通过 DLPack 构建跨框架深度学习编译器
以下内容翻译自:Building a Cross-Framework Deep Learning Compiler via DLPack
诸如 Tensorflow、PyTorch 和 Apache MxNet 等深度学习框架为深度学习的快速原型设计和模型部署提供了强大的工具箱。不幸的是,它们的易用性通常以碎片化为代价:这仅限于单独使用每个框架。垂直整合使得开发流程适用于常见用例,但打破常规可能会非常棘手。
一种支持不足的情况是在内存中直接将张量从一个框架传递到另一个框架,而不发生任何数据复制或拷贝。支持这样的用例将使用户能够将管道串联在一起,其中某些运算符在一个框架中比另一个框架支持得更好(或更快)。框架之间的共享数据表示也将弥补这一差距,并允许编译器堆栈在为运算符生成代码时以单一格式为目标。
DLPack 是张量数据结构的中间内存表示标准。以 DLPack 作为通用表示,我们可以在框架脚本中利用 TVM,而传统上其仅能依赖设备商提供的库。TVM 的打包函数可以在 DLPack 张量上运行,提供从 PyTorch 和 MxNet 等框架桥接张量数据结构并实现零数据复制的封装器。
DLPack 提供了一个简单、可移植的内存数据结构:
/*!
* \brief Plain C Tensor object, does not manage memory.
*/
typedef struct {
/*!
* \brief The opaque data pointer points to the allocated data.
* This will be CUDA device pointer or cl_mem handle in OpenCL.
* This pointer is always aligns to 256 bytes as in CUDA.
*/
void* data;
/*! \brief The device context of the tensor */
DLContext ctx;
/*! \brief Number of dimensions */
int ndim;
/*! \brief The data type of the pointer*/
DLDataType dtype;
/*! \brief The shape of the tensor */
int64_t* shape;
/*!
* \brief strides of the tensor,
* can be NULL, indicating tensor is compact.
*/
int64_t* strides;
/*! \brief The offset in bytes to the beginning pointer to data */
uint64_t byte_offset;
} DLTensor;例如,我们在 TVM 中声明并编译矩阵乘法运算符,并构建一个使用 DLPack 表示的包装器,以允许此运算符支持 PyTorch 张量。我们还用 MxNet 重复这个演示。此扩展允许机器学习开发人员快速将研究代码移植到相对不受支持的硬件平台,而不会牺牲性能。
DLPack 所提供框架和 TVM 之间共享的中间包装器的图解:
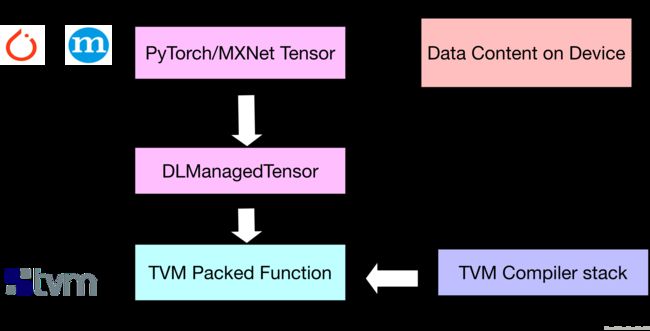
首先,我们在 PyTorch 中计算参考输出:
import torch
x = torch.rand(56,56)
y = torch.rand(56,56)
z = x.mm(y)然后,我们使用默认计划定义和构建 TVM 矩阵乘法运算符:
n = tvm.convert(56)
X = tvm.placeholder((n,n), name='X')
Y = tvm.placeholder((n,n), name='Y')
k = tvm.reduce_axis((0, n), name='k')
Z = tvm.compute((n,n), lambda i,j : tvm.sum(X[i,k]*Y[k,j], axis=k))
s = tvm.create_schedule(Z.op)
fmm = tvm.build(s, [X, Y, Z], target_host='llvm', name='fmm')为简洁起见,我们不介绍 TVM 的大量调度原语,我们可以使用这些原语来优化矩阵乘法。如果您希望在硬件设备上快速运行自定义 GEMM 运算符,可以在此处找到详细的教程。
然后我们将 TVM 函数转换为支持 PyTorch 张量的函数:
from tvm.contrib.dlpack import to_pytorch_func
# fmm is the previously built TVM function (Python function)
# fmm is the wrapped TVM function (Python function)
fmm_pytorch = to_pytorch_func(fmm)
z2 = torch.empty(56,56)
fmm_pytorch(x, y, z2)
np.testing.assert_allclose(z.numpy(), z2.numpy())并验证结果是否一致。
我们可以使用 MxNet 重复上面的例子:
import mxnet
from tvm.contrib.mxnet import to_mxnet_func
ctx = mxnet.cpu(0)
x = mxnet.nd.uniform(shape=(56,56), ctx=ctx)
y = mxnet.nd.uniform(shape=(56,56), ctx=ctx)
z = mxnet.nd.empty(shape=(56,56), ctx=ctx)
f = tvm.build(s, [X, Y, Z], target_host='llvm', name='f')
f_mxnet = to_mxnet_func(f)
f_mxnet(x, y, z)
np.testing.assert_allclose(z.asnumpy(), x.asnumpy().dot(y.asnumpy()))在 PyTorch 示例的底层
由于 TVM 提供了将 dlpack 张量与 tvm.ndarray 相互转换的函数,所以只需要通过包装函数来获得一些语法糖。对于拥有 dlpack 支持张量的框架,convert_func是通用转换器,可用于实现方便的转换器,例如 to_pytorch_func。
def convert_func(tvm_func, tensor_type, to_dlpack_func):
assert callable(tvm_func)
def _wrapper(*args):
args = tuple(ndarray.from_dlpack(to_dlpack_func(arg))\
if isinstance(arg, tensor_type) else arg for arg in args)
return tvm_func(*args)
return _wrapper
def to_pytorch_func(tvm_func):
import torch
import torch.utils.dlpack
return convert_func(tvm_func, torch.Tensor, torch.utils.dlpack.to_dlpack)