讲座回顾|2021/4/7|青源美团|CVPR 2021 预讲 · 美团专场,覆盖实例分割,图像分割,表情识别,特征选择和对齐...
讲座回顾|美团青源视觉2021/4/7讲座
- 1、魏晓林,美团视觉智能中心负责人
- 2、论文:End-to-End Video Instance Segmentation with Transformers
- 3、论文:Feature Decomposition and Reconstruction Learning for Effective Facial Expression Recognition
- 4、论文:Rethinking BiSeNet For Real-time Semantic Segmentation
- 5、论文:Embedded Discriminative Attention Mechanism for Weakly Supervised Semantic Segmentation
- 6、论文:Partial Feature Selection and Alignment for Multi-Source Domain Adaptation
1、魏晓林,美团视觉智能中心负责人
魏晓林,美团视觉智能中心负责人。获美国德克萨斯A&M大学博士学位,拥有30多项国际专利。曾任Google总部高级工程师,是推动Google 3D Maps从零到一发布的核心研发人员。曾在美国硅谷创立视觉技术公司Virtroid,研发了行业领先的环境理解和三维重建系统,被Magic Leap收购。
美团在人工智能的储备很强,公司会有该方面的幸福感。
美团视觉领域 线上搜索、推荐、安全风控、金融、安全识别、地图
线上线下连接紧密,无人配送、无人车机、无人零售、无人仓储,需要自动化、需要视觉技术
UGC\PGC数据的处理,如何有机展现在客户面前。如何把100亿图片变成几张展现给用户
无人车–在无人配送方面,大规模落地还需要较长的时间,需要积累人才不断迭代
通过无人车买菜达到了1W5单数
多模态学习、可解释性、对抗学习等等都有人专门跟进,前沿研究。
2、论文:End-to-End Video Instance Segmentation with Transformers
讲者 2:王钰晴

报告摘要:本文是第一个将Transformers应用于视频分割领域的方法。视频实例分割指的是同时对视频中感兴趣的物体进行分类,分割和跟踪的任务。现有的方法通常设计复杂的流程来解决此问题。本文提出了一种基于Transformers的视频实例分割新框架VisTR,该框架将视频实例分割任务视为直接端到端的并行序列解码和预测的问题。给定一个含有多帧图像的视频作为输入,VisTR直接按顺序输出视频中每个实例的掩码序列。该方法的核心是一种新的实例序列匹配和分割的策略,该策略在整个序列级别上对实例进行监督和分割。VisTR将实例分割和跟踪统一到了相似度学习的框架下,从而大大简化了流程。在没有任何trick的情况下,VisTR在所有使用单一模型的方法中获得了最佳效果,并且在YouTube-VIS数据集上实现了最快的速度。
相关工作:MaskTrack R-CNN基础上更新,增加了跟踪分支来提取实例特征
MaskProp 提出了


需要一个对多帧建模的模型。实现一个模型,能否将两个任务统一到一个框架下
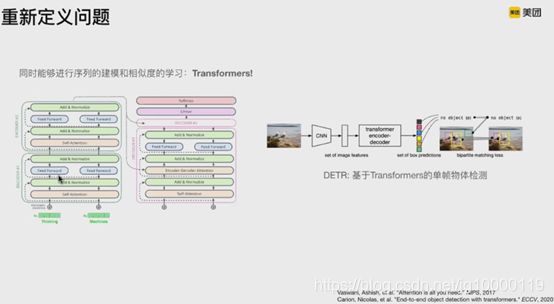
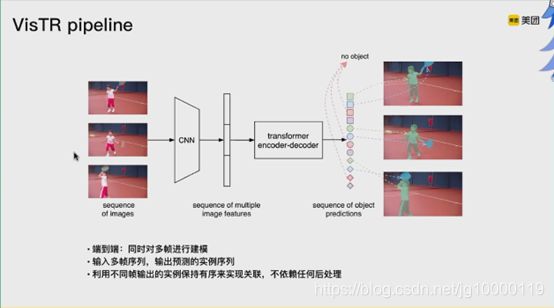
左边表示输入多帧图像序列,右边为输出实例序列。
CNN进行单帧特征提取,变成图像特征序列,在持续维度上,变成多个图像特征序列,进入trans建模,输出实例序列。
多帧输入输出是有序的,对单帧来说,预测不同实例在原始状态下无序的,因此需要后处理。
后面强制输出的颜色顺序是一致的,令其不需要后处理

