hive数据仓库安装与使用
第一部分:hive介绍
1、hive的概念
hive是基于hadoop的一个数据仓库的工具,也是数据库,存放的是历史数据,用于数据挖掘etl。
hive的元数据存放在mysql(或者derby)中,真正的数据存放在dfs分布式文件系统内,hive底层封装了很多mapreduce的任务,通过sql语句调度相应的任务。由yarn资源调度系统执行任务,分析数据,最后返还给hive一个执行结果
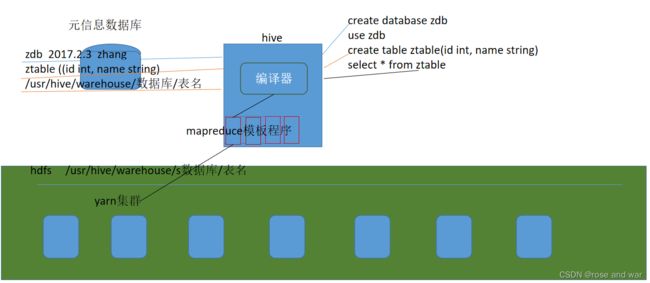
2、hive的数据存储
1)、Hive中所有的数据都存储在 HDFS中,没有专门的数据存储格式
2)、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3)、Hive 中包含以下数据模型: DB、Table,External Table,Partition,Bucket。
db:在hdfs中表现为S{hive,metastore.warehouse.dir;目录下一个文件夹
table:在hdfs中表现所属db目录下一个文件夹
externaltable:与table类似,不过其数据存放位置可以在任意指定路径
partition:在hdfs中表现为table目录下的子目录
bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件
第二部分:数据库安装
1、安装mariadb和hive
保证系统能连接外网,能连接外网的情况下该步骤可以省略:
/etc/resolv.conf增加
nameserver 192.168.47.2
nameserver 114.114.114.114
su切换root
安装
yum -y install mariadb mariadb-devel mariadb-server
查看版本
rpm -qi mariadb-server
开启服务
systemctl start mariadb.service
添加开机启动
systemctl enable mariadb.service
进行一些安全设置,以及修改数据库管理员密码
mysql_secure_installation
用户登录
mysql -u root -p
执行更改密码的语句
> update user set password=password('aaa) where user='root
# (执行下面的语句**:所有库下的所有表: 任何IP地址或主机都可以连接,用于navicat等软件连接mysql)
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
FLUSH PRIVILEGES;
断开连接
exit
su hadoop 切换到普通用户hadoop
hive安装
解压hive
安装mysql数据库
配置hive I
tar -zxvf hive-1.2.4.targz -C /home/hadoop/cluster
配置HIVE
HOME环境变量 vi conf/hive-env.sh 配置其中的$hadoop home
HADOOP_HOME=/home hadoop/cluster/hadoop-2.6.4
2、配置数据库信息 vi hive-site.xml
xxx/conf/hive-site.xml
3、将mysql驱动包拷贝到¥HIVE_HOME/lib目录下
4、Jline包版本不一致的问题,需要拷贝hive的lib目录中jline.2.12.jar的jar包替换掉hadoop中的
cp jline-2.12.jar /home/hadoop/cluster/hadoop-2.6.4/share/hadoop/yarn/lib/
5、启动hadoop集群 start-all.sh
启动mysql 切换到root systemctl start mariadb.service
启动hive hive-1.2.1/bin/ ./hive
第三部分:hive的使用
1、ddl部分
show databases;
use databsename;
show tables;
1)create语句
第一种方式
create [external] table[if not exists]table_name
[(col_name data_type[COMMIT col_comment],...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)]
INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;
若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会 被一起删除,而外部表只删除元数据,不删除数据。
PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)
partition是hive提供的一