java重点知识点总结 持续更新
java重点知识点总结
文章目录
- java重点知识点总结
- 前言
- 1、重载和重写
- 2、匿名对象
- 3、可变个数形参的方法
- 4、MVC设计模式
- 5、java.lang.Object类
- 6、自动装箱、自动拆箱
- 7、static、final关键字
- 8、程序、进程、线程
- 9、并行、并发
- 10 、何时需要多线程
- 11、线程调度
- 12、线程安全怎么解决
- 13、String不可变与String拼接
- 14、toCharArry():String转换为char[]
- 15、getBytes():String转换为byte[]
- 16、String、StringBuffer、StringBuilder区别
- 17、枚举列出一组确定的常量的类
- 18、java注解
- 19、AOP与IOC
- 20、java集合(Collection和Map)
- 21、collection和collections的区别
- 22、IO流体系与序列化
- 23、java8、9、10、11新特性
- 24、spring设计模式典型案例
- 25、数据结构
- 26、反射
- 27、数据源分类
- 28、idea查找快捷鍵、继承关系快捷键
- 29、sql事务、分布式事务
- 30、活锁、死锁
- 31.公平锁、非公平锁
- 32.乐观锁、悲观锁|排它锁、共享锁、读锁写锁
- 33.堆、栈
- 34.get、post
- 34.forward、redirect
- 35.hashcode和equals
- 36.cors、jsonp、代理服务器实现跨域问题
- 37.spring-boot特点
- 38.cookie、session、token区别
- 39.JAVA 中的几种基本数据类型是什么,各自占用多少字节
- 40.sql 优化有哪些,含索引创建
- 41.sql重要语法
- 42.MyISAM与InnoDB存储引擎区别
- 43.视图
- 44、DDD领域驱动模型
- 45、java拦截器与过滤器使用场景
- 46、接口幂等性
- 实战场景题
-
- 1. 如何实时统计在线用户(在某个页面、视频下)?
- 2. 项目中如何实现日志输出?
- 3. 完整的项目部署流程?
- 4. 项目中如何处理定时任务?
- 5. 项目中哪些场景用了MQ消息队列,以及用MQ处理分布式事务?
- 6. 项目中怎么实现文件操作的?
- 7. 项目中有哪些功能可以做全局配置的,或者说把这些功能单独做成微服务?
- 8. 微服务之间都是怎么治理的,怎么调用对方的接口?
- 9.用户身份鉴权一般用的什么?
- 总结
前言
以下是本篇文章正文内容,如有表达不全的问题还请指出,本文中插入的图片部分由网上下载,如涉及版权问题联系我删除!!!!,持续更新中!!!!
1、重载和重写
| 重载 | 同一个类 | 方法名相同,参数不同,返回值可以不同 |
|---|---|---|
| 重写 | 子类继承父类 | 方法名相同,参数相同,返回值相同 |
2、匿名对象
没有名字的对象,eg:new Phone().sendEmail();适用于只用一次的场景。
3、可变个数形参的方法
public void show(string…strs){ } 个数不限
4、MVC设计模式
视图层V—>控制层C---->数据模型层M
降低程序耦合性
5、java.lang.Object类
所有类都直接或间接继承Object类,继承它所有的功能。
6、自动装箱、自动拆箱
| 自动装箱 | 基本类型转包装类 | int n = 10; Integer m = n; |
|---|---|---|
| 自动拆箱 | 包装类转基本类 | int n = 10; Integer m = n; int j = m; |
自动装箱:
Integet m = new Integer(10);
Integet n = new Integer(10);
if (m == n) 是不等的Integet m = Integet.valueOf(10);
Integet n = Integet.valueOf(10);
if (m.equals(n) ) 相等自动拆箱:
Integer i = new Integer(10);
int j = i.intValue();
int j = i;
7、static、final关键字
| final | 最终类,修饰方法 | 不能被继承,不能被子类重写 |
|---|---|---|
| static | 静态的 ,修饰属性、方法、代码块、内部类 | 类创建的所有对象都共享同一个静态变量,如下图 |
class Test {
public static void main(String[] args) {
// 创建第一个 Student 对象,并赋值
Student s1 = new Student();
s1.name = "小明";
s1.country = "中国";
// 创建第二个 Student 对象
Student s2 = new Student();
System.out.println(s1);
System.out.println(s2);
}
}
class Student {
//非静态属性
public String name;
//静态属性
public static String country;
//无参构造
public Student() {
}
//toString 方法
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
"country='" + country + '\'' +
'}';
}
}
输出
Student{name='小明’country=‘中国’}
Student{name='null’country=‘中国’}
8、程序、进程、线程
| 程序 | 静态代码 | / |
|---|---|---|
| 进程 | 正在运行的程序 | 比如启动杀毒软件 |
| 线程 | 程序内部一条执行路径 | 杀毒软件可以同时进行电脑体检、清理、杀毒说明支持多线程;java.exe进程包括main主线程、gc线程、异常处理线程,异常会影响主线程 |
9、并行、并发
| 并行 | 多个人同时做不同事 |
|---|---|
| 并发 | 多个人同时做同一件事,比如秒杀 |
10 、何时需要多线程
- 同时执行两个或多个任务
- 有需要等待的任务:用户输入、文件读写、网络操作、搜索等
- 需要一些后台运行的程序
| 实现方法 | 实现过程 |
|---|---|
| 继承Thread类 | 1、创建子类,继承Thread类 2、重写run() 3、创建子类对象 4、对象.start() |
| 实现Runnable方法 | 1、创建实现Runnable方法的类 2、实现run()方法 3、创建Thread对象,将类作参数传过去 4、Thread.start(); 好处: 1、继承Thread类:如果本身就继承的有其他父类,就没办法继承Thread类了,有局限性,通常都会选Runnable方法; 2、实现的方式更适合来处理多个线程共享数据的情况 |
| 实现Callable接口 | 1、创建一个实现Callable的实现类 2、实现call方法,将此线程需要执行的操作声明在call()中 3、创建FutureTask的对象,将类作参数传过去 4、创建Thread对象,Thread(FutureTask的对象).start() 5、get()获取Callable中call方法的返回值 好处: 1、call()可以有返回值、可抛异常供外部捕获,而run()没有; 2、Callable接口支持泛型:implements Callable< Integer >通过指定泛型,call()方法的返回值就会有类型 |
| 使用线程池 | 1、提供指定线程数量的线程池 2、执行指定的线程的操作。需要提供实现Runnable接口或Callable接口实现类的对象 3、关闭连接池 好处: 1、便于线程管理 ,提高响应速度, 2、重复利用线程池中线程,不需要每次都创建,降低资源消耗 |
// 继承Thread类
// 主线程
public class thread_test{
public static void main(String[] args){
ThreadTest1 threadTest1 = new ThreadTest1();
ThreadTest2 threadTest2 = new ThreadTest2();
threadTest1.start();
threadTest2.start();
System.out.println("3333");
}
}
// 子线程1
class ThreadTest1 extends Thread {
@Override
public void run() {
System.out.println("11111");
}
}
// 子线程2
class ThreadTest2 extends Thread {
@Override
public void run() {
System.out.println("2222");
}
}
输出
3333
2222
11111
// 实现Runnable方法
public class runnable_test {
public static void main(String[] args){
Thread thread = new Thread(new RunnableTest());
thread.start();
}
}
class RunnableTest implements Runnable{
@Override
public void run() {
System.out.println("111111");
}
}
// 实现Callable接口
//1.创建一个实现Callable的实现类
class NumThread implements Callable {
//2.实现call方法,将此线程需要执行的操作声明在call()中
@Override
public Object call() throws Exception {
return "11111";
}
}
class callable_test {
public static void main(String[] args) {
//3.创建FutureTask的对象,将类作参数传过去
FutureTask futureTask = new FutureTask(new NumThread());
//4.将FutureTask的对象作为参数传递到Thread类的构造器中,创建Thread对象,并调用start()
new Thread(futureTask).start();
try {
//5.get()获取Callable中call方法的返回值
Object ss = futureTask.get();
System.out.println(ss);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
public class Executor_test {
public static void main(String[] args) {
// 1. 提供指定线程数量的线程池
ExecutorService service = Executors.newFixedThreadPool(5);
ThreadPoolExecutor threadPool = (ThreadPoolExecutor) service;
// 设置线程池的属性
threadPool.setCorePoolSize(15); // 核心池的大小
threadPool.setMaximumPoolSize(20); // 最大线程数
// threadPool.setKeepAliveTime(); // 线程没任务时最多保持多长时间后会终止
// 2.执行指定的线程的操作。需要提供实现Runnable接口或Callable接口实现类的对象
threadPool.execute(new executorTest1()); //execute: Runnable接口
threadPool.execute(new executorTest2());
try {
//submit: Callable接口,需要用get获取返回值,顺便捕捉异常
Future<Integer> i = threadPool.submit(new executorTest3());
System.out.println(i.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
;
// 3.关闭连接池
service.shutdown();
}
}
class executorTest1 implements Runnable {
@Override
public void run() {
System.out.println("1111");
}
}
class executorTest2 implements Runnable {
@Override
public void run() {
System.out.println("222");
}
}
class executorTest3 implements Callable<Integer> {
@Override
public Integer call() throws Exception {
return 10;
}
}
关于线程的方法:
| run() | 被重写的方法 |
|---|---|
| start() | 启动线程,调用当前线程run() |
| getName()、setName() | 得到、设置线程名字 |
| yield() | 释放当前cpu的执行权 |
| currentThread() | 返回当前线程 |
| join() | 在线程a中调用线程b.join(),让线程a等待线程b执行结束之后再运行,等待时线程a进入阻塞状态 |
| sleep(Long millitime) | 睡眠指定毫秒,睡眠时程阻塞状态 |
| stop() | 结束线程 |
| isAlive() | 是否启动 |
| getPriority()、setPriority()) | 优先级 |
| notify()、notifyAll()) | 唤醒一个正在等待的线程 |
线程生命周期
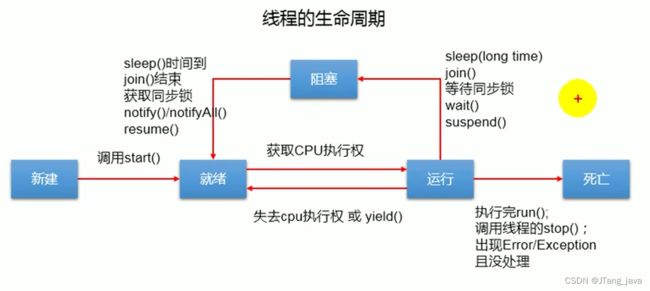
11、线程调度
同优先级先进先出
高优先级的线程会抢占cpu
12、线程安全怎么解决
像两个人同时在同一账户取钱,可能会发生线程安全问题
解决:同步机制
1、同步机代码块
2、同步方法
同步是一种高开销的操作,因此应该尽量减少同步的内容,通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可
| 同步机代码块 | synchronized(同步监视器){ //需要同步的代码 } |
|---|---|
| 同步方法 | public synchronized void save(){} |
| 特殊域变量(volatile) | public synchronized void save(){} |
| lock() : 获得锁 | Lock lock = new ReentrantLock(); lock.lock(); Lock是接口,要手动解锁unclock |
| ThreadLocal | 解决多线程中相同变量的访问冲突问题 |
| synchronized | 但是容易造成资源的浪费,是一种重量锁 |
|---|---|
| volatile | 轻量锁,锁住的是变量,不会阻塞线程,只能保证可见性,不保证原子性 |
| synchronized | 中途不能控制 |
|---|---|
| lock | 可控制、释放锁,非公平锁 |
同步机代码块 说明:
1.操作共享数据的代码,即为需要同步的代码 -->不能包含多了代码也不能包含少了。
2.共享数据:多个线程共同操作的变量。比如ticket就是共享数据
3.同步监视器,俗称:锁。任何一个类的对象都可以充当锁
要求:多个线程必须共用同一把锁(同一个对象)
补充:在实现Runnable接口创建多线程的方式中,我们可以考虑使用this充当同步监视器
// synchronized同步代码块
public class synchronized_test {
public static void main(String[] args) {
// 创建三个不同线程对象
ThreadTest threadTest = new ThreadTest();
Thread thread1 = new Thread(threadTest);
Thread thread2 = new Thread(threadTest);
Thread thread3 = new Thread(threadTest);
thread1.start();
thread2.start();
thread3.start();
}
}
class ThreadTest implements Runnable {
private Integer num = 50;
@Override
public void run() {
while (true) {
//this代表的唯一的当前对象,将共享操作synchronized
synchronized (this) {
if (num > 0) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ":" + num);
num--;
} else break;
}
}
}
}
13、String不可变与String拼接