首先,针对每一帧图像,CNN的backbone进行特征提取。原始空间信息编码,特征序列输入到trans中。
decoder做预测的实例特征序列。
做目标检测监督,按照位置来监督,拍出来找不到ground tures的信息,先找最近ground trues作为监督。

损失函数的匹配和监督都是序列级别的。

length指的是帧数
有序无序时间顺序进行对比,有序比无序要结果更好

360个query,结果是33.3
不同帧关于同一个instance的信息可以共享,不同的query不能共享。


第一行,两个实例遮挡
2,相对位置变化
3,同类临近物体
4,不同姿态下情形
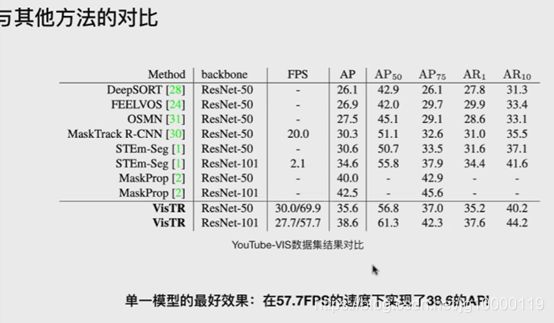
Youtube VIS数据集下的对比
利用监督来实现强制多帧中的instance顺序一致
3、论文:Feature Decomposition and Reconstruction Learning for Effective Facial Expression Recognition
讲者 3:阮德莲

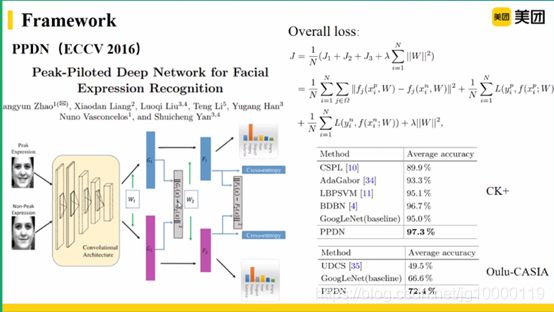
报告摘要:考虑到不同类别的表情之间存在着相似性,本文认为人脸表情信息由不同表情之间的共享信息与每个表情的特定信息组成,提出了一种基于特征解构与重构学习的人脸表情识别方法。具体地,首先使用特征分解网络将基本特征分解为一系列能够感知面部动作的潜在特征,这些潜在特征有效地建模了表情中的共享信息。然后,特征重构网络分别对这一系列潜在特征向量进行特征内部和特征之间的相关性建模,从而学习表情的特有信息。实验结果表明该方法在三个室内数据集(包括 CK+、 MMI 和 Oulu¬CASIA)和两个室外数据集(包括 RAF¬DB 和 SFEW)上都有优越的性能表现。
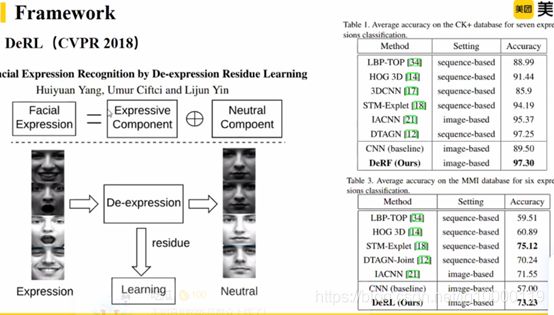
提出,人脸表情信息包含表情部分和中性人(年龄、性别都是普遍的)图像。
借助对抗网络技术,做出生成器。

大型人脸表情受到遮挡、模糊性的问题。
在训练模型过程中抑制不确定性。
首先是self-attention 来计算权重,令不确定性权重低,不确定性高的把其分组,使低权值group更低权重,relabeling–差大于某个阈值,改ID,没过就不改label
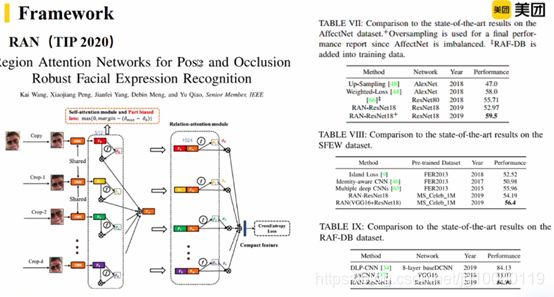
跟上一篇文章同一批作者,解决pose和occlusion的问题
把表情化为不同的区域,确定区域特征的权值,相加得到全体的特征。
对之前局部特征进行微调,像加在一起得到comeatropy less来计算。

