir__', '__doc__', '__enter__', '__eq__', '__exit__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '_checkClosed', '_checkReadable', '_checkSeekable', '_checkWritable', '_finalizing', 'buffer', 'close', 'closed', 'detach', 'encoding', 'errors', 'fileno', 'flush', 'isatty', 'line_buffering', 'mode', 'name', 'newlines', 'read', 'readable', 'readline', 'readlines', 'reconfigure', 'seek', 'seekable', 'tell', 'truncate', 'writable', 'write', 'write_through', 'writelines']
#使用上下文管理器则不用close
>>> with open("test.txt","a") as f:
f.write("\n跟XX学python")
11
>>> f = open("test.txt")
>>> for line in f:
print(line)
Life is short,you need python
跟XX学python
>>> help(print)
Help on built-in function print in module builtins:
print(...)
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
#由于print函数默认end='\n',所以会多打一个换行
>>> for line in f:
print(line,end='')
#由于f是一个迭代器对象,上一次循环之后,指针在最后面,再次循环前需要把指针位置改到最前面>>> f.seek(0)
0
>>> for line in f:
print(line,end='')
Life is short,you need python
跟XX学python
| 模式 | 说明 |
|---|---|
| r | 以读的方式打开文件。默认打开模式 |
| w | 以写的方式打开文件。如果文件已经存在,则覆盖原文件,否则新建文件 |
| a | 以写的方式打开文件。如果文件已经存在,则指针在文件的最后,实现向文件中追加新内容;否则,新建文件。 |
| b | 以二进制模式打开文件。不单独使用,配合r/w/a等模式使用 |
| + | 同时实现读写操作。不单独使用,配合r/w/a等模式使用 |
| x | 创建文件,如果文件存在,则无法创建 |
3.2、读写特定文件类型
2.1 csv文件读写
与上面不同的是,csv文件的读写除了文件对象(f)之外,还需创建写读对象(writer、reader)
>>> import csv
>>> data=[['name','number'],['python',111],['java',222],['php',333]]
>>> with open('csvfile.csv','w') as f:
writer = csv.writer(f)
writer.writerows(data)
>>> f = open('csvfile.csv')
>>> reader = csv.reader(f)
>>> for row in reader:
print(row)
['name', 'number']
[]
['python', '111']
[]
['java', '222']
[]
['php', '333']
[]
2.2 xlsx文件读写
注意:在excel文件中,起始行从1开始,而非0
>>> from openpyxl import Workbook
>>> wb = Workbook()
>>> ws = wb.active
>>> ws.title
'Sheet'
>>> ws.title = 'python'
>>> ws.title
'python'
>>> ws2 = wb.create_sheet('java')
>>> ws2.title
'java'
>>> wb.sheetnames
['python', 'java']
>>> ws['E1'] = 111
>>> ws.cell(row=2,column=2,value=222)
<Cell 'python'.B2>
>>> wb.save('example.xlsx')
4、异常处理
异常Exception 用异常对象(exception object)表示异常情况。异常是类
查看异常类:dir(builtins)
try:
#被检测的语句块
except 异常类名 as err: #as err 是可选功能 - 输出错误原因,err是错误原因名。
#异常处理语句块
#如果被检测的语句块没有异常, 则忽略except后面的语句,否则执行异常处理语句块。
except (异常类名1,异常类名2):
#多个异常一起处理,用这个格式。若不给出异常类名,则只要有异常就执行异常处理语句
except Exception as err:
#只要有异常就执行异常处理语句,并输出此异常名
else:
#else语句块,无异常时执行
finally:
#无论是否发生异常,finally子句都要被执行
编程时区分不同的异常,采用不同的处理方案
class Caculator:
is_raise = False
def calc(self,express):
try:
return eval(express)
except ZeroDivisionError:
if self.is_raise:
return "Zero can no be division"
else:
raise
if __name__ == "__main__":
c = Caculator()
print(c.calc("8/0"))
报错:
return eval(express)
File "" , line 1, in <module>
ZeroDivisionError: division by zero
while True:
try:
a = float(input('first number:'))
b = float(input('second number:'))
r = a/b
print("{0}/{1}={2}".format(a,b,r))
break
except ZeroDivisionError:
print("The second number can not be zero. Try again.")
except ValueError:
print('Please enter number. Try again')
except:
break
first number:1
second number:0
The second number can not be zero. Try again.
first number:1
second number:a
Please enter number. Try again
first number:1
second number:2
1.0/2.0=0.5
多个异常一起处理:
except (ZeroDivisionError,ValueError):
print("The second number can not be zero. Try again.")
5、语音合成
使用SDK
-
SDK:Software Development Kit,中文为:软件开发工具包,一般都是一些软件工程师为特定的软件包、软件框架、硬件平台、操作系统等建立应用软件时的开发工具集合
-
API:Application Programming Interface,应用程序接口。是一些预先定义的函数,或指软件系统不同组成部分衔接的约定。目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问原码,或理解内部工作机制的细节。
https://ai.baidu.com/
根据说明文档https://ai.baidu.com/ai-doc/SPEECH/zk4nlz99s
1、安装使用Python SDK
pip install baidu-aip
2、在百度云控制台中创建一个APP
3、新建AipSpeech
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
4、仔细阅读接口说明
这个代码生成的音频文件无法播放
from aip import AipSpeech
import json
APP_ID = '25533'
API_KEY = 'GuYRDkKkypZHhNxDl4F'
SECRET_KEY = 'BHmDtbzWbG4gSvTnmfOGq1v'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
s = '你好'
result = client.synthesis(s, 'zh', 1, {
'vol': 5,
'per': 3,
'spd': 6,
'pit': 3,
})
if not isinstance(result, dict):
with open('audio.mp3', 'wb') as f:
f.write(result)
#f.write(json.dumps(speak).encode())
6、网络爬虫
pip install lxml
import re
import json
from datetime import datetime
import pandas as pd
import requests
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
page = requests.get(url).content.decode("utf-8")
regexp = "