Java入门编码规范之小白崛起
IT小生浅谈阿里编码规范、spring boot后端注意事项及前端编码规范。
JAVA编码规范摘要
无规矩不成方圆 无规范不能协作
Java代码规范能够给业界带来一个标准,促使整体行业代码规范水平得到提高,最终能够帮助企业和开发者提升代码质量和降低代码故障率。作为Java初级开发者,更应该注重编码规范的重要性,养成良好的习惯。
基于阿里巴巴Java开发手册–简述安全规约、Mysql数据库

一、安全规约
“安全生产,责任重于泰山。”这句话同样适用于软件生产,本节主要描述编程中需要注意的比较基础的安全准则。
1.1阿里巴巴手册中强制规约(掌握)
- 【强制】隶属于用户个人的页面或者功能必须进行权限控制校验。
说明:防止没再做水平权限校验就可随意访问 、修改、删除别人的数据,比如查看他人的私信内窑、修改他人的订单。 - 【强制】 用户敏感数据禁止直接展示,必须对展式数据进行脱敏。
说明:个人手机号码会显示为 15****9119隐藏中间 4位,防止个人隐私泄露。 - 【强制】 用户输入的 SQL 参数严格使用参数绑定或者METADATA 字段值限定,防止 SQL 注入,禁止字符串拼接SQL 访问数据库。
- 【强制】 用户请求传入的任何参数必须做有效性验证。
说明:忽略参数校验可能导致如下情况:
1)page size 过大导致内存溢出
2)恶意 order by 导致数据库慢查询
3)任意重走向
4)SQL 注入
5)皮序列化注入
6)正则输入源串拒绝服务 ReDoS - 【强制】禁止向 HTML 页面输出未经安全过滤或未正确转义的用户数据。
- 【强制】 表单、AJAX 提交必须执行 CSRF 安全过滤。
说明: CSRF(Cross-Site Request Forgery )跨站请求伪造是一类常见编程漏洞。对于存在 CSRF 漏洞的应用或网站,攻击者可以事先构造好 URL ,一旦受害者用户访问,后台便可在用户不知情的情况下对数据库中的用户参数进行相应的修改。 - 【强制】 在使用平台资源时,譬如短信、邮件、电话、下单、支付,必须实现正确的防重放限制,如数量限制、疲劳度控、验证码校验,避免被滥刷、资损。
说明:如注册时发送验证码到手机,如果没再限制次数和频率,那么可以利用此功能骚扰到真他用户,并造成短信平台资源浪费。
1.2编码中推荐使用(了解)
- 【推荐】发贴、评论、发送即时消息等用户生成内容的场景必须实现防刷、文本内容违禁词过滤等风控策略。
二、MySQL数据库
底层数据库的规范有助于减少软件实现的复杂度,降低沟通成本,本节主要说明建表规范索引优化准则以及ORM 层的处理约定。
2.1 建表规约及说明
- 【强制】表达是与否概念的字段,必须使用 is_xxx 方式命名,数据类型是 unsigned、tinyint ( 1表示是,0表示否)。
说明: 任何字段如果为非负数,则必须是 unsigned。
正例 :表达逻辑删除的字段名 is_deleted, 1表示删除,0表示未删除。
2.【强制】表名、字段名必须使用小写字母或数字禁止出现数字开头,禁止两个下画线中间出现数字,数据库字段名修改代价很大,因为无法进行预发布所以字段名称需要慎重考虑。
说明: MySQL在Windows下不区分大小写,但在 Linux 下默认区分大小写,因此,数据库名、表名、字段名都不允许出现任何大写字母,避免节外生枝。 - 【强制】表名不使用复数名词。
说明:表名应该仅仅表示表里面的实体内容,不应该表示实体数量,对应于 DO 类名也是单数形式,符合
表达习惯。 - 【强制】禁用保留字,如 desc、range、match、delayed 等,请参考 MySQL 官方保留字。
- 【强制】主键索引名为 pk_字段名;唯一索引名为 uk_字段名;普通索引名则为 idx_字段名。
