应用层协议设计ProtoBuf
文章目录
- 一、协议设计
- 二、消息帧的完整性判断
- 三、协议设计范例
-
- IM即时通讯
- 云平台节点服务器
- nginx
- http
- redis
- 四、json/xml/protobuf不同序列化对比
-
- 协议安全
- 协议升级
- 五、protobuf工程实践和原理分析
-
- protobuf工程实践
- 原理
一、协议设计
为什么需要协议设计呢
比如说在qq聊天的场景中
文字聊天
文字当中有表情
语音聊天
两端去做沟通,就需要协议设计
如果不做协议设计,服务端就不知道客户端发了些什么东西
二、消息帧的完整性判断
比如说你在qq对话框当中输入文字发出去,就要使用消息帧的完整性判断,例如换行符的判断。

方式有这些
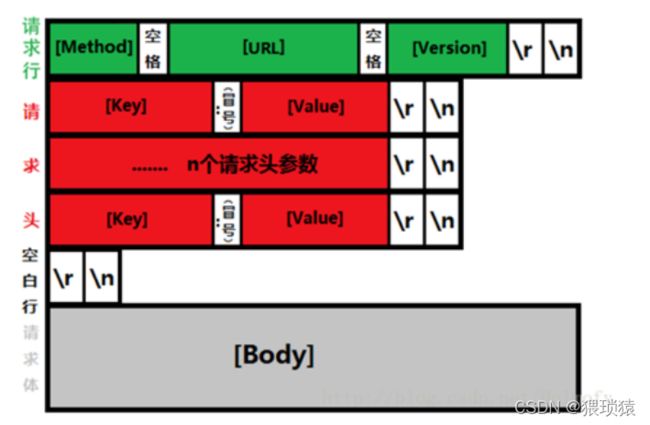
以特定符号来分界,例如\r\n,当在字节流中读取到这种字符串是,则表明上一个消息到此为止,例如我们的http的头部,每一行以这种符号为分隔
固定消息头+消息体结构,这种结构中一般消息头是一个固定长度的结构,并且消息头中有有一个特定的字段指定消息体的大小,收消息时,先接收固定字节数的头部,解出这个消息的完整长度,按此长度接收消息体,这是目前网络用的最多的一种消息格式:header+body。
在序列化后的buffer前面增加一个字符流的头部,http和redis就是用的这种方式,收消息的时候先判断已收到的数据中是否包含结束符,收到结束符后解析消息头,解出这个消息完整的长度,按此长度接收消息体
三、协议设计范例
IM即时通讯
length=head+body
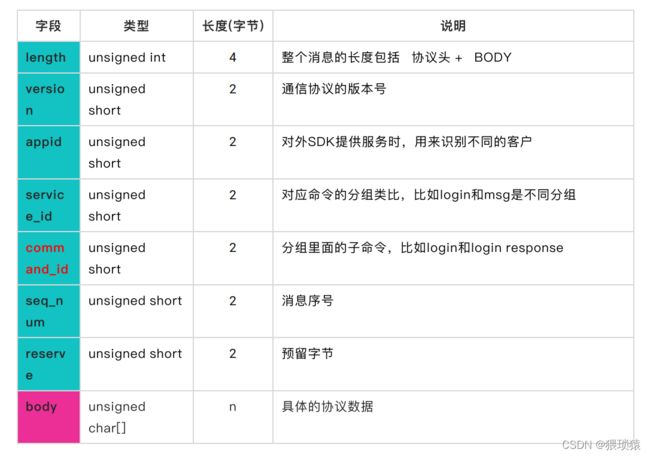
如何区分聊天软件,app的匿名聊天和电商聊天呢
我们用appid去识别,可以区分不同的业务应用
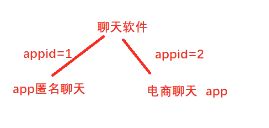 聊天大类,service_id与command_id
聊天大类,service_id与command_id

