python 学习
1.转义字符
字符串前加r,使转义字符不起作用
print(r"hello\t world")2.数据类型
python数据类型分为int,float,bool,str
整数类型的形式:
print("二进制0b开头", 0b10111001)
print("八进制0o开头", 0o1257436)
print("十六进制0x开头", 0x12cdef)
浮点数计算不精确
a = 1.1
b = 2.2
# 结果是3.3000000000000003,表示浮点数计算不精确
print(a+b)
引入decimal模块解决
from decimal import Decimal
print(Decimal("1.1")+Decimal("2.2"))字符串类型:
#数字与ascII码的转换
print(ord("a"))
print(chr(98))三引号的字符类型可以保留格式:
a = '''天阶夜色凉如水
卧看牵牛织女星
'''
print(a)
b = """银屏秋光冷画屏
轻罗小扇扑流萤
"""
print(b)
字符类型转换:
a = '天阶夜色凉如水'
b = 33
print(a+str(b))int()将其他类型转整数,只能转数字类型的字符串,浮点类型只保留整数部分
c = 33.93
d = True
print(int(c), int(d))
float()将其他数据类型转浮点类型,只能转数字类型的字符串,整数类型会加小数点.0
b = 33
print(float(b))3.注释
#号是单行注释
python没有多行注释,三引号可以当作多行注释
"""
这是多行注释
"""4.运算符
#除法运算,取商运算,取模运算
print(11/2)
print(11//2)
print(11 % 2)
#幂运算
print(2**3)赋值运算符
# 链式赋值
a = b = c = 20
# 解构赋值
aa, bb, cc = 30, 40, 50
# 交换赋值
aa, bb = bb, aa比较运算符
a = 20
b = "20"
print(a == b) # false
list1 = [11, 22, 33, 44]
list2 = [11, 22, 33, 44]
print(list1 == list2) #比较内存地址指向的内容
print(list1 is list2) #比较内存地址布尔运算符
a = 20
b = 10
# 与
print(a > 0 and b > 0)
# 或
print(a > 0 or b > 0)
# 非
print(not a > 0)
s = "aaffffsdf"
print("a" in s)
print("v" not in s)位与:同个位置都为1才是1
位或:同个位置有一个1就是1
print(4 & 8)
print(4 | 8)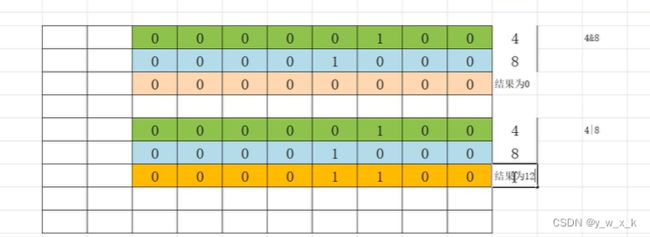
左移:整体左移,高位溢出,低位补0
print(4 << 1)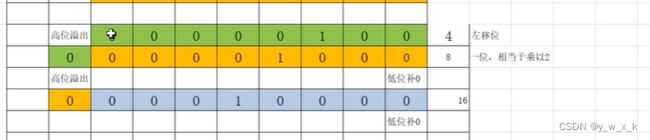
右移:整体右移,高位补0,低位截断
print(4 >> 1)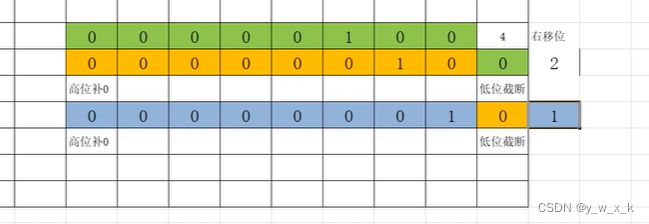
5.程序执行顺序
python的所有数据类型都有布尔值,任何空元素都是False;
b = int(input("输入数字"))
if b > 300:
print("大于300")
elif b > 200:
print("大于200")
elif b > 100:
print("大于100")
else:
print("小于100")
6.continue与beark
break:跳出循环;
continue:停止本轮循环,继续下一轮循环;
两者都只能在当层循环起作用,如果是嵌套循环,对上一层循环是没有作用的;
7.列表(数组)
两种创建方式:
ls1 = ["a", "b", 6446, "a"]
li2 = list(["c", "d", 344])
获取元素的索引:
print(ls1.index("a"))
#获取0,2索引间a元素的索引值
print(ls1.index("a", 0, 2))#逆向索引,从-1开始
print(ls1[-2])
#切片
ls = list(range(25))
#开始:结束:步长
print(ls[5:20:2])
#结束不写,默认到最后
print(ls[5::2])
# 反向切片,可以倒置数组
print(ls[10:0:-1])
print(ls[::-1])#in与not in判断元素是否在数组中
print(115 in ls)#遍历元素
for item in ls:
print(item)
ls = ['a', 'b', 'c']
# 向列表添加一个元素
ls.append('d')
# 批量向列表添加元素
ls.extend(['e', 'f'])
# 向列表的任意位置添加元素
ls.insert(2, "gggg")
# 切片方式替换列表
ls[2:] = ['hh', 'kk']
#从列表中删除一个元素,如果有重复元素,则移除第一个
ls.remove("hh")
#移除指定索引的元素
ls.pop(1)
#移除列表的最后一个元素
ls.pop()
# 切片删除列表的多个元素,但是会产生一个新的列表,原列表不变
ls_new = ls[1:3]
# 切片删除多个元素,改变原列表
ls[1:3] = []
#清空列表
ls.clear()