说明:pk_ 即 primary key;uk_ 即 unique key;idx_ 即 index 的简称。 - 【强制】小数类型为 decimal,禁止使用 float 和 double。
说明:在存储的时候,float 和 double 都存在精度损失的问题,很可能在比较值的时候,得到不正确的结果。如果存储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数并分开存储。 - 【强制】如果存储的字符串长度几乎相等,使用 char 定长字符串类型。
- 【强制】varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长度大于此值,定义字段类型为 text,独立出来一张表,用主键来对应,避免影响其它字段索引效率。
- 【强制】表必备三字段:id, create_time,update_time。
说明:其中 id 必为主键,类型为 bigint unsigned、单表时自增、步长为 1。create_time, update_time的类型均为 datetime 类型,前者现在时表示主动式创建,后者过去分词表示被动式更新。
2.2 索引规约
- 【强制】业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。
说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的;另外,即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。 - 【强制】超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时,
保证被关联的字段需要有索引。
说明:即使双表 join 也要注意表索引、SQL 性能。 - 【强制】在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据
实际文本区分度决定索引长度。
说明:索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为 20 的索引,区分度会高达 90%
以上,可以使用 count(distinct left(列名, 索引长度))/count(*)的区分度来确定。 - 【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
2.3 SQL语句优化使用
- 【强制】不要使用 count(列名)或 count(常量)来替代 count(),count()是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。 - 【强制】count(distinct col) 计算该列除 NULL 之外的不重复行数,注意 count(distinct col1, col2) 如果其中一列全为 NULL,那么即使另一列有不同的值,也返回为 0。
- 【强制】当某一列的值全是 NULL 时,count(col)的返回结果为 0,但 sum(col)的返回结果为NULL,因此使用 sum()时需注意 NPE 问题。
正例:可以使用如下方式来避免 sum 的 NPE 问题:SELECT IFNULL(SUM(column), 0) FROM table; - 【强制】使用 ISNULL()来判断是否为 NULL 值。
说明:NULL 与任何值的直接比较都为 NULL。 1) NULL<>NULL 的返回结果是 NULL,而不是 false。 2) NULL=NULL 的返回结果是 NULL,而不是 true。 3) NULL<>1 的返回结果是 NULL,而不是 true。
