python爬虫(十二)爬取好看视频和新发地菜价
好看视频
需求分析
爬取首页的视频,并分类存储于相应的文件夹内,视频名为网站上显示的文件名。
页面分析
打开好看视频首页,点击刷新会发现,每一次显示的视频是不一样的,所以爬取到的视频会出现跟看到的不一致的情况。
视频首页有推荐,影视,音乐,vlog,游戏等标签,我们可以设置生成相应名称的文件夹。
选择一个视频,点右键检查。光标定位到
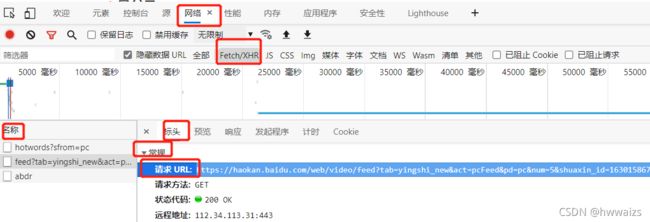
我们可以通过查看数据接口的方式查看,点击Network(网络) --> XHR ,进入后在网页空白地方点击刷新。
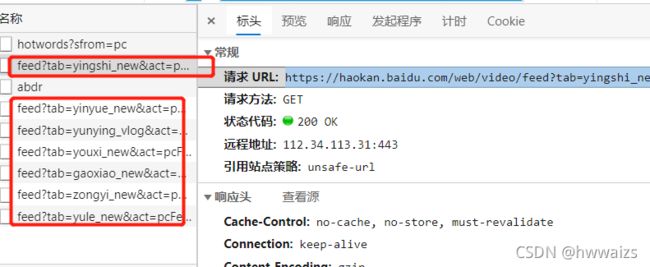
如上图所示,我们点击左侧“文件”下"feed?tab"开头的文件(其他几个文件里的url里均无内容),复制请求url地址,到网页中打开(需要JSONView,浏览器右上角三个点,扩展,把"JSONView-for-Chrome-master"文件夹下的"WebContent"文件拖到浏览器中,重启浏览器就可以了),我们可以看到数据是以嵌套字典的形式存放,我们按照取字典关键字的方式进行取值,就可以得到视频所在的url,直接向这个url发起请求,就可以得到想要的视频

但是经过爬取发现文件中只存放了5个视频,这时我们回到检查网页界面,随着鼠标在空白地方下滑,在左侧文件下面陆续出现了多个feed?tab"开头的文件,经过分析,他们区别在于"tab ="里的内容,其他部分的内容都一样,这时我们可以把"tab ="里不同的内容存放于列表中,利用遍历取出内容,拼接到url中进行取值,就可以得到多个不同栏目的内容。
代码实现
import requests
import time
import os
lis = ['影视', '音乐', 'VLOG', '游戏']
lis1 = ['yingshi_new', 'yunying_vlog', 'yunying_vlog', 'youxi_new', ]
"""lis里的名字用于创建文件夹,lis1里的内容是放到url里进行网页的循环爬取
对两个文件进行zip打包,再用遍历取出两个值,用于不同的地方
如果lis和lis1的内容一样,创建的文件夹名字就是里面英文的内容"""
for i, m in zip(lis, lis1):
data_dir = f'./video2/{i}'
os.makedirs(data_dir)
print(f'{i}文件创建成功')
url = f'https://haokan.baidu.com/web/video/feed?tab={m}&act=pcFeed&pd=pc&num=5&shuaxin_id=1630038532427'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