#删除列表
del ls# 修改列表
ls[1] = "aaa"
# 切片替换
ls[1:2] = [100, 200, 500, 600]
ls2 = [5, 2, 98, 254, 56, 34]
# 升序排序
ls2.sort()
#降序排序
ls2.sort(reverse=True)
# 排序,产生一个新的列表
ls3 = sorted(ls2)
ls4 = sorted(ls2, reverse=True)#列表生成式
ls2 = [i for i in range(10)]8.字典(键值对数据结构)
是无序数据结构;
#创建字典
d = {'a': 'aa', 'b': 'bbb', 'c': 'cc'}
d2 = dict(name="hello", age=32, sex="男")
#字典取值
print(d['a'], d2.get("age"))
# 查找的元素不存在时,返回默认值
print(d2.get("aaaa", "world"))
# 判断元素是否在字典中
print("a" in d2, "a" not in d2)
# 字典的删除
del d2["name"]
# 字典的新增
d2['name2'] = "曹冲"
# 字典的修改
d2['name2'] = "曹操"
#清空字典
d2.clear()
# 获取字典所有key
keys = d2.keys()
# 获取字典所有value
vals = d2.values()
# 获取字典所有items
item = d2.items()
# 字典生成式
l1 = ["zhangsan", "lisi", "wangwu"]
l2 = [35, 12, 89]
d1 = zip(l1, l2)
d2 = {key: val for key, val in d1}
9.元组
元组是不可变序列,相当于常量对象;
不可变指的是元素的引用地址不可变,如果元素是列表,则列表内的元素是可变的;
在多任务环境下,同时操作元组可以不用加锁;
#创建元组
t1 = ("aaa", "bbb", 98)
t2 = tuple(("ccc", "ddd", 123))
t3 = "eee", "ffff", 1321只有一个元素的元组需要使用逗号和小括号,否则会认为是一个字符串
t4 = ("gggg",)#创建空元组
t1 = ()
t2 = tuple()
#元组元素的地址不可变
t1 = (1, [2, 3], 4)
t1[1] = [100, 200] #会抛出异常
#如果元组中的元素是可变对象,那么可以修改该元素的数据
t1[1][1] = 100
# 获取元组的元素
print(t1[1])
for item in t1:
print(item)
10.集合
与列表,字典一样,是可变序列;
集合是没有value的字典
集合是一种无序列表,元素不可重复
# 创建集合
s = {'aa', 'bb', 'cc', 'aa'}
# 将列表转集合
s2 = set([5, 8, 9, 7, 6])
# 将元组转集合
s3 = set((5, 6, 8, 9, 2, 4, 5, 200))
# 定义空集合
s4 = set()
# 判断集合中的元素
print('aa' in s)
# 向集合添加一个元素
s.add("ee")
# 向集合一次添加多个元素
s.update({'ff', 'aaa', 'ccc'})
# 集合中删除元素
s.remove("cccc")
# remove删除不存在的元素会抛出异常,discard方法不会
s.discard("cccc")
# 随机删除集合中的一个元素
s.pop()
# 清空集合
s.clear()
# 判断集合关系
s1 = {1, 2, 3, 4}
s2 = {4, 1, 3, 2}
# 集合是无序的,两个集合的元素相同即集合相等
print(s1 == s2)
s3 = {2, 1}
# 如果一个集合的所有元素都在另一个集合中,那么这个集合是另一个集合的子集,两个相同的集合互为子集
print(s2.issubset(s1))
print(s3.issubset(s1))
# 超集,即父集,与子集相反,如果a集合是b集合的子集,那么b集合就是a集合的超集
print(s1.issuperset(s3))
s4 = {5, 6, 8, 6}
# isdisjoint判断是否没有交集
print(s4.isdisjoint(s1))
# 集合当中的数学运算
s1 = {10, 20, 30, 40}
s2 = {30, 40, 50, 60}
# 交集
print(s1 & s2)
print(s1.intersection(s2))
# 并集
print(s1 | s2)
print(s1.union(s2))
# 差集
print(s1.difference(s2))
print(s1 - s2)
# 对称差集,两个集合相并,去掉共有元素
print(s1.symmetric_difference(s2))
print(s1 ^ s2)
11.字符串深入
s1 = "hello world"
#字符串第一次出现的位置,没找到抛出异常
print(s1.index("o"))
#字符串最后一次出现的位置,没找到抛出异常
print(s1.rindex("o"))
# 字符串第一次出现的位置,没找到返回-1
print(s1.find("a"))
# 字符串最后一次出现的位置,没找到返回-1
print(s1.rfind("a"))