中间共享分支,下面是干扰分支。
干扰分支去除性别、年龄、人种等信息。
特征可以很好关注在和表情相关的区域。
去表情干扰因素,如何识别对表情因素有用的信息,怎样对弱强度信息表情的学习。

三个group,分别相同样子但是不同表情。
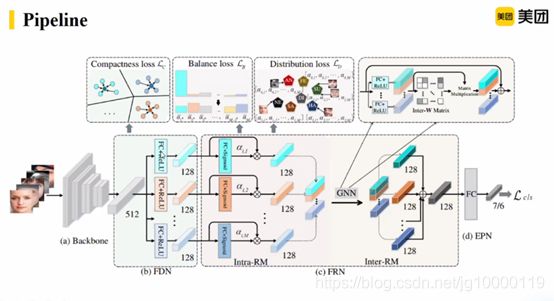
贡献:提出特征结构与程度学习的方法来建模表情相似性和差异性的方法。
重点在特征分解网络、特征重构网络


特征重构网络。得到M个潜在特征,对于不同表情也是共享的。要鉴别表情差异性,就需要对其重构。
用FC和seg的层来计算权重
对权重向量加权来得到特征重要性
会发现,对所有输入图像,第一个潜在特征激活值最大的,后面的几乎忽略。这个不是期待的方向。
用一个balanceloss来限制权重的学习。
对整个batch特征把权值分在不同潜在特征上面,
对于同一个表情不同输入图像的权值应该是相似的。为了消除影响,对每个表情都学习权值分布到中心的距离。

表情会与表情action相关。比如动嘴和动眼和吃惊相关。

对特征相关性计算相关性矩阵,m个特征得到m*m矩阵大小。
计算第一个和第二个之间的关系,计算第一个和第二个的距离+激活函数约束到0~1之间。
再更新潜在特征,计算所有与潜在特征相连的潜在特征的加强权和。得到F^
得到

overloss就是最后用来计算表情的特征。

不同损失函数参数对模型准确率的影响,当loss权值为0,效果会下降,
在λ值达到XX时效果最好

潜在特征太少时候,无法很好学习。太多的时候,会学到有关的,也会学到无用的。数量在9的时候效果最好。
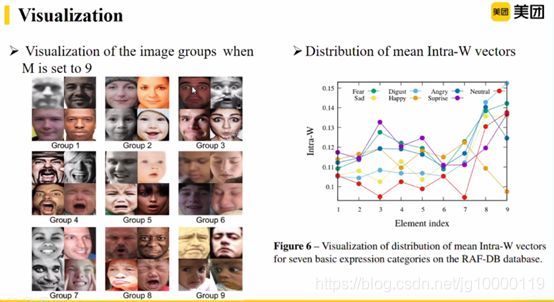
潜在特征是什么样子的,展示一些图像。
9个group。8是皱眉,9是眉毛下坠。
与表情相关的 feature action
学习到的权值分布,红色是中性表情,相对较低
紫色是suprise,3最高
Feature action重要性更大的权值会大一些

表情特征2D可视化,baseline存在表情相似性边界难以区分,FDRL可以比较好的分开。
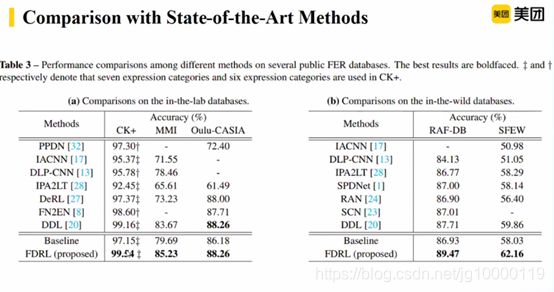
目前效果是最好的