}
res = requests.get(url, headers=headers) # 对url发起请求,获取相应栏目的内容
html = res.json()['data']['response']['videos'] # .json()以字典的形式呈现网页的内容,对获取的网页内容进行字典取值
# print(html)
name = 1 # 用于对写入的视频进行计数
for video in html: # 遍历取出每一个视频的url
# print(video['previewUrlHttp'])
# print(video['title'])
time.sleep(3) # 每次爬取暂停3秒
response = requests.get(video['previewUrlHttp']) # 对每个视频的url发起请求
title = video['title'] # 取出视频的名字用于保存视频
# print(response, title)
video_path = '{}/{}.mp4'.format(data_dir, title) # 传入保存文件的路径和名字
with open(video_path, 'wb') as f: # 以二进制的形式保存视频,音频,照片
print(f'正在写入第{name}个视频')
f.write(response.content)
name += 1
由于视频对网速的要求很高,比较慢,这里就爬取了两个类别的,最后爬取的效果如下:


新发地菜价
需求分析
获取到北京新发地的菜价,这里只爬取前9页,如果需要爬取多页,请在main函数中更改range的值
页面分析
在表格的“大白菜”处点击鼠标右键,查看网页源码中未能找到相关内容,说明数据不在网页源码中,点击右键,检查,在network,左侧名称下面只有一个文件,点击,在Preview(预览)中依次点开按钮可以看到数据都在list下,点开0标签,可以看到大白菜的所有信息。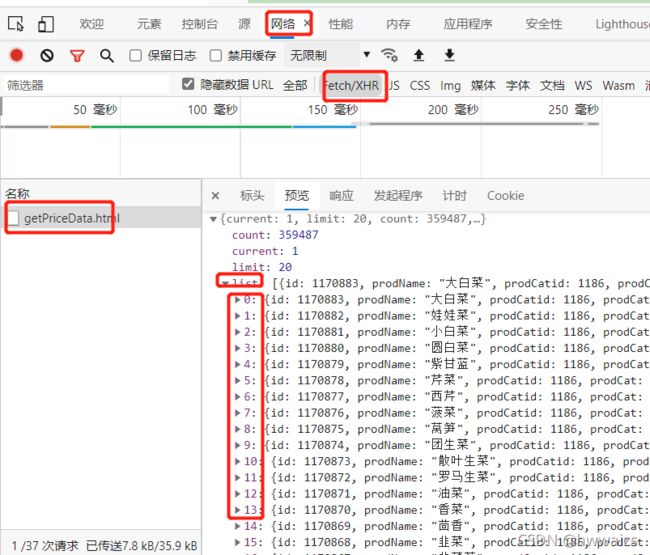
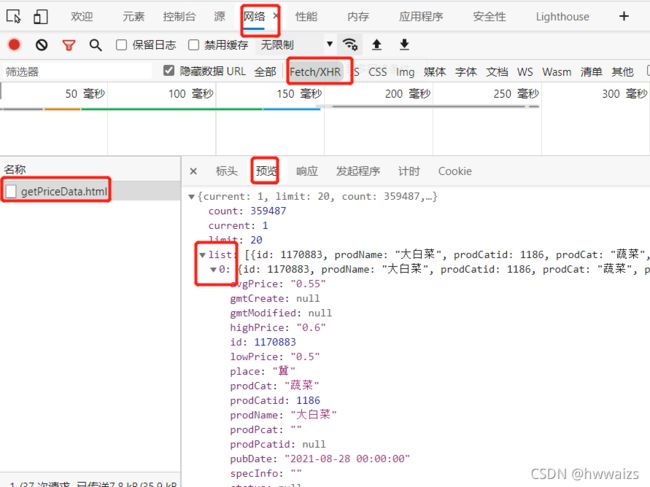
可以看到我们需要的数据都在list标签里面,我们可以访问Headers(表头)的url去获取数据。
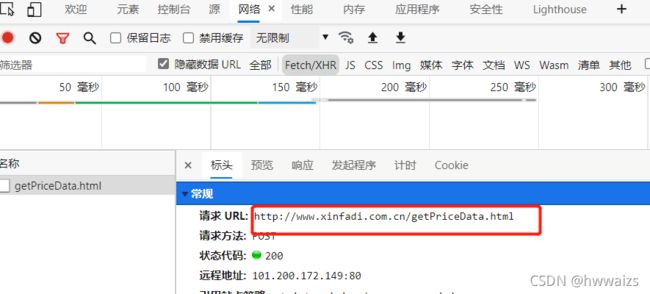
把url复制到网页中,可以看到需要的参数是以嵌套字典的形式展现,只需要用字典的关键字去取值就可以了。

从请求方法中我们可以看到是 post请求,当点击第二页,第三页的时候在下面出现了多个"getPrice"的文件,点开之后发现它们的url都一样,这样的话如何实现翻页处理呢?