# 字符串左右填充,居中对齐
print(s1.center(20, "*"))
# 字符串左对齐
print(s1.ljust(20, "*"))
# 字符串右对齐
print(s1.rjust(20, "*"))
# 字符串右对齐,填充0对齐
print(s1.zfill(20))
# 字符串分割成数组
print(s1.split(","))
# 最大分割次数为1
print(s1.split(",", 1))
# 从右边开始分割
print(s1.rsplit(","))
# 最大分割次数为1
print(s1.rsplit(",", 1))
#判断是否合法标识符,即字母,数字,下划线组成的字符串
print(s1.isidentifier())
# 判断是否合法标识符,即字母,数字,下划线组成的字符串
print(s1.isidentifier())
# 判断是否是十进制数字
print('04548'.isdecimal())
# 判断是否是数字
print("4848".isnumeric())
# 判断是否有数字字母组成
print("dfgdfg5576".isalnum())
# 将列表或元组的字符串,组成字符串
l1 = ['1', '5', 'ghfg', '45ff']
print(",".join(l1))
l2 = ("fghg", "hh", "oo")
print("/".join(l2))字符串是驻留在常量池的,所以是不可变类型,不能进行增删改操作;任何对字符串的增删改都要产生新的变量;
#字符串占位操作
print("aaa%sbbb,ccc%dddd" % ("apple", 32))
print("aaa{0}bbb,ccc{1}ddd".format("apple", 32))
s1 = 'apple'
s2 = 32
print(f'aaa{s1}--bbb{s2}')
# 设定占位符宽度
print("%10d" % 88)
# 设定占位符精度
print("%.3f" % 3.1415926)
print("aa{0:.3f}bb".format(3.14159))
# 同时设置精度跟宽度
print('%10.3f' % 3.14159265758)
print("aa{0:10.3f}bb".format(3.14159))
#一共是3位数
print("aa{0:.3}bb".format(3.14159))12.函数
按照关键字传参:
calc(b=6, a=9)#函数如果没有返回值,return可以不写
#函数返回多个值时,返回元组
def fun():
a1 = [6, 99, 8]
a2 = [5, 7, 6, 3]
return a1, a2
# 参数数量不确定时,传入可变参数
def fun(*args):
print(args)
# 可变关键字传参,接收到的是字典
def fun2(**args):
print(args)
#扩展运算符
def fun(*args):
print(args)
l1 = [55, 66, 99]
print(fun(*l1))
l2 = {"a": 55, "b": 66, "c": 88}
def fun2(a, b, c):
print(a, b, c)
print(fun2(**l2))
#局部变量升级成全局变量
def fun():
global name
name = "aaa"
print(name)13.异常
a = 10
b = 0
try:
a/b
except Exception as e:
# 如果有异常
print('error', e)
else:
# 如果没有异常
print("ok")
finally:
# 最终都会执行
print("finally")14.类与对象
class Cat:
name = ""
age = 0
# 初始方法
def __init__(self, name, age):
self.name = name
self.age = age
# 类方法
def eat(self):
print(self.name+"吃饭")
# 静态方法
@staticmethod
def jiao():
print("多多叫了")
@classmethod
def cm(cls):
print("类方法")
duoduo = Cat("duoduo", 5)
#调用实例方法
duoduo.eat()
#多态
tuantuan = Cat("tuantuan", 3)
Cat.eat(duoduo)
Cat.eat(tuantuan)
# 静态方法调用
Cat.jiao()
# 类方法调用
Cat.cm()
python中没有特定的修饰符表示类的私有属性,但是可以用"__"加属性名表示不允许被外部访问;
class Cat:
__age = 0
def __init__(self, age):
self.__age = age
def get_age(self):
print(self.__age)
#在类的外部可以使用这个方法获取不允许访问的属性
print(cat._Cat__age)
class Cat():
name = ""
age = ""
def __init__(self, name, age):
self.name = name
self.age = age
def info(self):
print("我叫"+self.name+",今年" + str(self.age)+"岁")
class Jinjila(Cat):
def __init__(self, name, age):
