音视频录制+RTMP直播推拉流
音视频录制:
1,录音 通过条件编译识别pc或者mac:
//条件编译技术 识别pc或者mac
#ifdef Q_OS_WIN
#define FMT_NAME "dshow"
#define DEVICE_NAME "audio=麦克风 (Realtek Audio)"
#else
#define FMT_NAME "avfoundation"
#define DEVICE_NAME ":0"
#endif 根据short_name寻找自己的采集图像设备,short_name可以是硬件名称或编码格式h264、aac等。以下是简单的录音代码。
本文福利, 免费领取C++音视频学习资料包、技术视频/代码,内容包括(音视频开发,面试题,FFmpeg ,webRTC ,rtmp ,hls ,rtsp ,ffplay ,编解码,推拉流,srs)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓
const AVInputFormat *fmt = av_find_input_format(const char *short_name)
//创建格式化I/O上下文并初始化;
//Open an input stream and read the header.
avformat_open_input(&ctx, DEVICE_NAME,fmt,nullptr);
//从上下文中读取包
av_read_frame(ctx, &pkt);
//写数据到本地 //原始数据raw-data:pcm。
file.write((const char *)pkt.data, pkt.size);
2,视频录制
如果进行摄像头直播。window可以尝试使用"gdigrab"桌面直播,mac切换"v:a"中v的index参数即可,例如直播教学分享。以下是个简单的代码
设备名
#define DEVICE_NAME "video=HD camera"
#define DEVICE_NAME ":0"
//打开输入设备
av_find_input_format(FMT_NAME);
//设置视频格式输出参数:
AVDictionary *options = nullptr;
//ffmpeg命令行: -s 640x480 -pix_format yuyv422 -r 15
av_dict_set(&options,"video_size", "640x480",0);
av_dict_set(&options,"pixel_format", "yuyv422",0);
av_dict_set(&options,"framerate", "15",0);
//创建格式化I/O上下文并初始化(同上)
avformat_open_input(&ctx, DEVICE_NAME, fmt, &options);
//获取一帧的大小
av_image_buffer_size(AVPixelFormat, image_width, image_height, 1);
AVPacket *pkt = av_packet_alloc();
while(##interrupt-signal##) {
//从格式化I/O上下文中读取AVPacket包数据。
int ret = av_read_frame(ctx, pkt);
if(ret == 0) {
file.write(...);
}
}
3,h264视频编解码
(1)编码过程:
//1,根据指定的AVCodecID或编码器name寻找编码器
const AVCodec *avcodec_find_encoder(enum AVCodecID id)
const AVCodec *avcodec_find_encoder_by_name("libx264");
//2,libfdk_acc对数据的要求:采样格式必须是16位整数。
//检查输入数据的采样格式。详情参考官方Demo代码
check_pixel_fmt(codec,in.pixelFmt)
//3,创建编码器上下文,并设置视频格式的三要素:pixel_format,width,height
AVCodecContext *codecCtx = avcodec_alloc_context3(codec);
//4,打开编码器上下文
avcodec_open2(codecCtx, codec, nullptr);
//5创建AVFrame和AVPacket
//5.1需设置三要素以及时间基等参数,并创建frame->data缓冲区
AVFrame *frame = avv_frame_alloc();
av_image_alloc(frame->data, frame->linesize, width, height, pixel_format, 1);
//5.2创建AVPacket
AVPacket *pkt = av_packet_alloc();
//6 保证文件可读或可写后,读取输入文件的到frame缓冲区,对于linesize的设置需注意
while (input_file.read(frame.data[0], frame->linesize[0]) > 0) {
//解码数据
发送frame到编码器上下文
if(avcodec_send_frame(codecCtx, frame) > 0) {
while(1) {
int readEncodedDataResult = avcodec_receive_packet(codecCtx, packet);
if(readEncodedDataResult == AVERROR(EAGAIN) || readEncodedDataResult == AVERROR_EOF) {
return 0;
}
...