参考https://blog.csdn.net/weixin_38004638/article/details/115012897
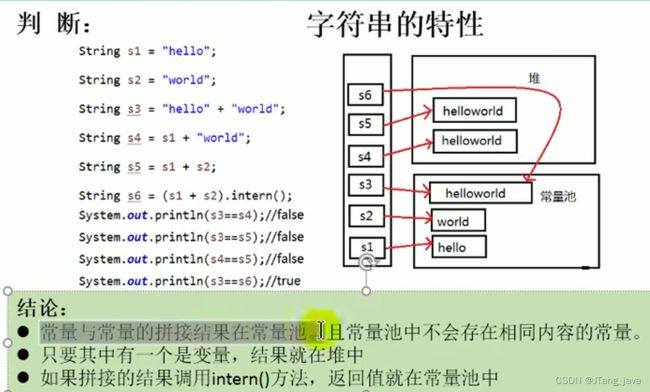
- string类能不能被继承,String类实际是一个被final关键字修饰的char[]数组,所以实现细节上也是不允许改变,它是Immutable(不可变)属性
- 因为字符串是不可变的,所以是多线程安全的,同一个字符串实例可以被多个线程共享。这样便不用因为线程安全问题而使用同步。字符串自己便是线程安全的
- 通过反射我们可以修改String的值
14、toCharArry():String转换为char[]
15、getBytes():String转换为byte[]
16、String、StringBuffer、StringBuilder区别
| String | 不可变 | / | / | 操作少量数据 |
|---|---|---|---|---|
| StringBuffer | 可变,初始容量16,扩容机制都是"旧容量*2+2" | 线程安全synchronized | 效率低 | 适合多线程,并发量小, |
| StringBuilder | 可变,初始容量16 | 线程不安全 | 高 | 速度快,一般都是单线程,用这个好点,线程安全问题可以通过ThreadLocal解决,可用于高并发 |

扩容机制:

