干货:浏览器渲染引擎Webkit和V8引擎工作原理
浏览器的历史
W3C在80年代后期90年代初期发明了世界上第一个浏览器WorldWideWeb(后更名为Nexus),支持文本/简单的样式表/电影/声音和图片
1993年,网景(netscape)浏览器诞生,没有JavaScript,没有css,只显示简单的html元素
1995年,微软推出闻名世界的IE浏览器,自此第一次浏览器大战打响,IE受益于Windows系统获得空前的成功,逐渐取代网景浏览器
1998年处于低谷的网景成立了Mozilla基金会,在该基金会推动下,开发了著名的开源项目Firefox并在2004年发布1.0版本,拉开了第二次浏览器大战的序幕,IE发展更新较缓慢,Firefox一推出就深受大家的喜爱,市场份额一直上升。
在Firefox浏览器发布1.0版本的前一年,2003年,苹果发布了Safari浏览器,并在2005年释放了浏览器中一种非常重要部件的源代码,发起了一个新的开源项目WebKit
2008年,Google以苹果开源项目WebKit作为内核,创建了一个新的项目Chromium,在Chiromium的基础上,Google发布了Chrome
Webkit模块和其依赖模块

上图是WebKit模块和其依赖模块的关系。
在操作系统之上的是WebKit赖以工作的众多第三方库,如何高效使用它们是WebKit和各大浏览器厂商的一个重大课题。
WebCore部分都是加载和渲染的基础部分
WebKit Ports是WebKit非共享部分,对于不同浏览器移植中由于平台差异/依赖的第三方库和需求不同等方面原因,往往按照自己的方式来设计和实现。
在WebCore/js引擎/WebKitPorts之上主要是提供嵌入式编程接口,提供给浏览器调用。
页面加载解析渲染过程简介

如上图所示,图中虚线是与底层第三方库交互。
当访问一个页面的时候,会利用网络去请求获取内容,如果命中缓存了,则会在存储上直接获取;
如果内容是个HTML格式,首先会找到html解释器进行解析生成DOM树,解析到style的时候会找到css解释器工作得到CSSOM,解析到script会停止解析并开始解析执行js脚本;
DOM树和CSSOM树会构建成一个render树,render树上的节点不和DOM树一一对应,只有显示节点才会存在render树上;
render树已经知道怎么绘制了,进入布局和绘图,绘制完成后将调用绘制接口,从而显示在屏幕上。
从资源的字节流到DOM树
上面我们简单介绍了整个过程,现在我们开始认识一下各个步骤的具体过程。

字节流经过解码后是字符流,然后通过词法分析器会被解释成词语(Tokens),之后经过语法分析器构建成节点,最后这些节点组成一棵DOM树
-
词法分析
在进行词法分析前,解释器首先要检查网页内容实用的编码格式,找到合适的解码器,将字节流转换成特定格式的字符串,然后交给词法分析器进行分析。
每次词法分析器都会根据上次设置的内部状态和上次处理后的字符串来生成一个新的词语。内部使用了超过70种状态。(ps:生成的词语还会进过XssAutitor验证词语是否安全合法,非合法的词语不能通过)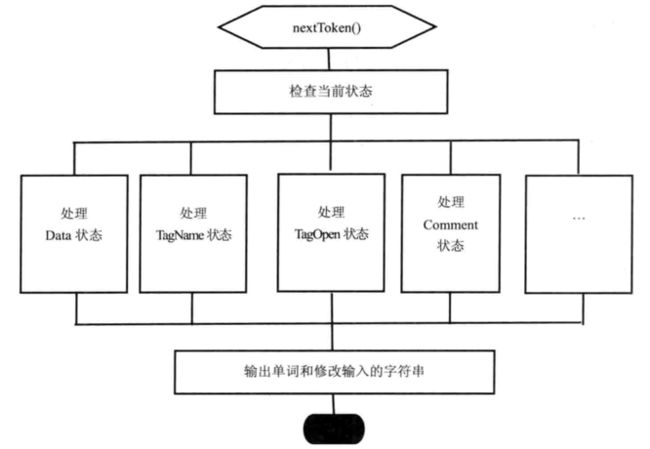
如上图所示,举个例子

1 接收到"<"进入TagOpen状态
2 接收"d",根据当前状态是TagOpen判断进入TagName状态,之后接收"i"/"v"
3 接收">"进入TagEnd状态,此时得到了div的开始标签(StartTag)
4 接收"<"进入TagOpen,接收"img"后接收到空格得到了img开始标签
6 进入attribute一系列(笔者自己命名的,不知道叫啥)状态,得到了src属性吗和"/a"属性值
6 同样方式获得div结束标签
- 词语到节点
