从入门到入土,万字超详细Redis学习笔记 【基础篇】+【实战篇】
从入门到入土,万字超详细Redis学习笔记 【基础篇】+【实战篇】
文章目录
- 从入门到入土,万字超详细Redis学习笔记 【基础篇】+【实战篇】
-
- redis通用命令
- resp图形化界面连接redis
- String类型的常用命令
-
- key的层级结构
- Hash类型的常见命令
- LIst类型的常见命令
- Set类型的常见命令
- SortedSet类型常用命令
- Redis的java客户端
-
- Jedis
- Jedis连接池
- SpringDataRedis
- Redis的实战运用场景
-
- 基于Redis实现共享session登录
- Redis缓存
- 缓存更新策略
- 缓存穿透
- 缓存雪崩
- 缓存击穿
- 超卖问题
- 乐观锁和悲观锁
- 分布式锁
redis通用命令
-
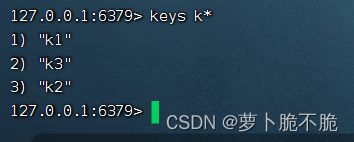
KEYS age:查询所有键为key的键,age可以使用通配符,生产环境下数据量庞大,一般不建议使用
-
-
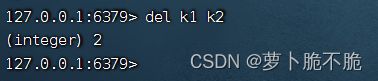
DEL key1 key2 …:删除指定的键,可以同时删除多个,返回删除的个数
-
EXISTS key1 key2 …:判断键是否存在,可以同时查询多个,有几个键存在就返回几
-
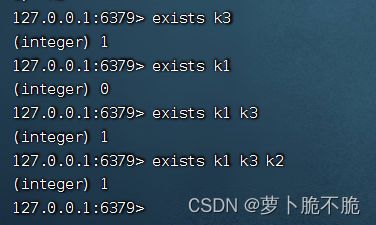
-
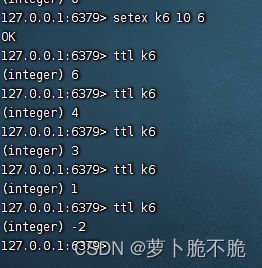
EXPIRE key 时间(秒):给指定键加一个销毁时间,时间到了之后这个键会自动销毁
-

-
TTL key:查看一个指定键的有效期,有效期到了之后返回-2,没有设置有效期的键返回-1
-

resp图形化界面连接redis

在连接redis时,以上ip和端口正确的,但是出现连接不上,原因有可能是两种:
- redis服务端还未开启,可以使用systemctl status redis 命令查看redis的运行状态,检查为未开启状态时,可以使用systemctl start redis 命令启动redis
- Linux系统的防火墙未关闭,在LInux系统上面使用redis需要将Linux的防火墙关闭,这样才能正常连接,CentOS7可以使用systemctl stop firewalld.service 命令关闭防火墙
String类型的常用命令
在FinalShell或者虚拟机终端使用命令时,需要先连接上服务端才能对redis进行操作,先使用redis-cli 命令创建一个命令行客户端连接redis,再使用auth 密码,输入密码,之后便可以在终端命令行中使用redis命令了
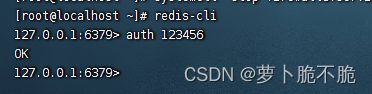
String类型有三种格式,分别是字符串、int、float
String类型的常用命令有:
- SET key val:添加或修改指定键值对,当输入的键存在的话就是修改,不存在就是添加
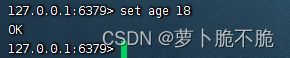
- GET key:根据指定的key获取String类型的value

- MSET key1 1 key2 2 key3 3…:同时添加多个键值对
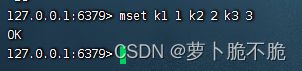
- MGET key1 key2 key3 …:同时获取多个键值对的值
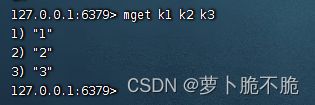
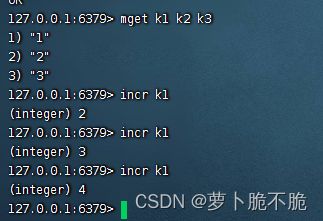
- INCR key :让一个整形的key自增1
-
INCRBY key 自增数字:让一个整型的键自增指定数字,例如让k2自增2
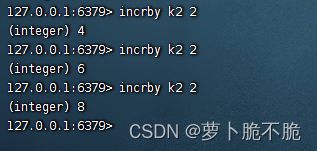
-
INCRBYFLOAT key 自增数字:让一个浮点型的数字自增指定步长

- SETNX key val :添加一个String类型的键值对,前提是这个键值对不存在,如果存在则添加失败
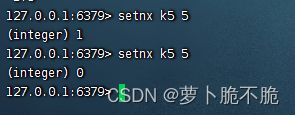
- SETEX key 时间 val:添加一个String类型的键值对,并且指定有效期
key的层级结构
Redis允许有多个单词形成层级结构,多个单词使用 ‘:’ 隔开,格式如下:
项目名:业务名:类型:id
在resp中查看

根据我们输入的层级关系,redis会自动帮我们层级分类,这样就克服了区分不同类型的key的问题了
Hash类型的常见命令
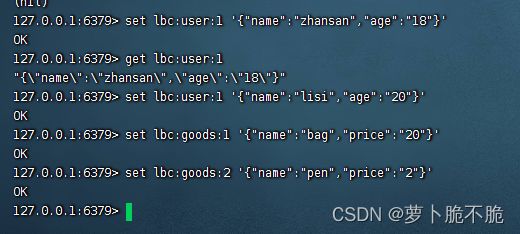
什么是Hash类型,Hash类型,也叫散列,类似于java中的HashMap结构,String类型是将对象序列化成JSON字符串后存储,但需要修改某个字段时很不方便,Hash结构可以将字段单独存储,可以对单个字段做curd
String结构:

Hash结构:

Hash结构的常见命令和String类型的常见命令相似,基本上都是在String命令的基础上加上H,代表操作的时Hash结构
- HSET key field value:添加或修改key中的field的值
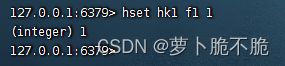
- HGET key field:获取一个hash类型的key的field的值
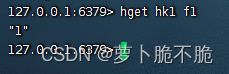
- HMSET key field1 value1 field2 value2 …:批量添加Hash类型的的key的field的值
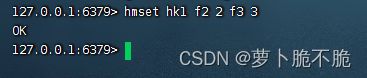
- HMGET key field1 field2 field3 …:批量查看key值的field的值,如果查看的field不存在,则显示null
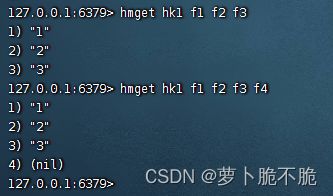
- HGETALL key:获取key中的所有field和value,类似于java中的entryset,获取所有的键值对
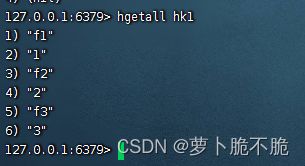
- HKEYS key:获取key中的所有field,类似于Java中的根据键获取值
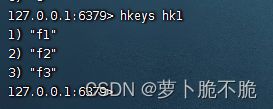
- HVALS key:获取key中的所有value,类似于java中的获取键的方法
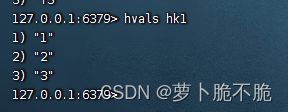
- HINCRBY key field:使一个键中的某一个字段自增指定步长
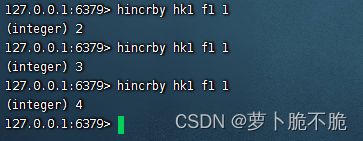
- HSETNCX key field value:添加一个Hash类型的的key和field的值,前提是这个field不存在,否则添加失败

LIst类型的常见命令
Redis中的List类型是一个双向链表结构,具有有序可重复、插入删除快、查询速度一般的特点。
List的常见命令:
- LPUSH key element … :向链表的左侧插入一个或多个元素
- RPUSH key element … :向链表的右侧插入一个或多个元素

resp显示:

- LPOP key count:删除并返回左侧的count个元素,count可以不写,返回左侧第一个元素,若没有元素则返回nil
- RPOP key count:删除并返回右侧的count个元素,count可以不写,返回右侧第一个元素,若没有元素则返回nil
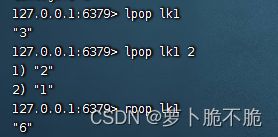
- LRANGE key star end:返回某一角标内的所有元素,包括该角标

- BLPOP key timeout:与LPOP类似,增加了一个等待时间,timeout秒之后,若找不到元素,则返回nil,BLPOP一样

Set类型的常见命令
Redis的Set集合和java中的HashSet类似,可以看做是一个value为null的HashMap。
Set类型的常见命令:
- SADD key member …:向Set中添加一个或者多个元素

- SREM key member:删除set集合中的指定元素

- SCARD key :返回set集合中的元素个数
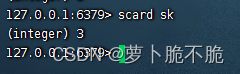
- SISMEMBER key member:判断一个元素是否存在于set中。存在返回1,不存在返回0
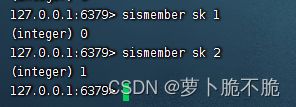
- SMEMBERS key:获取key中的所有元素

- SINTER key1 key2 …:求key1和key2的交集
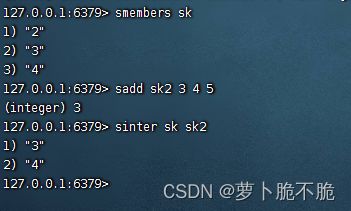
- SDIFF key1 key2 …:求key1和key2的差集
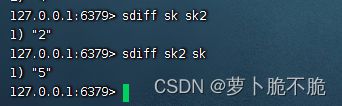
SortedSet类型常用命令
SortedSet是Redis中的一个可排序的set集合,SortedSet集合中的每一个元素都有一个score属性,可以基于score属性对元素进行排序,底层是跳表加哈希表。
SortedSet类型常见命令:
- ZADD key score member:添加一个或多个元素到sortedset集合中,如果已经存在则跟更新其score值
![]()
resp中显示:

- ZREM key member:删除key中的一个指定元素

- ZSCORE key member:获取key中指定member的score值

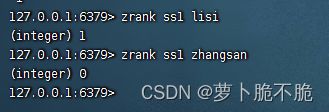
- ZRANK key member:获取key的member的score的排名,也就是下标,从0开始
- ZCARD key:获取key中的元素个数

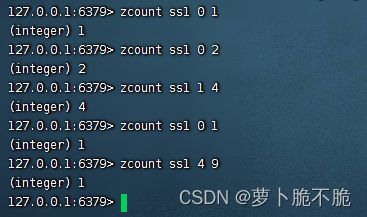
- ZCOUNT key min max:统计score在范围内所有元素的个数
- ZINCRBY key increment member:让key中的member的score自增increment步长

- ZRANGE key min max:按照score排序后,获取指定排名范围内的元素,member值,与zcount格式相同,zount是统计个数,而zrange是统计元素

