深度学习模型部署与优化:策略与实践;L40S与A100、H100的对比分析
★深度学习、机器学习、生成式AI、深度神经网络、抽象学习、Seq2Seq、VAE、GAN、GPT、BERT、预训练语言模型、Transformer、ChatGPT、GenAI、多模态大模型、视觉大模型、TensorFlow、PyTorch、Batchnorm、Scale、Crop算子、L40S、A100、H100、A800、H800
随着生成式AI应用的迅猛发展,我们正处在前所未有的大爆发时代。在这个时代,深度学习模型的部署成为一个亟待解决的问题。尽管GPU在训练和推理中扮演着关键角色,但关于它在生成式AI领域的误解仍然存在。近期英伟达L40S GPU架构成为了热门话题,那么与A100和H100相比,L40S有哪些优势呢?
生成式AI应用进入大爆发时代
一、驱动因素:大模型、算力与生态的共振
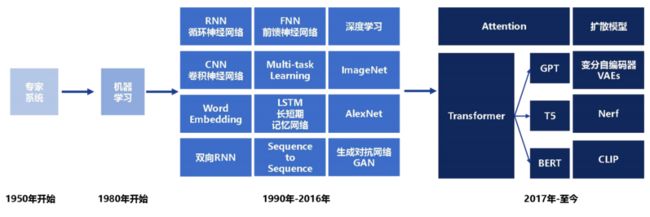
生成式AI起源于20世纪50年代Rule-based的专家系统,虽具备处理字符匹配、词频统计等简单任务的能力,但词汇量有限,上下文理解欠佳,生成创造性内容的能力非常薄弱。
80年代机器学习的兴起为AI注入新动力,90年代神经网络的出现使其开始模仿人脑,从数据中学习生成更真实内容的能力。当代生成式AI的核心技术起源于2012年后深度神经网络结构的不断深化,模型通过层层抽象学习任务的复杂特征表示,进而提高准确性和真实性。
随后几年,Seq2Seq、VAE、GAN等一系列算法的成熟,以及计算能力和数据规模的增长,使大模型训练成为可能,让生成式AI发展产生质的飞跃。特别是GPT、BERT等预训练语言模型的诞生,标志着文本生成领域迈入新的阶段。
人工智能产业发展浪潮
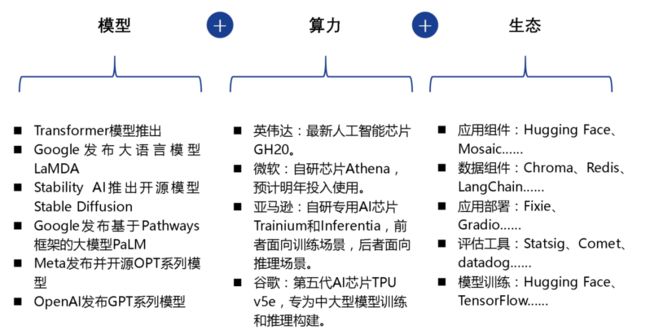
1、模型、算力、生态推动 AI 应用进入大爆发时代
1)算法及模型的快速进步
GenAI在文本领域取得重大进展,随着2017年Transformer模型的发布和2022年ChatGPT的推出,其多项能力已经超越人类基准。未来,更强大的语言大模型如GPT-5以及多模态大模型和视觉大模型的技术突破,将继续推动AI应用的持续进化。
2)算力基础设施将更快、更便宜
虽然短期内大模型训练需求的激增导致算力成本的持续上涨,但是随着英伟达算力芯片的不断更新迭代,微软、亚马逊、谷歌等在 AI 云服务资本开支的不断加大,AI 应用的发展将得到更加强有力的支撑。
3)AI 生态的逐渐成熟
AI 组件层(AI Stack)的完善和产业分工细化,为 AI 应用在模型训练、数据整合、应用开发、应用部署等环节提供全生命周期的支撑。
模型、算力、生态推动为 AI 应用进入大爆发时代
目前,GPT-4在推理、生成、对话等多个维度上已经超过人类水平。其强大不仅在于文本,更在于大模型框架本身就可适用于各种任务,成为包括图像、代码、音频等在内的多模态生成的统一技术基础。

GPT-4 是目前最强大的大模型
二、产业现状:一二级视角看 AI 应用的演进
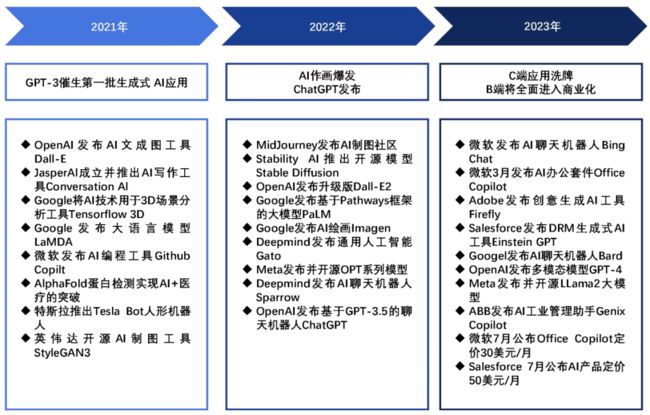
生成式AI应用的发展经历三个阶段:
1、GPT-3催生期
GPT-3强大的语言生成能力,使第一批像Jasper AI的生成式AI应用得以在2021年诞生,并迅速增长用户和收入。
2、2022年爆发期
这一年AI作画应用层出不穷,代表作有MidJourney和Stable Diffusion等。同时ChatGPT的发布标志着文本生成进入新的高度。视频、3D等其他模态的生成能力也在提升。
3、2023年商业化期
GPT-4进一步提升语言模型能力,而开源模型Llama提供低成本选择。各行业的AI应用如雨后春笋般涌现,Microsoft和Salesforce等巨头公布了AI产品的商业定价,预示着AI应用正式步入商业化。
生成式 AI 应用的发展阶段
三、应用框架:应用的四大赛道与产业逻辑
生成式AI应用可分为工具类、通用软件类、行业软件类和智能硬件类。工具类应用如聊天机器人主要服务C端,同质化严重,对底层模型高度依赖。通用软件类应用如办公软件,标杆产品已经出现,将进入商业化阶段。行业软件类面向特定垂直领域,如金融和医疗,行业差异大,数据挖掘是核心竞争力。智能硬件类应用如自动驾驶,感知和决策是瓶颈,需要底层技术突破。从工具类到智能硬件类,应用呈现从通用到专业、从C端到B端的演进趋势,竞争核心也从对模型依赖向数据应用和底层技术创新转变。这标志着生成式AI应用正在朝着成熟和落地方向发展。
生成式 AI 应用产业地图
生成式AI的三大底层元能力是感知、分析和生成。当前以文本理解为主,未来会延伸到图像视觉感知。分析能力将从信息整合走向复杂推理。生成能力也会从文本拓展到图片、视频等多模态内容。通过这三大能力的协同提升,生成式AI将实现跨模态的统一感知、理解和创造,向着对真实世界的全面理解与创造性反应的方向演进,以达到更强大的智能水平。