反例:在 SQL 语句中,如果在 null 前换行,影响可读性。select * from table where column1 is null and column3 is not null; 而ISNULL(column)是一个整体,简洁易懂。从性能数据上分析,ISNULL(column)执行效率更快一些。 - 【强制】代码中写分页查询逻辑时,若 count 为 0 应直接返回,避免执行后面的分页语句。
- 【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
说明:(概念解释)学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。 - 【强制】禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。
- 【强制】数据订正(特别是删除或修改记录操作)时,要先 select,避免出现误删除,确认无误才能执行更新语句。
- 【强制】对于数据库中表记录的查询和变更,只要涉及多个表,都需要在列名前加表的别名(或表名)进行限定。
说明:对多表进行查询记录、更新记录、删除记录时,如果对操作列没有限定表的别名(或表名),并且操作列在多个表中存在时,就会抛异常。
正例:select t1.name from table_first as t1 , table_second as t2 where t1.id=t2.id;
反例:在某业务中,由于多表关联查询语句没有加表的别名(或表名)的限制,正常运行两年后,最近在某个表中增加一个同名字段,在预发布环境做数据库变更后,线上查询语句出现出1052 异常:Column ‘name’ in field list is ambiguous。
spring boot后端编码注意事项
一、 ResTful API 风格
1.1 Restful Api有三个主要的特性:
1)是基于Http协议的,是无状态的
2)是以资源为导向的
3)人性化的,返回体内部包含相关必要的指导和链接
1.2 HTTP方法
GET(SELECT):从服务器取出资源(一项或多项)。
POST(CREATE):在服务器新建一个资源。
PUT(UPDATE):在服务器更新全部资源(客户端提供改变后的完整资源)。
PATCH(UPDATE):在服务器更新部分资源(客户端提供改变的属性)。
DELETE(DELETE):从服务器删除资源。
1.3 响应状态码
100~199:信息状态码,代表请求已被接受,需要继续处理。
200~299:成功状态码,代表请求已成功被服务器接收、理解、并接受。
300~399:重定向状态码,代表需要客户端采取进一步的操作才能完成请求。
400~499:客户端错误状态码,代表了客户端看起来可能发生了错误,妨碍了服务器的处理。
500~599:服务器错误状态码,代表了服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器意识到以当前的软硬件资源无法完成对请求的处理。
特别注意几个常用的状态码:
200 请求已成功,请求所希望的响应头或数据体将随此响应返回。
400 1、语义有误,当前请求无法被服务器理解。除非进行修改,否则客户端不应该重复提交这个请求;2、请求参数有误。
500 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器的程序码出错时出现。
二、常见的文本、邮件、不能为空等,spring boot自带注解可以快速实现:@Valid注解和BindingResult验证请求参数的合法性并处理校验结果。(此块内容在开发中应用较为广泛,认真学习)