- ZRANGEBYSCORE key min max:根据score的排序,获取score范围内的元素

- ZDIFF、ZINTER、ZUNION:求差集、交集、并集
Redis的java客户端
Jedis
Jedis是以Redis命令作为方法名称的,学习成本低,简单使用,但是Jedis实例是线程不安全的,多线程环境下需要基于连接池来使用。
Jedis官方网址:GitHub - redis/jedis: Redis Java client
Jedis的基本使用:
- 引入依赖
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>4.4.3version>
dependency>
- 建立连接
@BeforeEach
void setUp(){
//建立连接
jedis = new Jedis("192.168.190.134", 6379);
//设置密码
jedis.auth("123456");
//选择库
jedis.select(0);
}
- 测试连接
@Test
//String类型
void contextLoads() {
//插入数据
String result = jedis.set("name", "lisi");
System.out.println("result="+result);
//获取数据
String name = jedis.get("name");
System.out.println("mame="+name);
}
@Test
//Hash类型
void testHash(){
//插入数据
jedis.hset("user:1","name","zhangsan");
jedis.hset("user:1","age","18");
//获取数据
Map<String, String> stringStringMap = jedis.hgetAll("user:1");
System.out.println(stringStringMap);
}
- 释放资源
@AfterEach
void tearDown(){
//释放资源
if (jedis!=null){
jedis.close();
}
}
补充: @BeforeEach和@AfterEach注解的作用:分别为在执行测试类中的方之前和执行完成之后执行该方法
Jedis连接池
因为Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能消耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式。
编写连接池类
package com.lbc.redisdemo.util;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* @program: Redisdemo
* @Date: 2023/8/4 22:05
* @Author: Huang
* @Description:
*/
public class JedisConnectionFactory {
private static final JedisPool jedisPoll;
static {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
//最大连接
jedisPoolConfig.setMaxTotal(8);
//最大空闲连接
jedisPoolConfig.setMaxIdle(8);
//最小空闲连接
jedisPoolConfig.setMinIdle(0);
//设置等待时长 ms
jedisPoolConfig.setMaxWaitMillis(200);
jedisPoll = new JedisPool(jedisPoolConfig, "192.168.190.134", 6379, 1000, "123456");
}
//获取jedis对象
public static Jedis getJedis(){
return jedisPoll.getResource();
}
}
测试类
package com.lbc.redisdemo;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.lbc.redisdemo.pojo.User;
import com.lbc.redisdemo.util.JedisConnectionFactory;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import redis.clients.jedis.Jedis;
@SpringBootTest
class RedisdemoApplicationTests {
private Jedis jedis;
@BeforeEach
void setUp(){
//建立连接
// jedis = new Jedis("192.168.190.134", 6379);
jedis = JedisConnectionFactory.getJedis();
//设置密码
jedis.auth("123456");
//选择库
jedis.select(0);
}
@Test
void contextLoads() {
//插入数据
String result = jedis.set("name", "lisi");
System.out.println("result="+result);
//获取数据
String name = jedis.get("name");
System.out.println("mame="+name);
}
@Test
void testHash(){
//插入数据
jedis.hset("user:1","name","zhangsan");
jedis.hset("user:1","age","18");
//获取数据
Map<String, String> stringStringMap = jedis.hgetAll("user:1");
System.out.println(stringStringMap);
}
@AfterEach
void tearDown(){
//释放资源
if (jedis!=null){
jedis.close();
}
}
}
SpringDataRedis
SpringData是Spring中数据操作的模块,包含对各种数据的集成,其中对Redis集成的模块就叫SpringDataRedis。
官网:Spring Data Redis
SpringDataRedis的优势:
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一api来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring对象的数据序列化和反序列化
- 支持基于Redis的JDKCollection实现
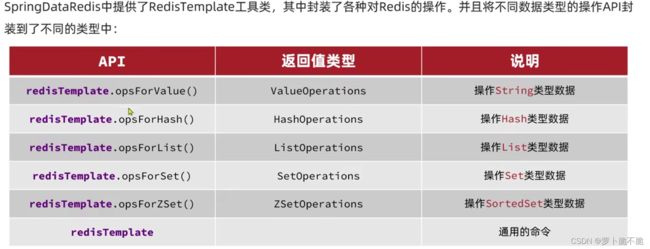
SpringDataRedis基本使用
- 导入依赖
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-databindartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redisartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-pool2artifactId>
dependency>
- 配置文件
spring:
redis:
host: 192.168.190.141
port: 6379
password: 123456
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 100
- 编写测试类
package com.lbc.redisdemo;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.lbc.redisdemo.pojo.User;
import com.lbc.redisdemo.util.JedisConnectionFactory;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import redis.clients.jedis.Jedis;
import java.util.List;
import java.util.Map;
import java.util.Set;
@SpringBootTest
class RedisdemoApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void testString(){
//插入String的一条数据
redisTemplate.opsForValue().set("name","Jack");
//读取一条String类型的数据
Object name = redisTemplate.opsForValue().get("name");
System.out.println(name);
redisTemplate.opsForValue().set("User:10",new User("zhansan","19"));
User o = (User) redisTemplate.opsForValue().get("User:10");
System.out.println("o="+o);
}
@Test
void testHash2(){
//插入数据
redisTemplate.opsForHash().put("User:30","name","zhangsan");
redisTemplate.opsForHash().put("User:30","age","21");
//获取数据
//获取所有键值对
Map entries = redisTemplate.opsForHash().entries("User:30");
//获取所有键
Set keys = redisTemplate.opsForHash().keys("User:30");
//获取所有值
List values = redisTemplate.opsForHash().values("User:30");
System.out.println("键值对="+entries);
System.out.println("键="+keys);
System.out.println("值="+values);
}
}
在RedisTemplate中,对String类型的操作方法名与redis的名字一致,但是对Hash类型的操作是与Map集合的相似,因为Hash类型与java的Map类型一样的键值对存储结构。
RedisTemplate可以接收任意的Object作为值写入Redis,只不过写入之前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是一段长字符,这样可读性差并且内存的占用比较大。
为解决上述问题,我们可以自定义RedisTemplate的序列化形式,编写的配置类如下代码
package com.lbc.redisdemo.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;
/**
* @program: Redisdemo
* @Date: 2023/8/7 9:45
* @Author: Huang
* @Description:
*/
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory redisConnectionFactory){
//创建Template
RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();
//设置连接工厂
redisTemplate.setConnectionFactory(redisConnectionFactory);
//设置序列化工具
GenericJackson2JsonRedisSerializer jackson2JsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
//key和hashKey采用String序列化
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
//value和hashValue采用JSON序列化
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
return redisTemplate;
}
}
重新运行上段测试代码,获得的结果为:

图中还有一段字段为该对象的类名,我们发现类型的所占内存甚至比我们存储的信息还要大,这是我们不希望看到的,于是我们需要手动的对对象进行序列化共和反序列化,代码如下:
package com.lbc.redisdemo;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.lbc.redisdemo.pojo.User;
import com.lbc.redisdemo.util.JedisConnectionFactory;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import redis.clients.jedis.Jedis;
import java.util.List;
import java.util.Map;
import java.util.Set;
@SpringBootTest
class RedisdemoApplicationTests {
private Jedis jedis;
@Autowired
private RedisTemplate redisTemplate;
private static final ObjectMapper mapper = new ObjectMapper();
@Test
void testString() throws JsonProcessingException {
//创建一个对象
User user = new User("zhangsan","20");
//手动序列化
String json = mapper.writeValueAsString(user);
System.out.println(json);
redisTemplate.opsForValue().set("User:20",json);
//获取数据
String jsonUser = (String) redisTemplate.opsForValue().get("User:10");
System.out.println(jsonUser);
//手动反序列化
User user1 = mapper.readValue(jsonUser, User.class);
System.out.println(user1);
}
@Test
void testHash2(){
//插入数据
redisTemplate.opsForHash().put("User:30","name","zhangsan");
redisTemplate.opsForHash().put("User:30","age","21");
//获取数据
//获取所有键值对
Map entries = redisTemplate.opsForHash().entries("User:30");
//获取所有键
Set keys = redisTemplate.opsForHash().keys("User:30");
//获取所有值
List values = redisTemplate.opsForHash().values("User:30");
System.out.println("键值对="+entries);
System.out.println("键="+keys);
System.out.println("值="+values);
}
}
运行获得结果:

Redis的实战运用场景
基于Redis实现共享session登录
session共享问题 :多台Tomcat不会共享session存储空间,当多个请求切换到不同的Tomcat服务时会造成数据丢失的问题。

举个例子,当我们在使用短信验证码登录时,我们先点击发送验证码,这个请求由Tomcat1接收处理了,而产生的验证码存储在Tomcat1的session中,当我们输入验证码点击登录时,由Tomcat2接收处理,当我们需要获取先前产生的验证码与用户输入的验证码进行校验时,这时我们生成的验证码是保存在Tomcat1的session中,而处理这个请求的Tomcat2的session中是没有数据的,这就造成了session共享的数据丢失问题。
为了解决这个问题,我们可以使用Redis来对session的数据进行统一存储管理,这样每一台Tomcat都能获取同一份数据了。
以短信验证码登录为例:

在登录功能中主要存储的信息有两个,一是生成的验证码,二是登录的用户信息,前者需要拿来进行登录校验,后者用来进行拦截操作(部分功能需要登录之后才能使用)。
生成验证码:
@Override
public Result sendCode(String phone, HttpSession session) {
//1、校验手机号
if (RegexUtils.isPhoneInvalid(phone)){
//2、手机号不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
//3、手机号符合,生成验证码
String code = RandomUtil.randomNumbers(6);
//4、保存验证码到redis中 设置验证码有效期为2分钟
stringRedisTemplate.opsForValue().set(LOGIN_CODE_KEY+phone,code,LOGIN_CODE_TTL, TimeUnit.MINUTES);
//5、发送验证码
log.debug("发送短信验证码成功!验证码:{}",code);
return Result.ok();
}
这里使用的数据类型是String类型,并且设置了验证码的有效期为2分钟,为防止产生的验证码过多而引起不必要的麻烦。
登录校验:
@Override
public Result login(LoginFormDTO loginForm, HttpSession session) {
//1、校验手机号码格式
String phone = loginForm.getPhone();
if (RegexUtils.isPhoneInvalid(phone)){
//2、手机号不符合,返回错误信息
return Result.fail("手机号格式错误!");
}
//3、手机号码格式正确,校验验证码 从redis中获取验证码
String cacheCode = stringRedisTemplate.opsForValue().get(LOGIN_CODE_KEY+phone);
String code = loginForm.getCode();
if (code == null || !cacheCode.equals(code)){
//不一致
return Result.fail("验证码错误");
}
//一致 根据手机号查询用户
User user = query().eq("phone", phone).one();
//判断用户是否存在
if (user == null){
//不存在 根据电话号码创建用户
user = createUserWithPhone(phone);
}
//保存用户信息到redis中
//随机生成token,作为登录的令牌
String token = UUID.randomUUID().toString(true);
//将User对象转化成Hash存储
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
//这里UserDTO的id为long类型 需要将long类型转换成String类型才能在Redis中存储
Map<String, Object> userMap = BeanUtil.beanToMap(userDTO,new HashMap<>(),
CopyOptions
.create().setIgnoreNullValue(true)
.setFieldValueEditor((fieldName,fieldValue) -> fieldValue.toString()));
//存储
stringRedisTemplate.opsForHash().putAll(LOGIN_USER_KEY+token,userMap);
//设置有效期
stringRedisTemplate.expire(LOGIN_USER_KEY+token,LOGIN_USER_TTL,TimeUnit.MINUTES);
return Result.ok(token);
}
private User createUserWithPhone(String phone) {
User user = new User();
user.setPhone(phone);
user.setNickName(SystemConstants.USER_NICK_NAME_PREFIX+RandomUtil.randomString(10));
//保存用户
save(user);
return user;
}
这里我们把用户信息的键设置成一个随机生成的唯一的token,这样可以避免一些敏感信息保存在外
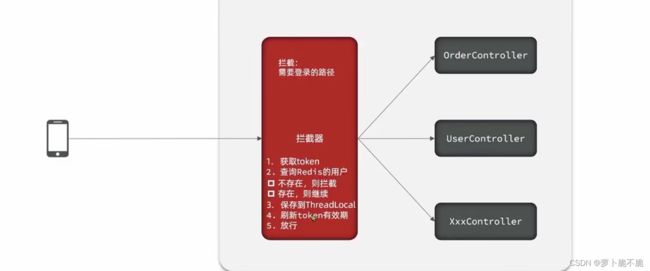
拦截器中从Redis中获取用户信息进行判断拦截:
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//获取请求头中的token
String token = request.getHeader("authorization");
//判断token是否为空
if (StrUtil.isBlank(token)){
response.setStatus(401);
//拦截
return false;
}
//基于token从redis中获取用户
Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(LOGIN_USER_KEY + token);
//判断用户是否存在
if (userMap.isEmpty()){
response.setStatus(401);
//拦截
return false;
}
//将查询到的hash数据转换成userDTO对象
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
//存在 保存用户信息到ThreadLocal
UserHolder.saveUser(userDTO);
//刷新token有效时间
stringRedisTemplate.expire(LOGIN_USER_KEY + token,LOGIN_USER_TTL, TimeUnit.MINUTES);
//放行
return true;
}
这里对拦截器做一些优化,现在我们只有对那些需要拦截的操作才能刷新token的有效期,应该是用户做任何操作都应该刷新token的有效期,我们可以使用两个拦截器,一个用来对所有请求路径进行拦截刷新token的有效期,一个用来对无效的请求进行拦截。
原拦截模式:
双拦截模式:
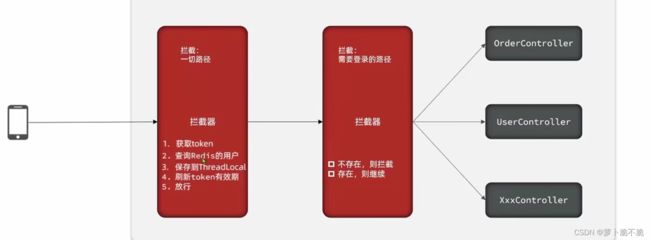
代码:
package com.hmdp.utils;
import cn.hutool.core.bean.BeanUtil;
import cn.hutool.core.util.StrUtil;
import com.hmdp.dto.UserDTO;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.Map;
import java.util.concurrent.TimeUnit;
import static com.hmdp.utils.RedisConstants.LOGIN_USER_KEY;
import static com.hmdp.utils.RedisConstants.LOGIN_USER_TTL;
/**
* @program: hm-dianping
* @Date: 2023/8/8 16:38
* @Author: Huang
* @Description:
*/
public class RefreshTokenInterceptor implements HandlerInterceptor {