生成式AI未来发展有四大方向:内容生成、知识洞察、智能助手和数字代理。内容生成是核心价值,通过提升大模型和多模态技术实现更广泛内容的自动化生成。知识洞察利用大模型分析数据提供洞见,服务决策。智能助手将AI能力嵌入场景中主动协作。数字代理基于环境自主决策和行动达成目标。从被动服务到主动作为,生成式AI正朝着具备内容创造、洞悉世界、智能协作及自主行动的更高智能方向演进。

AI 细分应用的标杆产品与发展路径
深度学习模型如何部署
训练出的模型需要经过优化和调整,以转化为标准格式的推理模型,以便在部署中使用。优化包括算子融合、常量折叠等操作,以提高推理性能。由于部署目标场景各异,需要根据硬件限制来选择合适的模型格式。为了适应硬件限制,可能需要使用模型压缩或降低精度等方法。模型部署后,推理时延和占用资源是关键指标,可以通过定制化芯片和软硬协同优化等方式进行改进。在软件优化中,需要考虑到数据布局、计算并行等因素,并针对CPU架构进行设计。模型是企业的重要资产,因此部署后必须确保其安全性。总之,模型从训练到部署需要经历多个过程,包括转化优化、规模调整和软硬协同等,以确保适应不同场景的资源限制、性能指标和安全要求,并充分发挥模型的价值。
针对上述模型部署时的挑战,业界有一些常见的方法:
-
算子融合
通过表达式简化、属性融合等方式将多个算子合并为一个算子的技术,融合可以降低模型的计算复杂度及模型的体积。
-
常量折叠
将符合条件的算子在离线阶段提前完成前向计算,从而降低模型的计算复杂度和模型的体积。
-
模型压缩
通过量化、剪枝等手段减小模型体积以及计算复杂度的技术,可以分为需要重训的压缩技术和不需要重训的压缩技术两类。
-
数据排布
根据后端算子库支持程度和硬件限制,搜索网络中每层的最优数据排布格式,并进行数据重排或者插入数据重排算子,从而降低部署时的推理时延。
-
模型混淆
对训练好的模型进行混淆操作,主要包括新增网络节点和分支、替换算子名的操作,攻击者即使窃取到混淆后的模型也不能理解原模型的结构。此外,混淆后的模型可以直接在部署环境中以混淆态执行,保证模型在运行过程中的安全性。
一、训练模型到推理模型的转换及优化
1、模型转换
不同的模型训练框架如TensorFlow和PyTorch都有各自的数据结构定义,这给模型部署带来了一定的不便。为解决这个问题,业界开发开放的神经网络交换格式ONNX。它具有强大的表达能力,支持各种运算符,并提供不同框架到ONNX的转换器。
模型转换的本质是在不同的数据结构之间传递结构化信息。因此,需要分析两种结构的异同点,对相似的结构部分进行直接映射,而对差异较大的部分则要根据语义找出合理的转换方式。如果存在不兼容的情况,则无法进行转换。
ONNX的优势在于其强大的表达能力,大多数框架的模型都可以转换到ONNX上,从而避免了不兼容的问题。作为中间表示格式,ONNX成为不同框架和部署环境之间的桥梁,实现模型的无缝迁移。
模型可以抽象为一种图,从而模型的数据结构可以解构为以下两个要点:
1)模型拓扑连接
从图论角度看是图的边,对应模型中的数据流和控制流。决定子图表达、输入输出以及控制流结构。不同框架对此有不同表示,需要进行等价转换。如TensorFlow的循环控制流转为ONNX的While、If算子,避免引入环。
2)算子原型定义
从图论角度看是图的顶点,对应模型的运算单元。包括算子类型、输入输出、属性等。不同框架的算子虽然名称相同,但语义不一致。因此需要解析语义等价性,进行适当映射。例如Caffe的Slice算子需要转为ONNX的Split。没有完全等价算子也需要组合表达。
模型转换完成后,会进行各种优化来提前完成一些常量计算,合并相关的算子,用更强大的算子替换多个简单算子,根据依赖关系重排算子等。这些算子融合、折叠、替换、重排的优化手段和编译器进行的优化非常类似,目的都是提前计算,减少运算量,增强并行度。之所以只能在部署阶段进行彻底优化是因为只有这个时段才能确定硬件后端和运行环境。模型部署阶段的优化能够有效压缩模型大小,减少计算量,提升执行效率。与编译优化思路一脉相承都遵循提前计算、融合运算、调整布局的策略,以更好地发挥硬件性能。
2、算子融合
算子融合是一种模型压缩技术,其核心思想是合并多个相关的算子成一个算子。在深度学习模型中,大量重复的计算和频繁的内存访问会导致推理延迟和能耗问题。算子融合通过解析模型拓扑结构,找出可以合并的算子节点,按照一定规则将其“融合”为新的算子。这相当于在图论中的“合同图”,可以有效减少节点数量和边数量。减少节点数量意味着运算步骤更少,减少边数量意味着内存访问更少。因此,算子融合技术可以减小模型的计算复杂度和存储占用,从而降低模型推理时的时延和功耗。

计算机分层存储架构
算子融合的性能提升主要源自两点:
1)充分利用缓存,减少内存访问
CPU寄存器和多级缓存速度远快于内存,融合后一次计算结果可暂存至高速缓存,供下一计算直接读取,省去内存读写的开销。
2)提前计算,消除冗余
多次相同计算可以预先完成,避免在前向推理时重复运算,特别是循环中的重复计算。CPU与内存之间存在巨大的速度鸿沟。靠近CPU的缓存越小且越快,内存越大越慢。算子融合通过合并操作,充分利用缓存加速重复计算,并消除冗余,减少内存访问次数。这是其能明显减小时延和功耗的根本原因。