super().__init__(name, age)
class Yinjianchen(Cat):
def __init__(self, name, age):
super().__init__(name, age)
def my_info(self):
print("我是银渐层")
#子类多继承
class C(Jinjila, Yinjianchen):
def __init__(self, name, age):
super().__init__(name, age)
def c_info(self):
print("多继承子类")
#重写父类方法
def my_info(self):
#调用祖类方法
super().info()
print("我是杂交猫")
duoduo = Jinjila("多多", 5)
duoduo.info()
tuantuan = C("团团", 6)
tuantuan.my_info()所有类的基类是object,dir()查看对象的所有方法
可以用__str__()方法重写对象的描述
class Dog():
def __str__(self) -> str:
return ("这是一只狗")
d = Dog()
print(d)特殊属性:
#查看对象与类的所有属性
print(tuantuan.__dict__)
print(Cat.__dict__)
#查看对象所属的类
print(tuantuan.__class__)
# 查看类的所有父类
print(C.__bases__)
# 查看类的继承链
print(C.__mro__)
# 查看子类
print(Cat.__subclasses__())特殊方法:
class Cat():
name = ""
age = ""
def __init__(self, name, age) -> None:
self.name = name
self.age = age
#重写对象的加法运算
def __add__(self, other):
return self.name+other.name
# 重写对象的长度运算
def __len__(self):
return 10
def __init__(self, name, age) -> None:
print("init方法被调用了,self id{0}".format(id(self)))
self.name = name
self.age = age
def __new__(cls, *args, **kwargs):
print("new方法被调用了,cls={0}".format(id(cls)))
obj = super().__new__(cls)
print("创建对象obj,id={0}".format(id(obj)))
return obj
print("object类对象id={0}".format(id(object)))
print("Cat类对象id={0}".format(id(Cat)))
c1 = Cat("团团", 1)
print("c1对象的id={0}".format(id(c1)))
c2 = Cat("多多", 2)
print("c2对象的id={0}".format(id(c2)))
print(c1+c2)
print(len(c1))
import copy
class A():
pass
class B():
pass
class C():
def __init__(self, a, b):
self.a = a
self.b = b
a = A()
b = B()
c = C(a, b)
# 对象的浅拷贝
c2 = copy.copy(c)
print(id(c.a), id(c2.a))
# 深拷贝
c3 = copy.deepcopy(c)
print(id(c.a), id(c3.a))15.模块化
python中,任何.py结尾的文件都是模块,模块的内容可以包含方法,类,语句;
#第一种导入方式
import Cat
#别名
#import Cat as Dog
print(Cat.duoduo)
Cat.eat()
dd = Cat.Cat()
#第二种导入方式
from Cat import duoduo, eat, Cat
print(duoduo)
eat()
dd = Cat()每个模块都有一个记录模块名称的变量__name__,值为文件名,用于程序检查在哪个模块执行,如果一个模块不是被导入到其他模块中执行,那么他可能是程序的顶级模块,顶级模块的__name__的值为__main__
class Cat():
def __init__(self):
print("我是多多")
duoduo = "多多"
def eat():
print("吃")
if __name__ == "__main__":
print("只有在当前模块是顶级模块的时候才运行这个代码")包:
包是一种分层次的目录结构,他将一组功能相近的模块组织在一个文件夹下;
包与文件夹的区别:包含__init__.py文件的目录称为包;
#导入包
import Cat.Jinjila
#取别名
import Cat.Jinjila as Jin
#导入包的模块的变量
from Cat.Jinjila import duoduo
print(Cat.Jinjila.duoduo)
Python的内置模块:
sys:提供python环境操作的相关方法;
time:提供时间相关的各种函数;