17、枚举列出一组确定的常量的类
比如星期类、季节类、性别类
自定义类实现枚举:
- 将构造器私有化,目的是防止被new出对象
- 去掉 setXxxx() 方法,防止属性被修改
- 在Season内部,直接创建固定对象
- 对外暴露对象(通过为对象添加 public static final 修饰符)
public class Demo03 {
public static void main(String[] args) {
System.out.println(Season.AUTUMN);
System.out.println(Season.SUMMER);
}
}
class Season{
private String name;
private String desc;
//定义了四个对象
//加final是为了使引用不能被修改
public static final Season SPRING = new Season("春天", "温暖");
public static final Season WINTER = new Season("冬天", "寒冷");
public static final Season SUMMER = new Season("夏天", "炎热");
public static final Season AUTUMN = new Season("秋天", "凉爽");
private Season(String name, String desc) {
this.name = name;
this.desc = desc;
}
public String getName() {
return name;
}
public String getDesc() {
return desc;
}
@Override
public String toString() {
return "Season{" +
"name='" + name + '\'' +
", desc='" + desc + '\'' +
'}';
}
}
输出:
Season{name=‘秋天’, desc=‘凉爽’}
Season{name=‘夏天’, desc=‘炎热’}
使用enum关键字实现枚举:
- 使用 enum 关键字代替 class
- 常量对象名(实参列表)
- public static final Season2 SPRING = new Season2(“春天”, “温暖”); 等价于 SPRING(“春天”, “温暖”);
- 如果有多个对象,需要使用
,间隔 - 如果使用 enum 关键字来实现枚举,要求将定义的常量对象写在最前面
public class Demo04 {
public static void main(String[] args) {
System.out.println(Season2.SPRING);
System.out.println(Season2.SUMMER);
}
}
enum Season2{
SPRING("春天", "温暖"),WINTER("夏天", "炎热"),SUMMER("夏天", "炎热"),AUTUMN("秋天", "凉爽");
private String name;
private String desc;
private Season2(String name, String desc) {
this.name = name;
this.desc = desc;
}
public String getName() {
return name;
}
public String getDesc() {
return desc;
}
@Override
public String toString() {
return "Season{" +
"name='" + name + '\'' +
", desc='" + desc + '\'' +
'}';
}
}
18、java注解
自定义注解实现拦截器和日志打印功能参考
https://editor.csdn.net/md/?articleId=126342182
1、spring各个层级注解:MVC模型分别对应:model处理业务@Repository+@Service、接收与响应@Controller、
2、spring注入一个类为配置类:@Configuration、@Component表示这个类是spring管理的bean、实体类加@ConfigurationProperties(prefix = “image”)注解以绑定application.yml配置文件中前缀为image的属性
boot配置属性、@SpringBootApplication、@MapperScan扫描mapper
3、接口请求响应的注解:@ResponseBody、@RequestBody、@RequestParam、@RequestMapping设置请求地址和请求方式、@Path、@POST
4、实体类里面的注解:@Entity,@Column标识实体类中属性与数据表中字段的对应关系,@Id主键、@Generated自动生成、@TableName标注对应数据库名、@Data提供读写属性、@NonNull属性非空声明、@IntercerptorIgnore忽略多租户拦截器
5、注入bean的注解:@Inject+@Named按名称、@Autowired+@Qualifier按名称、@Resource
6、java类里面的注解:@Override复用,@SIf4j方便打印log
其他注解参考https://blog.csdn.net/qq_45807943/article/details/116980851
19、AOP与IOC
AOP:面向切面编程,缩写:Aspect-oriented Programming,日志记录,性能统计,安全控制,事务处理,异常处理;
IOC:控制反转,一个容器;
DI:依赖注入,是控制反转的实现。依赖什么对象就注入什么对象。可以通过setter方法注入(设值注入)、构造器注入和接口注入三种方式来实现;
反转:不能主动去获取外部资源,而是被动等待 IoC/DI 容器给它注入它所需要的资源。
为什么要反转:解耦
参考https://baijiahao.baidu.com/s?id=1677252147318999232&wfr=spider&for=pc
setter注入对象:

构造器注入:
除了上面的手动注入,还可以通过主动装配与注解注入:
@Resource:java的注解,默认以byName的方式去匹配与属性名相同的bean的id,如果没有找到就会以byType的方式查找,如果byType查找到多个的话,使用@Qualifier注解(spring注解)指定某个具体名称的bean
@Autowired:spring注解,默认是以byType的方式去匹配与属性名相同的bean的id,如果没有找到,就通过byName的方式去查找
@Inject
参考https://blog.csdn.net/shangliangren/article/details/123932809
20、java集合(Collection和Map)
| 集合体系 | 结构 |
|---|---|
| Collection接口 | 单列集合,存储一个一个的数据 |
| Map接口 | 双列集合,存储key-value一对一对的数据 |

6在这里插入图片描述
PressOn链接https://www.processon.com/view/link/5e61cb68e4b0a967bb396f06
Collection接口方法
| retainAll() | 两个数组交集 | |
|---|---|---|
| stream()() | 流 | jdk8新方法 |
| parallelStream() | 并行流 | jdk8新特性 |
| spliterator()() | 并行流分割器 | jdk8新特性 |
| removeIf() | 如果满足就lambda方式移除元素 | jdk8新特性 |
List接口方法
| subList(0, 1) | 截取集合中的部分元素 |
|---|---|
| sort() | 排序 |
| listIterator() | 迭代器 |
ArryList接口方法
| clone() | 克隆 |
|---|---|
| ensureCapacity(N) | 预先设置list的大小,自动扩容1.5倍 |
| trimToSize() | 将动态数组中的容量调整为数组中的元素个数,减少数据空间 |
ArrayList有三种初始化方法:
1、初始化一种指定集合大小的空ArrayList;
2、初始化一个空的ArrayList;
3、初始化一个含有指定元素的ArrayLsit。
LinkedList接口方法
| addFirst()/addLast() | 头部插入特定元素 |
|---|---|
| descendingIterator() | 按相反的顺序迭代 |
| element()/getFirst()/peek() | 返回第一个元素 |
| element()/getFirst() | 返回第一个元素 |
| indexOf() | 查找指定元素从前往后第一次出现的索引 |
| offer() | 向链表末尾添加元素 |
| poll() | 删除并返回第一个元素 |
| pop() | 弹出一个元素 |
| push() | 压入元素 |
| poll() () | 删除并返回第一个元素 |
| pop() | 弹出一个元素 |
Map接口方法
| compute() | 对 hashMap 中指定 key 的值进行重新计算 |
|---|---|
| containsKey() | 包含key |
| containsValue() | 包含value |
| entrySet() | 返回 hashMap 中所有映射项的集合 |
| keySet() | 返回 hashMap 中所有 key 组成的集合 |
| merge() | 合并 |
| replace () | 替换 |
其他方法参考https://www.runoob.com/java/java-arraylist.html
数组转换为集合:Arrays.asList(数组名)
集合转换为数组:list.toArray();
21、collection和collections的区别
collection:集合;
Collections:是一个工具类,它包含了很多静态方法,不能被实例化,比如排序方法: Collections. sort(list)等。
Collections.addAll(单值类型集合,元素1,元素2,元素3);
Collections.sort(list集合);
Collections.sort(list集合,比较器对象)
Collections.reverse(list集合); // 降序排序
让线程不安全的变成安全的:
Collections.synchronizedList(list集合);
Collections.synchornizedSet(set集合);
Collections.synchronizedSortedSet(sortedSet集合);
Collections.sycchronizedCollection(collection集合);
22、IO流体系与序列化