output_file.write(pkt.data, pkt.size);
//释放pkt内部的资源,保证最后一次读完后,也能释放
av_packet_unref(pkt);
}
}
}
//刷新缓冲区
encode(codecCtx, nullptr, pkt, output_file)
//释放资源
if(frame){
av_freep(&frame->datap[0]);
av_free_frame(&frame);
}
av_packet_free(&pkt);
avcodec_free_context(&codecCtx);(2)解码过程: 相对于编码过程,多了一个AVCodecParserContext的解析器的概念。因为对于压缩后的数据,在解包前并不能准确知道解压后的数据大小。而解析器的存在,可以把压缩的格式包进行切割送到AVCodecContext解码上下文中。
//创建data缓冲区
int data_size = 4096;
char inDataArray[data_size+64];
char *indata = inDataArray;
//解码器
const AVCodec *decodec = avcodec_find_decoder_by_name("h264");
//初始化解析器上下文
AVCodecPraserContext *praserCtx = av_praser_init(decodec->id);
//创建解码器上下文
AVCodecContext *decodeCtx = avcodec_alloc_context3(decodec);
AVPacket *packet = av_packet_alloc();
AVFrame *frame = av_frame_alloc();
//打开解码器
avcodec_open2(decodeCtx, decodec, nullptr);
while (!feof(infile)) {
int inlen = infile.read(indata, data_size);
//解析一次读的数据,一次不一定能读完,需要多次解析,所以进行循环
while(inLen > 0) {
av_parser_parser2(parserCtx, decodecCtx,
&packet.data, &packet.size,
indata, inlen,
AV_NOPTS_VALUE, AV_NOPTS_VALUE, 0);
//因为parserCtx不是每次解析到数据就发送包,析到一定量后,才发给解码器上下文。所以这里需要计算indata的指针
//解码: 发送解码数据到解码器上下文
avcodec_send_packet(decodeCtx, packet);
while(1) {
avcodec_receive_frame(decodecCtx, frame);
//...
//将解码后的planar数据写入文件
//frame.linesizep[0]表示Y平面的一行的长度, height表示有多少行Y平面
outfile.write(frame.data[0], frame.linesize[0]*decodeCtx.height);
//U和V分量的行数是Y行数的一半,一行的UV分量长度也是Y的一半,所以用(frame.linesize[0]*decodeCtx.height)>> 2 也一样
outfile.write(frame.data[0], frame.linesize[1] * decodeCtx.height >> 1);
outfile.write(frame.data[0], frame.linesize[1] * decodeCtx.height >> 1);
}
}
}
4,对iOS设备的摄像头操作,大致列举几个AVFoundation的API:
//1,创建捕获会话,相当于建立一个会话处理器,连接输入设备端(麦克风或者摄像头采集音频或视频流)和输出端(将采集且已经封装好的流)。
AVCaptureSession *session = [[AVCaptureSession alloc] init];
/*2,根据MediaType获取可用的设备列表,进而可获取到指定的视频设备*v_Device,例如前置/后置摄像头。 type: AVMediaTypeAudio...音频设备a_Device*/
[AVCaptureDevice devicesWithMediaType:AVMediaTypeVideo]
//3,创建视频输入对象AVCaptureInput that provides an interface for capturing media from an AVCaptureDevice: 提供了设备用于捕获媒体流的接口。Device: audioDevice =》音频输入对象
[AVCaptureDeviceInput deviceInputWithDevice:v_Device error:nil]
//4,添加输入输出对象到会话中
[session addInput: ##音视频输入对象##]
//5,AVCaptureOutput:AVCaptureOutput that can be used to process uncompressed or compressed samples from the video/audio being captured. 翻译:就是AVCaptureOutput用于处理未压缩的或已经压缩的被捕获的样本。
//创建音视频输出设备
AVCaptureAudioDataOutput *a_output = [[AVCaptureAudioDataOutput alloc] init];
AVCaptureVideoDataOutput *v_output = [[AVCaptureVideoDataOutput alloc] init];
//设置代理和执行队列(sampleBufferCallbackQueue)
[videoOutput setSampleBufferDelegate:self queue:##dispatch_queue_t##];
//将音视频输出对象添加到会话中
[session addOutput:##音视频输出对象##]
//6获取视频输入输出连接,在AVCaptureAudioDataOutputSampleBufferDelegate代理的回调方法中,可以区分当前输出的流数据是否是音频连接。
