tcmalloc 框架介绍
tcmalloc解决锁频繁加锁解锁以及缓解锁竞争问题,尤其是在多线程并发申请内存的时候,相比malloc效率大大提升。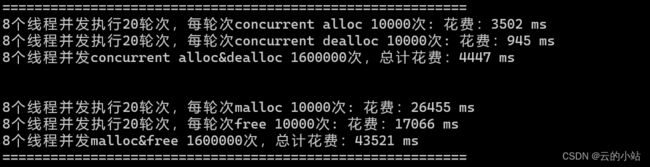
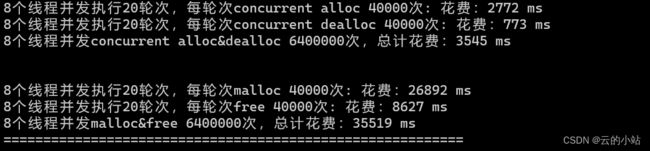
20轮,每次8个线程,每次个线程申请10000次,释放10000次;
malloc和我们的tcmalloc相比,malloc像个万金油,哪里都能有,但是哪里都不突出,所以在多线程高并发申请内存的过程中相比tcmalloc,malloc内存池申请是缓慢的。所以,我们创造tcmalloc内存池解决高并发效率问题。
tcmalloc有3层结构,分别是ThreadCache层、CentralCache层、PageCache层。其项目使用插件技术拥有定长内存池做的对象池,Size类(该类中拥有向上取整函数以及子函数,桶位判定函数以及子函数)、自由链表类、Span类,SpanList类用于管理Span块、基数树。在这些插件与锁的使用设计合并在一起的时候,在多线程上效率和安全上都有了大幅度提升和保障,并且也解决了内存外碎片化问题,可以说在多线程下中有频繁的申请释放内存时,应该使用高并发内存池提高我们程序的安全与效率。
自由链表,定长对象内存池文章介绍:tcmalloc(高并发内存池)简化版讲解-项目_云的小站的博客-CSDN博客
在该内存池的最外层处,并不属于三层内存池结构(ThreadCache、CentralCache、PageCache)中而是我们在内存池的最外层做了个外壳,申请内存和内存池并不直接接触,有效安全保护了内存池不被恶意的修改数据,这类似于linux操作系统的shell外壳,一定的保护了内核数据不被应用层人员恶意修改,只提供接口给外界使用,实际的操作用户层并不需要知道内核工作原理只能获取内核会给你的数据。内存池也是这样的,你需要申请多少字节内存,我就给你多少字节内存,你不用知道我是如何实现的,这就是这一层添加的意义。 
在这一层中存在两个接口函数,一个接口函数用于申请内存,一个接口用于释放内存,我们可以将其直接和malloc和free一样的使用,申请接口传入需要多大字节内存整型,返回一个地址,而释放接口就只需要传入之前是从内存池申请的内存释放,那么有几个问题来了如果用户层向内存池申请一大块,超出内存池的中承受范围,以及归还内存时候资源并不是属于内存池资源的处理情况。
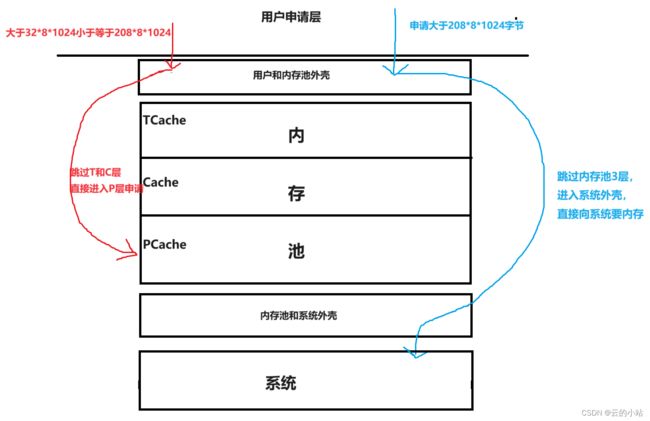
来先解决大块内存问题,前提先了解TCache和CCache层最大存储内存范围是[0,32*8*1024],[0,208 * 8 * 1024],用户层需要向内存池申请了一大块内存时,有3个内存池承受区间:
- 当内存申请小于等于32 * 8 * 1024字节时,线程执行流会进入thread层执行正常的内存池申请流程。
- 当内存申请大于32 * 8 * 1024字节,小于等于208 * 8 * 1024字节时(32 * 8 * 1024,208 * 8 * 1024],线程执行流跳过TCache层与CCache层直接进入PageCache申请对应内存。