对于提取人类表情特征关键在于:特征分解网络有效建模不同表情相似性,在此基础上对表情学习各自有用的,得到更显著表情特征
后续工作:特征分解是无监督的,后续加入空间之类的信息。在分解过程中,加入两步分解,在得到基础特征前,把模块分为上中下三个模块,最后潜在特征的总和,因为引入空间信息,应该可更有效学习feature action。
特征重构过程中,对局部特征建模,并未考虑全局特征,后续加入
在其他视觉领域,类别之间相似性高,用到其他视觉领域上去。
不确定性用self-attention的机制,让他自己去计算不确定性,自动降低权值
特征分解和特征重构网络是否直接相连?是直接相连,分解之后直接输入到重构网络中。
4、论文:Rethinking BiSeNet For Real-time Semantic Segmentation
讲者 4:范铭源

报告摘要:本文从减少深度模型的结构性冗余的角度重新思考了经典的快速图像分割方法BiSeNet,从而对基础网络结构和解码器部分同时进行改进。在基础网络部分,提出了一种高效的短时密集连接网络,在不降低性能的情况下,大幅度提升推理速度。在解码器部分,通过使用细节引导模块加强浅层特征来代替细节分支,进一步减少了网络的结构性冗余。该模型在快速图像分割领域取得了领先水平,在相同性能下,速度比当前最好方法快45%以上。
实施语义分割的文章


语义分割:目的,赋予像素级别标签。

从经典的BiSeNET出发,双塔模型,希望将图像语义信息和空间信息分开做提取,空间信息用了三层浅网络
两个问题:空间信息提取,没有显示引导。endocer到底充不充分。分类任务banckbone不一定适合分割任务,可能存在结构性冗余。
从分割原理出发,设计了轻量级backbone。把网络浅层特征来学习encoder

通过设计短时密集链接模块设计短时密集链接网络
设计细节引导模块,更好利用空间信息,而且不产生额外时间消耗
在三个数据集渠道最好结果

快速分割要求去除结构性冗余,分割网络关注大的感受野和 浅层
输入输出是固定的M、N
11将为输入大小一半,33提供更丰富的感受野信息
倒数第一fusion不做降维
b加了两个stride,保证整体网络一致性
通过不停1/2chanel的降维,减少结构性冗余
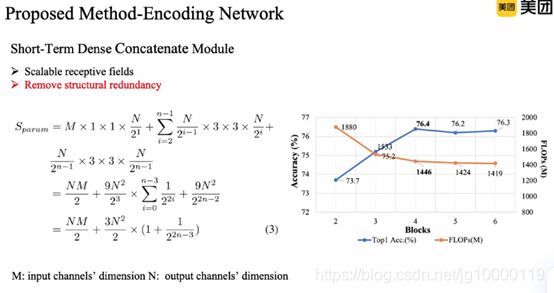
参数量只与输入与输出相关,随block增多,减少
Block=4得到最好的性能。
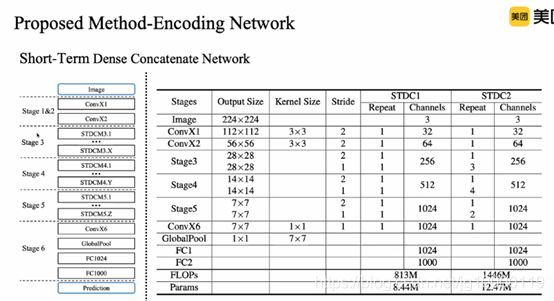
模块堆叠进行网络设计
6,stdc1关注速度,stdc2关注精度,速度也不慢
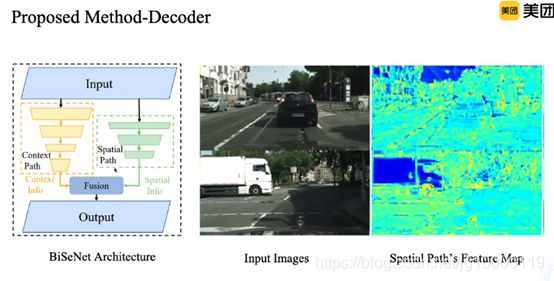
SP提取空间信息特征,确实包括边缘、角点特征
缺点:自发学习,没有引导性约束,到底有没有充分表达。
额外分支有着额外的时间消耗

左边蓝色,模型推理框架,沿用CP分支,对stage3进行细节引导训练。
浅绿色只参与训练不参与模型推理,不造成时间损耗。
拉普拉斯卷积
得到边缘焦点信息的ground truth
Stage3网络浅层通过detail head进行降维,