例子:创建用户时,接口参数中用户名不能为空。@NotBlank(message = “用户名不能为空”)
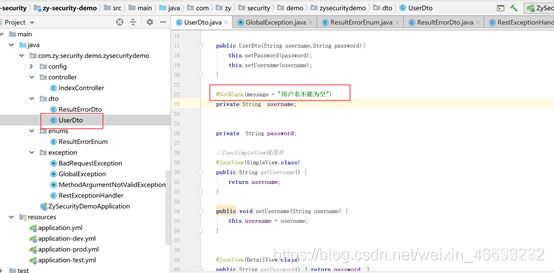
提示:在请求方法的字段上加上@valid注解时,以上的注解将生效。如果请求接口的参数无法通过校验,将返回状态码为400(此处认真理解学习)

使用postman测试结果如下:

常见的注解如下图:

已经能够按照RestFulApi的方式返回400的错误信息,但是返回的异常信息不是很友好(有很多乱七八糟的字段,与我们自定义的400错误信息json结构不一致,那么前端接受到此json时还需特殊处理),并且错误信息也没有进行统一的维护。所以 我们重构注解的异常方法,让其错误信息按着我们统一格式返回。
第一步:定义错误消息枚举
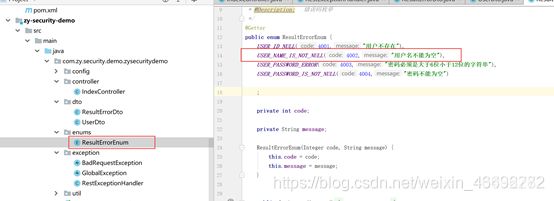
第二步:在dto中加入相应注解并在message中传入定义的枚举

第三步: Postman测试结果
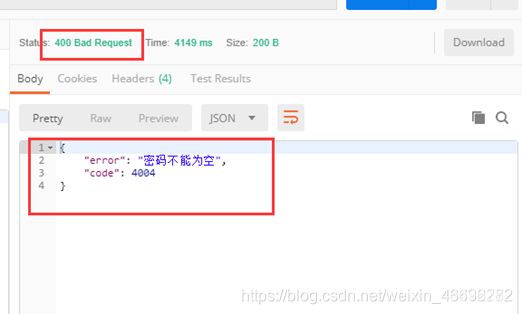
第四步: 前端接收到后端返回的json对象,做统一的拦截处理,判断 status==400弹出统一的提示(提示框为警告黄色状态,提示语为返回json对象中“error”信息)
总结:使用此方式,代码精简、错误码与消息能够统一维护、返回客户端的状态更加明确,是符合RestFulApi的最佳实践。
三、定义全局的异常处理方法,避免异常未经处理直接暴露给前端,前端无法处理未知错误的异常,经常给客户造成系统bug。(此处很关键,在日常开发中不需要程序员在此处编写逻辑代码,但是需要理解实现原理,以及重视对异常的处理,方便在一些大型项目中重构我在此封装的方法。)
解决方案:我们比较传统的解决办法是用try catch去捕获异常并按照相应的逻辑状态输出json错误码,但是初级程序员,经常遗漏或者不重视此块的代码编写,往往造成大量的程序漏洞。所以 采用spring boot 全局异常重构的方法处理此问题。
提示:基于前后端分离,重构ErrorController方法实现全局异常的捕获,所以 下面的方法对于不是前后端分离的项目不起作用,需要重新封装.特别注意----可以捕获到Controller层的异常,前提是Controller层没有对异常进行catch处理,如果Controller层对异常进行了catch处理,那么在这里就不会捕获到Controller层的异常了,所以这一点要特别注意(不是特殊业务需求,不用书写try catch)。
第一步: 在yml配置文件中定义异常后跳转路由。
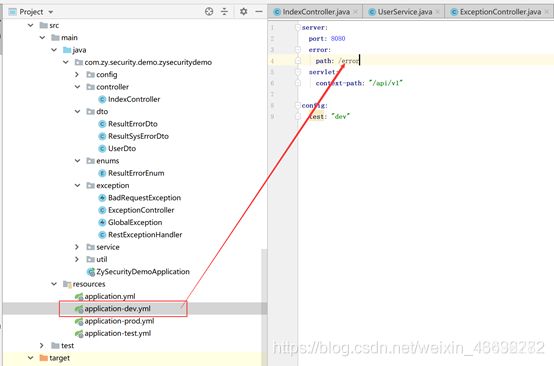
第二步 :重构ErrorController方法,此方法最大的作用是将所有http错误状态 加入code错误码方便前端获取此类状态,所有未定义的错误 前端code都将收到500的错误状态码,但是也将系统异常信息返回给前端,方便程序员日常维护与定位错误。
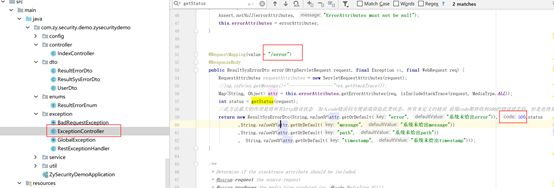
第三步:Postman测试结果:

第四步: 前端接收到后端返回的json对象,做统一的拦截处理,判断 status==500弹出统一的提示(提示框为危险红色状态,提示语为“系统错误,请联系管理员处理!”,在浏览器中console.log出json对象信息)。
总结:如postman测试结果找不到此路由本来系统返回的是status 404状态,但通过重构全局的异常方法,将所有http错误状态统一返回status为500服务器内部错误状态(返回的status同样保留系统原始异常抛出的状态方便程序员定位错误原因),方便前端获取此状态后做统一的判断处理。避免由于系统开发造成的未知bug,引起前端做无状态的处理或者处理起来容易遗漏。