- 当内存申请大于208 * 8 * 1024字节时,这个时候需要的内存就非常非常大了,就连PCache层都无法满足该内存的时候我们就需要直接向系统申请对应的超大内存了。
总有不守规矩的人,比如我,以及测试开发人员总是会写一些不属于内存池接口申请出来的内存,归还给内存池,更有甚者比如我,把栈区的地址归还,我们必须有处理机制管理。我们利用基数树帮助,让小块内存地址和内存管理块地址做到映射查找,如果发现归还的内存无法与基数树建立映射关系,基数树会给我们一个空值(nullptr),允许基数树给空值得地方只有内存管理块合并时允许,其他地方查询返回基数树返回空值得时候都是属于错误得非法情况,我们需要对其做处理。我们将合并外得查找做一个包装器,在PageCache层外(基数树管理存储属于PageCache层)不可直接访问到基数树,并且只能读基数的的数据,如果在P层外读取基数树的映射位置为nullptr时,就应该做错误处理:
- 在Debug模式下,我们使用assert报警,并且在报警前说明是说明地址导致的问题。
- 在release模式下,我们使用异常exceptionc处理抛出异常,带有的错误信息也是与Debug报错的信息一样。
为了下层T和C的范围性固定大小字节,我们会将传入的字节做向上调整,比如我们需要一个字节,会返回给其8个字节大小,这对应着自由链表、TCache和CCache层结构中的某些要求,后续再谈这个。向上取整后返回的内存,一定能够满足外界对其的内存使用需求,唯一不足的是会产生内碎片问题,申请5个字节内存,返回8个字节内存,存在3个字节无法被利用的问题,这就是内碎片问题。但这并不影响多少,当申请自己大的时候,可以计算出,除了申请int类小内存外,申请最大浪费仅仅占到10%左右,在当今计算机中根据摩尔定律,效率>内存,所以这内碎片浪费无所谓。所以范围返回内存是一个明知之举,以较小内存牺牲换取提高多线程频繁申请内存时的效率。
在这边我们使用了1个接口来确认向上调整的字节数,依托这个函数,我们在内存池外壳先对其申请的字节大小做调整后,方便后续进入TCache或CCache层的操作。
在释放内存时,我们仅仅传入地址,但是在内存归还必须得了解该小块内存的大小,才可以方便我们后续归还时的连接到对应桶中,或者大内存归还给系统。这个就需要基数数的配合了,依托基数树帮助,我们可以根据归还内存第一个字节地址,通过位运算(32位机器>>13或者/8/1024)得到对应页号,通过基数树查找对应的span地址信息,每一个从内存池出来的内存都被一个span管理着,每个span生成都会将所有拥有页映射到基数树中,所以归还的内存可以通过基数树查找对应的所属的span,应为span所管理的小块内存大小相同并且记录小内存大小,所以可以从查找的span中获得内存大小,然后连同内存地址以及内存大小一同传递给下一级TCache或者PageCache或者系统中。这里的基数树的查询接口外再次包装一个接口,在该包装中,判定基数树原生接口返回的span地址是否存在,是否被使用,一个不成立我们将启动报错机制,release和debug下分别写了不同的处理机制:debug我们使用assert,release我们使用抛异常处理,二者都将打印错误信息包括了释放的地址数据,以方便我们查看究竟是什么地址导致的我们的错误发生。.