AVCaptureConnection *a_connect = [v_output connectionWithMediaType:AVMediaTypeAudio];
//7,添加视频预览图层
AVCaptureVideoPreviewLayer *preLayer = [AVCaptureVideoPreviewLayer layerWithSession:_session];
//8,启动会话
[session startRunning];音视频同步:
1,对于上述音视频的录制,在真正的应用开发中,音频需要涉及到重采样,视频需要进行颜色空间重写,都是为了得到指定format/pixel_format的文件。
1.1 音频重采样关键API展示:
SwrContext *swrCtx = swr_alloc(void);
av_opt_set_int(swrCtx, ...);
av_opt_set_sample_fmt(swrCtx, ...);
//包含上述两个功能
swr_alloc_set_opts2(swrCtx, ...);
swr_init(swrCtx);
swr_convert(swrCtx, ...);1.2 视频重采样关键API展示:
SwsContext *swsCtx = sws_getContext(...);
sws_scale(swsCtx, ...)1.3 ffmpeg音视频录制推流代码逻辑:
//**0**: 音视频录制逻辑略
//初始化网络库
avformat_nerwork_init();
//推流的源文件
const char *inUrl = "Q:\\rtmp\\V_Char222.flv";
//推流地址
const char *outUrl = "rtmp://192.168.1.111:1935/appliction/temp";
//这是我实现的推流demo。代码会挂在我的git库上,地址会同步
//**I**:
//输出格式化I/O上下文
AVFormatContext *out_FmtCtx = nullptr;
///本地路径或直播推流路径
const char *outFileName = m_filePath.toStdString().c_str();
QString fileStr = m_filePath.toLower();
if (fileStr.endsWith(".flv")||fileStr.startsWith("rtmp://")){
avformat_alloc_output_context2(&out_FmtCtx, nullptr, "flv", outFileName);
} else {
avformat_alloc_output_context2(&out_FmtCtx, nullptr, nullptr, outFileName);
}
//**II**:
//创建两路流,一路a_Stream 一路v_Stream;并且保留对应streamIndex。
avformat_new_stream(out_fmtCtx, nullptr);
//videoStream另需设置时间基:一般都是帧率的倒数
videoStream->time_base = AVRational{1, fps};
//创建视频编码器上下文v_codecCtx和音频编码器上下文a_codecCtx,并分别配置相应参数
//根据上述设置的codec_id寻找视频编码器v_codec和音频编码器a_codec
//对于视频需要设置sps/pps
*_codecCtx->flags |= AV_CODEC_FLAG_GLOBAL_HEADER;
//ps: 以下“*_” 的 “*”做通配符,代表a或v。临时起意的。
//通过avcodec_open2(*_codecCtx, *_codec, nullptr)打开编码器上下文,API注释为:Initialize the AVCodecContext to use the given AVCodec。
//复制上下文参数到流中
avcodec_parameters_from_context(*_stream)
avio_open(&out_fmtCtx->pb, outFileName, AVIO_FLAG_WRITE);
avformat_write_header(out_fmtCtx, nullptr);
//**III**:
//创建两个队列:音频队列+视频队列; a_formatCtx 针对音频输入的格式化I/O上下文;v_formatCtx针对视频输入的格式化I/O上下文。
// 设置队列中能够装载的帧的最大数量:FRAME_COUNT = 30;
int a_nbSamples = a_formatCtx->frame_size;
//一帧图片的大小
int videoOut_frameSize = av_image_buffer_size(...);
//音频:
//创建音频队列
AVAudioFifo* aStream_fifoBuf = av_audio_fifo_alloc(a_formatCtx->sample_fmt, a_format->channles, FRAME_COUNT * a_nbSamples);
//视频:
//创建一帧输出空间
vOut_frameBuffer = av_malloc(videoOut_frameSize);
//创建出队列的用于接收视频的AVFrame
AVFrame *vOut_Frame = av_frame_alloc();
//通过av_image_fill_arrays(...)初始化vOut_Frame->data指针指向vOut_frameBuffer
//创建视频队列
AVFifoBuffer* vStream_fifoBuf = av_fifo_alloc_array(FRAME_COUNT, videoOut_frameSize);
//**IV**:
//开启两个子线程分别进行视频录制和音频录制,eg:
std::thread videoRecord(##FUNC_NAME##, par);
//定义一个videoRecord线程对象,可以通过videoRecord.detach()将子线程从主线程分离出来,此时主线程对子线程不会有控制权,子线程执行完后,自己会释放掉资源。
//桌面录制: !!!!!!!!!!!!!!!!!!!!!!!!