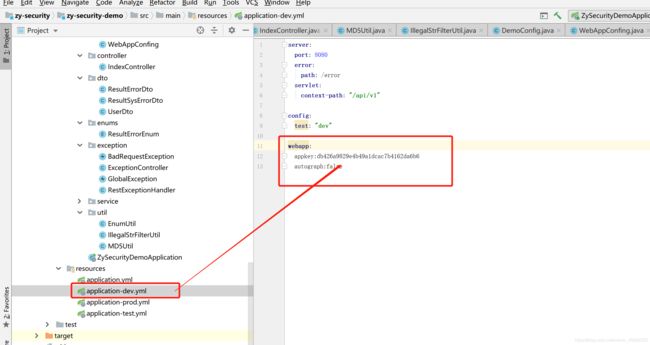
四、开发过程中需要注意如数据库密码、用户名等可配置信息请存放在配置文件中,读取配置文件参数,配置类在包config/DemoConfig.java(根据需求新增新的配置类)下面书写。配置文件 统一使用yml的方式,并且书写四个yml配置文件,用于不同环境下面的参数书写。

五、注解@JsonView的使用,有时候我们希望在不同的请求中隐藏一些字段。可以用@JsonView控制输出内容。
例子:条件查询时候不返回用户的密码,查看详情时候返回用户的密码。
六、使用前后端分离开发的项目,需要定义统一的前置路由规范
例子:http://localhost:8080/api/v1/user/1 api–代表后端接口,v1–代表版本
Yml中的实现:
server:
port: 8080
servlet:
context-path: “/api/v1”
七、代码逻辑必须写在service层,除非极为特殊情况,可以将少量逻辑放在controller
八、SpringBoot Web项目的参数绑定:URL传参及默认参数设置
第一种情况:参数类型必须书写包装类型
基本的数据类型如果在声明的时候没有初始化,编译器会赋予默认值,引用类型的对象(如String)默认值为null。但如果是局部变量(Local Variables,方法体内申明),编译器不会自动赋予初始值,会报编译错误。
第二种情况:如果页面上表单里的参数和代码里的参数名不一样怎么办,这时候就可以用注解了:@RequestParam(value = “paramTest”)
第三种情况:有时候页面上的表单客户不填任何值,但是在控制器里希望它有默认值
可以这样:@RequestParam(defaultValue = “5”)
第四种情况:RequestParam还有个属性:required
九、理解spring boot 自带tomcat
1.明白是哪一个依赖让我们使用了springboot自带的tomcat

十、AOP切面的理解与应用
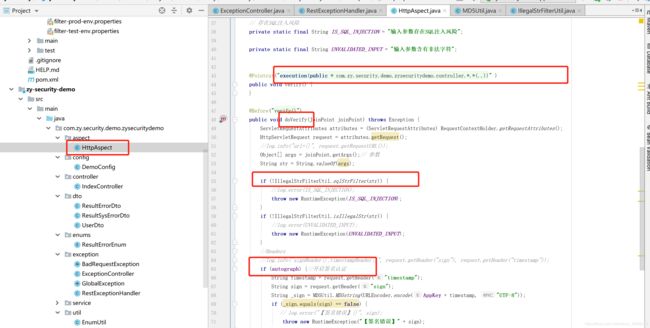
例子:① 若是需要一个记录日志的功能,首先想到的是在方法中通过log4j或其他框架来进行记录日志,但写下来发现一个问题,在每个方法都需要写log日志的输出代码。②判断用户是否有登录过,登录后才能让其访问我们的controller层,也需要在每个controller方法前写统一的判断方法。所以 我们使用AOP切面进行操做。
使用AOP实现 http请求中验证http签名
实现思路:
1.前端在Header中加入请求时间参数
String timestamp =request.getHeader(“timestamp”);
2.前端与后端使用同一种加密算法加密出sign 并在Header中加入
String sign = request.getHeader(“sign”);
3.后端使用同样的算法计算sign
String _sign = MD5Util.MD5string(URLEncoder.encode(webAppConfing.getAppKey() + timestamp, “UTF-8”));
if (_sign.equals(sign) == false) {
// log.error("【签名错误】{}", sign);
4.如果计算出来的sign不一致,则抛出异常,不让其访问接口
throw new RuntimeException("【签名错误】" + sign);