这一层在多线程的过程中是不用锁存在的,在这一层的TCache并不是只有一个,而是每个线程拥有独立的ThreadCache内存池,这里利用了TSL技术,让线程拥有独立的ThreadCache类全局指针(其实就是把变量从公共的数据区放到共享区中的线程独立栈中),这样不同线程使用这个指针变量就不会发生线程安全等问题,就在内存地址中保证了,你访问你的我访问我的ThreadCache内存池,所以不同线程访问着不同的TCache内存池,不用加锁保护线程安全就可以在该层内存池的获得资源,这就是高并发内存池效率高最核心的地方,无需频繁加锁解锁。每一个TCache池都被同一个对象内存池管理着,每次我们要确保每次线程申请到的内存都是干净的,我需要对每一个归还的线程做字节清除处理(所有字节设置为0),每次归还内存的时候,将所有自由链表上的小块内存全部归还,保证了内存不泄露,为什么会泄露?因为内存池需要重新规划头8字节,会破坏原来保存的桶0的地址,如果不清空会导致归还桶0的链表管理结构体地址丢失。所以最好为其做一个占位符位于TCache类中前4~8字节,这样可以防止回收内存时候覆盖头4~8字节用于链接自由链表这会覆盖桶0位,所以我们设置占位变量,用于抵消这个自由链表头链接时覆盖前4~8字节,如果我们使用了这个占位符操作,在设计上可以让当TCache层回收的时候,无需回收全部内存块,因为桶0问题已解决。
在申请内存或者释放的执行流在内存池外壳中完成了前期工作后,执行流进入内存池的第一层TCache层。
在该层回收内存时候,也是依托传入的内存字节大小,来区分该放入哪位桶位的。在这一层有4个函数,2个函数,2个释放函数,
ThreadCache层的设计是由一个hash桶所管理,每个桶中是一个管理自由链表的数据结构的地址,在同一条自由链表中内存块字节大小是一样的,不同的自由链表组织的内存块大小是不一样的,大概有208条自由链表,分别管理着不同大小的内存块,将不同的内存块,将208个管理自由的链表数据结构地址以小内存大小hash计算后映射的方式管理在一个数组中,对申请以及回收内字节数,根据桶位算法得到对应的对应桶,对对于桶位的结构体中的自由链表做操作。
这层的自由链表管理不仅仅是一个连续的内存块,并非直接将头节点放入hash映射表中,而是利用了一个数据结构管理着这段自由链表,然后将该就结构体的地址放入函数表中,我们取走的其实是该结构体所管理的原生自由链表中的小块内存,数据结构会记录当前小内存使用情况,允许保存的小内存没有上限,该结构体会保存当前数据结构所拥有的小块内存的数量以及下次申请的期望内存数。这个数据结构存在的目的就是配合TCache层做数据管理,这是非常重要的,在该数据结构提供的接口,我们可以非常方便的申请或者回收内存,并且记录属于数量,尤其时记录数量这一步,为再次向下回收内存条提升了效率,不用我们在手动去检查内存长度,应为其提供2个接口,当前size与MaxSize接口,该函数实现非常简单,直接将记录size和maxsize返回,不用再去遍历自由链表记录数量。提供增删查改接口,其中拥有大范围删除与增加。
申请内存时,上层外壳将申请的内存字节已经向上调整,在这一层可以直接根据该调整字节(也可以直接用原生申请的),根据这个字节大小可以在桶位算法中得对应桶位,根据桶位映射找到对应得自由链表结构体地址,然后再结构体中申请一个小块内存,做头删取其内存块,存在内存块则返回,做准备工作然后进入下层内存池申请内存,向下申请并不是只申请一小块内存块,而是申请连续的内存块,实际申请多少内存是看当前桶位的结构体中的Maxsize,当然并不是Maxsize是多少就是多少块内存,还有一个算法制约着,取其小值当向下申请块数量。在每次申请后都使得MaxSize+1;在得到内存返回时,实际申请和理想申请并不是一样的多,接口函数返回实际内存数。在内存返回后,如果只得到一个内存块直接返回,如果得到多个内存块,返回第一个内存块,然后将剩余的内存块链接到结构体的自由链表中。
释放内存时,依靠上层外壳将传入的地址通过基数树得知释放内存对应的字节大小,再将释放内存地址和释放内存大小传入TCache暴露的释放接口中即可,该函数中工作和申请内存一样,通过内存大小得知对应的桶位,然后将内存头插入对应桶位的自由链表中即可,返回的内存连入TCache对应自由链表时会触发自由链表长度判定,一旦我们的内存到达一个临界值(会变化)时,会将这条自由链表所有内存取出,将对应桶位所管理的自由链表置空,然后将这段链式内存全部传递到给下层Cache层。
如果执行流来到了CentralCache层,意味着执行流一定已执行ThreadCache层,那么申请的内存块一定是小于MAX_BYTES才会流入该层,否者进入Page或者系统层,所以在这一层无需判定申请的字节大小是否超出该层最大小块内存,这是不可能的,可以写一个assert判定不可能出现的情况。