// v_fmtCtx: 视频录入的格式化I/O上下文
//创建AVPacket用于存储从格式化上下中读取的rgba包数据
//创建两个AVFrame,后文有。
//一个存储AVPacket解码后的帧,一个存储颜色空间转换缩放后的帧(需要通过av_image_fillarray绑定buffer缓存空间)
//都需要进行资源释放,时机不同。
while(recordState != Stopped) {
//线程阻塞check:
std::condition_variable event_notPause; //用户暂停事件关联的
std::condition_variable v_buf_notFull; //视频-帧消费者
std::condition_variable v_buf_notEmpty; //视频-帧生产者
unique_lock v_event_lock(event_pause_mutex);
//查看源码:这句意思是return YES 往下走,NO是阻塞当前线程,也就是暂停状态阻塞
//一旦阻塞,在另一处调用notify可唤醒当前线程
event_notPause.wait(v_event_lock, [this]{
return recordState != RecordState::Paused;
});
//本质:从屏幕设备中读帧,屏幕录制经过A/D模数转换得到的是RGBA
av_read_frame(v_fmtCtx, (AVPacket *)pkt);
//将包发送给解码上下文
avcodec_send_packet(v_decodecCtx, pkt);
//从解码上下文拿到解码后的帧
avcodec_receive_frame(v_decodecCtx, v_Frame);
//pts的设置
// v_frame中得到的像素格式不一定是目标格式YUV420p,需要颜色空间转换、缩放操作(略)产生新的帧v_scaleNewFrame
sws_scale(swsCtx, v_frame..to ... v_scaleNewFrame);
//线程操作check 视频队列是否有可够的存帧 空间
{
// v_buf_mutex 针对视频队列加的互斥锁
unique_lock v_buf_lock(v_buf_mutex);
v_buf_notFull.wait(v_buf_lock, [this]{
//判断视频队列中是否 有 足够容纳一帧大小的空间
return av_fifo_space(vStream_fifoBuf) >= videoOut_frameSize;
});
}
int y_space_size = 定义录制的video的宽高积
//三种写方式(有两种是最新的API,是AVFifo的)
av_fifo_generic_write(vStream_fifoBuf, v_scaleNewFrame->data[0], y_space_size, NULL);
av_fifo_write(vStream_fifoBuf, v_scaleNewFrame->data[1], y_space_size >> 2);
av_fifo_write_from_cb(vStream_fifoBuf, nullptr, v_scaleNewFrame->data[1], y_space_size >> 2);
//此时表明vStream_fifoBuf视频队列 一定不为空。
//notify_noe : 只唤醒一个线程,不存在锁竞争;
// notify_all唤醒所有阻塞的线程,存在锁竞争,只有一个线程能够获得锁,其余未获得锁的线程仍会阻塞
v_buf_notEmpty.notify_noe();
}
//冲刷视频解码器上下文缓存空间,原理看此方法注释
av_codec_send_packet(v_decodecCtx, nullptr);
//音频录制:!!!!!!!!!!!!!!!!!!!!!!!!