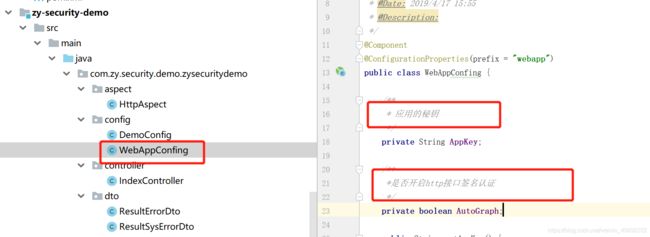
第一步:在yml文件中加入配置参数,并实现参数的调用(参考上面内容如何写配置文件)
第二步:新建AOP切面,并写切面逻辑
第三步:postman测试
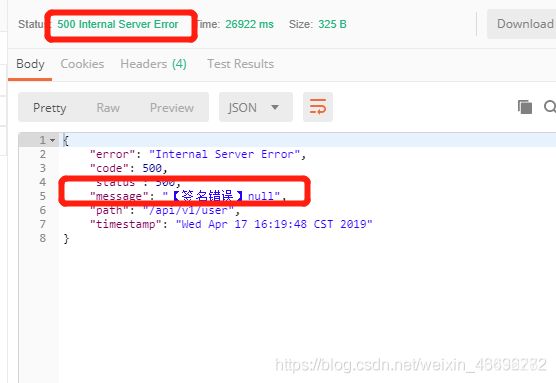
总结: 使用切面可以轻松完成签名认证,防止我们后端接口没有任何安全策略的情况下暴露给任何人,从而提高系统的健壮性。
使用AOP完成sql注入的筛选
实现方法较为简单,自己查看源码包中的实现方式。
前端编码规范
一、一般规范
1.1 文件/资源命名
在 web 项目中,所有的文件名应该都遵循同一命名约定。以可读性而言,减号(-)是用来分隔文件名的不二之选。同时它也是常见的 URL 分隔符(i.e. //example.com/blog/my-blog-entry or //s.example.com/images/big-black-background.jpg),所以理所当然的,减号应该也是用来分隔资源名称的好选择。
请确保文件命名总是以字母开头而不是数字。而以特殊字符开头命名的文件,一般都有特殊的含义与用处(比如 compass[1] 中的下划线就是用来标记跳过直接编译的文件用的)。
资源的字母名称必须全为小写,这是因为在某些对大小写字母敏感的操作系统中,当文件通过工具压缩混淆后,或者人为修改过后,大小写不同而导致引用文件不同的错误,很难被发现。
还有一些情况下,需要对文件增加前后缀或特定的扩展名(比如 .min.js, .min.css),抑或一串前缀(比如 3fa89b.main.min.css)。这种情况下,建议使用点分隔符来区分这些在文件名中带有清晰意义的元数据。
推荐

1.2 协议
不要指定引入资源所带的具体协议。
当引入图片或其他媒体文件,还有样式和脚本时,URLs 所指向的具体路径,不要指定协议部分(http:, https:),除非这两者协议都不可用。
不指定协议使得 URL 从绝对的获取路径转变为相对的,在请求资源协议无法确定时非常好用,而且还能为文件大小节省几个字节。
推荐


1.3 文本缩进
一次缩进两个空格。
推荐

1.4注释
注释是你自己与你的小伙伴们了解代码写法和目的的唯一途径。特别是在写一些看似琐碎的无关紧要的代码时,由于记忆点不深刻,注释就变得尤为重要了。
编写自解释代码只是一个传说,没有任何代码是可以完全自解释的。而代码注释,则是永远也不嫌多。
当你写注释时一定要注意:不要写你的代码都干了些什么,而要写你的代码为什么要这么写,背后的考量是什么。当然也可以加入所思考问题或是解决方案的链接地址。
推荐

一些注释工具可以帮助你写出更好的注释。JSDoc 或 YUIDoc 就是用来写 JavaScript 注释用的。你甚至可以使用工具来为这些注释生成文档,这也是激励开发者们写注释的一个好方法,因为一旦有了这样方便的生成文档的工具,他们通常会开始花更多时间在注释细节上。
1.5 代码检查
对于比较宽松自由的编程语言来说,严格遵循编码规范和格式化风格指南就显得极为重要。遵循规范固然很好,但是有自动化流程来确保其执行情况,岂不更佳。Trust is good, control is better.
对于 JavaScript,建议使用 JSLint 或 JSHint
二、HTML规范
2.1 HTML 规范
- 文档类型
推荐使用 HTML5 的文档类型申明: .
(建议使用 text/html 格式的 HTML。避免使用 XHTML。XHTML 以及它的属性,比如 application/xhtml+xml 在浏览器中的应用支持与优化空间都十分有限)。
HTML 中最好不要将无内容元素[1] 的标签闭合,例如:使用
而非
.