3、算子替换
算子替换旨在将模型中的算子替换为计算逻辑相同但更适合在线部署的算子。该技术通过数学方法如合并同类项和提取公因式,简化算子的计算公式,并将简化后的公式映射到一类更高效的算子上。通过算子替换,可以实现降低计算量和模型大小的效果。
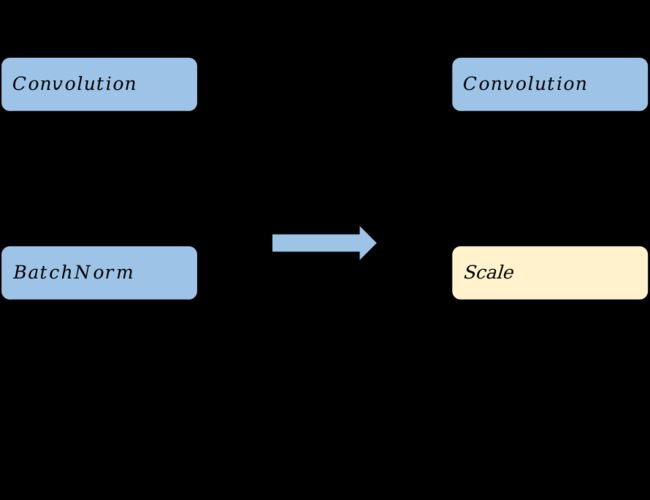
Batchnorm算子替换
通过将Batchnorm算子替换为Scale算子,可以在模型部署阶段优化功耗和性能。然而需要注意的是,这种优化策略只适用于部署阶段,因为在训练阶段,Batchnorm算子中的参数被视为变量而不是常量。此外,这种优化策略会改变模型的结构,降低模型的表达能力,并且可能影响模型在训练过程中的收敛性和准确率。
4、算子重排
算子重排通过重新排布模型中算子的拓扑序来减少模型推理的计算量,同时保持推理精度不变。常见的算子重排技术包括将裁切类算子(如Slice、StrideSlice、Crop等)向前移动,对Reshape和Transpose算子进行重排,以及对BinaryOp算子进行重排。这些技术的目标是通过重新组织算子的计算顺序,减少不必要的计算和数据传输,从而提高模型的推理效率。
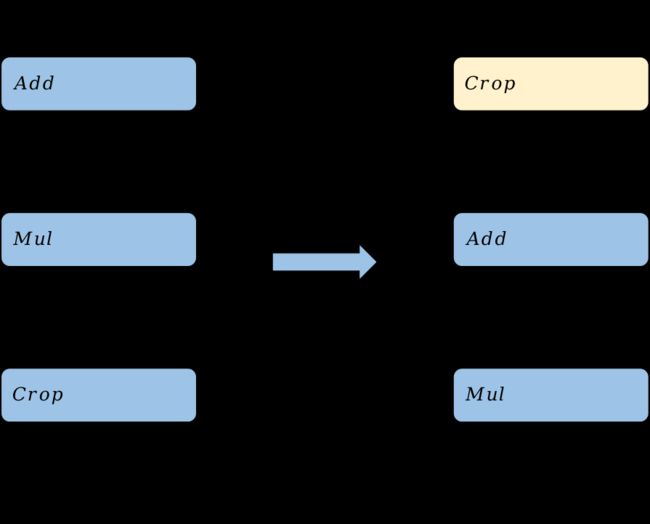
Crop算子重排
通过将Crop算子的裁切过程前移,即在模型中提前对特征图进行裁切,可以降低后续算子的计算量,从而提高模型在部署阶段的推理性能。这种优化策略的性能提升取决于Crop算子的参数设置。然而需要注意的是,只有element-wise类算子才能进行前移操作。根据之前的实验数据,可以看出,在模型部署前进行优化可以显著提升推理的时延、功耗和内存占用效果。
二、模型压缩
针对不同硬件环境的需求差异,比如在手机等资源受限的设备上部署模型时,对模型大小通常有严格的要求,一般要求在几兆字节的范围内。因此,对于较大的模型,通常需要采用一些模型压缩技术,以满足不同计算硬件的需求。这些技术可以通过减少模型参数、降低模型复杂度或使用量化等方法来实现。通过模型压缩,可以在保持模型性能的同时,减小模型的存储空间和计算开销,从而更好地适应不同的硬件平台。
1、量化
模型量化通过以较低的推理精度损失来表示连续取值的浮点型权重。通过使用更少的位数来表示浮点数据,模型量化可以减小模型的尺寸,从而减少在推理过程中的内存消耗。此外,在一些支持低精度运算的处理器上,模型量化还可以提高推理速度。
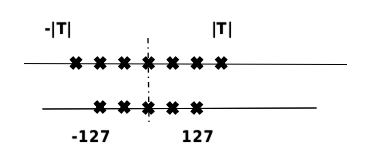
量化原理
在计算机中,不同数据类型的占用比特数和表示范围不同。通过将模型的参数量化为不同位数的数据类型,可以根据实际需求来降低模型的存储大小。一般来说,深度神经网络中的参数使用单精度浮点数表示,但如果可以近似使用有符号整数来表示参数,那么量化后的权重参数存储大小可以减少到原来的四分之一。量化位数越少,模型压缩率越高。
此外,根据量化方法是否使用线性或非线性量化,可以进一步将量化方法分为线性量化和非线性量化。实际深度神经网络中,权重和激活值通常是不均匀的,因此理论上,非线性量化可以更准确地表示这些值,从而减小精度损失。然而,在实际推理中,非线性量化的计算复杂度较高,因此通常使用线性量化来进行模型量化。
1)量化感知训练
量化感知训练是一种在训练过程中模拟量化的方法,通过在模型中插入伪量化算子来模拟量化操作。在每次训练迭代中,量化感知训练会计算量化网络层的权重和激活值的范围,并将量化损失引入前向推理和反向传播的过程中。通过这种方式,优化器可以在训练过程中尽量减少量化误差,从而获得更高的模型精度。
具体而言,量化感知训练的流程如下:
-
初始化:设置权重和激活值的范围,并初始化网络的权重和激活值。构建模拟量化网络:在需要量化的权重和激活值后插入伪量化算子,以模拟实际量化操作。
-
量化训练:重复以下步骤直到网络收敛。a. 计算量化网络层的权重和激活值的范围。b. 根据范围将量化损失带入前向推理和反向传播的过程中,以更新网络的参数。
-
导出量化网络:获取量化网络层的权重和激活值的范围,并计算量化参数。将量化参数代入量化公式中,将网络中的权重转换为量化整数值。最后,删除伪量化算子,并在量化网络层前后分别插入量化和反量化算子,以得到最终的量化网络。
通过量化感知训练,可以在减小模型尺寸的同时,尽量保持模型的精度,并在低精度运算较快的处理器上获得更快的推理速度。
2)训练后量化
在训练后的量化中,有两种常见的方法:权重量化和全量化。
权重量化仅对模型的重进行量化,以减小模型的大小。在推理时,将量化后权重反量化为原始的float32数据,并使用普通的float32算子进行推理。权重量化的好处是不需要校准数据集,不需要实现量化算子,并且模型的精度误差较小。然而,由于实际推理仍使用float32算子,推理性能不会提高。