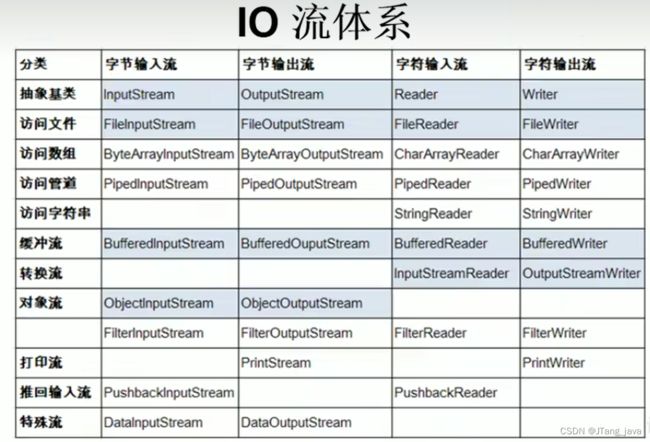
1、文本文件(.txt,.java ,.c ,.cpp),使用字符流
2、非文本文件(.jpg,.mp3,.doc,.ppt),用字节流。
版权声明:下面关于序列化的知识点由CSDN博主「Be a good programmer」的原创文章,遵循 CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xiaoxinxin123456789/article/details/83545946
序列化:(从内存中的数据传到硬盘中)
1、序列化能把堆内存中的对象的声明周期延长,做持久化操作,当下次再需要这个对象的时候,我们不用new了,直接从硬盘中读取就可以了(存储到硬盘上的是一个文件,不需要我们再去解析了,如果用记事本打开解析会出现乱码,解析要用特定的方式,不用我们管,我们只能需要读取)
MyBatis 的二级缓存,实际上就是将数据放进了硬盘文件中去了。
2、在搞web开发的时候一些类就需要实现序列化接口,因为服务器就会对你的对象进行临时本地存储,他怕服务器崩了的以后,你的会话都消失了,所以存储在硬盘上,你重新启动服务器会恢复之前的会话,回复对象,你之前运行的东西还会在。
序列化API:
1、java.io.ObjectOutputStream代表对象输出流,它的writeObject(Object obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
2、java.io.ObjectInputStream代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
3、只有实现了Serializable和Externalizable接口的类的对象才能被序列化。Externalizable接口继承自 Serializable接口,实现Externalizable接口的类完全由自身来控制序列化的行为。
4、而仅实现Serializable接口的类可以 采用默认的序列化方式 。
对象序列化步骤:
1、创建一个对象输出流,它可以包装一个其他类型的目标输出流,如文件输出流;
2、通过对象输出流的writeObject()方法写对象。
对象反序列化步骤:
1、创建一个对象输入流,它可以包装一个其他类型的源输入流,如文件输入流;
2、通过对象输入流的readObject()方法读取对象。
// 对象序列化
Employee e = new Employee();
e.name = "Reyan Ali";
e.address = "Phokka Kuan, Ambehta Peer";
e.SSN = 11122333;
e.number = 101;
try
{
FileOutputStream fileOut =
new FileOutputStream("D:/学习文件/百度网盘下载资料/employee.ser");
// 1、创建对象输出流,它可包装一个文件输出流
ObjectOutputStream out = new ObjectOutputStream(fileOut);
// 调用writeObject()方法将创建好的Employee对象写入流中
out.writeObject(e);
// 关闭各种流
out.close();
fileOut.close();
System.out.printf("Serialized data is saved in /tmp/employee.ser");
}catch(IOException i)
{
i.printStackTrace();
}
// 反序列化
Employee e = null;
try
{
FileInputStream fileIn = new FileInputStream("D:/学习文件/百度网盘下载资料/employee.ser");
// 1、创建对象输入流,它可包装一个文件输入流
ObjectInputStream in = new ObjectInputStream(fileIn);
// 2、用readObject()方法读取流中的对象出来
e = (Employee) in.readObject();
// 关闭各种流
in.close();
fileIn.close();
}catch(IOException i)
{
i.printStackTrace();
return;
}catch(ClassNotFoundException c)
{
System.out.println("Employee class not found");
c.printStackTrace();
return;
}
System.out.println("Deserialized Employee...");
System.out.println("Name: " + e.name);
System.out.println("Address: " + e.address);
System.out.println("SSN: " + e.SSN);
System.out.println("Number: " + e.number);
23、java8、9、10、11新特性
24、spring设计模式典型案例
![]()
参考:https://csdn.net/qq_42373007/article/details/115398373
单例模式:某个类只有一个实例
补充:责任链设计模式:过滤器中的FilterChain.doFilter()方法,意思是放行当前过滤器,进入下一个过滤器。
25、数据结构
数据结构参考:https://zhuanlan.zhihu.com/p/337183238
26、反射
27、数据源分类
原生态:JDBC
封装:dbcp,c3p0,druid
Spring 推荐使用dbcp;
Hibernate 推荐使用c3p0和proxool
28、idea查找快捷鍵、继承关系快捷键
搜索类、文件:双shift、ctrl+shift+n
查看类继承关系:列表: ctrl+H; 图示: ctrl+alt+shift+U

29、sql事务、分布式事务
- 事务:数据库操作
- 这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行。如果任何一个SQL操作失败,那么整个操作就都失败,所有操作都会回滚到操作前状态,或者是上一个节点
截图来自韩顺平老师课程
- 用 Connection 对象控制

关于事务,举个例子:
例如以银行转账为例,从原账户扣除金额,以及向目标账户添加金额,这两个阶段的操作,被视为一个完整的逻辑过程,不可拆分。
简单的说,要么全部成功,要么全部失败!这个过程被称为一个事务,具有 ACID 四个特点!
并发操作的几个问题:
(1)脏读:A操作a数据,还未提交,B又来操作它并提交了(A读的是脏数据,update,delete,insert操作);
(2)不可重复读:eg:A正在读取一个记录,他只想读取当前时间以前的,但B在这个时候立马修改或删除了一条数据,A读到这条数据时就变了(update,delete操作)
(3)幻读:eg:A正在读取某个范围的记录,他只想读取当前时间以前的,但B在这个时候立马插入了一条数据,A读到这个范围的数据时就变了(insert操作)

隔离级别:
(1)Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
(2)Repeatable read (可重复读):可避免脏读、不可重复读的发生。默认。
(3)Read committed (读已提交):可避免脏读的发生。
(4)Read uncommitted (读未提交):最低级别,任何情况都无法保证。

本机上查询默认隔离级别是可重复读,参考文章:https://blog.51cto.com/u_15880918/5859919:
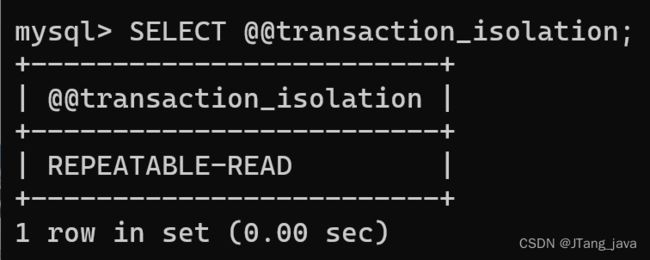
本机上设置隔离级别为读未提交:

事务的特性:ACID
1、原子性(Atomicity):
事务是一个完整的操作。事务的各步操作是不可分的(原子的);要么都执行,要么都不执行。
2、一致性(Consistency):
当事务执行失败时,所有被该事务影响的数据都应该恢复到事务执行前的状态。
3、隔离性(Isolation):
对数据进行修改的所有并发事务是彼此隔离的,这表明事务必须是独立的,它不应以任何方式依赖 于或影响其他事务。
4、持久性(Durability):
事务完成后,它对数据库的修改被永久保持,事务日志能够保持事务的持久性。
事务实现方式:
1、编程式:硬编码,代码多;
2、声明式:@Transactional注解、aop
事务会失效的场景:
1、数据库存储引擎不是innodb;
2、@Transactional注解的方法是private非公开会编译报错;
3、在普通方法中调用加了事务的方法不会生效;
4、@Transactional(rollbackFor = Exception.class)设定的异常与方法体中抛出的异常不匹配;
5、多线程:子线程抛异常,主线程捕获不了;
分布式事务:
1、分布式系统中实现事务,它其实是由多个本地事务组合而成。
2、部署在不同结点上的系统通过网络交互来完成协同工作的系统。
比如:充值加积分的业务,用户在充值系统向自己的账户充钱,在积分系统中自己积分相应的增加。充值系统和积分系统是两个不同的系统,一次充值加积分的业务就需要这两个系统协同工作来完成。
CAP理论和BASE理论、2PC、TCC:
CAP理论:
1、Consistency一致性:更新操作执行后用户读到最新的值;
2、Availability可用性:无论这个操作是否更新成功,一定到在用户可接受的时间内返回一个结果,如果一直超时,那可用性太差了;
3、Partition Tolerance分区容忍性:打个比方,这里集群有多台机器,有台机器网络出现了问题,但是这个集群仍然可以正常工作。
一般都能达到CP或者AP。
数据的一致性:
1、强一致性:达到CP,牺牲A可用性,一个服务涉及多个系统的操作,想要用户看到最新的结果势必要牺牲比较长的时间去等待系统处理。mysql都是acid指的是强一致性(原子一致性)。2PC、3PC、TCC是强一致分布式事务。
2、弱一致性:达到AP,牺牲C一致性。比如网上办理业务审核,提交审核会立马告诉你提交成功,但人家根本没告诉你什么时候能审批完,也没告诉你到底会不会被审批通过,这种不确定的等待就很恼火。
3、最终一致性:比如提交退款,提交成功,并告诉你第二天一定会到账,这种确定的等待让人就很信任。mq是最终一致性事务。
参考:https://zhuanlan.zhihu.com/p/183753774
RocketMq实现分布式事务:
参考:https://zhuanlan.zhihu.com/p/329941683
大库存商品秒杀:
参考:https://blog.csdn.net/xinzun/article/details/79457585
30、活锁、死锁
| 类型 | 例子 | 必要条件 | 解决办法 |
|---|---|---|---|
| 死锁 | 迎面而来两个或多个汽车,互不谦让,一直堵着路口,导致交通瘫痪,很粗鲁 | 互斥、竞争占有、不可抢占、循环等待 | 重启应用,或破坏4大条件中一条即可 |
| 活锁 | 两个独木桥上相遇的人,互相谦让让对方先走,很绅士 | 可能自行解开,死锁则不能 | 两者等待一个随机的时间再执行 |
| 饥饿 | 一个年轻人在独木桥这头,对面是一个老人,让他先过桥,没想到后面还有一堆老人,只能一直等他们全部过桥,绅士过头了 | 一个可运行的进程尽管能继续执行,但被调度器无限期地忽视 | 通过先来先服务等资源分配策略来避免 |

参考例子https://blog.csdn.net/ZW547138858/article/details/83269342
参考代码https://blog.csdn.net/weixin_42740530/article/details/105844160
31.公平锁、非公平锁
| 公平锁 | 先等待先获取锁 |
|---|---|
| 非公平锁 | 先等待也不一定先获取锁 |
32.乐观锁、悲观锁|排它锁、共享锁、读锁写锁
| 类型 | 概念 | 例子 | ||
|---|---|---|---|---|
| 乐观锁 | 认为数据一般不会发生冲突,用户提交时再判断,有冲突就返一些错误信息给用户自己处理 | 读多写少 | 给表加一个版本号或时间戳,版本号相等就更新,否则拒绝操作 | 性能差 |
| 悲观锁 | 总认为会发生并发冲突,在整个数据处理过程中,需要将数据锁定 | 写多读少 | 通常依靠数据库提供的锁机制实现,比如mysql的排他锁,select … for update来实现,先上锁然后再处理数据的保守策略 (Synchronized、行锁表锁读锁写锁等) |
安全,效率低 |
| 共享锁 | 读锁 | 可同时读 |
|---|---|---|
| 排它锁 | 写锁 | 不能与其他锁并存 |
mysql中的行级锁是基于索引的,如果sql没有走索引,那将使用表级锁把整张表锁住

参考https://m.php.cn/article/480427.html
参考https://blog.csdn.net/weixin_39900180/article/details/111689465
33.堆、栈
| 类别 | 内存分配 | 大小 | 分配效率 |
|---|---|---|---|
| 堆 | 系统释放回收,可能内存泄漏 | 虚拟空间很灵活 | new分配,慢 |
| 栈 | 编译器自动分配和释放 | win系统2M | 自动分配,快 |
34.get、post
| get | url后带参数以?拼接,用作获取数据 |
|---|---|
| post | 参数无限制,放http请求包中,用作提交数据 |
34.forward、redirect
| forward | 服务器跳转,浏览器地址不变,转发是带着转发前的请求参数。 服务器forward到jsp |
|---|---|
| redirect | 浏览器跳转,浏览器地址变了,是新情求 一个jsp到另一个jsp |
35.hashcode和equals
- equals相同,hashcode一定相同
- equals不相同,hashcode能同/不同
- hashcode相同,equals可能同/不同
- hashcode不相同,equals一定不同
36.cors、jsonp、代理服务器实现跨域问题
- 为什么会跨域?
比如一个请求接口在后台服务器中部署的端口是8080,而前端页面部署的服务器端口是6003,因为浏览器有同源策略,当前端请求到后端时,两者的协议、域名、端口不一致就会导致跨域。(以下是从b站网请求百度网,因为header中Access-Control-Allow-Origin属性没有设置允许跨域)
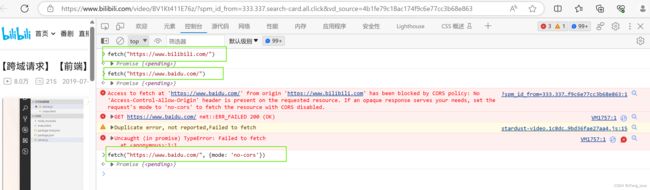
PS:通过href、src方式请求的资源是静态的文件,不涉及到后台数据处理,这种不会发生跨域,ajax动态请求才会有跨域问题。
- 解决方法
1、cors后端实现:
(1)最简单的是加@CrossOrigin注解到请求接口上,但因接口繁多,每个都加不是很适用;
(2)写一个CrossFilter,设置允许哪些源、method、header请求;
(3)实现WebMvcConfigure接口,重写addCrossMapping,设置允许哪些源、method、header请求。
2、代理服务器实现:
(4)vue-cli搭建的Webpack环境,可以直接在config文件中通过配置proxy正向代理(客户端)进行转发;
// vue.config.js/webpack.config.js
// 优点:可以配置多个代理,且可灵活控制请求是否走代理
// 缺点:配置繁琐,发起代理请求时必须加上配置好的前缀
module.exports={
devServer:{
proxy:{
'/api01':{
target:'http://xxx.xxx.xxx:5000', // 跨域的域名
changeOrigin:true, // 是否开启跨域
// 重写请求,根据接口详情,判断是否需要
pathRewrite:{
'^/api01':''
}
},
'/api02':{
target:'http://xxx.xxx.xxx:5001',
changeOrigin:true,
// 重写请求,根据接口详情,判断是否需要
pathRewrite:{
'^/api02':''
}
}
}
}
}
// changeOrigin设置为true时,服务器收到的请求头的host与服务器地址相同
// changeOrigin设置为false时,服务器收到的请求头的host与前端地址相同
PS:在vue.config.js中配置的devServer.proxy只是在开发环境下将请求代理到后端服务器的本地服务,我们把项目打包成dist文件只把我们的组件等资源打包了,并不会将代理服务器给打包,所以项目中的请求路径不完整导致访问不到对应资源,这样就需要用nginx才行,或者是用vite构建前端,可以省去打包步骤,区别参考:https://juejin.cn/post/7018754950498877471,
https://zhuanlan.zhihu.com/p/434462624。
(5)在前端通过配置nginx反向代理服务器(服务端),conf配置文件中配置可以跨域的源即可(以下:前端用nginx做web服务器,端口是8080,然后监听请求地址中是否有/api,如果匹配就转发到带8081端口地址的后台服务器上,就可以实现跨域了)
(备注:代理服务器与服务器之间是非同源,但不存在跨域问题,是因为服务器之间采用的是http请求,而不是ajax技术)