private StringRedisTemplate stringRedisTemplate;
public RefreshTokenInterceptor(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//获取请求头中的token
String token = request.getHeader("authorization");
//判断token是否为空
if (StrUtil.isBlank(token)){
return true;
}
//基于token从redis中获取用户
Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(LOGIN_USER_KEY + token);
//判断用户是否存在
if (userMap.isEmpty()){
return true;
}
//将查询到的hash数据转换成userDTO对象
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
//存在 保存用户信息到ThreadLocal
UserHolder.saveUser(userDTO);
//刷新token有效时间
stringRedisTemplate.expire(LOGIN_USER_KEY + token,LOGIN_USER_TTL, TimeUnit.MINUTES);
//放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
//移除用户
UserHolder.removeUser();
}
}
package com.hmdp.utils;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* @program: hm-dianping
* @Date: 2023/8/8 16:38
* @Author: Huang
* @Description:
*/
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//判断用户是否存在
if (UserHolder.getUser() == null){
response.setStatus(401);
return false;
}
return true;
}
}
config配置类
package com.hmdp.config;
import com.hmdp.utils.LoginInterceptor;
import com.hmdp.utils.RefreshTokenInterceptor;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import javax.annotation.Resource;
/**
* @program: hm-dianping
* @Date: 2023/8/8 16:46
* @Author: Huang
* @Description:
*/
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Resource
StringRedisTemplate stringRedisTemplate;
@Override
public void addInterceptors(InterceptorRegistry registry) {
//注册拦截器并设置放行路径
registry.addInterceptor(new LoginInterceptor())
.excludePathPatterns(
"/shop/**",
"/voucher/**",
"/shop-type/**",
"/upload/**",
"/blog/hot",
"/user/code",
"/user/login"
).order(1);
//order越小越先执行
registry.addInterceptor(new RefreshTokenInterceptor(stringRedisTemplate)).order(0);
}
}
Redis缓存
redis的读写效率高,在实际场景中能用来做缓存,那么什么是缓存呢?
缓存是数据交换的缓冲区,是存储数据的地方,一般读写性能要求较高。缓存有好的一面也有坏的一面。
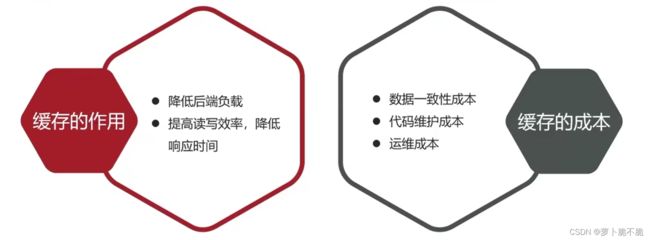
redis的数据是存储在内存当中,所以它的读写效率很高,所以常用来做缓存。那么redis在项目中是如何作为缓存的呢?下面以商铺查询为例,介绍redis如何作为缓存在项目中提高项目的效率。
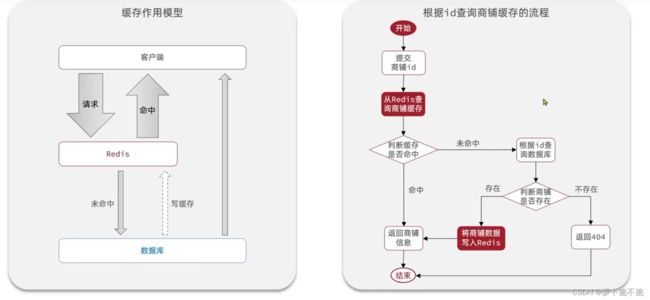
一般情况下,当前端发出一个查询的请求时,我们需要去数据库中查询,在数据库中查询是io操作,这使得查询速率会很慢,这时我们便需要redis作为缓存,当请求打到后端时,我们先从redis缓存中查询我们需要的数据,假如在redis缓存中查询到了我们需要的数据之后,我们可以直接返回,这个过程称为命中,假如redis缓存中没有我们需要的数据,我们则从数据中进行查询,查询到了之后需要将数据写入缓存中以便下一次查询,最后再返回给前端,当下一次发起同样的请求查询同样的数据时,便可以从redis缓存中查询,大大提高查询效率。
package com.hmdp.service.impl;
import cn.hutool.core.util.StrUtil;
import cn.hutool.json.JSONUtil;
import com.hmdp.dto.Result;
import com.hmdp.entity.Shop;
import com.hmdp.mapper.ShopMapper;
import com.hmdp.service.IShopService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import static com.hmdp.utils.RedisConstants.CACHE_SHOP_KEY;
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
StringRedisTemplate stringRedisTemplate;
@Override
public Result queryShopById(Long id) {
//1、从redis中读取缓存
String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
//2、判断redis中是否有缓存
if (StrUtil.isNotBlank(shopJson)){
//3、有,直接读取返回
return Result.ok(JSONUtil.toBean(shopJson,Shop.class));
}
//4、没有 从数据库中读取
Shop shop = getById(id);
//5、判断数据库中是否存在
if (shop == null){
//6、不存在 返回错误信息
return Result.fail("商铺不存在!");
}
//7、存在 写入缓存
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id,JSONUtil.toJsonStr(shop));
return Result.ok(shop);
}
}
缓存更新策略
redis缓存是存储在内存当中,内存的大小是有限的,比较珍贵,所以我们需要有一个缓存的更新策略来保证缓存不会将内存撑爆。缓存的更新策略有以下三种:
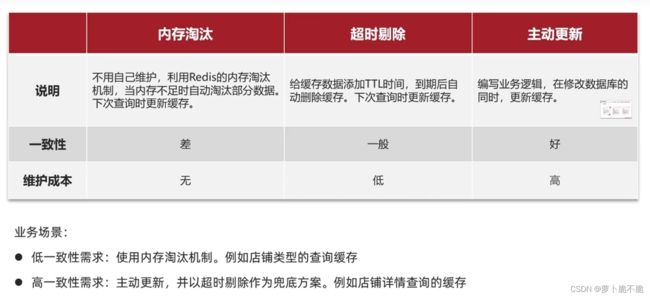
不同的业务场景所使用的更新策略也不同。相对于内存淘汰和超时剔除,主动更新会更安全可靠一些。主动更新策略又有几种不同的方案。