全量化不仅量化模型权重,还量化模型激活值,通过执行量化算子来加速推理过程。为量化激活值,需要提供一定数量校准数据集,用于统计每一层激活值的分布,并对量化算子进行校准。校准数据集可以来自训练数据集或真实场景的输入数据,通常数量很小。
在量化激活值时,首先使用直方图统计原始float32数据的分布。然后,在给定的搜索空间中选择适当的量化参数,将激活值量化为量化后的数据。接下来,使用直方图统计量化后的数据分布,并计算量化参数,以度量量化前后的分布差异。
此外,由于量化存在固有误差,需要校正量化误差。例如,在矩阵乘法中,需要校正量化后的均值和方差,以使其与float32算子一致。通过对量化后的数据进行校正,可以保持量化后的分布与量化前一致。
量化方法作为一种通用的模型压缩方法,可以显著提高神经网络存储和压缩的效率,并已经被广泛应用。
2、模型稀疏
稀疏模型是一种通过减少神经网络中的组件来降低存储和计算成本的方法。它是一种为了降低模型计算复杂度而引入的强归纳偏差,类似于模型权重量化、权重共享和池化等方法。
1)模型稀疏的动机
稀疏模型的合理性可以从两个方面解释。
-
现有的神经网络模型通常存在过多的参数,这导致模型过于复杂和冗余。
-
对于许多视觉任务来说,激活值特征图中有用的信息只占整个图像的一小部分。
基于这些观察,稀疏模型可以通过去除权重或激活值中弱连接来减少冗余。具体而言,稀疏模型会根据连接的强度(通常是权重或激活的绝对值大小)对一些较弱的连接进行剪枝,将它们置为零。这样可以提高模型的稀疏度,并降低计算和存储的需求。
然而,需要注意的是,稀疏模型的稀疏度越高,模型的准确率下降可能会越大。因此,稀疏模型的目标是在提高稀疏度的同时尽量减小准确率的损失。
2)结构与非结构化稀疏
权重稀疏可以分为结构化和非结构化稀疏。结构化稀疏通过在通道或卷积核层面对模型进行剪枝,得到规则且规模更小的权重矩阵。这种稀疏方式适合在CPU和GPU上进行加速计算,但准确率下降较大。非结构化稀疏可以对权重矩阵中任意位置的权重进行裁剪,准确率下降较小。然而,非结构化稀疏的不规则性导致难以利用硬件加速,并带来指令层面和线程层面的并行度下降,以及访存效率降低的问题。为了克服这些问题,最近的研究提出了结合结构化和非结构化稀疏的方法,以兼具两者的优点并解决其缺点。
3)稀疏策略
稀疏模型的具体策略包括预训练、剪枝和微调。预训练是指首先训练一个稠密模型,然后在此基础上进行稀疏和微调。剪枝是指根据一定的规则或标准,去除模型中的冗余权重,使模型更加稀疏。剪枝可以一次性进行,也可以与训练交替进行,逐步发现冗余的部分。微调是指在剪枝后对模型进行进一步的训练,以恢复稀疏模型的准确性。
以Deep Compression为例,剪枝后的稀疏模型可以进一步进行量化,即使用更低比特的数据来表示权重。此外,结合霍夫曼编码可以进一步减小模型的存储空间。这些策略的综合应用可以显著降低模型的存储需求,同时保持较高的准确性。
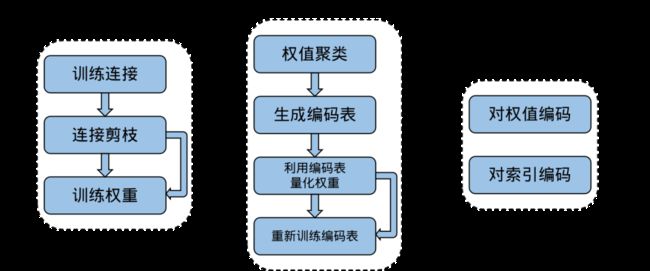
Deep Compression
除了直接去除冗余的神经元之外,还可以使用基于字典学习的方法来去除深度卷积神经网络中无用的权值。这种方法通过学习一系列卷积核的基,将原始卷积核变换到系数域上,并且使其变得稀疏。例如,Bagherinezhad等人提出了一种方法,将原始卷积核分解成卷积核的基和稀疏系数的加权线性组合。通过这种方式,可以有效地去除网络中不必要的权值,从而减少模型的存储需求和计算复杂度。
3、知识蒸馏
教师-学生神经网络学习算法,也称为知识蒸馏。在实践中,大型深度网络通常能够获得出色的性能,因为过度参数化有助于提高模型的泛化能力。在知识蒸馏中,通常使用一个较大的神经网络作为教师网络,已经经过预训练并具有较高的准确性。然后,将一个全新的、更深、更窄的神经网络作为学生网络,通过监督学习的方式将教师网络的知识传授给学生网络。知识蒸馏的关键在于如何有效地将教师网络的知识转移到学生网络中,从而提高学生网络的性能和泛化能力。

一种基于感知(attention)的教师神经网络-学生神经网络学习算法
知识蒸馏是一种有效的方法,可以帮助小网络进行优化,并且可以与剪枝、量化等其他压缩方法结合使用。通过知识蒸馏可以训练出具有高精度和较小计算量的高效模型。这种综合应用可以显著减小模型的复杂性,同时保持较高的性能。
四、模型推理
将训练好的模型部署到计算硬件上进行推理时,需要经历几个关键步骤:
-
前处理:将原始数据进行预处理,使其适合输入到网络中进行推理。
-
推理执行:将经过训练和转换的模型部署到设备上,通过输入数据进行计算,得到输出数据。
-
后处理:对模型的输出结果进行进一步的处理,例如应用筛选阈值或其他后处理操作,以获得最终的结果。
这些步骤是将训练好的模型应用到实际场景中的关键环节,确保模型能够正确地处理输入数据并生成准确的输出。
1、前处理与后处理
1)前处理
在机器学习中,数据预处理是一个关键的步骤,它的目的是将原始数据转换为适合模型输入的形式,并消除其中的噪声和无关信息,以提高模型的性能和可靠性。
数据预处理通常包括以下几个方面:
-