Detail loss和dice loss一起训练,通过浅层特征得到更丰富的细节信息
b是细节分支。
加了细节引导后,浅层特征不只保留了语义信息,还保留了一些空间信息

用backbone直接替换主干,替换后对比,还是比专为分类的主干更好。
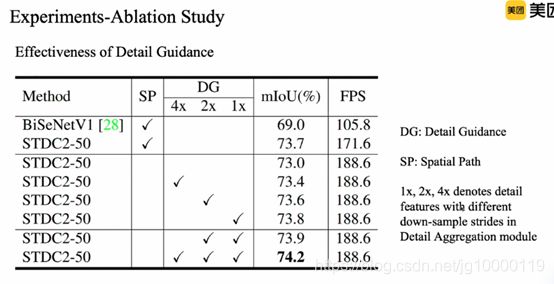
1、同样spatial分支下,主干比BiSeNET精度速度更好
2、加spitial path 速度会明显下降
3、detail guidance 细节引导模块

配置
imagenet:随机梯度下降、。。、。。、。。
精度评测方式: top-1 精度
速度测速方法
对比分割专用主干和轻量级主干。STDC1速度最快,STDC2很高的精度还保持高得FPS

cityscapes是很有说服力的数据集。
对比最近的所有方法,之前的改进型方法,我们的方法比较领先。STDC1-seg50达到250FPS,得到了最快。精度更高,速度更快
Sege75达到了非实时语义性能,还达到了接近100FPS
处在最右上角位置。方法在速度精度取得最好结果

带角标d带我们的细节引导模块、
加了之后又更多空间信息,把更小物体预测更好。

本着去除结构化冗余,在多数据取得好结果
backbone在更多方面的应用
网络对于空间边界的信息能不能应用在更多的任务上面
5、论文:Embedded Discriminative Attention Mechanism for Weakly Supervised Semantic Segmentation
讲者 5:吴桐
北理工研二

报告摘要:使用图像级标注的弱监督语义分割通常将分类网络的类别激活图(CAM)视为语义分割的伪标签。然而这些激活图通常仅仅突显局部的具有区分性的区域,而不是语义分割所要求的物体的完整区域。为了生成更加完整的类别激活图,我们提出了Embedded Discriminative Attention Mechanism (EDAM) 将类别激活图的生成直接融合进了分类网络中。具体来说,我们使用了一个Discriminative Activation (DA) 层来生成类别独立的掩膜,并通过这些掩膜提取出各个类别独立的特征。随后我们通过Collaborative Multi-Attention (CMA)机制,聚合图片内和图片间的上下文信息。我们的方法在PASCAL VOC 2012的测试集上取得了70.6%的mIoU,达到了最优性能。

弱监督语义分割
弱监督语义分割目标:右上角,需要图像级标签,比全监督像素级简单许多
弱监督seg最主流:图像及别标签

目前弱监督语义分割通用流程
给出图像及标签和图片,传统方法训练分类网络,CAM生成类别激活图,对像素点上去argmax,得到点对应类别,生成为标签

类别激活图的方法,PLG

得到初始化伪标签,需要对其细化。
找到对应的显著性图片,最为前景背景线索,进行细化


CAM结果往往只会显示最具有区分性的部分,导致CAM关注度集中在脸部,导致前景不完整,无法全覆盖物体

![]()
针对这情况,扩大CAM关注区,通过多尺度多特征生成多张CAM,通过叠加方式扩大CAM范围【1】
通过生成子类别的方式,KNN聚类,大类中分出子类,为了分出子类,关注细节区域,增强CAM效果【2】
叠加方式引入特征,细分子类方式又不够直接
想出了新的方法

EDAM–作者方法
三个大部分
1、backbone
选择resnet38
2、负责生成
3、负责聚合图片内和图之间的信息,提高准确度
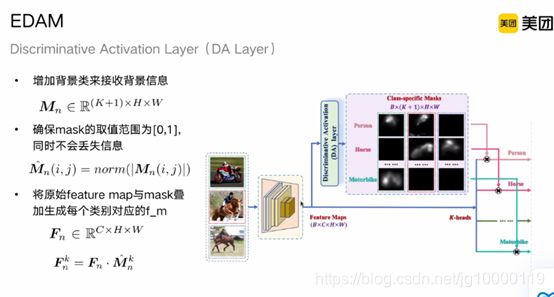
K是前景类别数量,+1是为了增加一个背景类,增加背景信息
对mask的定义:代表像素点所属各个类别的概率(0~1),需要做一个归一化,L2
norm
fm和mask做乘操作,得到Fk