//创建一个AVPacket用于接收音频输入格式化I/O上下文输出的音频包
//创建两个AVFrame帧,一个用于音频解码上下文输出的帧,一个用于重采样的帧swr_newFrame(此帧需要绑定buffer空间:自定义或者ffmpeg-api)
//通过av_rescale_rnd公式计算对应的输出的样本数
while(recordState != Stopped) {
//检查录制事件是否有暂停操作
if isPasued {
unique_lock event_lock(event_pause_mutex);
event_notPause.wait(event_lock, [this]{
return recordState != Paused;
});
}
//通过av_read_frame从音频输入格式化I/O上下文中读pkt,
//通过avcodec_send_packet将pkt发送到音频解码上下文
//通过avcodec_receive_frame从音频解码上下文读帧,累加pts
//再次通过av_rescale_rnd公式进一步考虑重采样中输入sample与输出sample中产生的延迟(swr_get_delay),计算一帧对应的样本数。当样本数大于之前的样本数时,需要建立新的AVFrame帧buffer空间接收重采样后的音频帧数据(这里的帧就是swr_newFrame)。
//然后通过swr_convert进行重采样,这里会返回重采样后真正的样本数。
std::condition_variable a_buf_notFull; //队列不满,作为消费者,触发生成队列元素的操作
std::condition_vatiable a_buf_notEmpty; //队列不空,作为生产者,出发消费队列的操作
std::mutex a_buf_mutex; //针对音频队列的互斥锁
//check 音频队列是否满 & 线程阻塞
{
unique_lock lock(a_buf_mutex);
a_buf_notFull.wait(lock, [this]{
av_audio_fifo_space(aStream_fifoBuf) >= swr_newFrame.nb_samples;
});
}
//写入swr_newFrame到队列中。写入成功则返回的值总是和swr_newFrame.nb_samples相等
av_audio_fifo_write(aStream_fifoBuf, swr_newFrame,data, swr_newFrame.nb_samples);
//唤醒消费的操作
a_buf_notEmpty.notify_one();
}
//冲刷缓冲空间:上下文空间 重采样空间,基本是把上面的while内逻辑来一遍。
av_codec_send_packet(aDecodeCtx, nullptr);
**IV:** 音视频共享队列中读取数据
/*建立两个线程分别操作:
std::unique_lock为锁管理模板类,是对通用mutex的封装。
std::unique_lock对象以独占所有权的方式(unique owership)管理mutex对象的上锁和解锁操作。
即在unique_lock对象的声明周期内,它所管理的锁对象会一直保持上锁状态;
而unique_lock的生命周期结束之后,它所管理的锁对象会被解锁。
lock_guard与unique_lock不同点: 可以利用unique.unlock()来解锁。
*/
//defer_lock不获得互斥的所有权,也就是使用v_buf_mutex创建unique_lock对象,但是没有调用lock。
//v_buf_mutex:针对视频队列的互斥锁
unique_lock v_buf_out_lk(v_buf_mutex,std::defer_lock);
unique_lock a_buf_out_lk(a_buf_mutex, std::defer_lock);
std::lock(v_buf_mutex, a_buf_mutex);
while(1) {
//检测视频队列或音频队列是否有音或视频帧
//比较音视频pts; ts_a = 帧.pts ;
//ret: 1表示ts_a在前;-1反之; 0表示same position 同一个点
av_compare_ts(int64_t ts_a, AVRational tb_a, int64_t ts_b, AVRational tb_b);
===============> 如果audio帧在前,需要多解码一帧视频
{
unique_lock lock(v_buf_mutex)
v_buf_notEmpty.(lock, [this]{
//videoOut_frameSize 一帧图片的大小
return av_fifo_size(vStream_fifoBuf) >= videoOut_frameSize;
});
}
//从队列中拿出一帧大小videoOut_frameSize的数据放到vOut_frameBuffer缓存空间,
av_fifo_generic_read(vStream_fifoBuf, vOut_frameBuffer, videoOut_frameSize, nullptr);
//此时确定视频队列是不满的,触发生产者操作
v_buf_notFull.notify_one();
//向视频编码器上下文中添加刚刚读的视频帧(vOut_Frame->data指向的是vOut_frameBuffer)
avcodec_send_frame(v_codecCtx,vOut_Frame);
//编码器上下文读取压缩后的包, 并设置 pkt.streamIndex
avcodec_receive_packet(v_codecCtx, (AVPacket *)pkt);
//转换时间基,将pts 从基于编码层的timebase 转成 基于复用层(封装层)的time_base
// v_codecCtx->time_base: 编码层时间基,fps帧率的倒数
av_packet_rescale_ts(pkt, v_codecCtx->time_base, out_FmtCtx.stream[v_index]->time_base);
//交叉写入
av_interleaved_write_frame(out_FmtCtx, pkt);