得到词语(Tokens)后,就可以开始形成DOM节点了。
注意:这里说的节点不单单指HTMLElement节点,还包括TextNode/Attribute等等一系列节点,它们都继承自Node类。
词语类型只有6种,DOCTYPE/StartTag/EndTag/Comment/Character/EndOfFile - 组成DOM树
因为节点都可以看成有开始和结束标记,所以用栈的结构来辅助构建DOM树再合适不过了。
再拿上述的html代码做例子。
webkit xiha
1 遇到div开始标签,将div推入栈;
2 遇到img开始标签,将img推入栈;
3 遇到src属性,将src推入栈;
4 将src从栈中取出,作为DOM树的一部分;
5 遇到img结束标签,说明img包裹着src属性,取出img,作为src的父亲节点;
6 遇到span开始标签,将span推入栈;
7 遇到文本webkit,将文本推入栈;
8 取出webkit文本,待分发;
9 遇到span结束标签,说明span标签包裹着webkit文案,取出span标签,作为文本webkit的父亲节点;
10 遇到div结束标签,取出div标签,说明div标签包裹着img和span,作为它们的公共父亲节点
看了winter的《重学前端》中《一个浏览器是如何工作的》篇章,推翻了上述说法的过程,DOM树的构建不是从叶子到根的构建过程(自底向上),而是从根到叶子的构建过程(自顶向下)。
1 接收到div开始标签,将div推入栈,并且在DOM树上添加div节点,栈顶的节点表示了当前的父节点;
2 接收img开始标签,将img推入栈,根据栈中前一个节点,img是div的子节点,在DOM树上:在div节点下添加img节点
3 接收src属性,非独立节点,直接添加到img节点下;
4 接收img结束标签,将栈中img开始标签退栈;
5 接收span开始标签,将span推入栈,根据栈中前一个节点,span是div的子节点,在DOM树上:在div节点下添加span节点;
6 接收文本节点webkit,推入栈,在DOM树上,在span节点下添加“webkit”文本节点;
7 接收文本节点xiha,根据之前栈顶节点依旧是文本节点,直接将该文本节点合并到前面的文本节点“webkit xiha”;
8 接收span结束标签,一直执行退栈操作直到将span开始标签也离开了;
9 接收div结束标签,退栈;
10 接收endOfFile,DOM树构建结束;
该栈是HTMLElementStack,该栈的主要作用就是帮助DOM树维护当前的父节点是哪一个(栈顶这个),并且合并可以合并的词语。
CSS解析
WebKit 使用 Flex 和 Bison 解析器生成器,通过 CSS 语法文件自动创建解析器。最后WebKit将创建好的结果直接设置到StyleSheetContents对象中。
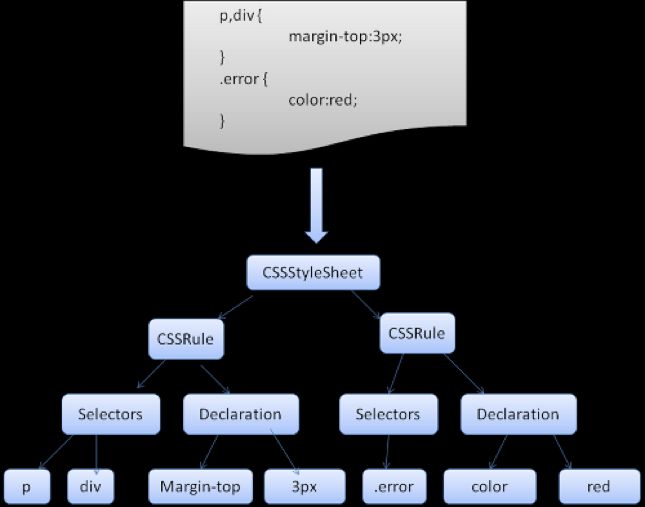
- 规则匹配
当WebKit需要为HTML元素创建RenderObject类(后面会讲到)的时候(当样式规则建立完成后且DOM树已经有内容的时候),首先会先去获取样式信息,得到RenderStyle对象——包含了匹配完的结果样式信息。
根据元素的标签名/属性检查规则,从规则查找匹配的规则,Webkit把这些规则保存在匹配结果中。
最后Webkit对这些规则进行排序,整合,将样式属性值返回。 - 脚本设置CSS
CSSOM在DOM中的一些节点接口加入了获取和操作css属性的JavaScript接口,因而JavaScript可以动态操作css样式。
CSSOM定义了样式表的接口CSSStyleSheet,document.styleshheets可以查看当前网页包含的所有css样式表