在代码当中,我们看到左边上边的部分封装的发送的登录的数据,左下是单聊封装的数据,右边是服务器接收消息的功能
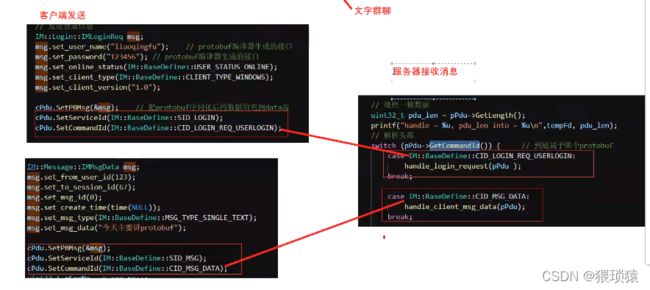 那么这个seq_num(消息序号)的作用是什么呢
那么这个seq_num(消息序号)的作用是什么呢
比如tcp保证消息可答,但不保证业务有处理,业务通过seq_num回应客户端
云平台节点服务器
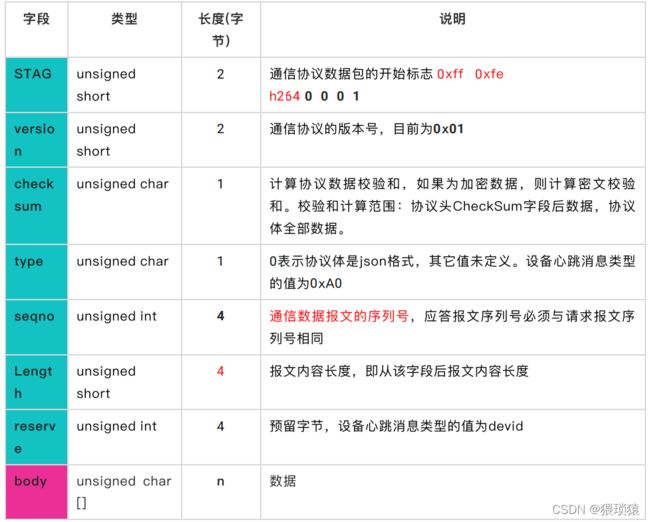
start tag通信协议数据包的开始标志
type,windows与安卓等可以使用protobuf,像单片机设备,51,stm32这些是没办法使用protobuf
length只包括body的长度,不包括head的长度
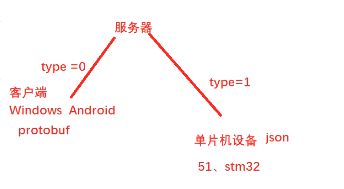
协议都是自定义,序列化协议可以用标准的,比如json、protobuf
nginx
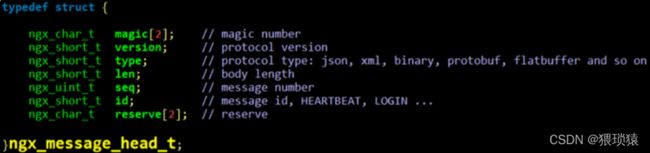
http
HTTP协议是我们最常⻅的协议,我们是否可以采⽤HTTP协议作为互联⽹后台的协议呢?这个⼀般是不适 当的,主要是考虑到以下2个原因:
- HTTP协议只是⼀个框架,没有指定包体的序列化⽅式,所以还需要配合其他序列化的⽅式使⽤才能传 递业务逻辑数据。
- HTTP协议解析效率低,⽽且⽐较复杂(不知道有没有⼈觉得HTTP协议简单,其实不是http协议简单, ⽽是HTTP⼤家⽐较熟悉⽽已)
有些情况下是可以使⽤HTTP协议的: - 对公⽹⽤户api,HTTP协议的穿透性最好,所以最适合;
- 效率要求没那么⾼的场景;
- 希望提供更多⼈熟悉的接⼝,⽐如新浪微、腾讯博提供的开放接⼝;
redis
REDIS协议: 基本原理是:先发送⼀个字符串表示参数个数,然后再逐个发送参数,每个参数发送的时候,先发送⼀个 字符串表示参数的数据⻓度,再发送参数的内容。
四、json/xml/protobuf不同序列化对比
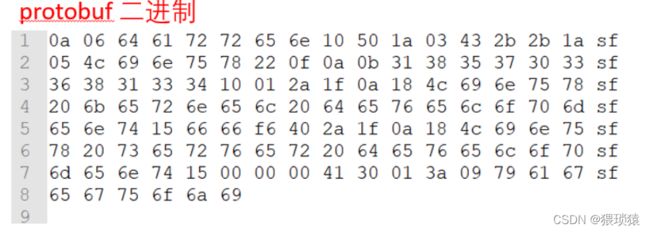
TLV编码及其变体(TLV是tag, length和value的缩写):⽐如Protobuf。
⽂本流编码:⽐如XML/JSON
固定结构编码: 基本原理是,协议约定了传输字段类型和字段含义,和TLV的⽅式类似,但是没有了 tag和len,只有value,⽐如TCP/IP 内存dump:基本原理是,把内存中的数据直接输出,不做任何序列化操作。反序列化的时候,直接还原内存。
主流序列化协议:xml、json、protobuf