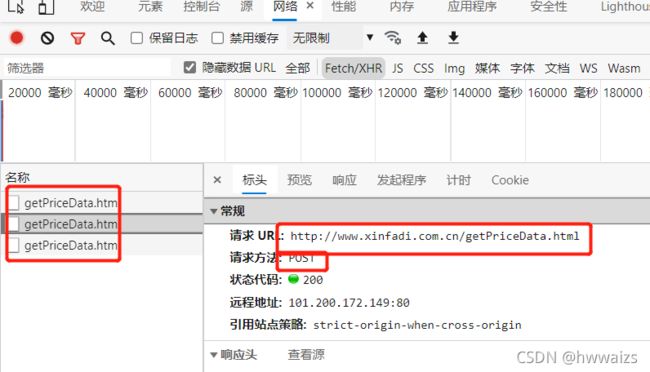
再仔细往下看,在表单数据中可以看到变化,第一页的current为1,第二页的为2,第三页的为3,依次类推,实现翻页功能的是current参数,这时就需要把post请求中携带的参数current进行遍历操作。

代码实现
import requests
import csv
import time
def get_url(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62'
}
res = requests.post(url, data=data, headers=headers)
html = res.json()['list']
# print(html)
return html
def parse_data(h):
lis = []
for i in h:
# print(i)
d = {}
d['编号'] = i['id']
d['一级分类'] = i['prodCat']
d['二级分类'] = i['prodPcat']
d['品名'] = i['prodName']
d['平均价'] = i['avgPrice']
d['最低价'] = i['lowPrice']
d['最高价'] = i['highPrice']
d['产地'] = i['place']
d['单位'] = i['unitInfo']
d['规格'] = i['specInfo']
d['发布日期'] = time.strftime("%Y/%m/%d", time.strptime(i['pubDate'], "%Y-%m-%d %H:%M:%S")) # 对时间的处理,只保留年月日
lis.append(d)
# print(lis)
return lis
def sava_data(lis_data, header):
with open('lis_data.csv', 'a', encoding='utf-8', newline="") as f:
print(f'正在爬取第{i}页')
writ = csv.DictWriter(f, header)
if i == 1: # 处理重复表头
writ.writeheader()
writ.writerows(lis_data)
if __name__ == '__main__':
global i
for i in range(1, 10): # 对data进行遍历,实现翻页操作
time.sleep(2)
data = {
'limit': 20,
'current': {i},
'pubDateStartTime': '',
'pubDateEndTime': '',
'prodPcatid': '',
'prodCatid': '',
'prodName': ''
}
url = 'http://www.xinfadi.com.cn/getPriceData.html'
header = ['编号', '一级分类', '二级分类', '品名', '平均价', '最低价', '最高价', '产地', '单位', '规格', '发布日期', ]
h = get_url(url)
lis_data = parse_data(h)
sava_data(lis_data, header)
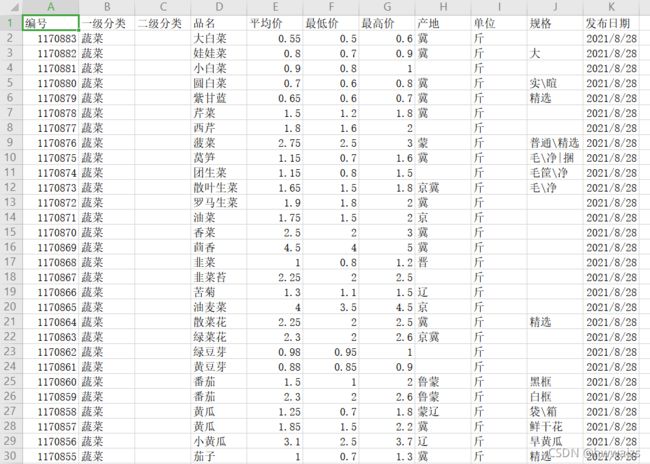
得到的结果如下图所示