第1课-OC对象原理基础
第1课-OC对象原理基础
[TOC]
在探索OC对象原理之前,我们首先需要了解以下知识点
1. lldb
lldb是xcode自带的命令行调试工具。
我们可以通过:
- help:查看lldb常见命令
- help expression: 也可以指定查看某个具体命令,这里是查看expression的具体用法

1.1 计算表达式命令(expression、po、p)
1.1.1 expression
expression可简写为expr或者e expression命令的作用是执行一个表达式,并将表达式返回的结果输出。expression的完整语法是这样的: expression
--: 命令选项结束符,表示所有的命令选项已经设置完毕,如果没有命令选项,--可以省略
例如
计算以及生成一个表达式
(lldb) expr (int)printf ("Print nine: %d.\n", 4 + 5) Print nine: 9. (int) $0 = 15创建一个变量并分配值,注意这里的变量需要添加$前缀
(lldb) expr int $val = 10 (lldb) expr $val (int) $val = 10expr打印值、修改值
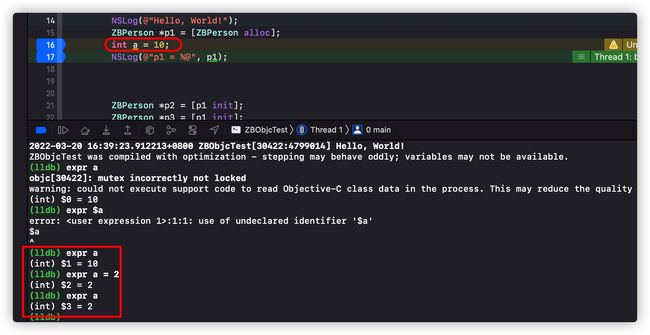
格式化相关打印
(lldb) e -f bin -- 10 (int) $22 = 0b00000000000000000000000000001010 (lldb) e -f oct -- 10 (int) $23 = 012其中:
- e是expression的缩写;
- --是分隔符
- -f bin/oct是格式化语法为:-f (format),其中format支持格式如下
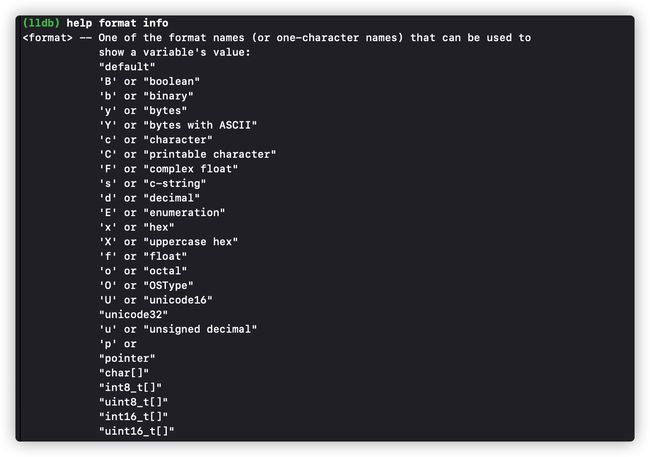
1.1.2 P
p是expression --的简写,它的工作是把接收到参数在当前环境中进行编译,然后打印出来。 例如: 使用p指令做进制转换
//默认打印为10进制
(lldb) p 10
(int) $0 = 10
//转16进制
(lldb) p/x 10
(int) $1 = 0x0000000a
//转8进制
(lldb) p/o 10
(int) $2 = 012
//转二进制
(lldb) p/t 10
(int) $3 = 0b00000000000000000000000000001010
//字符转10进制数字
(lldb) p/d 'A'
(char) $4 = 65
//10进制数字转字符
(lldb) p/c 66
(int) $5 = B\0\0\0
复制代码1.1.3 p、po、expr之间的关系
 总结: p是
总结: p是expression --的简写,它的工作是把接收到参数在当前环境中进行编译,然后打印出来。po是expression -o --的简写,其中-o的表示:-o ( --object-description ),它所做的操作和p相同。如果接收到的参数是一个指针,那么它会调用对象的description方法并打印;如果接收到的参数是一个core foundation对象,那么它会调用CFShow方法并打印。如果这两个方法都调用失败,那么po打印出和p相同的内容。
1.2 内存读取
x/nuf address 内存读取指令
- x是内存读取指令
- nuf参数含义如下

- address:内存地址
例如如下指令: x/4gx指令: 意思就是将内存每8字节分成1段,一共4段,然后以16进制的形式输出出来
- 第一个x是读取内存的命令
- 这里的数字4表示连续打印4段
- 对于g,常用的大小格式为b对应byte 1字节,h对应half word 2字节,w对应word 4字节,g对应giant word 8字节,这里意思就是每次读取8字节
如果我们直接使用x 地址的形式读取内存,会和上面有所不同 
上面
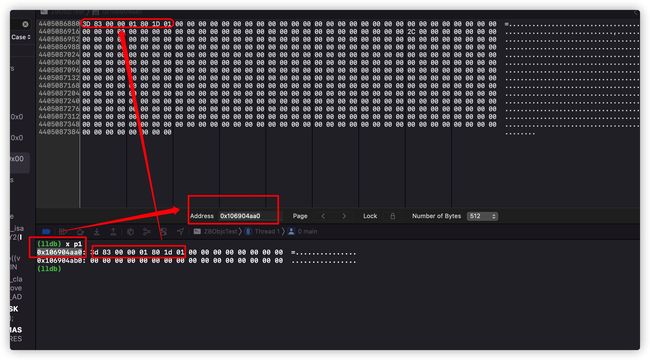
0x100c25360: 3d 83 00 00 01 80 1d 01 00 00 00 00 00 00 00 00 =...............