-
XML指可扩展标记语⾔(eXtensible Markup Language)。是⼀种通⽤和重量级的数据交换格式。 以⽂本⽅式存储。在本地配置,ui配置,qt,安卓的场景中运用最多

-
JSON(JavaScript ObjectNotation, JS 对象简谱) 是⼀种通⽤和轻量级的数据交换格式。以⽂本结构 进⾏存储。在websocket http协议,注册账号,web里边的登录等用的比较多

protocol buffer是Google的⼀种独⽴和轻量级的数据交换格式。以⼆进制结构进⾏存储。在业务内部,各个服务器之间rpc调用,即时通讯,游戏项目中用的较多
协议安全
xxtea 固定key (https://blog.csdn.net/gsls200808/article/details/48243019)
AES 固定key(https://www.yuque.com/docs/share/e1cc0245-5daf-466b-ad25- 32f9be9dff06?# 《AES详解》)
openssl
Signal protocol 端到端的通讯加密协议(https://www.yuque.com/docs/share/d8305ed5- 53ba-4533-b4ac-f1cbe52b7c58?# 《Signal protocol 开源协议理解》)
协议升级
协议升级= 增加字段
⼤版本
通过版本号指明协议版本,即是通过版本号辨别不同类型的协议
⽀持协议头部可扩展,即是在设计协议头部的时候有⼀个字段⽤来指明头部的⻓度。
五、protobuf工程实践和原理分析
protobuf工程实践
是谷歌私有的一个协议,只是开放出来了,不是国际标准
Protocol buffers是⼀种语⾔中⽴,平台⽆关,可扩展的序列化数据的格式,可⽤于通信协议,数据存储等。
Protocol buffers在序列化数据⽅⾯,它是灵活的,⾼效的。相⽐于 XML 来说,Protocol buffers 更加⼩巧,更加快速,更加简单。⼀旦定义了要处理的数据的数据结构之后,就可以利⽤ Protocol buffers的代码⽣成⼯具⽣成相关的代码。甚⾄可以在⽆需重新部署程序的情况下更新数据结构。只需使⽤ Protobuf 对数据结构进⾏⼀次描述,即可利⽤各种不同语⾔或从各种不同数据流中对你的结构化数据轻松读写。
Protocol buffers很适合做数据存储或 RPC数据交换格式。可⽤于通讯协议、数据存储等领域的语⾔⽆关、平台⽆关、可扩展的序列化结构数据格式。tars brpc
proto文件命名规则
项目.模块.proto
proto命名空间
项目.模块
引用文件
多个平台使用同一份proto文件
安卓,windows客户端,服务器都使用同一份proto文件,如果不使用的话,就会导致各个平台变化的数据不同步
syntax = "proto3";//proto2与proto3,如果要用proto3这里必须标注是proto3,否则会默认是proto2的语法
package IM.Message;//package IM.login
import "IM.BaseDefine.proto";//引用文件
option optimize_for = LITE_RUNTIME;
//service id 0x0003
message IMMsgData{
//cmd id: 0x0301
uint32 from_user_id = 1; //消息发送方
uint32 to_session_id = 2; //消息接受方
uint32 msg_id = 3; //消息ID
uint32 create_time = 4; //创建时间
IM.BaseDefine.MsgType msg_type = 5;
bytes msg_data = 6;
bytes attach_data = 20;
}
message IMMsgDataAck{
//cmd id: 0x0302
uint32 user_id = 1; //发送此信令的用户id
uint32 session_id = 2;
uint32 msg_id = 3;
IM.BaseDefine.SessionType session_type = 4;
}
protobuf字段是通过编号的方式去识别的
比如说string user_name=1,这个1发送到服务器,服务器会识别这个编号是用户名
![]()
编号是可以决定顺序的,所以这个string user_name=1不管在数据包的何种地方,它的字段顺序是不变的,发送和接收端,编号要匹配才能识别对应的字段值是什么。
其中repeated关键字的使用,类似于数组,分内置类型的数组与自定义类型的数组的增加与实例化是不一样的
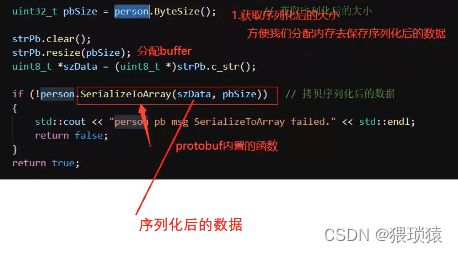
 序列化数据,也就是person对象填充后要去做序列化
序列化数据,也就是person对象填充后要去做序列化
反序列化
主要问题是,采用什么样的对象去承接序列化后的数据,在我们协议设计时候,协议头有字段指明