同一个批次中所有Fk过同一个attention
变为2D序列,符合ateention输入要求
BHW,与同一批次进行信息交换,还会和B-1HW的信息交互,不同图片进行交互
损失:b张图k类别的二分类损失进行平均

作左图目标特点是沙发,右边是壁画,导致图4和图2完全不相关,为了抑制这种情况,引入α和β

椅子不见,但是噪声区域变为前景
如果简单相乘,导致背景凸显,前景被去除
引入阈值β,点的最高置信度大于β,会让他从背景中重新凸显

如果CAM中,点最高置信度小于α,会被归为背景。
经过阈值卡控,得到最后的结果,准确度提高,噪声减少了很多
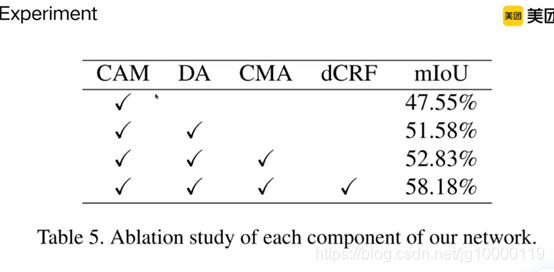
各种模块相容性试验,加入DA,CMA,DCRF的不同mIoU(语义分割指标)

DA layer效果的可视化
1行原始图片,2行CAM,3行加入DA layer,

加入阈值的效果,阿尔法、贝塔

方法的比较,ECCV2020最高67.8,我们做到了70.6
相同分割网络下全监督准确率在76左右,进一度缩小弱监督全监督的差距

验证集上的效果图。
d是自己的结果,在完整性和细节方面都更好。
DAlayer如何对应不同类生成mask,将feature直接放到 dalayer中,直接预测概率,会经过L2 lom,会被限制到(0~1)之间,那么每个类别的概率都知道了,返程到了fearture map上,得到不同类别特征图。
将一个批次同一类feature map放一起过一个map tach。不同类别聚合上下文没意义,同一个类别聚合比较有意义,更有利于准确率。
DCF是dance CAF
方法已经在github,文章还没发
6、论文:Partial Feature Selection and Alignment for Multi-Source Domain Adaptation
讲者 6:张明

电子科技大学
报告摘要:现有的多源域适应设置和方法常常忽略了两个方面的“部分性”,一是目标域的类别标签空间不完全包含于源域,二是源域特征中只有部分是与目标域高度相关的。我们提出了一个更加一般的多源域适应研究主题,名为多源部分域适应(MSPDA),同时提出一个部分特征选择和对齐框架网络(PFSA)能够处理传统MSDA问题和新提出的MSPDA问题。框架利用源域和目标域特征之间的相似性对源域特征进行选择,得到源域特征中与目标域更相关的部分。然后通过多种对齐损失实现了类别级别上的对齐。我们的方法在MSDA和MSPDA两个场景中的分类问题上都取得了领先。

无监督预测预适应
N个源域和多个目标域,点不同颜色是不同源域的样本

存在部分性的缺失,多源域的目标类别空间可能是不一致的
体现了部分性
只有部分类别是所有源域共享的
前面的文章只考虑了整体的特征对齐,实际上存在域上差异,导致性能下降

提出多源部分域适应,
三个不同设置
1、多个源域类别空间一致,而目标域是多源域的子集
2、各个源域类别空间不一致,目标域目标类别包含在多源域类别集合的交集
3、各个源域类别空间不一致,目标域包含在多源域的并集之中。(最一般情况,作为研究对象)