在这一层中是第一次遇见一种数据结构:Span数据结构,你可以先将其看成双链表数据结构的一个结点,结点中其他大小可以依赖继承或者成员变量的方式包含其他成员变量。Span是对大块连续内存管理的基本单位,在给Span中有一个变量是Page_ID表示着span的唯一标识。讲个知识点假设在32位机器中一共有4G内存,内存划分是以页为单位的,我们设定一页大小为8*1024字节,那么整个内存一共分为4G/8/1024=524288(页),我们将每一页都可以认定为唯一ID在内存上的标识,可以依靠该页号*8*1024就可以得出地址,也可以依据地址/8/1024得出页号。所以我们的Span块采用该方法定义ID,根据其ID就可以找到对应内存地址。但是一个span可能不止管理一页内存,一个Span会管理多页内存,所以在Span中还得加上一个Page_n来标识该span管理者多少页的内存块,所以某一个Span管理的内存范围地址[Page_ID<<13,(Page_ID+page_n-1)<<13],这些空间就属于该Span可访问的内存。我们将这么大的内存切分为一个一个的小块内存,以原生的自由链表方式链接,并且在span中记录切分的小块内存的大小,整个数值是为当归还内存时可以根据归还的地址得知span从而得知该归还的内存大小。这个原生的自由链表的头节点保存在span中,方便上层取用,并且每个span有一个计数器,记载使用内存情况,每次取用与归还时会记录该span发出或回收内存块情况,初始为0,每次从该span出内存时,计数器增加,归还时计数器减少。在span中我们还得记录一个该span是否在使用的标识,这是配合PageCache层合并内存使用的,当前先不关心。
在这一层的内存池设计中,我们也就采用了hash桶的方式,唯一区别是,这里是双向的Span链表作为每一个桶位的桶,每个SpanList的每个结点是span,每个span管理着自由链表,这是一个非常非常牛的设计。我们采用单例模式的的懒汉模式,保证了一个进程只允许有一个CentralCache类。这个中心缓存存在的意义:对上调节每一个TCache的内存回收和申请,高效的利用了内存块的使用,因为一个线程的TCache中存在空闲内存不可被其他线程访问,我们可以先将其返回到CCache中,然后在从其流入其他TCache中,完成了资源的调度机制。对下,将从PageCache获取的大块内存进行切分并且管理,这是很重要的一个中间层,诚然因为只允许有一个Cache池,所以多线程访问下必须有锁的干预,但是每个桶又是互不干预的,所以我们可以采用桶锁技术,访问哪个桶就加锁,如果2个线程并不是访问到同一个桶,那么线程依旧是并行的,只有当多个线程同时访问同桶时刻才会有锁竞争的问题。有了桶锁的设计,在不同线程访问不同的桶时,就可以认为是无锁的状态,这是也是高并发内存池的一种优化机制,也是高并发内存池高效的机制。
申请内存时,TCache层申请字节映射的桶位中的自由链表,没有对应的内存块,进入下一层向CentralCache层申请对应内存,这个申请并不是申请一个内存块,而是需要返回给TCache一串链接好的内存块,这样如果多次申请同样大小的内存块,只需要线程少量次进入Cache层申请,提高了线程的效率,如果一个一个申请的情况,如果一直只申请同范围大小的内存就会频繁进入Cache层,内存池效率大幅度减低,这是我们不希望看见的,并且CentralCache在整个进程只允许一个对象,频繁的加锁解锁严重影响效率,并且失去了ThreadCache无锁内存申请优势,得不偿失,所以每次从CentralCache返回内存应该是一串内存块。所以Cache的申请内存的接口不仅仅接收申请内存大小,还必须接收申请个数。当然并不是你要多少就给多少,和菜市场讨价还价一样,T层申请和C层返回的个数不一定是一样的,有可能申请10个连续内存块,只给8个连续内存块,所以CCache申请内存接口返回值返回真实申请到的内存数量,在该接口还得设置一个输出性参数start指向我们申请到的连续内存块的第一个内存块地址,还有一个输出性参数end指向内存块的最后一个内存块(其实这个不设置也行,应为我们知道小块内存的大小也知道实际大小,(char*)start+((actualNum-1)*bytesize)),这是我们的CentralCache层申请内存的对外的内存接口设计,在函数中也是依赖传入的小块内存申请大小根据桶位计算得出操作桶位,在桶位中查找是否有span存在空闲的小内存块,这里寻找内存并不在乎当是Span有多少小块内存,就对其Span操作,具体截取多少呢?以传入的请求为上限,查看当前Span有多少,如果小于等于请求就全部返回,如果大于者截取期望数量。将其截取的头赋值给输出性参数start,尾给end。如果当前整个桶的Span都没有空闲内存,就需要向下申请,向下申请到的Span标识着一大块内存,返回这块内存时,需要在CentralCache层分割大块内存,并且链接为自由链表。供申请使用。