0x100c25370: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................表示直接读取p1变量在内存中的地址,其中0x100c25360是起始地址,之后的3d 83 00 00 01 80 1d 01每2位占一个字节(16进制),一共占用了8个字节,后面的00 00 00 00 00 00 00 00表示该内存中是空内容。注意这里的0x100c25360是一个地址编号,就是计算机内部的最小存储单元,一个字节。而它存储的内容每2位占一个字节。
另外3d 83 00 00 01 80 1d 01这块地址,从后往前拼接到一块就是0x011d80010000833d这与通过x/4gz p1打印的0x011d80010000833d是相同的。
我们除了通过上面在控制台输入lldb命令查看内存外,我们还可以借助界面话工具查看: 
2. 字节对齐
博客推荐: https://juejin.cn/post/6971358469949489183/ https://juejin.cn/post/6972203893925085192
2.1 字节对齐原则
字节对齐主要是为了提高内存的访问效率。比如intel 32位cpu,每个总线周期都是从偶地址开始读取32位的内存数据,如果数据存放地址不是从偶数开始,则可能出现需要两个总线周期才能读取到想要的数据,那就大大降低了访问效率,因此需要在内存中存放数据时进行对齐。 通常我们说字节对齐很多时候都是说struct结构体的内存对齐。 内存对齐主要遵循下面三个原则:
- 结构体的成员中第一个成员从offset为0的位置开始,之后的成员的起始位置,要求是该成员类型大小的整数倍,如果是数组等包含子成员的成员,则要是其子成员类型大小的整数倍,前面多余的字节由前面的成员补齐
- 如果结构体 A 中包含另一个结构体 B,则 B 的起始位置要是 B 中最大成员的类型大小的整数倍(struct a里存有struct b,b里有char,int ,double等元素,那b应该从8的整数倍开始存储.)
- 结构体最终的大小要是其最大成员的类型大小的整数倍,如果包含子结构体,则最终的大小要是 max(自身最大成员大小,子结构体最大成员大小) 的整数倍,不够的字节在后面补齐
各数据类型占用内存的字节大小可以参照下图 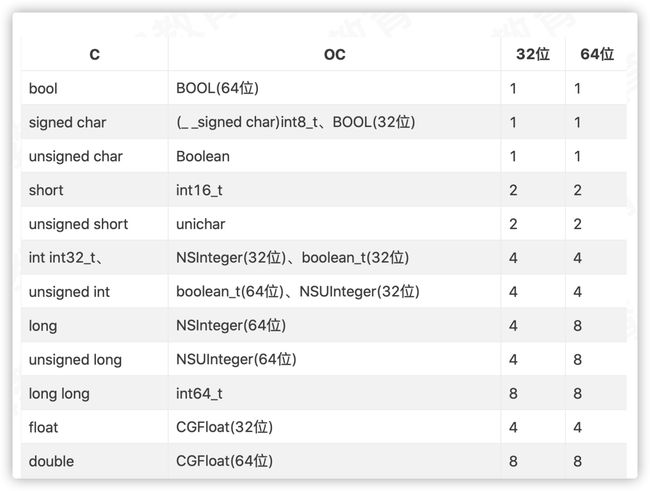
我们再来看下面实例:
2.2 结构体无嵌套
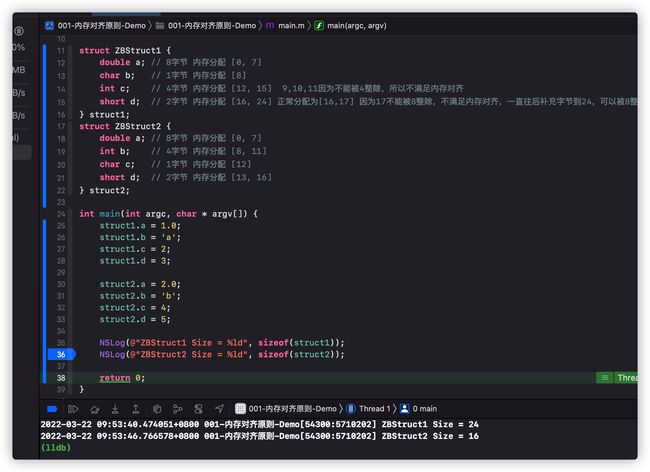
结构体struct1和struct2内部变量完全一样,只是char和int变量的顺序不一样,为什么sizeof不一样呢?这里就是因为内存对齐造成的。
按照内存对齐原则,我们来分析一下struct1和struct2的内存分配过程,假设内存起始地址为0x0000
struct ZBStruct1 {
double a; // 8字节 内存分配 [0, 7]
char b; // 1字节 内存分配 [8, 11] 正常分配[8]
int c; // 4字节 内存分配 [12, 15] 9,10,11因为不能被4整除,所以不满足内存对齐,
short d; // 2字节 内存分配 [16, 24] 正常分配为[16,17] 因为17不能被8整除,不满足内存对齐,一直往后补充字节到24,可以被8整除
} struct1;
struct ZBStruct2 {
double a; // 8字节 内存分配 [0, 7]
int b; // 4字节 内存分配 [8, 11]
char c; // 1字节 内存分配 [12]
short d; // 2字节 内存分配 [14, 16]
} struct2;通过以上分析可以得到与打印结果相同的数据。我们接下来验证一下:
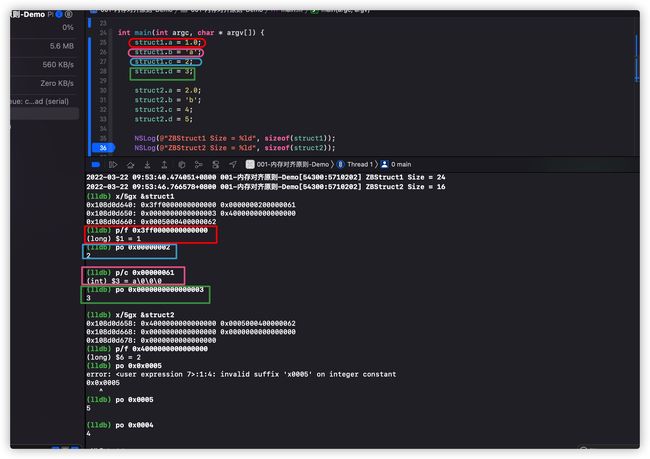