W3C定义了另外一个规范,CSSOM View,增加一些新的属性到Window,Document,Element,MounseEvent等接口,这些CSS的属性能让JavaScript获取视图信息
至此我们已经了解到了文档的解析过程,这里有一些实验可以帮助你更好的了解页面加载过程发生了什么。聊聊浏览器的渲染机制——若邪Y
布局
只要发生样式的改变,都会触发检查是否需要布局计算
当首次加载页面/renderStyle改变/滚动操作的时候,都会触发布局
布局是比较耗时的操作,更糟糕的时候布局的下一步就是渲染,我们可以通过硬件加速来跳过布局和渲染,下面我们会讲到。
多进程的浏览器
一个好的程序常常被划分为几个相互独立又彼此配合的模块,浏览器也是如此,以 Chrome 为例,它由多个进程组成,每个进程都有自己核心的职责,它们相互配合完成浏览器的整体功能,每个进程中又包含多个线程,一个进程内的多个线程也会协同工作,配合完成所在进程的职责。
Chrome 采用多进程架构,其顶层存在一个 Browser process 用以协调浏览器的其它进程。
具体说来,Chrome 的主要进程及其职责如下:
Browser Process:
负责包括地址栏,书签栏,前进后退按钮等部分的工作; 负责处理浏览器的一些不可见的底层操作,比如网络请求和文件访问;
Renderer Process:
负责一个 tab 内关于网页呈现的所有事情
Plugin Process:
负责控制一个网页用到的所有插件,如 flash
GPU Process
负责处理 GPU 相关的任务
通过「页面右上角的三个点点点 --- 更多工具 --- 任务管理器」即可打开相关面板
加载页面各进程的合作
处理输入
Browser Process 需要判断用户输入的是 URL 还是 query;
开始导航
当用户点击回车键,Browser Process 通知 network thread 获取网页内容,并控制 tab 上的 spinner 展现,表示正在加载中。
读取响应
当请求响应返回的时候,network thread 会依据 Content-Type 及 MIME Type sniffing 判断响应内容的格式
如果响应内容的格式是 HTML ,下一步将会把这些数据传递给 renderer process,如果是 二进制流或者其它文件,会把相关数据传输给下载管理器。
查找渲染进程
当上述所有检查完成,network thread 确信浏览器可以导航到请求网页,network thread 会通知 Browser Process 数据已经准备好,Browser Process 会交给 renderer process 进行网页的渲染。
确认导航
经过了上述过程,数据以及渲染进程都可用了, Browser Process 会给 renderer process 发送 IPC 消息来确认导航,一旦 Browser Process 收到 renderer process 的渲染确认消息,导航过程结束,页面加载过程开始。
此时,地址栏会更新,展示出新页面的网页信息。history tab 会更新,可通过返回键返回导航来的页面,为了让关闭 tab 或者窗口后便于恢复,这些信息会存放在硬盘中。
渲染
RenderObject
DOM树构建完成之后,Webkit还要为DOM树构建RenderObject树。
什么情况下会为一个DOM节点建立新的RenderObject对象呢
1.ducument节点
2.可视节点,例如html,body,div等。而WebKit不会为非可视化节点创建RenderObject节点,例如link,head,script
3.某些情况下WebKit会建立匿名的RenderObject,该RenderObject不对应DOM树的任何节点,例如匿名的RenderBlock
tip:
如果一个节点即包含块级节点又包含内联节点,会为内联节点创建一个RenderBlock,即形成
RenderObject——RenderObject
——RenderBlock——RenderObject
RenderLayer
网页是可以分层的,可以让WebKit在渲染处理上获得便利。
会产生RenderLayer的情况:
- document节点和html节点
- 显示定义position属性的RenderObject
- 节点有overflow/alpha等效果RenderObject
- 使用canvas2d或者webgl技术,(注:canvas节点创建的时候不会马上生成RenderLayer对象,在js创建了2d或者3d上下文的时候才创建
- Video节点对应的RenderObject
RenderObject对象知道如何绘制自己了,需要调用绘图上下文来进行绘图操作。
渲染方式:软件渲染(Cpu完成)和硬件加速渲染(Gpu完成)
软件渲染
Renderer进程消息循环调用判断是否需要重新计算的布局和更新,如要
Renderer进程创建共享内存
WebKit计算重绘区域中重叠的RenderObject,RenderObject重新绘制,绘制结果到共享内存的位图中
绘制完成后,Renderer进程发生消息给Browser进程,Browser进程将更新的区域将共享内存的内容绘制到自己对应存储区域中(绘制过程不会影响该网页结果的显示)
Browser进程回复消息给Renderer,回收共享内存
Browser进程绘制到窗口
硬件渲染
GPU硬件进行绘图和合成,每个网页的Renderer进程都是将之前介绍的3D绘图和合成操作传递给GPU进程,由它来统一调度 和执行,在移动端中,GPU进程并不存在,WebKit将所有工作放在Browser进程中的一个线程完成。
GPU进程处理一些命令后,会向Renderer进程报告自己当前的状态,Renderer进程通过检查状态信息和自己的期望结果来确定是否满足自己的条件。GPU进程最终绘制的结果不再像软件渲染那样通过共享内存的方式传递给Browser进程,而是直接将页面的内容绘制在浏览器的标签窗口
理想情况,每一个层都会有个存储区域,保存绘图结果,最后将这些层的内容合并(compositing)
软件渲染机制是没有合成阶段的,软件渲染的结果是一个位图(bitmap),绘制每一层的时候都使用该位图,区别在于绘制的位置可能不一样,每一层按照从后前的顺序。这样软件绘图使用的只是一块内存空间即可。
软件渲染只能处理2D方面的操作,并且在高fps的绘图中性能不好,比如视频和canvas2d等,但是cpu使用的缓存机制有效减少了重复绘制的开销
硬件绘制和所有的层的合成都使用Gpu完成,硬件加速渲染能支持现在所有的html5定义的2d和3d绘图标准;另外,由于软件渲染没有为每一层提供后端存储,因而需要将和某区域有重叠部分的所有层次相关区域重新绘制一次,而硬件加速渲染只需重新绘制更新发生的层次。
实验时间:利用CSS3D启动硬件加速的优势
#box {
position: relative;
width: 100px;
height: 100px;
background: #ccc;
transform: translate3d(0,0,0);
transition: transform 2s linear;
}
#box.move {
transform: translate3d(100px,0,0) !important
}
#box2 {
position: relative;
width: 100px;
height: 100px;
background: #ccc;
left: 0;
transition: left 2s linear;
}
#box2.move {
left: 100px !important
}