===============> 如果video帧在前,需要多解码一帧音频
//创建一帧AVFrame * a_outFrame
//初始化参数并且通过分配data-buf(av_frame_get_buffer快捷方式)
//nbSamples: 一个音频帧单个声道上的样本的数量
//return: 实际从音频队列中读取的样本数量
av_audio_fifo_read(aStream_fifoBuf, a_outFrame->data, nbSamples);
//消费一帧后,队列不满,可以通知*音频生产者*继续生产
a_buf_notFull.notify_one();
//向音频编码器发送刚从音频队列中读取的帧
avcodec_send_frame(a_codecCtx, a_outFrame);
//从音频编码器读取压缩后的包packet; 创建一个AVPacket pkt并初始化。
avcodec_receive_packet(a_codecCtx, &pkt);
//转换时间基
av_packet_rescale_ts(&pkt, a_codecCtx->time_base, out_FmtCtx.streams[a_index]->time_base);
//写入交织帧
av_interleaved_write_frame(out_FmtCtx, &pkt);
}
//冲刷缓冲区,【*_codecCtx】表示a_codecCtx或v_codecCtx
// 使用avcodec_send_frame(## *_codecCtx ##, nullptr);
// fflush逻辑和【帧读取到写入交织帧】基本一致
//写流尾到输出的媒体流文件中
av_write_trailer(out_FmtCtx);
//释放资源的操作略 其中不要忘记关闭AVIOContext
...
avio_close(out_FmtCtx->pb);
...
RTMP推流(附API源码):使用librtmp静态库。
关于编译,需要openssl,自己编译过程是个challenge。librtmp默认情况下是支持FLV而无法推送H264的,这里推荐srs-rtmp库可支持,也可以先解析h264封装成rtmp包,通过RTMP_SendPacket函数实现发送。关于QTCreator的FFmpeg推流代码会挂在git上,这里就不赘言了。以下会演示基于iOS设备的使用RTMP的推流代码演示。
//1:创建rtmp对象并初始化
RTMP* rtmp = RTMP_Alloc();
RTMP_Init(rtmp);
//2:设置URL,
/*
* I: 通过RTMP_ParseURL函数解析出rtmp.link对象,
* eg: protocol协议、hostname主机名、端口号port等
* II: SocksSetup函数初始化rtmp->Link下的sock信息
*/
RTMP_SetupURL(_rtmp, "rtmp://192.168.1.111:1935/appliction/temp");
//3:设置可写,即推流,必须在连接前使用。是publish策略而非play策略
//源码:r->Link.protocol |= RTMP_FEATURE_WRITE;
RTMP_EnableWrite(rtmp);
//4:连接服务器
/* 内部优先使用SOCKS(sockshost + socksport)连接,否则使用hostname+port的方式直接连接;
* 在RTMP_Connect0函数内部,基于AF_INET, SOCK_STREAM, TCP建立socket,并尝试建立连接。
* 在RTMP_Connect1函数内部,进行TLS连接,以及在handshaked握手成功后,进行RTMP连接,接着调用 *SendConnectPacket => RTMP_SendPacket
*/
RTMP_Connect(rtmp, NULL)
//5: 连接流
/* 函数内部有while循环,
* RTMP_IsConnected 判断sb_sock的连接状态
* 通过RTMP_ReadPacket读packet header or boay等操作
* 有通过RTMP_ClientPacket函数不同类型的包进行操作。
*/
RTMP_ConnectStream(rtmp,0);
//6: 推流flv
- cutFlvData2ChunkSizePushServer:(NSData *)flvData {
NSUInteger fileTotalLength = flvData.length;
NSUInteger lengthOfDidRead = 0;
NSUInteger chunkSize = 10 * 4096;
while (lengthOfDidRead < fileTotalLength) {
NSUInteger lengthOfUnreadData = chunkSize;
if(fileTotalLength - lengthOfDidRead < chunkSize){
lengthOfUnreadData = fileTotalLength - lengthOfDidRead;
}
NSData *chunkData = [NSData dataWithBytes:flvData.bytes length:chunkSize];
lengthOfDidRead += chunkSize;
@synchronized (self) {
if(RTMP_IsConnected(self.rtmp)) {
//查看源码发现此方法调用RTMPPacket_Alloc函数开辟rtmp包的缓冲空间
//然后调用RTMP_SendPacket发送rtmp_pkt包
int ret = RTMP_Write(**self**.rtmp, chunkData.bytes, (int)chunkData.length);
if (ret > 0){
NSLog(@"write success");
}
}
}
}
}
//7: 关闭和释放连接
RTMP_Close(rtmp);
RTMP_Free(rtmp);
rtmp = nil;RTMP拉流:对于推流和拉流的过程,本人通过FFMpeg推流+nginx服务器(配置rtmp)+librtmp完整地进行了整个过程。ijkplayer...