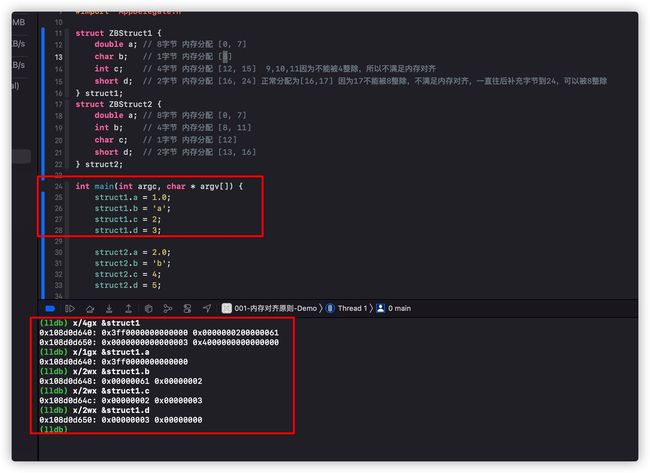
通过上图我们可以发现
- struct1.a 8字节,内存分配 [0x108d0d640, 0x108d0d647] 实际分配8字节
- struct1.b 4字节,内存分配 [0x108d0d648, 0x108d0d64B] 实际分配4字节
- struct1.c 1字节,内存分配 [0x108d0d64C, 0x108d0d64F] 实际分配4字节
- struct1.d 2字节,内存分配 [0x108d0d650, 0x108d0d657] 实际分配8字节
按照我们上面分析的过程,struct1一共分配24字节,验证正确。 不过这里还有一个问题,按照我们的分析sturct1应该先分配b变量,再分配c变量,但是实际存储0x0000000200000061却把c===2===0x00000002,b==='a'===00000061交换了顺序,这是为什么呢? 这里的原因我们通过x/4gx读取内存的时候是从后往前读取的,也就是实际内存中是 61 00 00 00 02 00 00 00这样的,实际上还是先存储的b,再存储的c
同理我们可以得到struct2的实际内存分配: 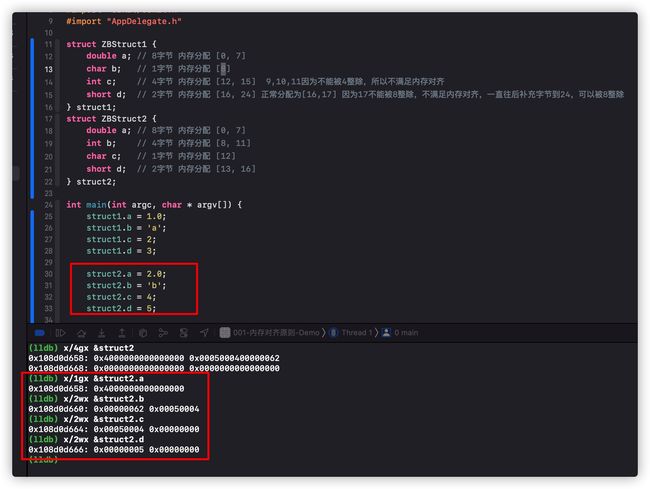
- struct2.a 8字节,内存分配 [0x108d0d658, 0x108d0d65F] 实际分配8字节
- struct2.b 4字节,内存分配 [0x108d0d660, 0x108d0d663] 实际分配4字节
- struct2.c 1字节,内存分配 [0x108d0d664, 0x108d0d665] 实际分配2字节
- struct2.d 2字节,内存分配 [0x108d0d666, 0x108d0d667] 实际分配2字节
总计分配16字节
2.3 结构体有嵌套
结论: 1. 结构体的对齐是按照变量先后顺序依次进行对齐的 2. 如果结构体中包含子结构体,那么子结构体同样需要满足结构体的对齐原则,需要先对齐之后,再对齐父结构体
实例1:
struct Struct1{
double a;
char b;
int c;
short d;
} s1;
struct Struct2{
long a;
int b;
short c;
char d;
struct Struct1 s1;
} s2 = {
1, 2, 3, 'a',
{10.0, 'd', 11, 12}
};
int main(int argc, char * argv[]) {
@autoreleasepool {
NSLog(@"Struct2 Size = %ld", sizeof(s2));
}
return 0;
}
2022-03-24 13:21:44.310610+0800 001-内存对齐原则-Demo[89487:7180330] Struct2 Size = 40接下来我们分析一下Struct2的内存对齐过程:
- long a: 8字节 内存分配8字节,补齐0字节 [0, 7]
- int b: 4字节 内存分配4字节,补齐0字节 [8, 11]
- short c: 2字节 内存分配2字节,补齐0字节 [12, 13]
- char d: 1字节 内存分配2字节,补齐1字节 [14, 15]
- 结构体s1: 24字节 内存分配24字节,补齐9字节 [16, 39]
- s1是结构体变量,内存对齐原则结构体成员要从其内部最大元素大小的整数倍地址开始存储。结构体最大的变量占8字节,所以offset从16开始,总计分配24字节
- double a; // 8字节 内存分配8字节,补齐0字节 [0, 7]
- char b; // 1字节 内存分配4字节,补齐3字节 [8, 11]
- int c; // 4字节 内存分配4字节,补齐0字节 [12, 15]
- short d; // 2字节 内存分配8字节,补齐6字节 [16, 23] 所以一共是40字节