回收内存时,当上层某一个桶中自由链表过长过大触发机制后,将回收存在的整条自由链表,接口设计为回收内存条的头结点地址,并且小内存块字节大小传入,根据小块内存找到Cache对应桶位的桶,桶上锁,将上层回收的长串自由链表,拆分,拆解的小块内存根据基数树的访问操作找到归属的Span块内存,这里可以做一个条件判断,如果span并不属于该桶,那么就报错,应为传入的自由链表上的小块内存都是同一大小的,那么他们在T层和C层应该都是同样的映射,所以给的自由链表中的每一个结点必然存在并且只在同一个CCache桶中。依次归还小内存到Span中,归还后该span的使用use变量自减,当某Span的使用use==0时,从该SpanList取出,将其归还到Page层中。当然在拆除后我们可以将其桶锁解除,在归还Page层后执行流回到Central层时重新申请桶锁,然后继续循环归还小块内存。
进入Page层,有两种可能,一种是执行流正常的从CCache层申请不到存在空闲Span块,去Page层申请一块Span块进行切分。还有一种情况就是外界申请或者归还大内存(256*1024,128*8*1024]直接跳过T和C层,直接进入PageCache层,因为内存过大前两层无法给予和回收,只能尤其申请。PageCache层也是hash桶结构,不同的是,该层的哈希桶桶位只有128位,不再是208个桶位,每个桶也是SpanList为桶,但是这里的Span是完整的一块空间,完全没有被使用,以ID和page_n为表示位置与大小。该桶会存在内存的合并与切分动作,这个动作是影响到整个Page哈希桶,所以这一层是需要一把大锁来约束的进入Page层中的所有线程行为,必须排队进入,因为合并外碎片与切分大内存是整个PageCache性的操作,若不加以约束,将造成数据覆盖,多线程用同块内存的错误现象。
申请内存时,申请内存执行流到CentralCache的某个桶时,桶内无空闲内存,然后会依据算法得出申请的桶位,应该需要一个多少页新Span块,此时就会根据需要页数来PageCache对应桶位查看是否有空闲Span块,有则头删返回span块,如果该桶位没有Span块,根据该桶位遍历向后遍历其他SpanList,一旦后边某个SpanList存在空闲Span,取出一块Span,对齐Span进行切分操作,切分为上层需要页的span块以及剩余的页数,将剩余页理解对应链表中,返回上层需要的页数Span,二者都需要将其中地址存入基数树。如果遍结束后一直无空闲的SpanList,PageCache将向系统申请内存,一次性申请最大可存储的内存块(128*8*1024)这已经是非常非常大的内存块,然后再递归依次该函数,切分新申请的128页的内存块。在PageCache层中创建了一个Span对象池,保证所有的Span对象都在这一层创建和销毁。
释放内存时,如果进入这一层,先是合并内存块,循环向前查看,前Span块是否被申请,是否被使用,合并后大小是可以被存放在PageCache中,如果被申请还未使用并且合并后小于最大桶位,说明前内存位于PageCache还未使用并且合并后允许存放,那么我们可以合并该Span,创立一个更多页数的Span块,并且调整Page_id,一旦条件不成立退出循环合并,然后再向后检测span块,和向前逻辑是类似的操作,每成功合并就需要将被合并从其桶位删除。合并操作结束后将新Span插入到对应的桶中,并且重新记录基数树。
基数树是存放在PageCache中的一个结构体,所以说他是一棵树,也可以说是hash表/桶,也可以认为是单多维数组,这些都是可以被理解。基数树分为单层与*多层结构,我才疏学浅只会个32位的2层基数树,先了解单层基数树,32位机器4G运行内存,以8*1024byte划分,一共524288个页,一个地址需要存放4个字节,一共有5242288个地址,所以存放这些地址的数组需要2097152个字节也就是2MB大小,对应内存4G来说这点内存何足挂齿,直接开524288个指针数组。这也是可以的。也可以使用二层基数树,通过对页号的bit划分以一层数组和二层数组,唯一不同的二层数组运行按需申请,但2MB就并不是很需要这样子做可以一次性全部开出来,当然这只是在32位机器下的,62位机器的基数树还要3层数组,也是依托页号的bit位来划分,但是62位机器可不允许全部一次性开创,必须按虚申请,否则会极大的占用内存这是万万不可的。所以说32位机器其实挺好的。
总结:高并发内存池依托许多配件以及3层结构,在巧妙使用锁下极大的优化了内存申请的效率,对比其malloc来说,在多线程下优势是遥遥领先。