应用计量经济学与R(一)
我们相信R在计量经济学中有巨大的潜力,至少有三个原因:
- R 基本上是独立于操作系统平台的,兼容性非常强,可以在 Windows、Mac系列操作系统和各种风格的 Unix/Linux上,也适用于一些更奇特的操作系统平台。
- R 是一款免费软件,可以从全球的镜像站点 CRAN(The Comprehensive R Archive Network) 中免费下载和安装。
- R 是一款开源软件,因此可以获得完整的源代码,用于学习、修改和扩展。平台独立性和开源理念使 R 成为可复制的(reproducible) 计量经济学研究的理想环境。
我们将介绍截面数据(cross-sectional data sets) 和时间序列数据(time series data) 的线性回归模型,以及微观经济计量学中常见的非线性模型,如 logit, probit 和tobit模型,以及计数数据(count data) 的回归模型。此外,我们还提供了一章关于编程的内容,包括模拟、最优化和对 Sweave() 的介绍,Sweave() 是一个允许在单个文档中集成文本和代码的环境,因此极大地促进了可复制的研究。
下面我们简要分析了两个数据集,这些例子应该有助于对R的功能和语法给出第一印象。关于技术细节的解释和更完整的分析将推迟到后面的博文。
例1:经济学期刊需求
我们从一个小数据集开始,该数据集提供了2000年美国图书馆经济学期刊订阅数量的信息。数据集在 R package AER 中的名称是 Journals. AER 可以通过

 选择一个镜像
选择一个镜像

安装,也可以使用
> install.packages("AER")注意>不是命令的一部分,而是由R打印输出的,以指示它已准备好输入另一个命令。>是标准的R提示符。
> data("Journals", package = "AER")
> dim(Journals)
[1] 180 10
> names(Journals)
[1] "title" "publisher" "society" "price"
[5] "pages" "charpp" "citations" "foundingyear"
[9] "subs" "field" 行号是博客编辑器加上的,R 窗口中没有。可见 Journals 是一个包含180个观察值(期刊)的数据集,这些观察值涉及10个变量,包括图书馆订阅数量(sub)、价格(price)、引文数量(citations),以及一个表明期刊是否为 published by a society 的定性变量。
在这里,我们感兴趣的是经济学期刊的需求与价格之间的关系。科学期刊价格的一个合适的衡量标准是 price per citation.通过
> plot(log(subs) ~ log(price/citations), data = Journals)得到散点图(自变量和因变量都取了自然对数)

散点图清楚地显示了订阅的数量随着价格的上升而减少。相应的线性回归模型可以很容易地用普通最小二乘法(OLS)拟合,使用函数lm(),
> j_lm <- lm(log(subs) ~ log(price/citations), data = Journals)
> abline(j_lm)
 函数 abline() 在上一幅散点图的基础上加入了最小二乘线。
函数 abline() 在上一幅散点图的基础上加入了最小二乘线。
最小二乘(自变量和因变量都取了自然对数)拟合结果概要
> summary(j_lm)
Call:
lm(formula = log(subs) ~ log(price/citations), data = Journals)
Residuals:
Min 1Q Median 3Q Max
-2.72478 -0.53609 0.03721 0.46619 1.84808
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.76621 0.05591 85.25 <2e-16 ***
log(price/citations) -0.53305 0.03561 -14.97 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.7497 on 178 degrees of freedom
Multiple R-squared: 0.5573, Adjusted R-squared: 0.5548
F-statistic: 224 on 1 and 178 DF, p-value: < 2.2e-16
结果列出了回归系数的估计值、标准误差、检验统计量、p值和 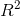 . 对于截面数据回归,拟合的模型是相当令人满意的。
. 对于截面数据回归,拟合的模型是相当令人满意的。
例2:工资的决定因素
在前面的例子中,我们展示了如何拟合一个简单的线性回归模型来获得对R操作的初步感受。通常,执行分析的命令读起来就像对系统说简单的句子。为了完成更复杂的任务,命令也变得更技术化,但是基本思路保持不变。因此,读者应该能够识别上一个示例中的许多语法结构,即使这里还没有解释函数的每个细节(关于命令和数据的更多细节将在后面的博文中提供)。
这里的应用是估计半对数形式的工资决定因素回归方程。数据来自1985年5月 Current Population Survey 的截面数据随机样本,包括533个观测值。从之前安装的 AER package 加载数据集 CPS1985 后,为了方便起见,我们首先对其重命名为 cps:
> data("CPS1985", package = "AER")
> cps <- CPS1985