我们验证一下内存分配情况 

s2内存分配如下:
- s2->a: 8字节 [0x10cce3870, 0x10cce3877]
- s2->b: 4字节 [0x10cce3878, 0x10cce387B]
- s2->c: 2字节 [0x10cce387C, 0x10cce387D]
- s2->d: 2字节 [0x10cce387E, 0x10cce387F]
- s2->s1->a: 8字节 [0x10cce3880, 0x10cce3887]
- s2->s1->b: 4字节 [0x10cce3888, 0x10cce388B]
- s2->s1->c: 4字节 [0x10cce388C, 0x10cce388F]
- s2->s1->d: 8字节 [0x10cce3890, 0x10cce3897]
验证通过
实例2: 我们对实例1的变量顺序调整一下
struct Struct1{
double a;
char b;
int c;
short d;
} s1;
struct Struct2{
long a;
int b;
short c;
struct Struct1 s1;
char d;
} s2 = {
1, 2, 3,
{10.0, 'd', 11, 12},
'a'
};
int main(int argc, char * argv[]) {
NSLog(@"Struct2 Size = %ld", sizeof(s2));
}
2022-03-24 13:49:59.159520+0800 001-内存对齐原则-Demo[89988:7202471] Struct2 Size = 48接下来我们分析一下Struct2的内存对齐过程:
- long a: 8字节 内存分配8字节,补齐0字节 [0, 7]
- int b: 4字节 内存分配4字节,补齐0字节 [8, 11]
- short c: 2字节 内存分配4字节,补齐2字节 [12, 15]
- 结构体s1: 24字节 内存分配24字节,补齐9字节 [16, 39]
- s1是结构体变量,内存对齐原则结构体成员要从其内部最大元素大小的整数倍地址开始存储。结构体最大的变量占8字节,所以offset从16开始,总计分配24字节
- double a; // 8字节 内存分配8字节,补齐0字节 [0, 7]
- char b; // 1字节 内存分配4字节,补齐3字节 [8, 11]
- int c; // 4字节 内存分配4字节,补齐0字节 [12, 15]
- short d; // 2字节 内存分配8字节,补齐6字节 [16, 23]
- char d: 1字节 内存分配8字节,补齐7字节 [40, 47] 所以一共是48字节
内存验证如下: 
s2内存分配如下:
- s2->a: 8字节 [0x10d454870, 0x10d454877]
- s2->b: 4字节 [0x10d454878, 0x10d45487B]
- s2->c: 4字节 [0x10d45487C, 0x10d45487F]
- s2->s1->a: 8字节 [0x10d454880, 0x10d454887]
- s2->s1->b: 4字节 [0x10d454888, 0x10d45488B]
- s2->s1->c: 4字节 [0x10d45488C, 0x10d45488F]
- s2->s1->d: 8字节 [0x10d454890, 0x10d454897]
- s2->d: 8字节 [0x10d454898, 0x10d45489F] 验证通过
实例3: 我们对实例2的变量顺序再调整一下
struct Struct1{
int a;
double b;
char c;
char d;
} s1;
struct Struct2{
struct Struct1 s1;
char a;
long b;
int c;
short d;
} s2 = {
{10, 11.0, 'a', 'b'},
