C++入门-引用
C++入门-引用
- 前置知识点:函数栈帧的复用
- 前置知识点:类型转换时产生的临时变量
- 1.含义
- 2.代码形式
- 3.引用的价值
-
- 1.传参数
-
- 传参效率测试
- 补充:C++与Java中引用的区别
- 2.引用做返回值(前置知识:栈帧复用)
-
- 1.传值返回
- 2.传引用返回
- 传引用返回并用引用接收
- 3.静态变量传引用返回
- 4.引用做返回值真正的价值
- 4.常引用(前置知识:类型转换时产生的临时变量)
- 5.引用的底层实现
- 6.引用和指针的区别
注意:引用的价值无法再这一节中全部说完,引用的更大价值在类和对象当中有所体现
前置知识点:函数栈帧的复用
首先请大家看一句话:
时间是一去不复返的
而空间是可以重复利用的
结合我们的日常生活,这句话没毛病,同样的,在C和C++中也是如此
其中空间是可以重复利用的这一点就被函数栈帧的复用所深刻地体现出来了
其中函数栈帧的销毁并不是说把这块内存空间销毁了,而是把这块内存空间的管理权归还给操作系统了,而申请内存空间就是向操作系统申请一块内存空间的管理权
释放空间就像是酒店退房间一样,退了的房间还能再租给下一个客人
下面写一份代码让大家更清晰的看一下

如图我们可以看出test1函数跟test2函数相继调用,在test1函数的栈帧销毁之后,再建立了test2函数的栈帧
我们发现a和b的地址相同,这也就说明了函数栈帧的复用
为什么a和b的地址会相同呢?
1.函数栈帧的复用
2.a和b的都是同大小的变量
如果我们修改一下test2函数的代码

我们发现,a和x的地址相同,但是a跟b的地址不相同了,
这个说明了即使函数内部所使用的空间大小不同,但是依然会进行函数栈帧的复用
所有的函数相继调用时都会复用上一个战帧
只不过开的栈帧的大小不同
这里先介绍一下函数栈帧的复用,为了后面讲解引用作为返回值的地方打下基础
前置知识点:类型转换时产生的临时变量
类型转换会产生临时变量!!!,临时变量具有常性,也就是不能再被修改了

1.含义
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
C++对C语言最大的改进:引用
因为C++设计者极其不喜欢指针,认为指针太麻烦
在语法上讲:引用就是取别名
2.代码形式
int main()
{
int a = 1;
int b = a;//把a的值拷贝给b
//c是a的别名
//c和a共用一块内存空间
int& c = a;
b++;
cout << a << endl;//1
c--;
cout << a << endl;//0
//取多少别名都可以
//也就是说一个对象可以有多个引用
int& d = a;
//这么取别名也可以(也可以给别名取别名)
int& e = d;
//a,c,d,e的地址是一样的
cout << &a << endl;
cout << &c << endl;
cout << &d << endl;
cout << &e << endl;
/*
0031FC38
0031FC38
0031FC38
0031FC38
*/
return 0;
}
3.引用的价值
1.传参数
引用还可以再传参的时候提升效率,不用再去额外的开辟空间
比方说我们要实现一个Swap函数交换两个整形变量
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
//这两个函数构成重载
void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}
int main()
{
int num1 = 1, num2 = 2;
Swap(&num1, &num2);
cout << num1 << " " << num2 << endl;
Swap(num1, num2);
cout << num1 << " " << num2 << endl;
/*
2 1
1 2
*/
return 0;
}
学习了引用之后,我们就能对单链表进行优化了

单链表是不可以传入一级指针建表的,除非你虚拟一个哨兵位的头节点,但是不推荐这样做

这里传入的实参是一个一级指针,如果传入的那个一级指针是一个NULL指针的话,如果我们的形参也是一个一级指针的话,只能改变这个结构体的成员
(可以改变next指针,增长这个链表的长度)
无法改变这个指针本身(因为形参的改变不会影响实参)
也就是说如果传入的这个链表不是空链表的话,传一级指针可以
但是如果传入的是一个空链表,想要改变这个空链表,那么只能传二级指针