正向代理和反向代理区别:

参考:https://blog.csdn.net/qq_45890970/article/details/123654674,
https://cloud.tencent.com/developer/article/1418457
3、前端实现:
(6)jsonp:利用script标签的src属性不受同源策略限制的特点,但只能解决get请求,需前后端配合,不安全可能会遭受XSS攻击,参考:https://segmentfault.com/a/1190000041946934
37.spring-boot特点
- 约定大于配置
- 默认读取properties/yml文件
- 嵌入式servlet容器,应用无需打开war包
- starters自动依赖与版本控制
- DevTools将文件更改自动部署到服务器并重启
- 自动配置原理
- SpringBootApplicaton
- EnablrAutoConfiguration
- 继承mybatis过程
- 添加mybatis的starter maven依赖
- 在mybatis接口中,添加@Mapper注解
- Application.yml配置数据源
- 核心注解
1. SpringBootApplication启动类注解 - 内置tomcat
- 日志框架
- 热部署
38.cookie、session、token区别
Cookie、session的工作原理
1、用户在浏览器(客户端)请求服务器;
2、服务器拿到这个用户的信息会new一个session和一个cookie,session中存有随机分配的唯一sessionId来区分用户,并将sessionId放入cookie中,再将cookie返回给浏览器;
3、后面这个用户再多次访问服务器时就会一直携带这个cookie,服务器接收到后就会通过携带的sessionId去session库中寻找是哪个用户,以及确定用户是否登陆或具有某种权限。

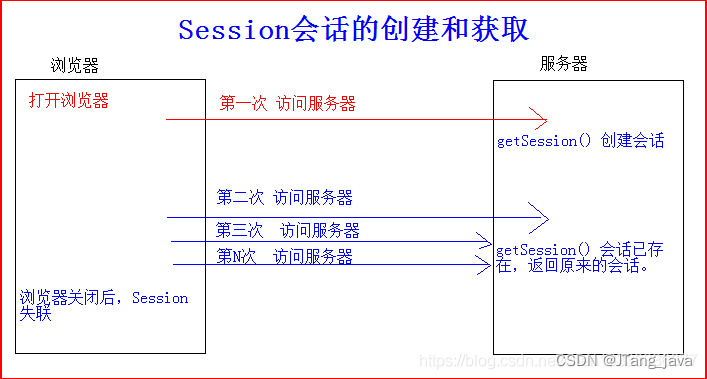
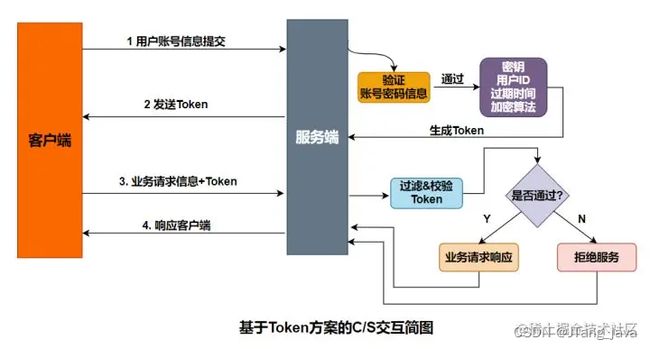
token(令牌)工作原理:
1、客户端将用户名和密码发送给服务端;
2、服务端收到后验证,通过就创建token并发回去;
3、客户端拿到后可保存本地,后面每次请求带上token;
4、服务器再根据相同的加密算法和参数生成Token和发过来的token做对比。所以只需在客户端存储状态信息即可。
最简单的token组成:uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名)
区别对比:
(1)cookie数据存放在客户的浏览器上,session数据放在服务器上
(2)cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session
(3)session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能(缺点)。再比如 A 服务器存储了 Session,就是做了负载均衡后,假如一段时间内 A 的访问量激增,会转发到 B 进行访问,但是 B 服务器并没有存储 A 的 Session,会导致 Session 的失效。如果主要考虑到减轻服务器性能方面,应当使用COOKIE
(4)单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能3K。
(5)所以:将登陆信息等重要信息存放为SESSION;其他信息如果需要保留,可以放在COOKIE中
(6)session的sessionID是放在cookie里,要想功破session的话,第一要功破cookie。功破cookie后,你要得到 sessionID,sessionID是要有人登录,或者启动session_start才会有,你不知道什么时候会有人登录。第二,sessionID是加密的,第二次session_start的时候,前一次的sessionID就没有用了,session过期时sessionid也会失效,想在短时间内功破加了密的 sessionID很难。session是针对某一次通信而言,会话结束session也就随着消失了,而真正的cookie存在于客户端硬盘上的一个文本文件,谁安全很显然了。
(7)Token避免了Session机制带来的海量信息存储问题,也避免了Cookie机制的一些安全性问题,属于典型的时间换空间的思路。在现代移动互联网场景、跨域访问等场景有广泛的用途。参考https://blog.csdn.net/rongwenbin/article/details/51784620,
https://blog.csdn.net/hanziang1996/article/details/78969044,
https://zhuanlan.zhihu.com/p/625995458,
https://blog.csdn.net/chen13333336677/article/details/100939030,
https://juejin.cn/post/7064953803564384263
39.JAVA 中的几种基本数据类型是什么,各自占用多少字节
基本数据类型共8种,引用数据类型:接口(interface)、数组([ ])、类(class)
| 整型byte、short、int、long | 1、2、4 、8个字节 |
|---|---|
| 字符型 char | 2个字节 (0 ~ 65535) |
| 单精度浮点型 float | 4个字节 |
| 双精度浮点型 double | 8个字节 |
| boole | 无规范大小,视jvm情况而定 |
40.sql 优化有哪些,含索引创建
- 尽量避免使用 select *,返回无用的字段会降低效率。
- 尽量避免使用 in 和 not in,会导致数据库引擎放弃索引进行全表扫描。如果是连续数值,可以用 between 代替,如果是子查询,可以用exists代替。
- 尽量避免在字段开头%模糊查询,会导致数据库引擎放弃索引进行全表扫描。优化方式:尽量在字段后面使用模糊查询。
- 尽量避免进行 null 值的判断,会导致数据库引擎放弃索引进行全表扫描。:可以给字段添加默认值 0,对 0 值进行判断
- 创建索引。
- 优化索引(对于删除数据库可以采用逻辑删除,加标记字段,避免索引产生变化)
索引作用:
1、加快查询、更新数据库表中数据,提高系统的性能;
2、可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义;
3、在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
代价:
1、创建索引也会占用数据库的存储空间;
2、创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加;当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。;截图来自韩顺平老师课程


