hive-行转列按顺序合并
目录
一、背景
二、实现
1.建表ddl
2.示例数据
3.按顺序合并
4.按顺序合并结果
5.可以看到最后一条最长的才是我们需要的数据
6.结果
一、背景
想实现行转列按顺序合并,但是impala不支持,故用hive实现
二、实现
1.建表ddl
create table a(
id bigint comment '主键',
type bigint comment '分类',
start_time bigint comment '开始时间,时间戳',
end_time bigint comment '结束时间,时间戳',
text string comment '内容'
)stored as textfile;2.示例数据
insert into a values(1,1,1648963299613,1648963319545,'哈哈');
insert into a values(2,1,1648963319545,1648963325635,'嘻嘻');
insert into a values(3,1,1648963325635,1648963331726,'嘿嘿');
insert into a values(4,1,1648963331726,1648963335417,'哦哦');
insert into a values(5,1,1648963335417,1648963346121,'嗯嗯');
insert into a values(6,2,1648964757698,1648964764500,'你');
insert into a values(7,2,1648964764500,1648964778843,'我');
insert into a values(8,2,1648964778843,1648964813889,'他');
insert into a values(9,2,1648964813889,1648964832633,'它');
insert into a values(10,2,1648964832633,1648964840608,'她');
insert into a values(11,2,1648965496307,1648965510042,'123');
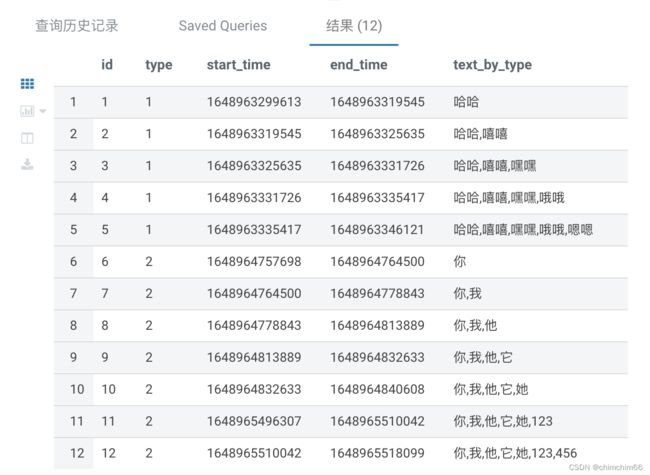
insert into a values(12,2,1648965510042,1648965518099,'456');3.按顺序合并
select
id
,type
,start_time
,end_time
,concat_ws(',',collect_set(text) over(partition by type order by start_time asc)) as text_by_type
from a
order by start_time4.按顺序合并结果
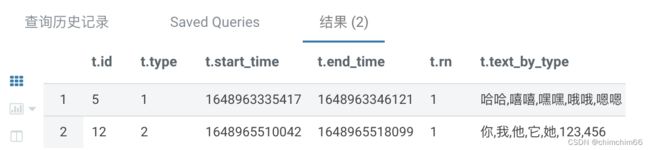
5.可以看到最后一条最长的才是我们需要的数据
select *
from (
select
id
,type
,start_time
,end_time
,row_number() over(partition by type order by start_time desc) as rn
,concat_ws(',',collect_set(text) over(partition by type order by start_time asc)) as text_by_type
from a
order by start_time
) t
where rn=16.结果