这里SListPushBack(LNode** pphead,int x);
中的*pphead就是传入的plist
但是传二级指针未免有些麻烦了吧,但是引用可以让我们继续只需要传一级指针
typedef struct ListNode
{
struct ListNode* next;
int val;
}LNode,*PLNode;
//PLNode:结点指针的typedef,也就是一个结构体指针
LNode* CreateNode(int x)
{
LNode* newnode = (LNode*)malloc(sizeof(LNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->val = x;
newnode->next = NULL;
return newnode;
}
//二级指针版本
void SListPushBack(LNode** pphead, int x)
{
LNode* newnode = CreateNode(x);
if (*pphead == NULL)
{
//没有头节点
*pphead = newnode;
}
else
{
//找尾指针,再链接newnode
LNode* tail = *pphead;
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode;
}
}
//phead是plist2的一个别名,也就是说phead就是plist2
void SListPushBack1(PLNode& phead, int x)
{
PLNode newnode = CreateNode(x);
if (phead == NULL)
{
//没有头节点
phead = newnode;
}
else
{
//找尾指针,再链接newnode
PLNode tail = phead;
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode;
}
};
//phead是plist3的一个别名,也就是说phead就是plist3
void SListPushBack2(LNode*& phead, int x)
{
LNode* newnode = CreateNode(x);
if (phead == NULL)
{
//没有头节点
phead = newnode;
}
else
{
//找尾指针,再链接newnode
LNode* tail = phead;
while (tail->next)
{
tail = tail->next;
}
tail->next = newnode;
}
};
void SListPrint(LNode* phead)
{
LNode* cur = phead;
while (cur)
{
cout << cur->val << " -> ";
cur = cur->next;
}
cout << endl;
}
int main()
{
LNode* plist1 = NULL;
SListPushBack(&plist1, 1);
SListPushBack(&plist1, 2);
SListPushBack(&plist1, 3);
SListPushBack(&plist1, 4);
SListPrint(plist1);
PLNode plist2 = NULL;
SListPushBack1(plist2, 1);
SListPushBack1(plist2, 2);
SListPushBack1(plist2, 3);
SListPushBack1(plist2, 4);
SListPrint(plist2);
LNode* plist3 = NULL;
SListPushBack2(plist3, 1);
SListPushBack2(plist3, 2);
SListPushBack2(plist3, 3);
SListPushBack2(plist3, 4);
SListPrint(plist3);
/*
1 -> 2 -> 3 -> 4 ->
1 -> 2 -> 3 -> 4 ->
1 -> 2 -> 3 -> 4 ->
*/
return 0;
}
传参效率测试
那么引用传参比起值传参来效率的提升能有多大呢?
我们来测试一下:
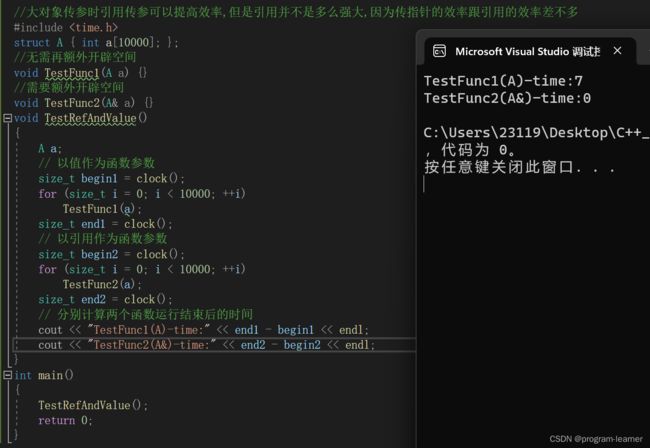
可见引用传参比起值传参还是有一定效率提升的,不过比起指针传参来,效率提升并不是很大,因为传指针也就多开辟4或者8个字节而已
补充:C++与Java中引用的区别
既然引用这么好,那么是不是C++就可以跟Java一样不需要指针了?
答案是:并不是这样的,C++中指针和引用是相辅相成的两种语法,缺一不可
而Java中的确不需要指针
为什么呢?
int main()
{
int a = 10;
int& b = a;
int c = 16;
//请问:b=c;这行代码是什么意思?
//选项1:b不再是a的别名,而是成为了c的别名
//选项2:b和a赋值为c
b = c;
cout << "&a = " << &a << endl;
cout << "&b = " << &b << endl;
cout << "&c = " << &c << endl;
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
return 0;
}
请大家先结合我们所学过的指针的特性来选择一下

选项2是正确的,也就是说b依然是a的别名,只不过a(也就是b)的值被赋值为16而已
但是如果是指针的话,情况就不一样了
int main()
{
int a = 10;
int* b = &a;
int c = 16;
b = &c;
cout << "&a = " << &a << endl;
cout << "b = " << b << endl;
cout << "&c = " << &c << endl;
cout << "a = " << a << endl;
cout << "*b = " << *b << endl;
cout << "c = " << c << endl;
return 0;
}


2.引用做返回值(前置知识:栈帧复用)
引用的第二大价值:引用作为返回值
1.传值返回
下面我们来看一个函数
int Count()
{
int n=0;
n++;
return n;
}
这里return n;
返回的并不是n,而是n的一个拷贝,这个拷贝是一个临时变量,具有常属性,
是一个右值,而不是左值
因为当Count函数调用完了之后Count函数的栈帧会销毁,所以再返回n的时候要先对返回值n进行拷贝,并把拷贝的临时变量返回给调用方,然后Count函数就可以安心的销毁了
2.传引用返回
int& Count()
{
int n=0;
n++;
return n;
}


出了作用域,返回对象就销毁了,不能用引用返回,否则结果是不确定的

在这里尽管我们加上了这几行,不过也依然不会让ret变为随机值,
因为我们每次调用完Count时都会立即用ret来接收n,ret已经保存了n的值,
继续使用cout来开辟栈帧并不会影响ret的值
所以打印出来的依然是1
传引用返回并用引用接收
如果我们用引用去接收引用的返回值呢?
这样的话会有很多坑点,有很多程序的运行结果是无法解释的,
因为传引用返回本来就是个非常严重的错误,你还用引用接收,那错误更加严重了
这就像是薛定谔的猫,猫到底是死的还是活的你并不知道
到底是随机值还是原数值你也并不知道
这是给大家举的一些样例:
1.