var box2 = document.getElementById('box2')
setTimeout(() => {
box2.classList.add('move')
}, 200);首先我们看下利用开发者工具Layers可以看到,如下图,box1利用了transform3d,从而判断需要为box1独立一层,而其他的内容则依旧附在document层。

我们切换到performance进行录制,查看event log如下图。发现在box2在移动的时候,不断重复5各过程:
recalculate style——layout——update layer tree——paint——composite layers
也就是说document层不断得重新计算布局,重新渲染,再和box2合并layers,这造成了巨大的浪费。我们接下来来看一些box1的移动。

var box = document.getElementById('box1')
setTimeout(() => {
box.classList.add('move')
}, 200);
如下图,在box1移动的时候,没有了布局和绘制的过程,利用CSS3D加速,只需要在合并层之前改变属性,再次合并层就可以了,不需要重新布局,也没有绘制步骤,这就是为什么我们在写动画的时候要时候3d启用硬件加速的原因,大大减少了布局绘制的资源浪费。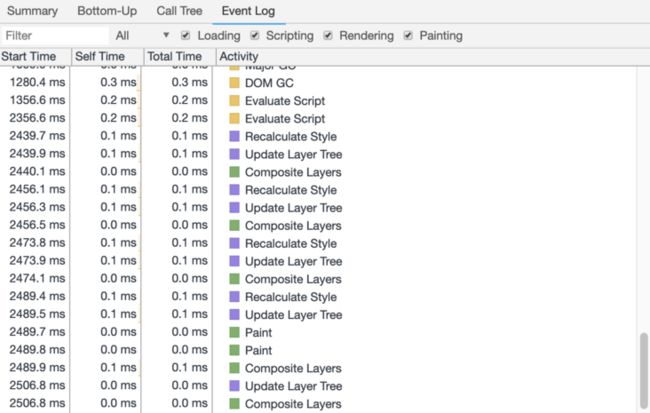
V8引擎
上面我们已经把渲染过程了解清楚了,接下来来看一下V8引擎这个重头戏吧~!
V8引擎和渲染引擎通信
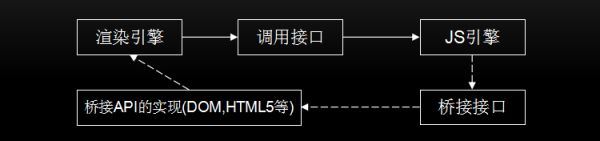
当用户在屏幕上触发诸如 touch 等手势时,首先收到手势信息的是 Browser process, 不过 Browser process 只会感知到在哪里发生了手势,对 tab 内内容的处理是还是由渲染进程控制的。
事件发生时,浏览器进程会发送事件类型及相应的坐标给渲染进程,渲染进程随后找到事件对象,交给js引擎处理,如果js代码中利用了侨界接口将该节点绑定了事件监听,那么就会触发该事件监听函数。
字节码 机器码 JIT

编译型语言如c/c++,处理该语言实际上使用编译器直接将它们编译成本地代码,用户只是使用这些编译好的本地代码,被系统的加载起加载执行,这些本地代码由操作系统调度CPU直接执行
java做法是明显的两个阶段,首先是编译,不像c/c++编译成本地代码,而是编译生成字节码,字节码是跨平台的中间表示,然后java虚拟机加载字节码,使用解释器执行这些代码。
V8之前的版本直接的将抽象语法树通过JIT技术转换成本地代码,放弃了在字节码阶段可以进行的一些性能优化,但保证了执行速度。在V8生成本地代码后,也会通过Profiler采集一些信息,来优化本地代码。虽然,少了生成字节码这一阶段的性能优化,但极大减少了转换时间。
但是在2017年4月底,v8 的 5.9 版本发布了,新增了一个 Ignition 字节码解释器,将默认启动
- (主要动机)减轻机器码占用的内存空间,即牺牲时间换空间
- 提高代码的启动速度
故事得从 Chrome 的一个 bug 说起: http://crbug.com/593477 。Bug 的报告人发现,当在 Chrome 51 (canary) 浏览器下加载、退出、重新加载 facebook 多次,并打开 about:tracing 里的各项监控开关,可以发现第一次加载时 v8.CompileScript 花费了 165 ms,再次加载加入 V8.ParseLazy 居然依然花费了 376 ms。按说如果 Facebook 网站的 js 脚本没有变,Chrome 的缓存功能应该缓存了对 js 脚本的解析结果,不该花费这么久。这是为什么呢?