特征编码:将原始数据转换为机器学习模型可以处理的数字形式。这涉及到将不同类型的数据(如文本、图像、音频等)转换为数值表示,例如使用独热编码、序号编码等方法。
-
数据归一化:将数据进行标准化处理,使其具有相同的尺度和范围,消除不同特征之间的量纲差异。常见的归一化方法包括最小-最大缩放和Z-score标准化。
-
处理离群值:离群值是与其他数据点相比具有显著不同的异常值,可能会对模型的性能产生负面影响。因此,可以通过检测和处理离群值来提高模型的准确性和鲁棒性。
通过数据预处理,我们可以提取和凸显有价值的特征,同时去除无关信息和噪声,为模型提供更好的输入,从而改善模型的性能和泛化能力。
2)后处理
在模型推理完成后,通常需要对输出数据进行后处理,以获得更可靠和有用的结果。常见的数据后处理手段包括:
-
离散化连续数据:如果模型的输出是连续值,但实际应用需要离散值,可以使用四舍五入、取阈值等方法将连续数据转换为离散数据,以得到实际可用的结果。
-
数据可视化:通过将数据以图形或表格的形式呈现,可以更直观地理解数据之间的关系和趋势,从而决定下一步的分析策略。
-
手动调整预测范围:某些情况下,回归模型可能无法准确预测极端值,而结果集中在中间范围。在这种情况下,可以手动调整预测范围,通过乘以一个系数来放大或缩小预测结果,以获得更准确的预测结果。
这些后处理手段可以进一步优化模型的输出结果,使其更符合实际应用需求,并提供更有用的信息供用户决策和分析。
2、并行计算
为了提高推理性能,推理框架通常会使用多线程机制来利用多核处理器的能力。这种机制的主要思想是将输入数据切分成多个小块,并使用多个线程并行地执行算子计算。每个线程负责处理不同的数据块,从而实现算子的并行计算,大大提高了计算性能。通过这种方式,可以充分利用多核处理器的计算能力,加速推理过程,提高系统的响应速度。
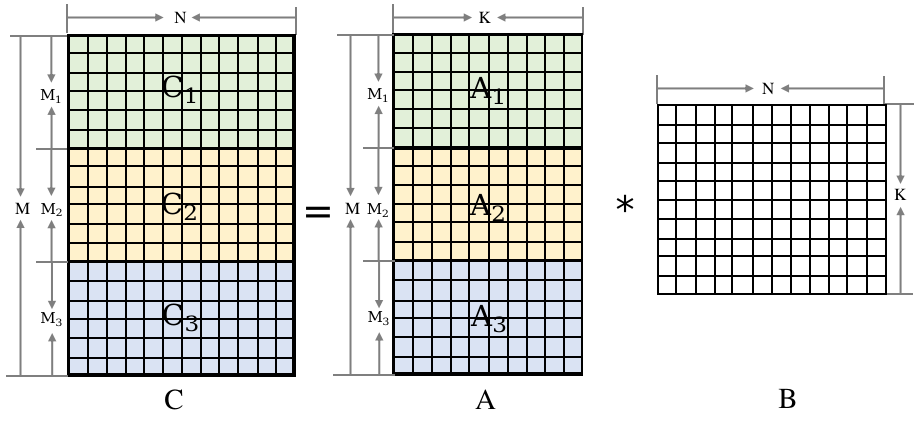
矩阵乘数据切分
为了实现矩阵乘的多线程并行计算,可以按照左矩阵的行进行切分,并使用线程池机制来方便地进行算子并行计算。在业界,有两种常用的做法:
1)使用OpenMP编程接口,它提供了一套跨平台的共享内存多线程并发编程API。通过使用OpenMP的"parallel for"接口,可以实现对for循环体的代码进行多线程并行执行。
2)推理框架自己实现针对算子并行计算的线程池机制。相对于使用OpenMP接口,推理框架的线程池可以更加针对性地实现算子的并行计算,从而提供更高的性能和更轻量的实现。
3、算子优化
对于深度学习网络而言,框架调度所占用的时间往往很少,性能的瓶颈通常出现在算子的执行过程中。为提高性能,可以从硬件指令和算法两个角度对算子进行优化。
从硬件指令角度来看,可以利用特定的硬件指令集,例如SIMD(单指令多数据)指令集,来并行处理多个数据。这样可以减少指令的执行次数,提高计算效率。另外,还可以使用硬件加速器,如GPU(图形处理器)或TPU(张量处理器),来加速算子的执行。
从算法角度来看,可以通过优化算法的实现方式来提高性能。例如,可以使用更高效的矩阵乘法算法,减少乘法和加法的次数。还可以使用近似计算方法,如量化(将浮点数转换为整数)或剪枝(删除不重要的权重),来减少计算量和存储需求。
1)硬件指令优化
绝大多数的设备上都有CPU,因此算子在CPU上的时间尤为重要。
-
汇编语言
高级编程语言通过编译器将代码转换为机器指令码序列,但其功能受限于编译器能力。相比之下,汇编语言更接近机器语言,可以直接编写特定的指令码序列。汇编语言编写的程序占用的存储空间较少,执行速度更快,效率也更高。
在实际应用中,通常使用高级编程语言编写大部分代码,而对于性能要求较高的部分,可以使用汇编语言编写,从而实现优势互补。在深度学习中,卷积和矩阵乘等算子涉及大量计算,使用汇编语言编写这些算子可以显著提高模型训练和推理的性能,通常能够实现数十到数百倍的性能提升。
-
寄存器与NEON指令
在ARMv8系列的CPU上,有32个NEON寄存器,每个寄存器可以存放128位的数据。这意味着每个寄存器可以存储4个float32数据、8个float16数据或16个int8数据。这些寄存器可以用于并行处理多个数据,从而提高计算效率。
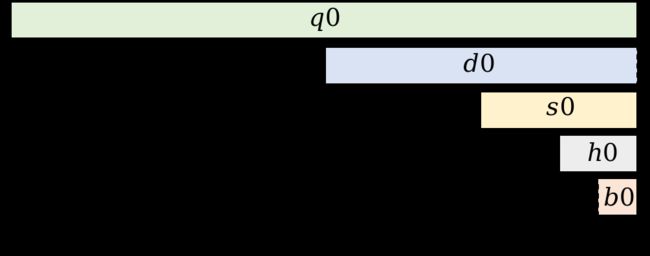
ARMv8处理器NEON寄存器v0的结构
NEON指令集是针对ARMv8系列处理器的一种特殊指令集,允许同时对多个数据进行操作,从而提高数据存取和计算的速度。与传统的单数据操作指令相比,NEON指令可以一次性处理多个数据。
例如,NEON的fmla指令可以同时对多个寄存器中的浮点数进行乘法和累加操作。指令的用法类似于"fmla v0.4s, v1.4s, v2.4s",其中v0、v1和v2分别表示NEON寄存器,".4s"表示每个寄存器中有4个float值。这条指令的作用是将v1和v2两个寄存器中相应位置的float值相乘,并将结果累加到v0寄存器中的对应位置。