第二次变成了随机值
2.
但是如果我们在两次cout当中再次调用Count函数的话

根据前面讲过的函数的栈帧复用原则,在第二次调用Count函数时新开辟的Count函数栈帧会复用第一次调用Count函数时开辟的栈帧,第二次调用Count函数时n的地址跟第一次的相等
而ret是通过引用接收的n,所以说ret就是n的别名,显然两次ret的地址也相同

所以两次ret的值也是1(VS编译器下)或者随机值

在这里第二次调用Add函数的时候,复用了第一次调用Add函数时所产生的栈帧,所以c的地址不变,值变为了7或者随机值
3.静态变量传引用返回
那么什么时候可以传引用返回呢?
1.堆上的数据
2.静态变量
反正只要不是局部变量就可以传引用返回(只要除了作用域后并没有销毁即可)
//局部的静态变量只初始化一次
//静态变量只在第一次调用的时候被初始化
int& Add1(int a, int b)
{
static int c = a + b;
return c;
}
int& Add2(int a, int b)
{
static int d;
d = a + b;
return d;
}
int main014()
{
int& ret = Add1(1, 2);
cout << ret << endl;//3
Add1(3, 4);
cout << ret << endl;//3
int& ret2 = Add2(1, 2);
cout << ret2 << endl;//3
Add2(3, 4);
cout << ret2 << endl;//7
return 0;
}
4.引用做返回值真正的价值
1:提高效率
2:后面在类和对象当中会有体现,到时候会详细说明的
这里先以静态的顺序表作为一个例子来看一下引用作为返回值的价值
//这里还没有对数组a进行初始化
//静态顺序表
typedef struct SeqList
{
int a[100];
int size = 100;
}SL;
#include 4.常引用(前置知识:类型转换时产生的临时变量)
引用跟指针类似,也存在const修饰的引用
权限放大只存在于引用和指针当中
const用于形参 修饰引用/指针
也叫做:预防性编程
int main016()
{
const int a = 10;
int& b = a;//err,这时b不能作为a的别名
//因为a是常变量,不能修改,但是如果b又作为a的别名,但是b又不具有常属性,所以不能这样
//这里的本质是权限的放大
//权限可以不变,可以变小,但是不可以放大
const int& b = a;//yes,权限没有变大
int c = 20;
const int& d = c;//yes,权限可以缩小
const int& e = 10;//yes,可以的,因为e具有常属性,跟10都是不可以改变的,也就是说权限并未放大
int& f = 10;//err,权限放大
const int f = 10;
int g = f;//可以,g是f的值拷贝,跟权限无关,g跟f不是同一块空间
int i = 1;
double j = i;
double& k = i;//err,为什么不可以呢?
const double& l = i;//这里是可以的,本质还是权限放大缩小的问题
//类型转换会产生临时变量!!!!!!,临时变量具有常性,也就是不能再被修改了
//所以加上const就行了
return 0;
}
5.引用的底层实现
引用底层是用汇编实现的,是用指针实现的,也就是说引用在底层上是跟指针一样都开辟了空间的
但是语法上认为引用并没有开辟空间,认为引用就是取别名,语法上并不管底层是如何实现的
日常学习中我们以语法为主,认为引用没有开辟空间的
1.证明引用的底层跟指针一样
int main()
{
int a = 10;
int& b = a;
int* ptr = &a;
return 0;
}
我们查看汇编代码:

发现引用跟指针的汇编代码极其相似,也就证明了引用在底层上是通过指针实现的
2.证明在语法上引用并没有开辟空间
int main()
{
//证明在语法上引用并没有开辟空间
//语法上不管底层:
char ch = 'x';
char& r = ch;
cout << sizeof(r) << endl;//1
//底层上r开了4个或者8个字节,因为底层上引用是用指针实现的
//但是语法上r就是char类型,就是1个字节
return 0;
}
6.引用和指针的区别
引用和指针(更多是使用上和概念上的区别)
引用更加安全一些,但是引用不是绝对安全,只是相对指针来说更安全
引用也可能会出现"野引用"的情况,此时并不安全

以上就是C++入门-引用的全部内容,希望能对大家有所帮助,谢谢大家!