还有这种判断,phone这个字段不去调用mutable.phone()的话,那么会把phone这个字段去掉,也就是phone的编码不会传,在服务端检测没有这个编号4


原理
protobuf组织结构
5bit 3bit
field num<<3|wire type value
客户端与服务端必须保持一致
 Base128 varints表示值
Base128 varints表示值
通常来说, 普通的 int 数据类型, ⽆论其值的⼤⼩, 所占⽤的存储空间都是相等的, 这点可以引起 ⼈们的思考, 是否可以根据数值的⼤⼩来动态地占⽤存储空间, 使得值⽐较⼩的数字占⽤较少的字节 数, 值相对⽐较⼤的数字占⽤较多的字节数, 这便是变⻓整型编码的基本思想, 采⽤变⻓整型编码的数 字, 其占⽤的字节数不是完全⼀致的, 为了达到这⼀点, Varints 编码使⽤每个字节的最⾼有效位作为 标志位, ⽽剩余的 7 位以⼆进制补码的形式来存储数字值本身, 当最⾼有效位为 1 时, 代表其后还跟 有字节, 当最⾼有效位为 0 时, 代表已经是该数字的最后的⼀个字节, 在 Protobuf 中, 使⽤的是 Base128 Varints 编码, 之所以叫这个名字原因即是在这种⽅式中, 使⽤ 7 bit 来存储数字, 在 Protobuf 中, Base128 Varints 采⽤的是⼩端序, 即数字的低位存放在⾼地址, 举例来看, 对于数 字 1, 我们假设 int 类型占 4 个字节, 以标准的整型存储, 其⼆进制表示应为
 可⻅, 只有最后⼀个字节存储了有效数值, 前3个字节都是 0, 若采⽤ Varints 编码, 每个字节的最高为不能直接用来表示我们的value,它是用来判断字节是否结束(1代表没有结束,0代表结束),其⼆进制形式为
可⻅, 只有最后⼀个字节存储了有效数值, 前3个字节都是 0, 若采⽤ Varints 编码, 每个字节的最高为不能直接用来表示我们的value,它是用来判断字节是否结束(1代表没有结束,0代表结束),其⼆进制形式为
 我们来看看另外一个例子,后边的绿线表示还原过程
我们来看看另外一个例子,后边的绿线表示还原过程

因为其没有后续字节, 因此其最⾼有效位为 0, 其余的 7 位以补码形式存放 1, 再⽐如数字 666, 其以 标准的整型存储, 其⼆进制表示为

我们可以尝试来复原⼀下上⾯这个 Base128 Varints 编码的⼆进制串, ⾸先看最⾼有效位
 接下来我们移除标识位, 由于 Base128 Varints 采⽤⼩端字节序, 因此数字的⾼位存放于低地址上
接下来我们移除标识位, 由于 Base128 Varints 采⽤⼩端字节序, 因此数字的⾼位存放于低地址上

移除标志位并交换字节序, 便得到原本的数值 1010011010, 即数字 666

从上⾯的编码解码过程可以看出, 可变⻓整型编码对于不同⼤⼩的数字, 其所占⽤的存储空间是 不同的, 编码思想与 CPU 的间接寻址原理相似, 都是⽤⼀⽐特来标识是否⾛到末尾, 但采⽤这种⽅式 存储数字, 也有⼀个相对不好的点便是, ⽆法对⼀个序列的数值进⾏随机查找, 因为每个数字所占⽤的 存储空间不是等⻓的, 因此若要获得序列中的第 N 个数字, ⽆法像等⻓存储那样在查找之前直接计算 出 Offset, 只能从头开始顺序查找
⽽采⽤ Varints 编码, 其⼆进制形式为

这里前边的表示数字,后边等号后边表示字节数
Varints

wire_type尽量不要超过15的编号,protobuff是小端存储,如果我们字段经常改动,我们可以考虑使用json



