用 OpenCV 检测猫脸
Python中的OpenCV猫脸检测代码

使用 OpenCV 的预训练级联分类器可以轻松检测照片或视频中的猫脸。完成所有工作的代码:
import cv2
cascade = cv2.CascadeClassifier('haarcascade_frontalcatface.xml')
cap = cv2.VideoCapture(0)
while True:
ret, img = cap.read()
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = cascade.detectMultiScale(img_gray, 1.5, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,255,0),2)
roi_gray = img_gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
cv2.imshow('img',img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()让我们逐行检查:
cv2 库被导入。
如果你还没有安装cv2:
#install cv2
pip install opencv-python
#1
import cv2加载级联分类器 XML 文件。
OpenCV 目录中有许多预训练的级联。猫也有一个(实际上是两个)。你可以从此地址下载文件:https://github.com/opencv/opencv/tree/4.x/data/haarcascades
#3
cascade = cv2.CascadeClassifier('haarcascade_frontalcatface.xml')级联分类器
级联是一种集成学习方法,是一种使用多个分类器来提高准确率的方法。第一个级联分类器是 Viola 和 Jones (2001) (https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf)的脸部检测器。这个分类器的要求是快速,以便在低功耗 CPU 上实现,例如相机和电话。
级联是一种训练分类器的方法(分类器是一种机器学习算法,可用于标记事物),以便它们在链中协同工作。链中的第一个分类器训练在几百张你试图检测的事物的“正面”图像上,以及一堆不包含该事物的“负面”图像上。
然后,可以将该分类器应用于图像的一个区域,并尝试检测该对象。如果它没有找到它,它将移动到下一个区域,依此类推,直到它找到了东西或搜索了整个图像。这个过程最常用于面部检测和识别。
该算法通过扫描图像并寻找与训练数据中的特征相匹配的 Haar 特征来工作。如果找到匹配项,则将该区域标记为脸。如果未找到匹配项,则将该区域标记为不是脸。
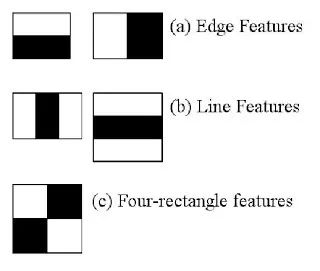
在整个图像中进行这种搜索是一项非常昂贵的业务。想想看,即使是 24x24 的图像也有 160000 个特征。因此,它使用积分图像,这是克服这一问题的有效方法。
积分图像允许快速计算给定矩形下的像素总和,用于计算各种特征。这种方法比传统方法快得多,因此非常适合用于大图像。

位置1的值是A中像素的总和。位置2的值是A和B的总和。位置3:A+C。位置 4 A+B+C+D。D 的值为 (4+1) - (2+3)。
在我们得到这些特征(会有很多)之后,我们需要对它们进行某种过滤,我们需要找出那些能够告诉我们一些东西的特征。Adaboost 是一种机器学习算法,有助于从大量特征中选择最佳特征。它通过关注与手头任务最相关的特征来做到这一点。
我们将每个特征应用于训练图像并获得正负示例中提供的最佳阈值。选择在两个方向上具有最低错误率的特征。Adaboost 的基础分类器很弱。但是当同时使用许多基础分类器时,Adaboost 可以达到一个强大的水平。通过将特征从 160000 个减少到 6000 个特征,实现了超级增益。
通常,包含脸部的区域与整个图像区域相比非常小。因此,到处寻找脸部仍然是低效的。相反,在你的脸更有可能出现在照片中间的区域。
Cascade of Classifiers 是一个引入的概念,以便更有效地将所有特征应用于窗口。这些特征被分组到分类器的不同阶段并被一一应用。如果窗口在第一阶段失败,则不考虑剩余的特征。如果通过,则应用第二阶段的特征并继续该过程。通过所有阶段的窗口就是脸部区域。
为了访问和读取从网络摄像头接收到的数据,我们创建了一个视频捕获对象并传递我们的设备编号。
VideoCapture 类用于捕获视频。你可以传递视频文件的路径。
#5
cap = cv2.VideoCapture(0)启动循环以确保视频数据的连续流。
#7
while True:VideoCapture 对象(cap)读取并解码,返回下一帧视频。
#8
ret, img = cap.read()
#ret is True if there is a video data
#img is the image我们将接收到的图像转换为灰度以最小化计算成本。
#9
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)现在,是时候在提供的图像帧中检测脸部了。我们将使用我们的级联方法。
detectMultiScale方法检测给定图像中各种大小的对象。它接受灰度图像、scaleFactor、minNeighbors、minSize、maxSize。
scaleFactor用于创建比例金字塔,它是一系列不同大小的图像,用于检测图像中不同大小的脸部。较小的比例因子会导致更彻底的脸部搜索,但速度较慢,而较大的比例因子会导致搜索速度更快,但可能会遗漏一些脸部。
minNeighbors 参数指定每个候选矩形应该保留多少个邻居。该参数会影响检测到的脸部质量。数值越高,检测次数越少,质量越高。3~6是很好的参考取值。
minSize确定被检测对象的阈值大小。对于maxSize,则相反。
#10
faces = cascade.detectMultiScale(img_gray, 1.5, 5)在图像中的面部周围绘制矩形。
#12-13-14-15
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,255,0),2)
roi_gray = img_gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]收听事件以结束程序。(在我们的例子中按下退出键)。
#19-20-21
k = cv2.waitKey(30) & 0xff
if k == 27:
break结果:

阅读更多…
在 C++ 中使用 OpenCV 扭曲对象的视角:https://towardsdev.com/warping-an-objects-perspective-with-opencv-in-c-cbe971698ac5
从零开始的 AdaBoostAdaBoost 算法解释和实现:https://medium.com/mlearning-ai/adaboost-from-scratch-f8979d961948
参考
https://docs.opencv.org/3.4/db/d28/tutorial_cascade_classifier.html
https://www.geeksforgeeks.org/detect-cat-faces-in-real-time-using-python-opencv/
https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