如何创建索引:
1、直接创建索引,例如使用CREATE INDEX 索引名 表名 (字段名)语句或者使用创建索引向导。
2、间接创建索引,例如在表中定义主键约束或者唯一性键约束时,同时也创建了索引。

创建索引原则:
1、最左前缀匹配原则(一直向右匹配直到遇到范围查询就停止匹配)
2、尽量选择区分度高的列作为索引
3、索引列不能参与计算
4、尽量的扩展索引,不要新建索引
5、选择唯一性索引(唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。)
6、为经常需要排序、分组和联合操作的字段建立索引;
7、为常作为查询条件的字段建立索引;
8、 限制索引的数目;
9、尽量使用数据量少的索引;
10、尽量使用前缀来索引;
11、删除不再使用或者很少使用的索引。

修改、删除索引:


41.sql重要语法
截图来自韩顺平老师课程



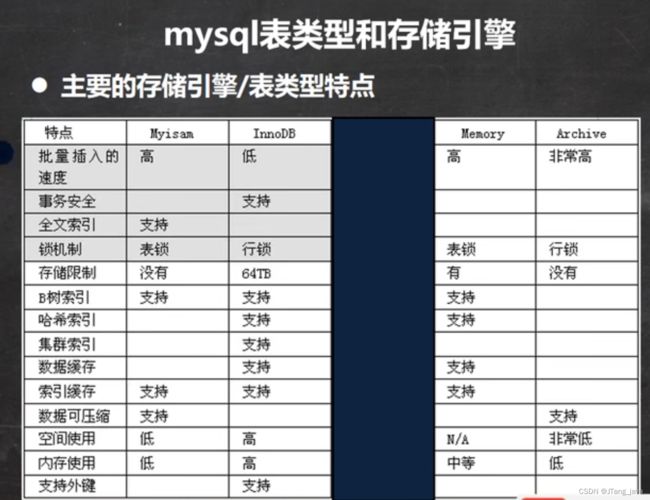
42.MyISAM与InnoDB存储引擎区别
43.视图
视图就是一张虚拟表,数据来自真实的基表
44、DDD领域驱动模型
参考:https://mp.weixin.qq.com/s/jU0awhez7QzN_nKrm4BNwg
45、java拦截器与过滤器使用场景
执行顺序:
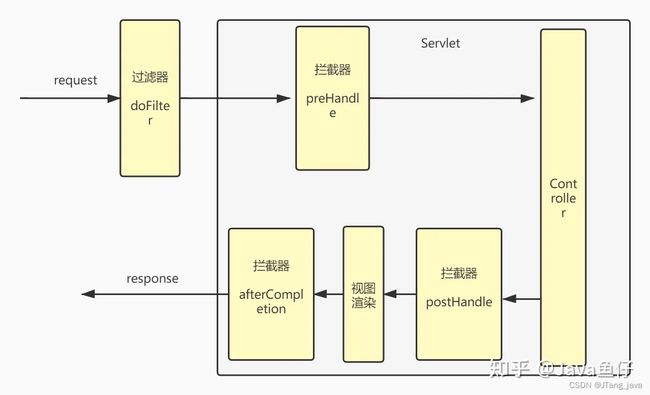
首先当一个请求进入Servlet之前,过滤器的doFilter方法进行过滤,
进入Servlet容器之后,执行Controller方法之前,拦截器的preHandle方法进行拦截,
执行Controller方法之后,视图渲染之前,拦截器的postHandle方法进行拦截,
视图渲染完成之后,执行拦截器的afterCompletion方法,一般是进行资源清理工作。
相同点:
1、拦截器与过滤器都是体现了AOP的思想,对方法实现增强,都可以拦截请求方法。
2、拦截器和过滤器都可以通过Order注解设定执行顺序。
不同点:
1、过滤器属于Servlet级别,拦截器属于Spring级别 Filter是在javax.servlet包中定义的,要依赖于网络容器,因此只能在web项目中使用。
Interceptor是SpringMVC中实现的,归根揭底拦截器是一个Spring组件,由Spring容器进行管理。
2、执行顺序不同,过滤器在前,拦截器在后。
3、过滤器基于函数回调方式实现,拦截器基于Java反射机制实现。
使用场景:
拦截器的应用场景:权限控制,日志打印,参数校验;
过滤器的应用场景:跨域问题解决,编码转换。
参考:https://zhuanlan.zhihu.com/p/408809649
46、接口幂等性
什么是幂等性?
幂等性是指同一个操作无论请求多少次,其结果都相同。
幂等操作实现方式有:
1、操作之前在业务方法进行判断如果执行过了就不再执行。
2、缓存所有请求和处理的结果,已经处理的请求则直接返回结果。
3、在数据库表中加一个状态字段(未处理,已处理),数据操作时判断未处理时再处理。
原文链接:https://blog.csdn.net/ityqing/article/details/102655827
实战场景题
1. 如何实时统计在线用户(在某个页面、视频下)?
单机页面统计在线人数:
- 用Listener实现了一个简单的在线人数实时统计的功能,其主要的原理,就是用来监听session的创建和销毁,以此来实现在线人数的+1/-1;
- 用户每次访问时,没有则创建session,并设置有效时间,有则更新session中的访问时间;当用户主动退出或者一段时间没有交互之后,则认为用户已经离开,session失效;
- 重点就两个类:监听Session创建和销毁的监听器 OnlineUserCountListener;计数服务 UserStatisticService。参考:https://www.yuque.com/itwanger/az7yww/bn619l7kpy57mhbg
集群场景使用redis存储当前在线用户信息,key可以是网页/视频id,value采用hash存储,包括用户id和创建时间等;然后通过定时器来刷新时间,如果用户主动退出或者key的过期时间到了就自动剔除,最后根据网页id/视频id查询下数量返回。
2. 项目中如何实现日志输出?
(1)采用Logback和Log4j日志框架,在配置文件中设置日志级别分开存储、输出的文件位置、输出格式、保留天数、文件大小,异步输出日志设置。代码中日志工厂获取日志对象,构造函数传入当前类,查找日志方便定位LoggerFactory.getLogger(当前类.class),方法体中用log.info记录param和value,再搭建ELK日志采集分析系统,来实现保存操作日志功能;
(2)部署到linux服务器上后,直接去找文件比较麻烦,可使用WebSocket实现实时获取,建立WebSocket连接后创建一个线程任务,每秒读取一次最新的日志文件,第一次只取后面500行,后面取相比上次新增的行,为了在页面上更加方便的阅读日志,通过前端对日志级别单词进行着色等等;大厂都有自己封装好的服务,统一日志收集规则,再通过可视化界面访问日志服务,还可以可以监控、告警,亿万级日志可以考虑先写进kafka消息中间件,作为数据库的缓冲,由消费者分批将日志数据保存到数据库,降低耦合,尽量使日志的操作不影响业务操作。
(3)因为日志文件没有永久保存,可以选择性的记录一些API的日志到数据库,可以用切面实现,GateWay请求时做拦截,获取接口的url、出入参、调用方、调用时长、用户id等,方便快速定位。
3. 完整的项目部署流程?
4. 项目中如何处理定时任务?
场景:每分钟扫描超时支付的订单,每小时清理一次日志文件,每天统计前一天的数据并生成报表,每个月月初的工资单的推送,每年一次的生日提醒等。
任务类型:实时任务、定时任务、corn任务
(1)实时任务,实时执行: 实时的给在线用户算数据,触发者是用户自己(自己手动点),但是算任务的只能同时由一个线程去执行,这就可以用 LTS分布式任务调度框架;
(2)定时任务:像7天自动收货,使用LTS,JobClient.submitJob()提交任务,JobTracker接收并分配任务,TaskTracker执行任务,LTS-Admin管理后台。
(3)Elastic-Job异步任务中间件,application.yml文件中配置;
(4)最简单的注解实现:在启动类加@EnableScheduling注解,@Scheduled(执行时间)加到类或者方法上,开启定时任务,配置好线程池大小,每个任务在线程池中并行,互不影响,微服务集群不适用。