贡献:
1、特征选择和xx网络
2、源域目标域特征相似新,从源域中选出更相关的部分
3、设置对其约束,来对选择特征对齐

3个子模块
灰色:CNN特征提取网络
蓝色:特征选择网络
橘色:特征对齐模块

根据源域特征和目标域特征相似性作为依据
用L1作为相似性度量,输入全链接简单网络,将网络得到的结果作为特征选择
1指维度独特征进行选择,0不选择
相当于过滤器


得到被选择后的特征,进一步提高对齐关系,选用了
![]()
高阶矩距离
通过最远化距离来对齐
高阶矩的距离、对特征选择L2的正则化
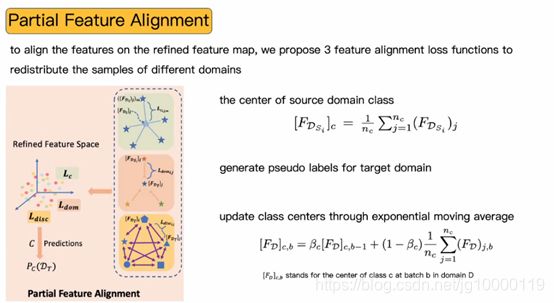
特征对齐模块
各个类别的中心,由属于这个类别的样本特征均值确立,通过分类器对目标样本生成为标签,得到熵,对置信度高的来获得类别中心
各个域类别中心更新,通过栋梁更新获得

1、希望每个域上属于这个类别的样本靠近所处的类别中心,最小化类内距离,聚类更紧凑
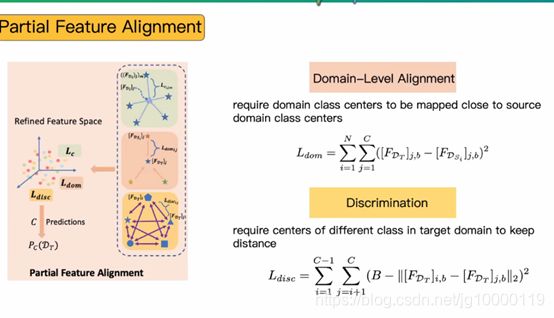
2、希望目标域类别中心更靠近源域,能够和源域样本分布靠近
3、各个类别中心距离要最大化
通过三个约束实现特征对齐有利于后续

最小化类别话交叉熵的值,最大化xx
特征提取器,缩小分类器值的差异
固定住特征提取器,训练分类器,预测值差异尽量的大,希望分类器从两个视角对样本进行分类,尽管两个视角
固定两个分类器,训练特征提取器,希望分类器预测值尽量靠近
希望特征提取器在不同视角结果尽量靠近,提高鲁棒性

在多源域适应和xx上进行试验
其中一个域作为目标域,其他作为源域
singel-best,单源域适应,把最好结果作为最终结果
SC,多源域组合为大源域,单元域适应
MS,
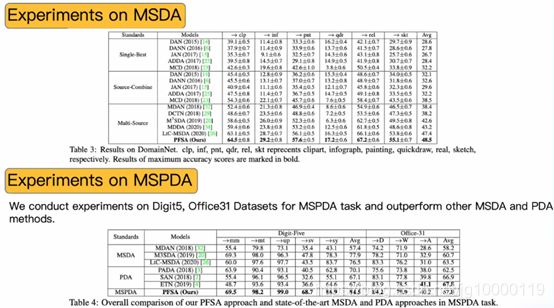
MSDA和PDA进行对比
我们的MSPDA取得领先效果

交融实验,去掉关键模块,对人任务性能的影响
去掉特征选择和特征对齐,精确度大为下降,证明模块有用
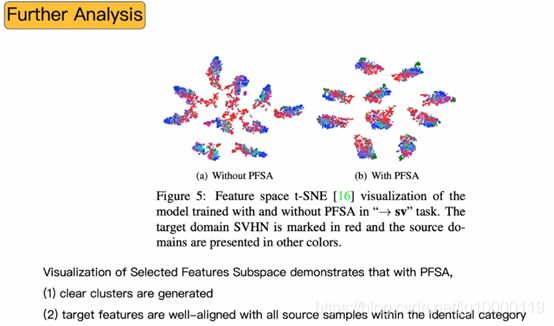
0-9数字的分布情况
红色为目标域点(样本)
在没有的情况下分散杂乱,聚类效果差
应用后分类很明确

特征选择和特征对齐框架
选择通过L1距离度量,相似性选择出更相关部分
对齐上选择对其损失来约束
文章是听讲座时的随手笔记,很多地方可能不正确还请指正。
见到比自己厉害很多的人的讲座很荣幸,收获很大