【COMP207 LEC20】
LEC 20,21,22
Distributed databases 分布式数据库 DDB
Providing access to large datasets to many users (e.g., for an online store) 给用户提供对大型数据库的访问
Distribute data over several computers – not necessarily identical (in software or hardware) 在多台计算机上分布数据
Computers could be at geographically separate locations (but also possible that they are the same place) 电脑可以在地理上分割
Possible advantages: Balance workload 负载平衡 & network traffic Easier to extend capacity or scale to higher number of users 网络流量更容易扩展容量或扩展到更多的用户
Collection of multiple logically interrelated databases 多个逻辑相关数据库的集合
Distributed over a computer network 分布在计算机网络上的

A、B、C :Node/site 节点 / 站点(用来储存数据库的) = computer in the network, where a database is stored
ABC之间的连接:Network link


Fragmentation, replication and transparency碎片化、复制和透明
>> Fragmentation
分为Horizontal fragmentation和vertical fragmentation and mixed,split databases into different parts that can be stored at different nodes
其中,Horizontal fragmentation的entire relation就是union of relations at the different sites
Vertical fragmentation的Original relation 就是 join of the fragments
>> Replication
>> Redundancy Improves Resilience,如果有一方的数据库system fail了,那其他数据库可以代替他工作,因为Other sites keep copies of fragment stored at Manchester
>> Redundancy Increases Efficiency,因为一个数据库不只保存了自己fragmentation的数据,所以他也可以很高效的回答其他问题
但同时,Controls how many sites keep a copy of a fragment就又成为了问题,如果每个数据库都保存每一份fragmentation 的copy,那么update就会非常慢;如果每个数据库都只保存自己的那一份fragmentation的copy,那么一旦崩溃就会出现问题。所以一般都是partial replication,控制Limit number of copies of each fragment
>> Transparency
DDBMSs ensures that users do not need to know certain facts then creating queries Transparency at different levels :
Fragmentation transparency、Replication transparency、Location transparency、Naming transparency
也就是说:

Transaction management in DDBMS
Recovery in DDBMS

Distributed Commit 分布式提交
>> Two-Phase Commit Protocol:
phase 1: Decide when to commit or abort
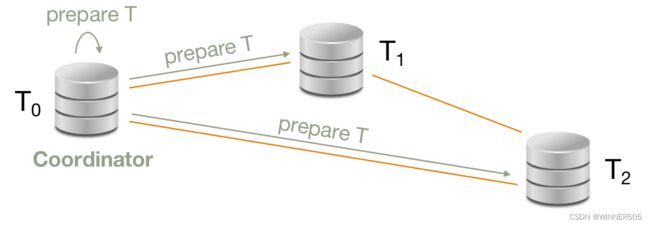
If commit : go into precommitted state & send back “ready T”
If abort : send back “don’t commit T” and abort local transaction
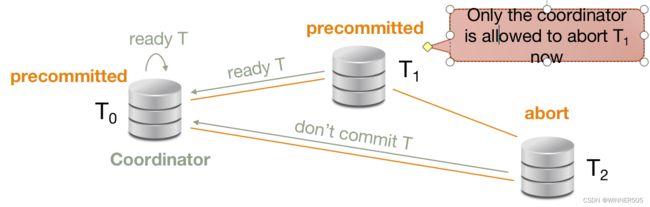
phase2 : Commit or abort
If nodes send "ready T" to coordinator, then send "commit T" back
If nodes send “don't commit T” to coordinator, then send "absort T" back
>> Three-Phase Commit Protocol

Advantage: if the coordinator fails, all nodes know if they should commit/abort a transaction
Query processing for DDBMS
Introduction to semi-structured data
>> Fully Structured Data
Data in the relation model is structured:
Advantage: highly efficient query processing
Data has to fit to schema
>> Unstructured Data
Completely free on how to organise data
No description of structure or data: programs have to know how to read & interpret the data
>> Semistructured Data
结合了两个的优点:
Self-describing: no schema required
Flexible: e.g., can add & remove attributes on demand
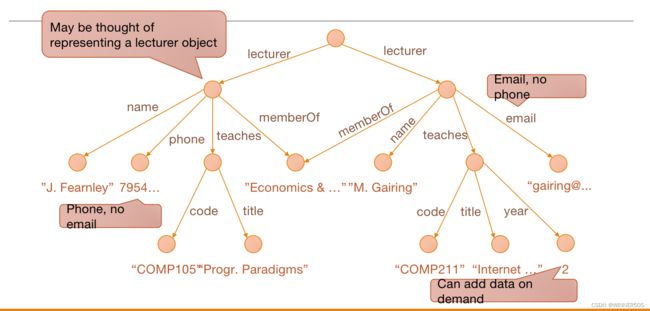
Semistructured Data Model:
Tree or "tree-like"
Leaf nodes :have associated data Strings, integers, etc.
Inner nodes : have edges going to other nodes / Each edge has a label
Root: No incoming edges / Each node reachable from the root
Example :
Application :
Popular form for storing & sharing data on the web
Text-based (typically)
Self-describing (no what is the meaning of this? Etc.)
Easy to process and manipulate, even for humans
Very flexible

Basics of XML
Example:

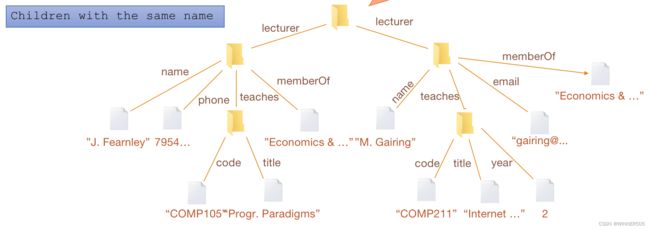

>> Elements may be nested(嵌套):
1. nesting(嵌套)必须合理
2. 只有一个root element
3. root element 不被包含在其他element
>> Element 可以是空的,这个时候opening tag和closing tag合并,就像 “
>> Element 区分大小写
>> Element 可以有attributes,which are put into the element’s opening tag

Only one attribute of a given name for each element 一个element只有一个给定名字的属性,所以他很适合用来当reference
When to use attributes or sub-elements? Staff ID of a lecturer / Email address
>> Elements in an XML document are ordered as they occur in the document

DTD (Document Type Definitions)


名字后面没有符号(例如“+”“?”“*”)的就只能有一个,
?:零次或一次
*:零次或多次
+:一次或多次


ID允许unique key 与 一个element相关联
IDREF允许一个element与另一个element通过一个designated key相关联
IDREFS允许一个element 与其他多个elements相关联
>> Document validity
Two levels of document processing: well-formed and valid.
Non-validating processor : Before passing information on to application,他会先检查XML document 是否是well-formed
Well-formed:检查是否conforms to structural and notational rules of XML 例如:1. 只有一个root element 2. elements必须嵌套在没有重叠的树结构
Validating processor :Will not only check that an XML document is well-formed but that it also conforms to a DTD (or XML Schema), in which case XML document is considered valid.