这就是之前 v8 将 JS 代码编译成机器码所带来的问题。因为机器码占空间很大,v8 没有办法把 Facebook 的所有 js 代码编译成机器码缓存下来,因为这样不仅缓存占用的内存、磁盘空间很大,而且再次进入时序列化、反序列化缓存所花费的时间也很长,时间、空间成本都接受不了。
在启动速度方面,如今内存占用过大的问题消除了,就可以提前编译所有代码了。因为前端工程为了节省网络流量,其最终 JS 产品往往不会分发无用的代码,所以可以期望全部提前编译 JS 代码不会因为编译了过多代码而浪费资源。v8 对于 Facebook 这样的网站就可以选择全部提前编译 JS 代码到字节码,并把字节码缓存下来,如此 Facebook 第二次打开的时候启动速度就变快了。下图是旧的 v8 的执行时间的统计数据,其中 33% 的解析、编译 JS 脚本的时间在新架构中就可以被缩短。

v8 自身的重构方面,有了字节码,v8 可以朝着简化的架构方向发展,消除 Cranshaft 这个旧的编译器,并让新的 Turbofan 直接从字节码来优化代码,并当需要进行反优化的时候直接反优化到字节码,而不需要再考虑 JS 源代码。最终达到如下图所示的架构。
其实,Ignition + TurboFan 的组合,就是字节码解释器 + JIT 编译器的黄金组合。这一黄金组合在很多 JS 引擎中都有所使用,例如微软的 Chakra,它首先解释执行字节码,然后观察执行情况,如果发现热点代码,那么后台的 JIT 就把字节码编译成高效代码,之后便只执行高效代码而不再解释执行字节码。
隐藏类
在V8中建立类有两个主要的理由,即(1)将属性名称相同的对象归类,及(2)识别属性名称不同的对象。同一类中的对象有完全相同的对象描述,而这可以加速属性存取。
在V8,符合归类条件的类会配置在各种JavaScript对象上。对象引用所配置的类。然而这些类只存在于V8作为方便之用,所以它们是「隐藏」的。
如果对象的描述是相同的,那么隐藏类也会相同。如下图的例子中,对象p和q都属于相同的隐藏类。
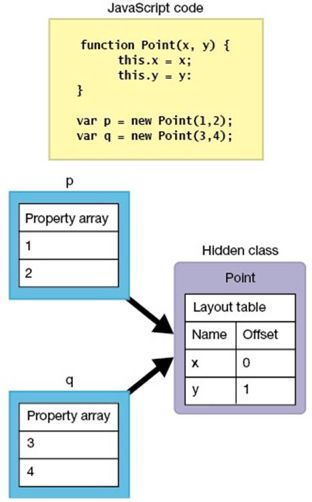
我们随时可以在JavaScript中新增或删除属性。然而当此事发生时会毁坏归类条件(归纳名称相同的属性)。V8借由建立属性变化所需的新类来解决。属性改变的对象透过一个称为「类型转换(class transition)」的程序纳入新级别中。
在类中储存类变换信息当在对象p中加入新属性z时,V8会在Point类内的表格上记录「加入属性z,建立类Point2」。
当同一Point类的对象q加入属性z时,V8会先搜寻Point类表。如果它发现了Point2类已加入属性z时,就会将对象q设定在Point2类。
所以,当我们不断利用js弱类型的特点改变某属性的类型,比如a.x=1;a.x='hello';除了让一起开发的同事摸不着头脑这个属性究竟是什么玩意,还将会不断破坏隐藏类,带来一定的性能损坏。所以,在日常开发中,因避免改变变量或者对象属性的类型。引入TS吧!是时候拥抱TS大法了哈哈哈。

内嵌内存
正常访问对象属性的过程是:首先获取隐藏类的地址,然后根据属性名查找偏移值,然后计算该属性的地址。虽然相比以往在整个执行环境中查找减小了很大的工作量,但依然比较耗时。能不能将之前查询的结果缓存起来,供再次访问呢?当然是可行的,这就是内嵌缓存。