'c',1, 2, 3
};
int main(int argc, char * argv[]) {
NSLog(@"Struct2 Size = %ld", sizeof(s2));
}
2022-03-24 13:49:59.159520+0800 001-内存对齐原则-Demo[89988:7202471] Struct2 Size = 48接下来我们分析一下Struct2的内存对齐过程:
- 结构体s1: 24字节 内存分配24字节,补齐10字节 [0, 23]
- s1是结构体变量,内存对齐原则结构体成员要从其内部最大元素大小的整数倍地址开始存储。结构体最大的变量占8字节,所以offset从0开始,总计分配24字节
- int a; // 4字节 内存分配8字节,补齐4字节 [0, 7]
- double b; // 8字节 内存分配8字节,补齐0字节 [8, 15]
- char c; // 1字节 内存分配1字节,补齐0字节 [16]
- char d; // 1字节 内存分配7字节,补齐6字节 [17, 23]
- char a: 1字节 内存分配8字节,补齐7字节 [24, 31]
- long b: 8字节 内存分配8字节,补齐0字节 [32, 39]
- int c: 4字节 内存分配4字节,补齐0字节 [40, 43]
- short d: 2字节 内存分配4字节,补齐2字节 [44, 47] 所以一共是48字节
内存验证如下: 
s2内存分配如下:
- s2->s1->a: 8字节 [0x104661870, 0x104661877]
- s2->s1->b: 8字节 [0x104661878, 0x10466187F]
- s2->s1->c: 1字节 [0x104661880]
- s2->s1->d: 7字节 [0x104661881, 0x104661887]
- s2->a: 8字节 [0x104661888, 0x10466188F]
- s2->b: 8字节 [0x104661890, 0x104661897]
- s2->c: 4字节 [0x104661898, 0x10466189B]
- s2->d: 4字节 [0x10466189C, 0x10466189F] 验证通过
3.编译器
我们在Xcode中经常会看到如下编译选项 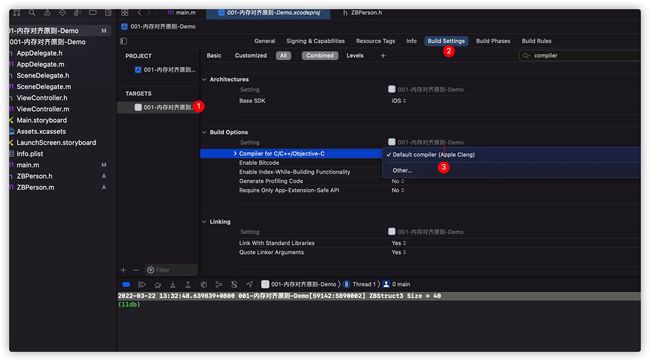 可能很多小伙伴不知道这是个什么东西。 这其实就是⼀个由Apple主导编写,基于LLVM的C/C++/Objective-C编译器Apple clang
可能很多小伙伴不知道这是个什么东西。 这其实就是⼀个由Apple主导编写,基于LLVM的C/C++/Objective-C编译器Apple clang
3.1 什么是编译器
简单讲,编译器就是将“一种语言(通常为高级语言)”翻译为“另一种语言(通常为低级语言)”的程序。一个现代编译器的主要工作流程:源代码 (source code) → 预处理器 (preprocessor) → 编译器 (compiler) → 目标代码 (object code) → 链接器 (Linker) → 可执行程序 (executables)
高级计算机语言便于人编写,阅读交流,维护。机器语言是计算机能直接解读、运行的。编译器将汇编或高级计算机语言源程序(Source program)作为输入,翻译成目标语言(Target language)机器代码的等价程序。源代码一般为高级语言 (High-level language), 如Pascal、C、C++、Java、汉语编程等或汇编语言,而目标则是机器语言的目标代码(Object code),有时也称作机器代码(Machine code)。
传统的编译器通常分为三个部分,前端(frontEnd),优化器(Optimizer)和后端(backEnd)。在编译过程中,前端主要负责词法和语法分析,将源代码转化为抽象语法树;优化器则是在前端的基础上,对得到的中间代码进行优化,使代码更加高效;后端则是将已经优化的中间代码转化为针对各自平台的机器代码。