//RTMP: alloc -> init -> SetupURL -> Connect -> ConnectStream
//设置缓冲时长
RTMP_SetBufferMS(rtmp, 3600*10);
//设置直播标识
rtmp->Link.lFlags = RTMP_LF_LIVE;
NSUInterge BUF_SIZE = 1024 * 1024 * 100;
char *buf = malloc(BUF_SIZE);
NSUInterge reallyReadSize = 0;
//拉流
while ((reallyReadSize = RTMP_Read(_rtmp, buf, BUF_SIZE)) > 0) {
NSData *playingData = [NSData dataWithBytes:(void *)buf length:BUF_SIZE];
}
RTMP原理解析+wireshark抓包
RTMP协议是应用层协议,通常是靠TCP来保证信息传输的可靠性的。在TCP三次握手建立完成后,RTMP协议还要client和server通过RTMP规则的握手来建立传输层链接之上的RTMP-Connection,然后此连接上传输信息,eg:SetChunkSize...。
RTMP协议会对数据做一层格式化包装,此时的数据称为RTMP Message。而在真正发送时,发送端会把Message划分为n个带有MessageID的Chunk。接收端会根据Chunk中包含的data的长度、messageid和message的长度把这n个Chunk还原成完整的Message。
===> flv文件格式:Flv由“Flv header” 和 “Flv Body”组成。Boby由一系列的Tag组成,每个Tag又有一个pre TagSize字段,标记着前面一个Tag的大小。Flv Body由一个tag组成,每个tag都有一个preTagSize字段,标记前一个Tag大小。Tag由三种类型:Audio Tag、Video Tag、script Tag(Metadata Tag);每个tag由Tag Header和Tag Data组成,对不同类型的Tag,TagHeader格式是相同的,TagBody格式就不一样了。一般一个flv文件由一个头信息,一个script Tag以及若干个video tag和audio tag组成。

===> h264数据结构: SODB(String Of Data Bits):数据比特串 是编码后的原始数据。 RBSP(Raw Byte Sequence Payload):原始字节序列载荷,是在原始编码数据后面添加了结尾比特,一个bit“1”和若干个“0”用于字节对齐。 ESBP(EncapSulated Byte Sequence Payload):扩展字节序列载荷:NALU的起始码为0x00 00 01(3个字节)或0x00 00 00 01(4个字节),在SPS、PPS和Access Unit的第一个NALU使用4字节起始码,其余都是3字节起始码。 在RBSP基础上添加了仿校验字节0x03,为了避免NALU主体中可能存在与起始码相冲突的字节码,在编码时,每遇到两个字节连续为0,就插入一个字节0x03,解码时进行0x03的脱壳操作。 H264将系统框架分为了两个层面:视频编码层(video coding layer:VCL)和 网络抽象层(Network Abstraction Layer, NAL)。 VCL层是对核心算法引擎、块、宏块、以及片的语法级别的定义,负责有效表示视频数据的内容,最终输出编码完的数据SODB。NAL层定义slice片级以上的语法级别,负责以恰当的方式格式化数据并提供头信息,以保证数据适合各种信道和存储介质上的传输。NAL将SODB打包成RBSP然后加上NAL头组成一个NALU单元。 实际视频网络数据传输过程中,H264数据结构是以VAL为基本单元进行传输的,传输数据结构组成【NALU Header】+ 【RBSP】。NALU头是用来标识后的RBSP是什么类型的数据,同时记录RBSP数据是否被其他帧参考以及网络传输是否有错误。
一个视频图像编码后的数据叫做一帧,一帧由n个片slice(n>0)组成,一个片由n个宏块组成,一个宏块由16x16的YUV数据组成。宏块是H264编码的基本单位。
关于宏块...差值预测...I帧内预测/空域压缩...P帧B帧间编码预测/时域压缩...GOP...变换->量化->熵编码...