通过使用NEON指令集,开发者可以充分利用处理器的并行计算能力,以更高效的方式处理大量数据。这种并行计算的优势可以在许多应用中得到体现,特别是在涉及大规模矩阵运算、图像处理和信号处理等领域。

fmla指令计算功能
-
汇编语言优化
在编写汇编语言程序时,可以采取一些优化策略来提高程序的性能,特别是通过提高缓存命中率来加速数据访问。
一种常见的优化策略是循环展开,通过使用更多的寄存器来减少内存访问,从而提高性能。另外,指令重排也是一种有效的优化方法,通过重新安排指令的执行顺序,使得流水线能够更充分地利用,减少延迟。
在使用NEON寄存器时,合理地分块寄存器可以减少寄存器空闲时间,增加寄存器的复用率。此外,通过重排计算数据的存储顺序,可以提高缓存命中率,尽量保证读写指令访问的内存是连续的。
最后,使用预取指令可以将即将使用的数据提前从主存加载到缓存中,以减少访问延迟。这些优化策略的综合应用可以显著提高程序的性能,使其达到数十到数百倍的提升。
五、模型的安全保护
模型的安全保护可以分为静态保护和动态保护两个方面。静态保护主要关注模型在传输和存储时的安全性,目前常用的方法是对模型文件进行加密,以密文形式传输和存储,并在内存中解密后进行推理。然而,这种方法存在内存中明文模型被窃取的风险。
动态保护则是在模型运行时进行保护,目前有三种常见的技术路线。一种是基于TEE(Trusted Execution Environment)的保护方案,通过可信硬件隔离出安全区域,在其中解密和运行模型。这种方案对推理时延影响较小,但需要特定的硬件支持,并且对大规模深度模型的保护有一定限制。另一种是基于密态计算的保护方案,利用密码学方法保持模型在传输、存储和运行过程中的密文状态。
这种方案不依赖特定硬件,但会带来较大的计算和通信开销,并且无法保护模型的结构信息。第三种是基于混淆的保护方案,通过对模型的计算逻辑进行加扰,使得即使敌对方获取到模型也无法理解其内部结构。相比前两种方案,混淆方案的性能开销较小,且精度损失较低,同时不依赖特定硬件,可以支持对大模型的保护。
模型混淆技术是一种能够自动混淆明文AI模型计算逻辑的方法,使得攻击者在传输和存储过程中即使获得了模型也无法理解其内部逻辑。同时,该技术还可以保证模型在运行时的机密性,并且不会影响模型原本的推理结果,只带来较小的推理性能开销。
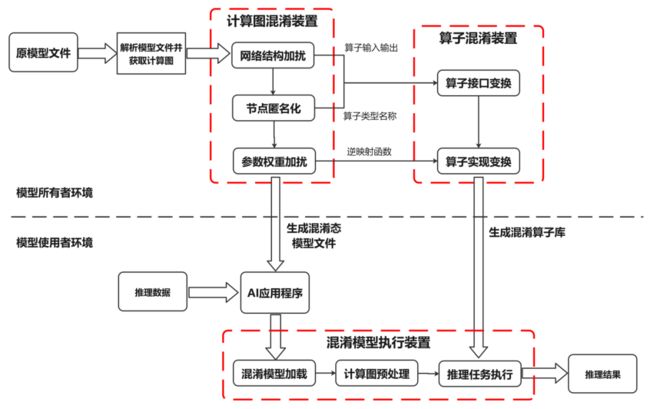
模型混淆实现步骤图
结合上图,详细阐述模型混淆的执行步骤:
对于一个已经训练好的模型,首先需要对其模型文件进行解析,并据此获取模型计算逻辑的图形表达形式(计算图),以便进行后续操作。这个计算图包括了节点标识符、节点运算符类型、节点参数权重以及网络结构等信息。
在完成获取计算图之后,可以通过图压缩和图扩展等技术,对计算图中节点与节点之间的依赖关系进行混淆处理,以此隐藏模型真实的计算逻辑。图压缩主要是通过检查整图来匹配原始网络中的关键子图结构,并将这些子图压缩并替换为单个新的计算节点。在压缩后的计算图上,图扩展通过在网络结构中添加新的输入/输出边,进一步隐藏节点间的真实依赖关系。这些新添加的输入/输出边可以来源于/指向现有的节点,也可以来源于/指向本步骤新增的混淆节点。
接着,为了进一步达到模型混淆的效果,还可以对计算图进行加扰处理。常用的加扰手段包括添加冗余的节点和边、融合部分子图等。这些操作都是为了达到模型混淆的目的。
然后,在完成上述步骤后,需要遍历处理后的计算图,筛选出需要保护的节点。对于这些节点,将节点标识符、节点运算符类型以及其他能够描述节点计算逻辑的属性替换为无语义信息的符号。对于节点标识符的匿名化处理,需要保证匿名化后的节点标识符仍然是唯一的,以便区分不同的节点。对于运算符类型的匿名化处理,为了避免大规模计算图匿名化导致运算符类型的爆炸问题,可以将计算图中同种运算符类型的节点划分为若干不相交的集合,同一个集合中的节点的运算符类型替换为相同的匿名符号。这样就能保证在节点匿名化后,模型仍然能够被识别和执行。
之后,对于每个需要保护的权重,通过一个随机噪声和映射函数来对它们进行加扰处理。每个权重在加扰时都可以使用不同的随机噪声和映射函数,同时这些加扰操作需要保证不会影响到模型执行结果的正确性。
完成以上步骤后,将经过处理后的计算图保存为模型文件以供后续使用。同时,对于每个需要保护的算子类型,需要对其进行形态变换并生成若干候选混淆算子。原本的算子与混淆算子之间是一对多的对应关系,而候选混淆算子的数量等于之前步骤中划分的节点集合的数量。在此基础上,根据之前步骤(2)(3)(4)得到的匿名化算子类型、算子输入/输出关系等信息,可以对相应的算子的接口进行变换。算子接口的变换方式包括但不限于输入输出变换、接口名称变换。其中,输入输出变换主要通过修改原算子的输入输出数据实现,而接口名称变换则是将原算子名称替换为之前步骤中生成的匿名化算子名称。这样能保证在节点匿名化后,模型仍然能够被识别和执行,同时算子的名称也不会泄露其计算逻辑。