内嵌缓存的大致思路就是将初次查找的隐藏类和偏移值保存起来,当下次查找的时候,先比较当前对象是否是之前的隐藏类,如果是的话,直接使用之前的缓存结果,减少再次查找表的时间。当然,如果一个对象有多个属性,那么缓存失误的概率就会提高,因为某个属性的类型变化之后,对象的隐藏类也会变化,就与之前的缓存不一致,需要重新使用以前的方式查找哈希表。
垃圾回收
V8的垃圾回收策略基于分代回收机制,该机制又基于 世代假说。该假说有两个特点:
- 大部分新生对象倾向于早死;
- 不死的对象,会活得更久。
在V8中,将内存分为了新生代(new space)和老生代(old space)。它们特点如下:
新生代:对象的存活时间较短。新生对象或只经过一次垃圾回收的对象。
老生代:对象存活时间较长。经历过一次或多次垃圾回收的对象。 -
新生代内存回收
新生代中的对象主要通过 Scavenge 算法进行垃圾回收。Scavenge 的具体实现,主要采用了Cheney算法。
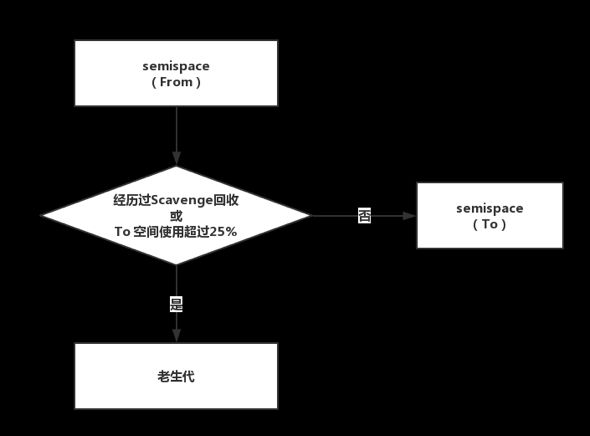
Cheney算法采用复制的方式进行垃圾回收。它将堆内存一分为二,每一部分空间称为 semispace。这两个空间,只有一个
空间处于使用中,另一个则处于闲置。使用中的 semispace 称为 「From 空间」,闲置的 semispace 称为 「To 空间」。
过程如下:
从 From 空间分配对象,若 semispace 被分配满,则执行 Scavenge 算法进行垃圾回收。
检查 From 空间的存活对象,若对象存活,则检查对象是否符合晋升条件,若符合条件则晋升到老生代,否则将对象从 From 空间复制到 To 空间。
若对象不存活,则释放不存活对象的空间。
完成复制后,将 From 空间与 To 空间进行角色翻转(flip)。Scavenge 算法的缺点是,它的算法机制决定了只能利用一半的内存空间。但是新生代中的对象生存周期短、存活对象少,进行对象复制的成本不是很高,因而非常适合这种场景。
-
老生代内存回收
Mark-Sweep,是标记清除的意思。它主要分为标记和清除两个阶段。
标记阶段,它将遍历堆中所有对象,并对存活的对象进行标记;
清除阶段,对未标记对象的空间进行回收。
与 Scavenge 算法不同,Mark-Sweep 不会对内存一分为二,因此不会浪费空间。但是,经历过一次 Mark-Sweep 之后,内存的空间将会变得不连续,这样会对后续内存分配造成问题。比如,当需要分配一个比较大的对象时,没有任何一个碎片内支持分配,这将提前触发一次垃圾回收,尽管这次垃圾回收是没有必要的。Mark-Compact则是将存活的对象移动到一边,然后再清理端边界外的内存。

这篇文章参考了大量的文章和书籍,并作出了自己的理解,如有不对之处,请大神指出~
这篇文章我整理了好久,希望转载表明出处~
参考:
《WebKit技术内幕》——朱永盛
极客《重学前端》——winter
图解浏览器的基本工作原理
深入理解V8的垃圾回收原理
为什么V8引擎这么快?
V8引擎详解
V8 Ignition:JS 引擎与字节码的不解之缘