===> wireshark抓包展示rtmp连接过程:client向server发送C0、C1、C2个Chunk,server会向client发送S0、S1、S2三个Chunk。client收到S1后才能向server发送C2;



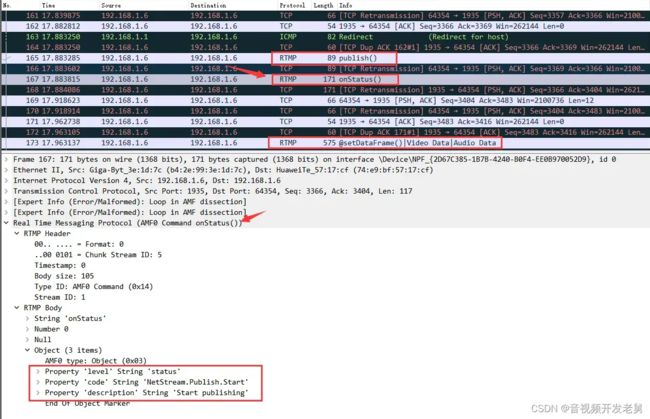
ps: wireshark抓本机包配置,在window上需要开启系统管理员身份,进行router配置。
领域拓展: nginx
nginx配置文件由三部分组成: 1,全局块:从配置开始到event块之间的内容,主要设置一些影响nginx服务器整体运行。 worker_processes power; //power值越大,可以支持的并发处理量也越多。 2,events块: worker_connections cnt_counts; //cnt_counts表示支持的最大连接数。 3,http块:...
简述功能:
1,动静分离;静态数据部署本地直接可拿到,而动态数据配置在tomcat上,再进行一次nginx到tomcat的转发请求。配置location 可以实现请求资源的动静分离。
2,反向代理;是正向代理,代表客户端向服务端拿数据;反向大致可以理解为我们不能直接向服务器拿数据,而是需要一个中介来向服务器拿到数据。这个中介就是nginx的存在,代理服务器进行一些操作。
3,负载均衡;有多种实现方式:(1),轮询 one-by-one的方式;(2)hash的方式,等于一个请求相当于指定了一个处理请求的服务器。(3)根据响应时间的快慢,woker进程抢占请求。
nginx中RTMP配置代码:
rtmp {
server {
listen 1935; //端口号
chunk_size 4000;
application live {
live on;
hls on;
#m3u8以及ts文件存储路径;
hls_path html/hls;
#每一个ts的时长
hls_fragment 5s;
}
}
}流媒体技术拓展(简):
RTSP(和RTMP一样是应用层协议;是对称协议,c和s都可以发送和应答请求,所有操作是两端的消息应答机制完成的,交互流程如下图)、 RTP和RTCP(默认采用UDP作为传输协议也可TCP,连续端口(奇偶分配),rtp传输音视频等数据,rtcp传输控制信息(流量控制、拥塞控制、数据包顺序等))、 HLS(HTTP Live Stream, m3u8文件(控制播放)、ts切片(es层->pes(加时间戳pts、dts等信息)->ts))、多码流自适应,http协议可跨防火墙) 、WebRTC(看前文)、HTTP-FLV(将音视频数据封装成FLV(flash video简称,流媒体封装格式,具体数据格式看上文),然后通过HTTP协议传输给客户端)。当前rtmp的推流延迟时效最低。
本文福利, 免费领取C++音视频学习资料包、技术视频/代码,内容包括(音视频开发,面试题,FFmpeg ,webRTC ,rtmp ,hls ,rtsp ,ffplay ,编解码,推拉流,srs)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