在苹果发展的历程中,先后使用了GCC、LLVM GCC、LLVM compliler 2.0等编译器
3.2 GCC
GCC(GNU Compiler Collection,GNU编译器套装),是一套由 GNU 开发的编程语言编译器。它是一套以 GPL 及 LGPL 许可证所发行的自由软件,也是 GNU计划的关键部分,亦是自由的类Unix及苹果电脑 Mac OS X 操作系统的标准编译器。
GCC 原名为 GNU C 语言编译器,因为它原本只能处理 C语言。GCC 很快地扩展,变得可处理 C++。之后也变得可处理 Fortran、Pascal、Objective-C、Java, 以及 Ada与其他语言。
3.3 LLVM GCC
LLVM 是 Low Level Virtual Machine 的简称,这个库提供了与编译器相关的支持,能够进行程序语言的编译期优化、链接优化、在线编译优化、代码生成。简而言之,可以作为多种语言编译器的后端来使用。LLVM属于编译器的中间层,它的输入是编译器的IF代码,输出经过最佳化的IF代码。然后再被编译器转化为机器相关的汇编代码。
苹果llvm官方源码 https://github.com/apple/llvm-project
Apple一直使用GCC作为官方的编译器。GCC作为开源世界的编译器标准一直做得不错,但Apple对编译工具会提出更高的要求。慢慢的GCC无法满足Apple编译器的需求,于是Apple请来了编译器高材生Chris Lattner,他对LLVM 的链接优化被直接加入到 Apple 的代码链接器上,而 LLVM-GCC 也被同步到使用 GCC4.0 代码。
3.4 clang
再后来,随着各种条件的限制,Apple无法使用LLVM 继续改进GCC的代码质量。于是,Apple决定从零开始写 C、C++、Objective-C语言的前端 Clang,完全替代掉GCC。于是clang编译器诞生。
Clang是⼀个C语⾔、C++、Objective-C语⾔的轻量级编译器。源代码发布于BSD协议下。Clang是⼀个由Apple主导编写,基于LLVM的C/C++/Objective-C编译器
下面这张图将显示GCC、LLVM-GCC、LLVM Compiler这三个编译选项的不同点:

3.5 GCC与Clang对比
Clang 特性:
- 速度快,通常Clang 比 GCC 快2倍多
- 内存占用小:Clang 内存占用是源码的 130%,Apple GCC 则超过 10 倍。
- 兼容性好:Clang 从一开始就被设计为一个 API,允许它被源代码分析工具和 IDE 集成。GCC 被构建成一个单一的静态编译器,这使得它非常难以被作为 API 并集成到其他工具中。
- Clang 有静态分析,GCC 没有。
- Clang 使用 BSD 许可证,GCC 使用 GPL 许可证。
GCC 优势:
- GCC 支持更多平台
- GCC 更流行,广泛使用,支持完备
- GCC 基于 C,不需要 C++ 编译器即可编译
目前苹果推荐使用clang作为xcode的编译器。
4.位域
4.1 什么是位域
有些信息在存储时,并不需要占用一个完整的字节,而只需占几个或一个二进制位。 例如在存放一个开关量时,只有 0 和 1 两种状态,用一位二进位即可。为了节省存储空间,并使处理简便,C语言又提供了一种数据结构,称为“位域”或“位段”。
4.2 位域的定义和使用说明
位域的定义和结构体有些相似,其一般形式为:
struct struct_name
{
位域列表 //格式为:[类型说明符 位域名:位域长度]
} name;例如下面这样定义一个位域:
struct bits
{
int a:8;
int b:2;
int c:6;
}data;上述位域,说明 data 为 struct bits 变量,共占两个字节,16位。其中位域 a 占 8 位,位域 b 占 2 位,位域 c 占 6位