LTS注册中心提供多种实现(Zookeeper,redis等),注册中心进行节点信息暴露,master选举。(Mongo or Mysql)存储任务队列和任务执行日志, netty or mina做底层通信, 并提供多种序列化方式fastjson, hessian2,java等。
ElasticJob-Lite 是依赖ZooKeeper的,如果主服务器挂了,会自动通过 ZooKeeper
的选举机制选举出新的主服务器,因此 ElasticJob-Lite 具有良好的扩展性和可用性。
5. 项目中哪些场景用了MQ消息队列,以及用MQ处理分布式事务?
场景:发货成功发短信通知客户的业务场景,我们可以在发货成功后发送MQ消息到队列,然后去消费mq消息,发送短信。一般两个系统间传递消息就用MQ(请求削峰和系统解耦)。
(1)比如下订单操作,支付成功会创建订单、扣减库存、增加积分、扣减优惠券、发送通知给用户等操作,而这些有可能都分布至多个微服务中,都同步处理的话时间太长了,可以这些不同模块的操作用丢进mq消息队列进行异步处理。因为里面有数据库操作,肯定涉及分布式事务,分布式系统一般考虑的是RocketMq。
(2)根据mq事务强一致性,当我的订单系统正在处理写订单的事务操作前就会发mq半消息到Broker端(中间人),Broker会持续等待订单事务处理成功,如果成功就commit,Broker街道commit指令就执行下一步库存的事务;如果失败就发rollback指令请求退出;Broker如果等了很久没等到指令,就会发超时询问的接口去消息回查,如果重试次数超过指定的次数就将消息转发到死信队列中,等待后续人工补偿,避免卡死队列。当然,如果是强一致性,那就直接rollback咯。
(3)发mq这里肯定要创建一个Producer发送器,代码里就能直接调用send方法发送;还要有一个事务Listener监听器,监听消息回查,然后根据事务日志表,就可以判断订单是否已完成;建立消费端,给他指定topic,以及跳转到那个消费者Listener处理。
(4)像发通知邮件这种非业务强相关的调用第三方服务的操作不需要用事务,也可以就发个lite-job异步任务就行,也不会管它是否会执行成功,反正可以手动重试的。
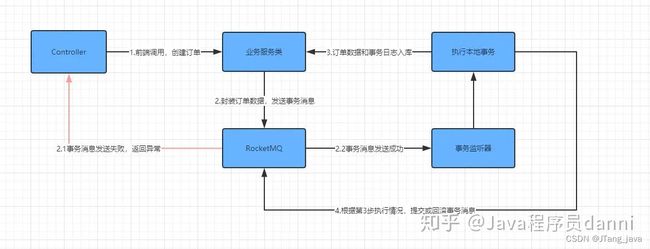
6. 项目中怎么实现文件操作的?
(1)大厂一般有工具类实现上传、下载、更新、添加水印,前端也有封装的文件组件,不需要自己写,下面只说几个比较常见的场景。
(2)配置word文件模版,动态往里面写入数据,然后转化成pdf文档:新建word模版,${***}设置为自动图文集,保存为xml文件导入工程里,读取模版,创建.doc的文件,用put(k,v)模式写入数据即可,最后用封装的工具转成pdf。参考:https://blog.csdn.net/qq_23126581/article/details/125446459
(3)下载excel的模版,批量写入一些数据,导入到web页面再用列表展示出来:异步读取excel文档,循环取出每一列每个单元格的数据,设置好文档的格式为数字格式或字符串格式,取得时候不要取错,或者是直接都按字符串格式取出再做转化;将数据写入集合中,再插入数据库,返回给前端提示导入成功或者失败,再做页面刷新,自动查询出最新内容;如果是失败,会把失败的原因回写到excel文档每一列后面,在页面可以下载这个失败的文档进行查看原因。
(4)用户勾选数据批量导出或者选全部导出:job/mq异步,或者使用easyexcel框架,读写数据很方便,减少oom问题;一般为了避免数据了过大,excel打不开,会设置最大条目数;也可以在页面设置一些条件来控制导出数量;分页查询数据库、分页存sheet多表,添加索引、分组等来优化百万级数据导出的性能。
(5)下载导入模版:一般模板文件都是上传到服务器,产生一个文档id,然后配置到公共平台上,例如大厂用的数据字典,下载的时候再获取出来。
(6)给文档添加水印:有封装好的pdf工具,直接set水印内容、字体、大小、位置,最后保存即可。
7. 项目中有哪些功能可以做全局配置的,或者说把这些功能单独做成微服务?
8. 微服务之间都是怎么治理的,怎么调用对方的接口?
服务治理:
- 服务治理是微服务架构最核心的问题,用于实现各个微服务的自动化注册与发现。在这里选择Eureka/Nacos注册中心。getInstances(服务名)从nacos中获取服务地址,restTemplate调用。
- 主流的注册中心有Eureka、Consul、ZooKeeper和Nacos。
通信方式:
- restTemplate.(url)方式,url配置在配置文件中;
- 通过消息通信,mq;
参考:https://blog.csdn.net/leilei1366615/article/details/108187933
9.用户身份鉴权一般用的什么?
springBoot+redis项目一般采用共享cookie实现SSO单点登录,即一次登录,多处访问。
以及结合soa架构向对外接口实现jwt鉴权,jwt包括头部(Header)、载荷(Payload)和签名(Signature),JWT是一种无状态的身份验证方案,服务器不需要在数据库中存储Token信息。由于Token包含所有必要的信息,服务器可以独立验证Token的有效性,从而避免了查询数据库的开销,适用于分布式系统和微服务架构。另外,为了防止Token被篡改,建议使用HTTPS协议传输Token,以确保安全性。
实现JWT鉴权的步骤:
- 生成Token:在用户登录认证通过后,服务器生成JWT Token,包括头部、载荷和签名。
- 发送Token:服务器将生成的Token返回给客户端,通常作为HTTP响应的一部分,可以放在响应的Header字段或Body中。
- 存储Token:客户端收到Token后,可以将其存储在本地,通常使用浏览器的本地存储(如LocalStorage或SessionStorage)。
- 发送Token:在后续的请求中,客户端需要将Token发送给服务器,通常将Token放在HTTP请求的Header字段中,使用Authorization字段。
- 验证Token:服务器在接收到请求后,从Header中获取Token,并进行验证。
服务器验证token:
- 检查Token的格式是否正确。
- 检查Token的签名是否有效,验证签名可以使用服务器保存的密钥或共享的密钥。
- 检查Token的有效期是否过期。
- 检查Token的载荷中的其他信息,例如用户角色、权限等
- 授权访问:如果Token验证通过,服务器根据Token中的信息,判断用户是否有权限访问请求的资源。
总结
本文简单介绍了java重点知识点的总结,有描述错误的地方请指出,感谢观看。