2.2 HTML 验证
一般情况下,建议使用能通过标准规范验证的 HTML 代码,除非在性能优化和控制文件大小上不得不做出让步。
使用诸如 W3C HTML validator 这样的工具来进行检测。
规范化的 HTML 是显现技术要求与局限的显著质量基线,它促进了 HTML 被更好地运用。
2.3 省略可选标签
HTML5 规范中规定了 HTML 标签是可以省略的。但从可读性来说,在开发的源文件中最好不要这样做,因为省略标签可能会导致一些问题。
省略一些可选的标签确实使得页面大小减少,这很有用,尤其是对于一些大型网站来说。为了达到这一目的,我们可以在开发后期对页面进行压缩处理,在这个环节中这些可选的标签完全就可以省略掉了。
2.4 脚本加载
出于性能考虑,脚本异步加载很关键。一段脚本放置在 内,比如 ,其加载会一直阻塞 DOM 解析,直至它完全地加载和执行完毕。这会造成页面显示的延迟。特别是一些重量级的脚本,对用户体验来说那真是一个巨大的影响。
异步加载脚本可缓解这种性能影响。如果只需兼容 IE10+,可将 HTML5 的 async 属性加至脚本中,它可防止阻塞 DOM 的解析,甚至你可以将脚本引用写在 里也没有影响。
如需兼容老旧的浏览器,实践表明可使用用来动态注入脚本的脚本加载器。你可以考虑 yepnope 或 labjs。注入脚本的一个问题是:一直要等到 CSS 对象文档已就绪,它们才开始加载(短暂地在 CSS 加载完毕之后),这就对需要及时触发的 JS 造成了一定的延迟,这多多少少也影响了用户体验吧。
终上所述,兼容老旧浏览器(IE9-)时,应该遵循以下最佳实践。
脚本引用写在 body 结束标签之前,并带上 async 属性。这虽然在老旧浏览器中不会异步加载脚本,但它只阻塞了 body 结束标签之前的 DOM 解析,这就大大降低了其阻塞影响。而在现代浏览器中,脚本将在 DOM 解析器发现 body 尾部的 script 标签才进行加载,此时加载属于异步加载,不会阻塞 CSSOM(但其执行仍发生在 CSSOM 之后)。
推荐
2.5 语义化
根据元素(有时被错误地称作“标签”)其被创造出来时的初始意义来使用它。打个比方,用 heading 元素来定义头部标题,p 元素来定义文字段落,用 a 元素来定义链接锚点,等等。
有根据有目的地使用 HTML 元素,对于可访问性、代码重用、代码效率来说意义重大。
2.6 多媒体回溯
对页面上的媒体而言,像图片、视频、canvas 动画等,要确保其有可替代的接入接口。图片文件我们可采用有意义的备选文本(alt),视频和音频文件我们可以为其加上说明文字或字幕。
提供可替代内容对可用性来说十分重要。试想,一位盲人用户如何能知晓一张图片是什么,要是没有 @alt 的话。
2.7 HTML 内容至上
不要让非内容信息污染了你的 HTML。现在貌似有一种倾向:通过 HTML 来解决设计问题,这是显然是不对的。HTML 就应该只关注内容。
HTML 标签的目的,就是为了不断地展示内容信息。
不要引入一些特定的 HTML 结构来解决一些视觉设计问题。
不要将 img 元素当做专门用来做视觉设计的元素。
三、JavaScript规范
3.1全局命名空间污染与 IIFE
总是将代码包裹成一个 IIFE(Immediately-Invoked Function Expression),用以创建独立隔绝的定义域。这一举措可防止全局命名空间被污染。
IIFE 还可确保你的代码不会轻易被其它全局命名空间里的代码所修改(i.e. 第三方库,window 引用,被覆盖的未定义的关键字等等)。
3.2 变量声明
总是使用 var 来声明变量。如不指定 var,变量将被隐式地声明为全局变量,这将对变量难以控制。如果没有声明,变量处于什么定义域就变得不清(可以是在 Document 或 Window 中,也可以很容易地进入本地定义域)。所以,请总是使用 var 来声明变量。