位域有以下特点:
- 位域的最大值不能超过其定义的类型的比特位数。如一个字节所剩空间不够存放另一位域时,应从下一单元起存放该位域。也可以有意使某位域从下一单元开始。
- 位域可以无位域名,这时它只用来作填充或调整位置。无名的位域是不能使用的。
struct bits
{
int a:4
int :0 /*空域*/
int b:4 /*从下一单元开始存放*/
int :4// 该4位不能使用
}以上,a 占第一字节的 4 位,后 4 位填 0 表示不使用,b 从第二字节开始,占用 4 位,后4位不能使用。假设int是4字节,也就是32位,也就是位域a最大支持32,也就是 int a : 32
我们举个例子:
 上面例子中,结构体s11占用4字节,位域s22占用1字节,位域大大节省了内存空间。
上面例子中,结构体s11占用4字节,位域s22占用1字节,位域大大节省了内存空间。
4.3 位域的总结
位域在本质上就是一种结构类型,不过其成员是按二进位分配的。
- 位运算是C语言的一种特殊运算功能, 它是以二进制位为单位进行运算的。 位运算符只有逻辑运算和移位运算两类。位运算符可以与赋值符一起组成复合赋值符。 如&=,|=,^=,>>=,<<=等。
- 利用位运算可以完成汇编语言的某些功能,如置位,位清零,移位等。还可进行数据的压缩存储和并行运算。
- 位域在本质上也是结构类型,不过它的成员按二进制位分配内存。其定义、说明及使用的方式都与结构相同。
- 位域提供了一种手段,可以在高级语言中实现数据的压缩,节省了存储空间,同时也提高了程序的效率。在以前老旧的机器上存储空间比较小,位域的设计确是能够节省存储空间。但随着时代的发展,现在机器的存储空间普遍都比较大,所以不要为了刻意节省存储空间而使用位域,我们只需要了解位域的相关知识即可
5.联合体/共用体union
5.1 联合体的定义和声明
联合体类型的一般形式为:
union 联合体类型名
{
成员类型 联合体成员名1;
成员类型 联合体成员名2;
...
成员类型 联合体成员名n;
}union 是定义联合体数据类型的关键字,联合体类型名是一个标识符,该标识符以后就是一个新的数据类型,成员类型是常规的数据类型,用来设置联合体成员的存储空间。
定义联合体有如下几种方式:
先定义联合体,然后声明联合体变量
union MyUnion { int a; char b; float c; }; union MyUnion myUnion;可以直接在定义时声明联合体变量
union MyUnion { int a; char b; float c; }myUnion;可以直接声明联合体变量(该方式省略了联合体类型名)
union { int a; char b; float c; }myUnion;
5.2 联合体的初始化
联合体的初始化方式和结构体相同,但联合体只能初始化一个值。尽管联合体中有多个成员变量,但是却是多个成员共用一个存储空间。
union MyUnion
{
int a;
char b;
float c;
}myUnion = {'A'};这种方式赋值可能存在问题,因为不能确定赋的值到底赋给了哪个变量,推荐使用下列方式:
union MyUnion
{
int a;
char b;
double c;
}myUnion;
myUnion.b = 'A';5.3 联合体的大小
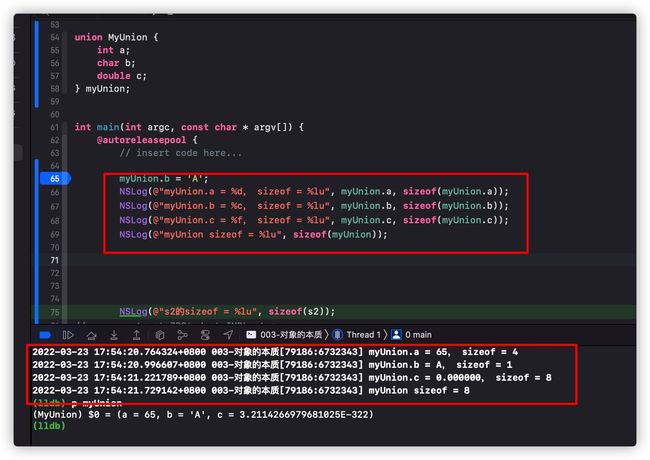 还是上面的例子,我们通过sizeof计算myUnion每个变量的大小,可以得出: a的大小是4字节,b的大小是1字节,c的大小是8字节,myUnion整体的大小是8字节。 联合体所有的成员共用一个存储空间,联合体存储空间的大小取决于最大成员的大小。
还是上面的例子,我们通过sizeof计算myUnion每个变量的大小,可以得出: a的大小是4字节,b的大小是1字节,c的大小是8字节,myUnion整体的大小是8字节。 联合体所有的成员共用一个存储空间,联合体存储空间的大小取决于最大成员的大小。