此外,还需要对算子的代码实现进行变换。这种代码实现的变换方式包括但不限于字符串加密、冗余代码等软件代码混淆技术。这些混淆技术可以保证混淆算子与原算子实现语义相同的计算逻辑,但同时也会使得混淆后的算子难以阅读和理解。需要注意的是,不同的算子可以采用不同组合的代码混淆技术进行代码变换。另外,在步骤(4)中提到的参数被加扰的算子,其混淆算子也需实现权重加扰的逆映射函数,以便在算子执行过程中动态消除噪声扰动,并保证混淆后模型的计算结果与原模型一致。
之后,将生成的混淆算子保存为库文件供后续使用。这些库文件包含了所有需要的混淆算子和它们的代码实现。
完成上述所有步骤后,将混淆态模型文件以及相应的混淆算子库文件部署到目标设备上。这样就可以准备执行模型推理任务了。
在执行推理任务前,首先需要根据模型结构解析混淆态模型文件以获取模型计算逻辑的图形表达(即混淆计算图)。
然后需要对这个混淆计算图进行初始化处理,生成执行任务序列。根据安全配置选项的要求,如果需要保护模型在运行时的安全,那么可以直接对这个混淆计算图进行初始化处理;如果只需要保护模型在传输和存储时的安全,那么可以先将内存中的混淆计算图恢复为原计算图,然后对原计算图进行初始化处理生成执行任务序列。这个任务序列中的每个计算单元对应一个混淆算子或原算子的执行。这样做可以进一步降低推理时的性能开销。
最后,根据AI应用程序输入的推理数据,遍历执行任务序列中的每个计算单元并得到推理结果。如果当前计算单元对应的算子是混淆算子,那么就调用混淆算子库;否则就调用原算子库。这样就可以完成整个推理任务。
GPU在生成式
AI领域的误解
生成式AI激发了我们的想象力,在各领域从预测性维护、患者诊断到客户支持等展现出了前所未有的潜力。这种潜力依赖于GPU提供的加速计算能力,使其能够高效训练复杂语言模型。然而,对GPU的过度简化或盲目信仰可能导致预期之外的问题,延误甚至失败数据科学项目。下面是在构建AI项目时需要避免的五个关于GPU的误解。
一、GPU正在提供最快的结果
在GPU之前,每个时间步骤大约有70%的时间被用于数据复制,以完成数据流程的各个阶段。GPU可以通过实现大规模并行计算,显著降低基础设施成本,并为端到端数据科学工作流提供卓越性能。12个NVIDIA GPU可以提供相当于2000个现代CPU的深度学习性能。若向同一服务器添加8个额外的GPU,则可提供多达55000个额外的核心。尽管GPU加速了计算过程,但研究指出它们可能会花费一半的时间等待数据,这意味着最终需要等待结果。为充分运用GPU的计算能力,需要更强大的网络与存储支持。
二、带宽为王,向带宽致敬
虽然带宽是优化GPU使用的关键指标,但并不能准确反映AI工作负载的所有特性。优化数据流程需要考虑更多,而不仅仅是传输大量数据到GPU,IOPs和元数据同样重要。不同的数据流程步骤有不同的IO需求,可能导致传统存储无法满足。
除了带宽,还需要考虑IOPS、延迟和元数据操作等性能特性。某些步骤需要低延迟和随机小IO,有些则需要大规模的流媒体带宽,还有一些需要同时进行两者的并发混合。多个数据流程同时运行,增加了同时处理不同IO配置文件的需求。
三、GPU驱动的AI工作负载在处理小文件时始终面临挑战
训练大语言模型用于大多数生成式AI应用涉及大量小文件,如数百万小图片和每个IoT设备的日志等数据。ETL工作流程会规范数据并使用随机梯度下降训练模型,这导致大规模的元数据和随机读取问题,特别是在AI深度学习流程的第一部分中有许多小IO请求,许多存储平台无法有效处理。
四、存储?GPU的重点在于计算能力
AI工作负载对性能、可用性和灵活性有特殊需求,传统存储平台难以满足。选择适合AI工作负载的存储解决方案对满足业务需求有显著影响。成功的AI项目在计算和存储需求方面往往迅速增长,因此需要仔细考虑存储选择的影响。然而,大多数AI基础设施的关注和投入集中在GPU和网络上,存储设备的预算所剩无几。对于AI存储来说,性能在大规模上同样重要,不仅仅是满足传统的要求。
五、本地存储才是GPU最快的存储方式
随着AI数据集不断增大,数据加载时间成为工作负载性能瓶颈。从本地NVMe存储中检索数据可避免传输瓶颈和延迟,但服务器主机已无法满足GPU速度增长需求。GPU受到慢速IO制约。
英伟达L40S GPU架构及A100、H100对比
在SIGGRAPH 2023上,NVIDIA推出全新的NVIDIA L40S GPU和搭载L40S的NVIDIA OVX服务器。这些产品主要针对生成式人工智能模型的训练和推理,有望进一步提升生成式人工智能模型的训练和推理场景的计算效率。
L40S基于Ada Lovelace架构,配备48GB的GDDR6显存和846GB/s的带宽。在第四代Tensor核心和FP8 Transformer引擎的支持下,可以提供超过1.45 PFLOPS的张量处理能力。根据NVIDIA给出的数据,在微调和推理场景的测试用例下,L40S的计算效率比A100有所提高。

相较于A100 GPU,L40S在以下几个方面存在差异:
一、显存类型
L40S采用更为成熟的GDDR6显存技术,与A100和H100使用的HBM显存相比,虽然在显存带宽上有所降低,但技术成熟度高且市场供应充足。
二、算力表现