而这三种方案中第一个方案相对于更有优势。在使用方案一时,我们会遇到三个问题。

第三个问题,是先删除缓存还是先操作数据库,下面看具体的分析。
先删缓存再操作数据库:
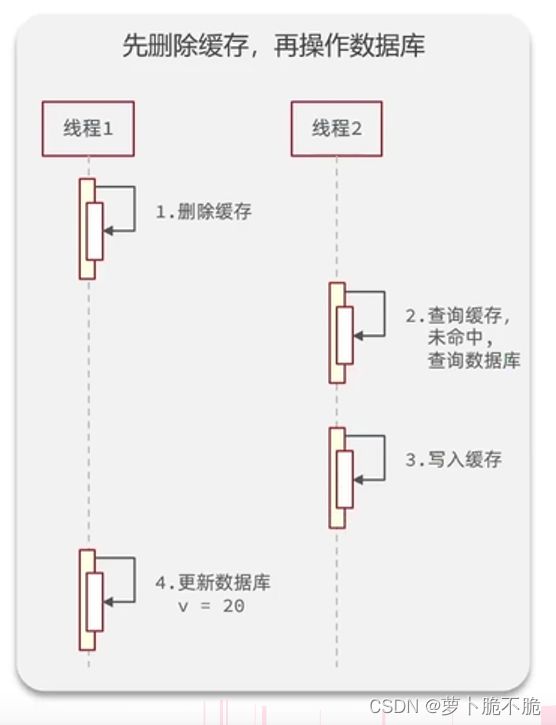
这种做法的弊端是:如图所示的运行顺序,当线程1删除缓存之后,由于更新数据库所需要花费的时间很长,所以当线程2来查询数据时会先查缓存,缓存中的数据已经被线程1删除了,线程2便会起查询数据库中的数据并且把数据重新写入缓存当中,在此期间,更新数据库的操作还没完成,缓存在被线程1删除之后,又被线程2重新写入一份旧数据,这样就造成了数据不同步的问题,在实际开发过程中,这样的情况挺常见。
先操作数据库,再删除缓存:
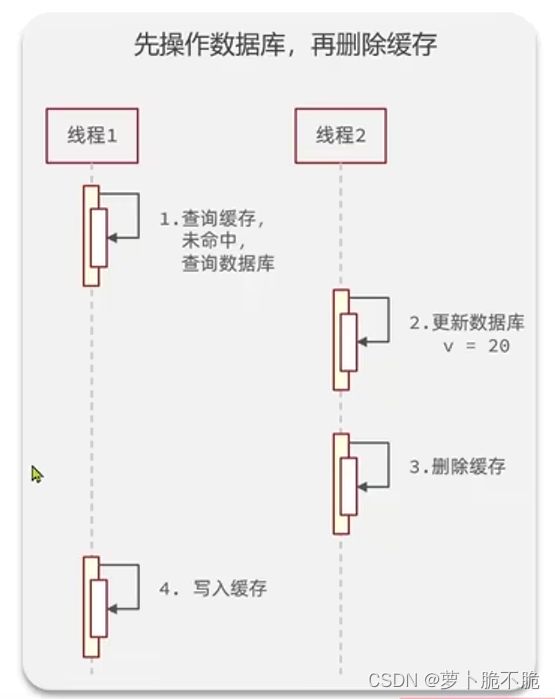
这种做法同样有弊端:如图所示,当线程1去查询数据,先查询缓存,发现未命中,之后去查询数据库,得到了一份数据,这时线程2进来更新数据库,将数据改变了,并且将缓存删掉了,线程1又将先前查询到旧数据写入缓存中,这时便造成了数据不同步的问题。
这两种方式都会出现数据不同步的问题,但是第二种出现问题的概率要比第一种低,所以推荐使用第二种,先操作数据库再删除内存。
缓存穿透
缓存穿透是指当客户端请求的数据在缓存和数据库中都不存在时,这些请求就都会打到数据库当中对你数据库进行查询,当这类请求数量多的情况下,数据库会顶不住压力从而崩掉。
解决方案:
缓存空对象:当我们发现缓存和数据库中都不存在数据时,我们在缓存中添加一个空对象并设置短暂的TTL值,当下次请求打进来时从缓存中获取空对象返回,大大提高效率。
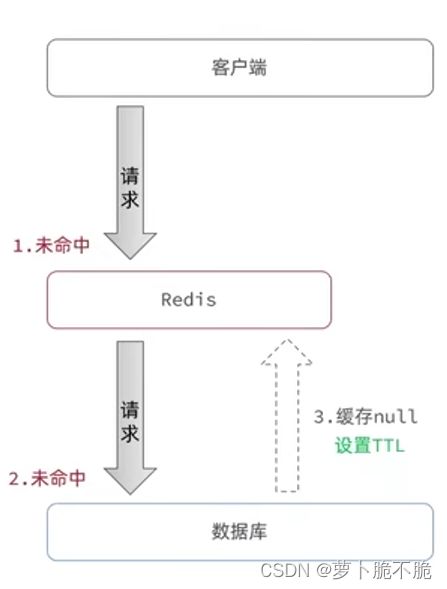
这方案的缺点就是会产生额外的内存消耗,可能造成短期的不一致(当数据库中添加了新的数据,如果先前保存的空缓存还未过期,请求获取的数据还是空对象,与数据库中的数据不一致,我们可以通过控制空缓存的TTL时间来限制这个问题)
代码:
//缓存穿透
public Shop queryWithPassThrough(Long id){
//1、从redis中读取缓存
String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
//2、判断redis中是否有缓存
if (StrUtil.isNotBlank(shopJson)){
//3、有,直接读取返回
return JSONUtil.toBean(shopJson,Shop.class);
}
//判断缓存中是否有空缓存
if (shopJson != null){
return null;
}
//4、没有 从数据库中读取
Shop shop = getById(id);
//5、判断数据库中是否存在
if (shop == null){
//6、不存在 返回错误信息
//向redis缓存中写入空信息
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id,"",CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
//7、存在 写入缓存
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id,JSONUtil.toJsonStr(shop));
return shop;
}
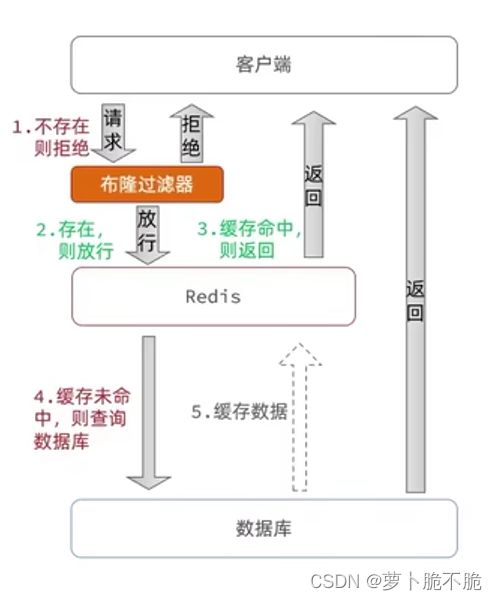
布隆过滤:布隆过滤是在读取缓存之前再加一层过滤器,判断数据是否存在,如果不存在则直接拒绝访问。
缓存雪崩
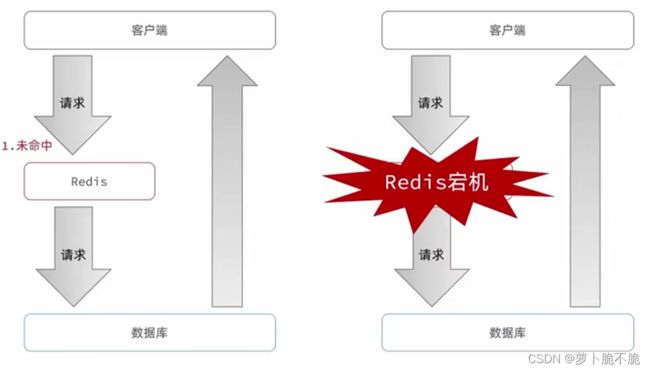
缓存雪崩是指在某一段时间里大量的缓存同时过期或者Redis直接宕机,导致大量的请求到达数据库,给数据库带来巨大的压力。
解决方案:
- 给不同的Key添加随机的TTL值,使它们不在同一时刻过期。
- 利用redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
缓存击穿
缓存击穿也叫热点Key问题,当某个被高并发并且缓存重建业务复杂的key突然失效了,无数的i请求访问会在瞬间给数据库带来巨大的冲击。经常在商铺办活动抢购的情况下出现,这时会有很多的同样的请求打到服务器中,假如这时数据正在更新,缓存中没有数据,则这些大量的请求都会进行数据库。
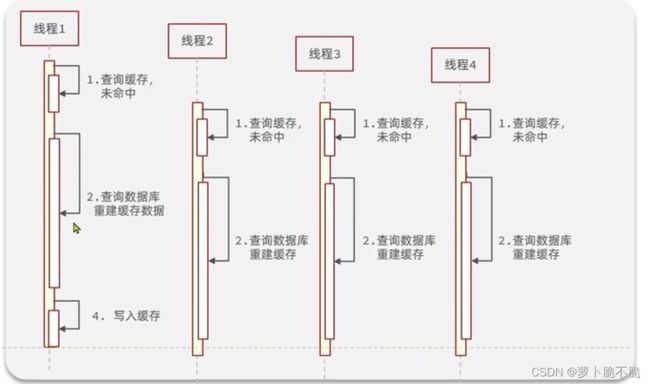
解决方案:
方案一:互斥锁:互斥锁的思路是当线程1查询缓存没有命中后,再去获取互斥锁,加了这把锁之后其他的线程就无法进来操作数据库,只能在外面进行休眠等待,直到线程1完成了数据库的操作并且将数据存入缓存中,在外等着的线程就可以读取缓存返回了。
互斥锁结构图:

代码案例流程图:

代码:
//互斥锁解决缓存击穿
public Shop queryWithMutes(Long id){
Shop shop = null;
try {
//1、从redis中读取缓存
String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
//2、判断redis中是否有缓存
if (StrUtil.isNotBlank(shopJson)){
//3、有,直接读取返回
return JSONUtil.toBean(shopJson,Shop.class);
}
//判断缓存中是否有空缓存
if (shopJson != null){
return null;
}
//4、没有 从数据库中读取
//未命中 尝试获取互斥锁
if (!tryLock(LOCK_SHOP_KEY+id)){
//获取失败,说明有其他线程正在操作数据库 等待
Thread.sleep(50);
//重新尝试读取缓存 递归
queryWithMutes(id);//可用循环代替 这里会一直读取redius直到redis中有数据为止
}
/*获取锁成功 进行第二次读取缓存 二次读取缓存的原因是:如果当前一个线程刚刚操作完数据库并且释放了锁,后一个线程刚好读取完空缓存然后拿到了锁
这样就会再一次对数据库进行操作,在高并发的环境下可能有大量的线程出现这种情况,从而我们需要在拿到锁之后再做一次缓存读取,防止上述情况发生
*/
//1、从redis中读取缓存
String newShopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
//2、判断redis中是否有缓存
if (StrUtil.isNotBlank(newShopJson)){
//3、有,直接读取返回
return JSONUtil.toBean(newShopJson,Shop.class);
}
//判断缓存中是否有空缓存
if (newShopJson != null){
return null;
}
shop = getById(id);
//5、判断数据库中是否存在
if (shop == null){
//6、不存在 返回错误信息
//向redis缓存中写入空信息
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id,"",CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
//7、存在 写入缓存
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id,JSONUtil.toJsonStr(shop));
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
//释放锁
unLock(LOCK_SHOP_KEY+id);
}
return shop;
}
//加锁
public boolean tryLock(String id){
//setIfAbsent方法对应String类型的SETNX key val命令,只有再当前key不存在时才能set成功,可以很好的充当锁的作用
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent(id, "1", LOCK_SHOP_TTL, TimeUnit.SECONDS);
return BooleanUtil.isTrue(lock);
}
//释放锁
public void unLock(String id){
stringRedisTemplate.delete(id);
}
这里有两个注意点,第一是二次读取缓存,我们在请求刚打入时做了一次缓存读取,读取失败后去获取锁,在获取锁成功之后要进行第二次缓存读取,这样做的原因是:如果当前一个线程刚刚操作完数据库并且释放了锁,后一个线程刚好读取完空缓存然后拿到了锁,这样就会再一次对数据库进行操作,在高并发的环境下可能有大量的线程出现这种情况,从而还是有很多的线程去操作数据库,所以我们需要在拿到锁之后再做一次缓存读取,防止上述情况发生。
第二个注意点是,我们这里用的锁并不是常规的lock锁和synchronized,我们采用的是redis中的SETNX key val命令,只有再当前key不存在时才能set成功,可以很好的充当锁的作用,这就能使所有的线程共用同一把锁,分布式锁的思想,不用lock和synchronized的原因是synchronized和lock是单机锁,每个tomcat服务器都会有锁,每次负载均衡到不同的服务器,就会出现有多把锁的情况。
互斥锁解决缓存击穿问题没有额外的内存消耗,能保证数据的一致性,实现起来比较简单,但是每一条未获取锁的线程都需要等待,性能会受到影响,还有死锁的风险。
方案二:逻辑过期:逻辑过期的思想是在缓存对象中添加一个逻辑过期的属性,当线程1进来时,下读取缓存判断是否过期,如果过期则去获取锁,获取锁成功之后开启一条新的线程去操作数据库,自己则带着已经过期的旧数据直接返回,当其他线程进来获取锁失败直接返回过期信息,这样线程就不会一直等待数据更新,提高性能,
逻辑过期结构图:

案例代码流程图:

代码:
//逻辑日期解决缓存击穿问题
private Shop queryWithLogicalExpire(Long id) {
//1、从redis中读取缓存
String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
//2、判断redis中是否有缓存
if (StrUtil.isBlank(shopJson)){
//未命中,直接返回空
return null;
}
//命中 将获取的JSON反序列化成对象
RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);
Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);
LocalDateTime expireTime = redisData.getExpireTime();
//判断缓存是否过期
if (expireTime.isAfter(LocalDateTime.now())){
//未过期
return shop;
}
//过期 尝试获取互斥锁
boolean isLock = tryLock(CACHE_SHOP_KEY + id);
if (isLock){
//获取成功 开启线程 定义了一个线程池
CACHE_REBUILD_EXECUTOR.submit(()->{
try {
this.saveShop2Redis(id,20L);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
//释放锁
unLock(CACHE_SHOP_KEY + id);
}
});
}
//获取失败 再次读取缓存
//1、从redis中读取缓存
String newShopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
//2、判断redis中是否有缓存
if (StrUtil.isBlank(newShopJson)){
//未命中,直接返回空
return null;
}
RedisData NewRedisData = JSONUtil.toBean(shopJson, RedisData.class);
Shop newShop = JSONUtil.toBean((JSONObject) NewRedisData.getData(), Shop.class);
return newShop;
}
public void saveShop2Redis(Long id,Long expireSeconds){
//查询商店信息
Shop shop = getById(id);
//封装过期时间
RedisData redisData = new RedisData();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().plusMinutes(expireSeconds));
//写入redis
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,JSONUtil.toJsonStr(redisData));
}
这里需要注意的是,我们需要在原来的shop添加一个逻辑时间的属性,一般的按照规范来说,我们不能直接去修改原来的对象,降低耦合,我们采用的方案是重新创建一个类RedisData,将Shop类作为RedisDate的一个属性存进去,再在RedisDate中添加一个逻辑时间的属性,这样做可以很好的降低代码的耦合性。
package com.hmdp.utils;
import lombok.Data;
import java.time.LocalDateTime;
@Data
public class RedisData {
private LocalDateTime expireTime;
private Object data;
}
超卖问题
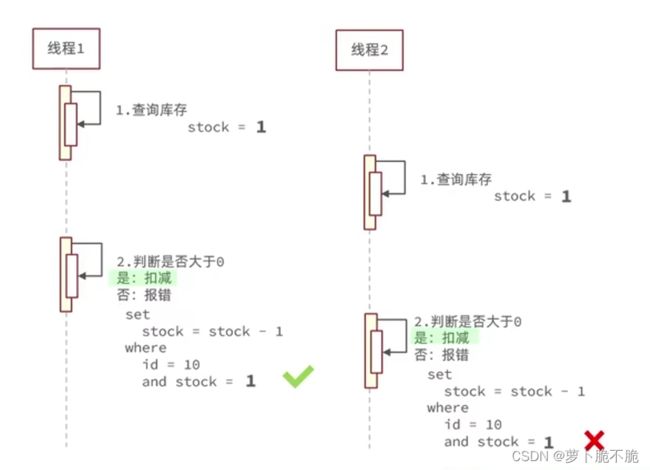
超卖问题是典型的线程安全问题,顾名思义,超卖问题就是商家需要卖出的一类数量有限的商品时,由于多线程同时进行操作数据库,使得数据库的中的商品数量数据出现负数的情况,具体线程执行流程如下图,假设现在某件商品的库存为1,当线程1去查询数据库中的商品库存是否大于0,之后再去对数据库的库存进行扣减操作,但在这时,线程2和线程3也进来了,并且在线程1对数据库进行库存减扣之前进行了查询库存的操作,这时他们拿到的库存数量也是1,同样也可以执行减扣的操作,这时便出现了商品超卖问题,一件商品有三个人买到。

解决超卖问题的常见方法就是加锁
乐观锁和悲观锁
乐观锁和悲观锁是两种常见的加锁理念,下面看看这这两种锁的区别
悲观锁:悲观锁认为线程安全一定会发生,所以在操作数据之前先获取锁,确保线程串行执行,例如Synchronized、Lock都属于悲观锁。
乐观锁:乐观锁认为线程安全不一定会发生,所以不加锁,只有当更新数据的时候去判断数据有没有被修改,如果没有被修改则认为是安全的,自己才可以跟更新数据,如果被修改了则说明出现了线程安全问题,此时可以重试或异常。
乐观锁的关键是判断得到的数据是否被修改过,常见的方法有两种:
版本号法:我们给每一条数据添加一个version版本字段,每次更新数据的时候对version进行加一更新并且使用where条件限制执行,必须当前的版本号与之前查询所得的版本号相同才能执行更新操作。

CAS法:CAS法与版本号法思想是一样的,只不过实现方法不同,CAS法没有给数据添加version字段,而是直接使用查出来的额数据作为限制条件,我们在对数据进行更新的时候,先判断当前的数据是否和先前查询得到的数据相同,用查出来的数据代替version的作用。
实战运用:
代码:
package com.hmdp.service.impl;
import com.hmdp.dto.Result;
import com.hmdp.entity.SeckillVoucher;
import com.hmdp.entity.VoucherOrder;
import com.hmdp.mapper.VoucherOrderMapper;
import com.hmdp.service.ISeckillVoucherService;
import com.hmdp.service.IVoucherOrderService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.hmdp.utils.RedisIdWorker;
import com.hmdp.utils.UserHolder;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
import java.time.LocalDateTime;
@Service
public class VoucherOrderServiceImpl extends ServiceImpl<VoucherOrderMapper, VoucherOrder> implements IVoucherOrderService {
@Resource
private ISeckillVoucherService seckillVoucherService;
@Resource
private RedisIdWorker redisIdWorker;
@Override
@Transactional
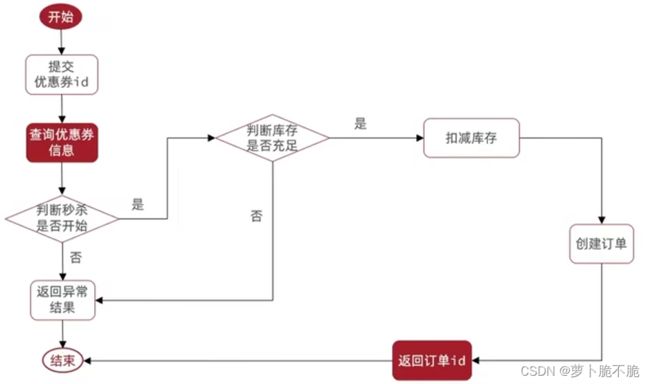
public Result seckillVoucher(Long voucherId) {
//1、查询优惠卷
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
//2、判断秒杀是否开始
if(voucher.getBeginTime().isAfter(LocalDateTime.now())){
//尚未开始
return Result.fail("秒杀尚未开始!");
}
//3、判断秒杀是否结束
if(voucher.getBeginTime().isBefore(LocalDateTime.now())){
//已经结束
return Result.fail("秒杀已经结束!");
}
//4、判断库存是否充足
if (voucher.getStock() < 1){
return Result.fail("库存不足!");
}
//5、减扣库存 这里使用了乐观锁的CAS法
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1")
.eq("voucher_id", voucherId)
//.eq("stock",voucher.getStock())//where id = ? and stock = ? //CAS法
.gt("stock",0)
.update();
if (!success){
//减扣失败
return Result.fail("库存不足!");
}
//6、创建订单
VoucherOrder voucherOrder = new VoucherOrder();
//6.1、订单id
long orderId = redisIdWorker.nextId("order");
voucherOrder.setId(orderId);
//6.2、用户id
Long userId = UserHolder.getUser().getId();
voucherOrder.setVoucherId(userId);
//6.3、代金卷id
voucherOrder.setVoucherId(voucherId);
save(voucherOrder);
//7、返回订单id
return Result.ok(orderId);
}
}
这里做了优化,原来的方式是当stock等于先前查询的数据才进行删减库存的操作,这样做会导致效率低下的问题,所有我们将等于的条件改成大于0的条件,这样可以很好的提高效率。
分布式锁
未完待续