我们再举个例子:  我们仔细观察上面当一个联合体的变量被赋值的时候,其他变量的情况。
我们仔细观察上面当一个联合体的变量被赋值的时候,其他变量的情况。
- name被赋值时,age = 15958,height = 0.00000都是脏内存,因为联合体当前只有name是有效的,其他变量都是无效的
- age被赋值时,name,height是脏数据
- height被赋值时,name,age是脏数据,因为name是脏数据,所以在打印name的时候可能遇到了非法指针而崩溃。
5.4 联合体特点
- 使用联合体变量的目的是希望用同一个内存段存放几种不同类型的数据,但请注意,在同一时间只能存放其中一种,而不是同时存放几种。
- 能够被访问的是联合体变量中最后一次被赋值的成员,在对一个新的成员赋值后原有的成员就失去作用。
- 联合体变量的地址和它的各成员的地址都是同一个地址。
- 不能对联合体变量名赋值,不能企图引用变量名来得到一个值,不能用联合体变量名做为函数参数。
对比结构体与联合体我们可以发现如下特点:
- 结构体(struct)中所有变量是“共存”的——优点是“有容乃⼤”,全⾯;缺点是struct内存空间的分配是粗放的,不管⽤不⽤,全分配。
- 联合体(union)中是各变量是“互斥”的——缺点就是不够“包容”;但优点是内存使⽤更为精细灵活,也节省了内存空间
5.5 联合体位域
通过联合体,然后结合位域,能够进一步节省内存空间。看如下实例
union u1 {
unsigned long bits;
Class cls;
struct {
unsigned long a : 1;
unsigned long b : 1;
unsigned long c : 1;
unsigned long d : 44;
unsigned long e : 6;
unsigned long f : 1;
unsigned long g : 1;
unsigned long h : 1;
unsigned long i : 8;
};
}myUnion;
执行myUnion.bits = 10; 
执行myUnion.cls = person.class;
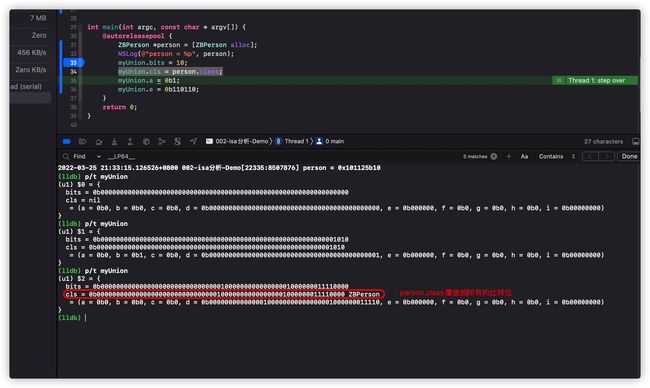
执行myUnion.a = 0b1; 
执行myUnion.e = 0b110110; 
由上面的分析我们可以得出如下结论:
- 联合体中bits,cls,和匿名位域公用8字节的内存空间
- 无论是给哪个变量赋值,都会直接影响8字节的比特位,那么其他的变量的值都会跟随改变
- 上面的联合体位域其实就是对象成员变量isa底层的联合体位域原型。
6. 大端和小端模式
所谓的大端模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中; 所谓的小端模式,是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中。
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
我们的ios设备就是采用的小端模式。
例如,32bit宽的数0x12345678在小端模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
| 内存地址 | 0x4000 | 0x4001 | 0x4002 | 0x4003 |
|---|---|---|---|---|
| 存放内容 | 0x78 | 0x56 | 0x34 | 0x12 |
而在大端模式CPU内存中的存放方式则为:
| 内存地址 | 0x4000 | 0x4001 | 0x4002 | 0x4003 |
|---|---|---|---|---|
| 存放内容 | 0x12 | 0x34 | 0x56 | 0x78 |