采用严格模式带来的好处是,当你手误输入错误的变量名时,它可以通过报错信息来帮助你定位错误出处。
3.3 理解 JavaScript 的定义域和定义域提升
在 JavaScript 中变量和方法定义会自动提升到执行之前。JavaScript 只有 function 级的定义域,而无其他很多编程语言中的块定义域,所以使得你在某一 function 内的某语句和循环体中定义了一个变量,此变量可作用于整个 function 内,而不仅仅是在此语句或循环体中,因为它们的声明被 JavaScript 自动提升了。
3.4 异常
基本上你无法避免出现异常,特别是在做大型开发时(使用应用开发框架等等)。
在没有自定义异常的情况下,从有返回值的函数中返回错误信息一定非常的棘手,更别提多不优雅了。不好的解决方案包括了传第一个引用类型来接纳错误信息,或总是返回一个对象列表,其中包含着可能的错误对象。以上方式基本上是比较简陋的异常处理方式。适时可做自定义异常处理。
四、CSS/SCSS规范
4.1 合理的避免使用ID
一般情况下ID不应该被应用于样式。
ID的样式不能被复用并且每个页面中你只能使用一次ID。
使用ID唯一有效的是确定网页或整个站点中的位置。
尽管如此,你应该始终考虑使用class,而不是id,除非只使用一次。
4.2 CSS选择器中避免标签名
当构建选择器时应该使用清晰, 准确和有语义的class(类)名。不要使用标签选择器。 如果你只关心你的class(类)名
,而不是你的代码元素,这样会更容易维护。
从分离的角度考虑,在表现层中不应该分配html标记/语义。
它可能是一个有序列表需要被改成一个无序列表,或者一个div将被转换成article。
如果你只使用具有实际意义的class(类)名,并且不使用元素选择器,那么你只需要改变你的html标记,而不用改动你的CSS。
4.3 十六进制表示法
在可能的情况下,使用3个字符的十六进制表示法。颜色值允许这样表示,3个字符的十六进制表示法更简短。始终使用小写的十六进制数字。
4.4 ID 和 Class(类) 名的分隔符
使用连字符(中划线)分隔ID和Class(类)名中的单词。为了增强课理解性,在选择器中不要使用除了连字符(中划线)以为的任何字符(包括没有)来连接单词和缩写。
另外,作为该标准,预设属性选择器能识别连字符(中划线)作为单词[attribute|=value]的分隔符,所以最好的坚持使用连字符作为分隔符。
4.5选择器嵌套 (SCSS)
在Sass中你可以嵌套选择器,这可以使代码变得更清洁和可读。嵌套所有的选择器,但尽量避免嵌套没有任何内容的选择器。
如果你需要指定一些子元素的样式属性,而父元素将不什么样式属性,
可以使用常规的CSS选择器链。
这将防止您的脚本看起来过于复杂。
4.6 上下文媒体查询(SCSS)
在Sass中,当你嵌套你的选择器时也可以使用上下文媒体查询。
在Sass中,你可以在任何给定的嵌套层次中使用媒体查询。
由此生成的CSS将被转换,这样的媒体查询将包裹选择器的形式呈现。这技术非常方便,有助于保持媒体查询属于的上下文。
第一种方法这可以让你先写你的手机样式,然后在任何你需要的地方用上下文媒体查询以提供桌面样式。
4.7嵌套顺序和父级选择器(SCSS)
当使用Sass的嵌套功能的时候,重要的是有一个明确的嵌套顺序,以下内容是一个SCSS块应具有的顺序。
- 当前选择器的样式属性
- 父级选择器的伪类选择器 (:first-letter, :hover, :active etc)
- 伪类元素 (:before and :after)
- 父级选择器的声明样式 (.selected, .active, .enlarged etc.)
- 用Sass的上下文媒体查询
- 子选择器作为最后的部分