os:操作系统文件相关方法;
calendar:日期相关方法;
urllib:是一个包,提供网络请求相关方法;
json:序列化与反序列化相关方法;
math:数学运算相关方法;
decimal:运算精度控制,十进制转化相关方法;
logging:错误记录,警告、调试等日志方法;
安装第三方模块:pip install xxxx
16.IO流
读写文件的原理:文件的内容以队列数据结构,先进先出的形式,通过管道由一个文件流入另一个文件;
步骤:打开或者创建文件->读、写文件->关闭资源
格式: file=open(filename,[打开模式(默认只读),字符编码])
打开模式:
r:只读模式,不能往文件里写入东西,指针在文件开头;
w:只写模式,只能往文件里写入内容,不能读取,文件不存在则会创建文件,指针在文件开头;
a:追加模式,只能往文件里追加内容,不能读取,文件不存在则会创建文件,指针在文件内容末尾;
b:以二进制方式读取内容,通常用来读取图片,视频,必须配合其他模式使用,rb,wb;
+:以读写的方式一起打开,必须配合其他模式使用,a+,
#边读边写文件,文件拷贝
src_file = open("6.jpg", "rb")
target_file = open('88.jpg', 'wb')
target_file.write(src_file.read())
target_file.close()
src_file.close()
文件操作相关方法:
#每次读取若干个字节,没有参数则全部读取
print(file.read(2))
#每次读取一行内容
print(file.readline())
# 将内容按行分割,放入列表中返回
print(file.readlines())
# 写入内容
file.write("相顾无言惟有泪千行")
# 将列表的内容写入文件,不换行
l = ['小轩窗正梳妆', '相顾无言惟有泪千行', '料得年年肠断']
file.writelines(l)
# 将文件指针移动到第3个字节处,UTF8一个汉字占3个字节,不能是1或者2,读半个汉字会报错
file.seek(3)
print(file.read())
#获取文件的当前指针位置
print(file.tell())
# 把缓冲区的内容写入文件,而不关闭文件
file.write("十年生死两茫茫")
file.flush()
# 把缓冲区的内容写入文件,然后关闭文件,释放相关资源
file.close()# with语句可以自动管理上下文资源,不论什么原因跳出with语句,都能保证文件的正确关闭,释放资源
with open('b.txt', 'r+', encoding='utf-8') as file:
print(file.read())
with open('6.jpg', 'rb') as img:
with open('99.jpg', 'wb') as new_img:
new_img.write(img.read())
17.os模块
os模块非常强大,os模块是与操作系统相关的模块,可以调用操作系统的软件与文件;
import os
# 直接打开系统的计算器
# os.system("calc.exe")
# 直接打开系统软件
os.system('E:\\QQ\\Bin\\QQ.exe')os模块操作目录:
#获取当前目录路径
print(os.getcwd())
# 返回指定路径下的文件列表
print(os.listdir("./Cat"))
# 创建目录
os.mkdir("./aa")
# 创建多级目录
os.makedirs('./aaa/bb/cc')
# 删除空目录
os.rmdir("./aa")
# 删除多级目录
os.removedirs("./aaa/bb/cc")
# 设置当前工作目录
os.chdir("C:\\Users\\Administrator\\Desktop\\图片")
print(os.getcwd())os.path模块
import os.path
# 获取文件的绝对路径
print(os.path.abspath("6.jpg"))
# 判断文件是否存在
print(os.path.exists("818.jpg"))
# 将目录与目录或文件拼接
print(os.path.join("E://a/", "88.jpg"))
# 分离路径与文件名
print(os.path.split("E://aa/88.jpg"))
# 分离文件名与扩展名
print(os.path.splitext("88.jpg"))
# 获取路径中的文件名
print(os.path.basename("E://aa/bb/c.txt"))
# 获取路径中的目录路径
print(os.path.dirname("E://aa/bb/c.txt"))
# 判断目录路径是否存在
print(os.path.isdir("E:\\QQ\\Bin1"))
dir = os.getcwd()
#递归获取目录下所有文件及其子目录
dir_dict = os.walk(dir)
for dirpath, dirname, filename in dir_dict:
print(dirpath, dirname, filename)
print("-----------------")18.项目打包
安装打包插件
pip install Pyinstaller打包程序:
pyinstaller -F F:\pytest\stu_system\menus.py