L40S在FP16算力(智能算力)方面较A100有所提高,而在FP32算力(通用算力)方面较A100有更为明显的提升,使其更适应科学计算等场景的需求。
三、能耗表现
相较于A100,L40S在功率上有所降低,这有利于降低数据中心的相关能耗,提高能源效率。
四、性价比较
根据Super Micro的数据,L40S在性价比上相较于A100具有优势,为希望部署高效且具有竞争力的生成式人工智能解决方案的用户提供更多选择。

L40S与A100、H100存在差异化设计
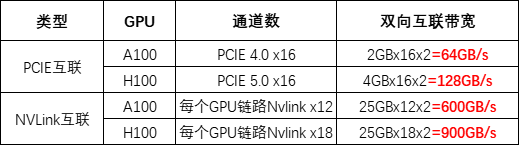
类似于A100,L40S通过16通道的PCIe Gen 4接口与CPU进行通信,最大双向传输速率为64 GB/s。然而,与L40S不同的是,NVIDIA Grace Hopper采用NVLink-C2C技术将Hopper架构的GPU与Grace架构的CPU相连,实现CPU到GPU、GPU到GPU间总带宽高达900 GB/s,比PCIe Gen 5快7倍。

PCIe协议对L40S的通信宽带有所限制
基于Ada Lovelace架构的L40S GPU,配备GDDR6显存和846GB/s带宽,并通过第四代Tensor核心和FP8 Transformer引擎提供超过1.45 PetaFLOPS的张量处理能力。针对计算密集型任务,L40S的18,176个CUDA核心可提供比A100高近5倍的单精度浮点性能,从而加速复杂计算和数据密集型分析。
此外,为支持专业视觉处理工作,如实时渲染、产品设计和3D内容创建,L40S还配备142个第三代RT核心,可提供212TFLOP的光线追踪性能。功耗达到350瓦。对于生成式AI工作负载,L40S相较于A100可实现高达1.2倍的推理性能提升和高达1.7倍的训练性能提升。在L40S GPU的加持下,英伟达还推出最多可搭载8张L40S的OVX服务器。英伟达方面宣布,对于拥有8.6亿token的GPT3-40B模型,OVX服务器只需7个小时就能完成微调;对于Stable Diffusion XL模型,则可实现每分钟80张的图像生成。
蓝海大脑大模型训练平台
蓝海大脑大模型训练平台提供强大的算力支持,包括基于开放加速模组高速互联的AI加速器。配置高速内存且支持全互联拓扑,满足大模型训练中张量并行的通信需求。支持高性能I/O扩展,同时可以扩展至万卡AI集群,满足大模型流水线和数据并行的通信需求。强大的液冷系统热插拔及智能电源管理技术,当BMC收到PSU故障或错误警告(如断电、电涌,过热),自动强制系统的CPU进入ULFM(超低频模式,以实现最低功耗)。致力于通过“低碳节能”为客户提供环保绿色的高性能计算解决方案。主要应用于深度学习、学术教育、生物医药、地球勘探、气象海洋、超算中心、AI及大数据等领域。

一、为什么需要大模型?
1、模型效果更优
大模型在各场景上的效果均优于普通模型
2、创造能力更强
大模型能够进行内容生成(AIGC),助力内容规模化生产
3、灵活定制场景
通过举例子的方式,定制大模型海量的应用场景
4、标注数据更少
通过学习少量行业数据,大模型就能够应对特定业务场景的需求
二、平台特点
1、异构计算资源调度
一种基于通用服务器和专用硬件的综合解决方案,用于调度和管理多种异构计算资源,包括CPU、GPU等。通过强大的虚拟化管理功能,能够轻松部署底层计算资源,并高效运行各种模型。同时充分发挥不同异构资源的硬件加速能力,以加快模型的运行速度和生成速度。
2、稳定可靠的数据存储
支持多存储类型协议,包括块、文件和对象存储服务。将存储资源池化实现模型和生成数据的自由流通,提高数据的利用率。同时采用多副本、多级故障域和故障自恢复等数据保护机制,确保模型和数据的安全稳定运行。
3、高性能分布式网络
提供算力资源的网络和存储,并通过分布式网络机制进行转发,透传物理网络性能,显著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用严格的权限管理机制,确保模型仓库的安全性。在数据存储方面,提供私有化部署和数据磁盘加密等措施,保证数据的安全可控性。同时,在模型分发和运行过程中,提供全面的账号认证和日志审计功能,全方位保障模型和数据的安全性。
三、常用配置
1、处理器CPU:
Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
AMD EPYC™ 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
AMD EPYC™ 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
2、显卡GPU:
NVIDIA L40S GPU 48GB×8
NVIDIA NVLink-A100-SXM640GB
NVIDIA HGX A800 80GB×8
NVIDIA Tesla H800 80GB HBM2
NVIDIA A800-80GB-400Wx8-NvlinkSW×8